How We Won the First Data-Centric AI Competition: Synaptic-AnN

In this blog post, Synaptic-AnN, one of the winners of the Data-Centric AI Competition, describes techniques and strategies that led to victory. Participants received a fixed model architecture and a dataset of 1,500 handwritten Roman numerals. Their task was to optimize model performance solely by improving the dataset and dividing it into training and validation sets. The dataset size was capped at 10,000. You can find more details about the competition here.
1. Your personal journey in AI:
Asfandyar:
Before all this, I was following in my father’s footsteps thinking that I wanted to become a hot-shot banker. However, while pursuing a degree in Mathematics and Economics, I realized that my quantitative skills were not being applied in the banking sector as I had wished. I quickly found out that consultancy work and Excel spreadsheets were not for me.
After watching the movie The Internship, the TV-series Silicon Valley, and playing the video game Detroit: Become Human, I was sold on artificial intelligence and the tech industry. While taking a deep dive on YouTube, I came across multiple tech channels that spoke fondly of Andrew Ng’s Machine Learning course on Coursera. I had to try it!
Next thing I know, I’ve completed the Deep Learning specialization on Coursera and am pursuing my current degree program in Data Science and AI. Furthermore, Deeplearning.ai and Stanford HAI’s virtual event on Healthcare’s AI Future made me understand AI’s sheer impact on our society. I went through a major spinal cord surgery back in late 2019 caused by a congenital birth defect that was undetected at birth (Spina Bifida Occulta with Tethered Cord Syndrome). I want to one day build an AI system that supplements neuroimaging in detecting such cases to save people in the future from the inconveniences of this condition, and help them get the required surgery earlier.
I have finally found myself in a career path that calls upon my quantitative abilities while also being applicable in any domain. Between completing my first machine learning internship behind me and winning the Data-Centric AI competition, many doors have opened up for me. I am looking forward to the next challenge in my AI journey! I aspire to leave behind a legacy and bring about meaningful change in society.
Nidhish:
My AI adventure began with the introduction of virtual assistants such as Siri and Google. The potential of machines to comprehend human language piqued my interest. However, I was too young to appreciate the concepts behind these technologies at the time. Therefore, my budding interest in AI was pushed to the back of my mind. When I came across OpenAI’s Hide and Seek project, which uses multi-agent Reinforcement Learning, I was fascinated by how agents simulated human behavior in way seven the researchers did not expect. After that I explored AI through a series of tiny side endeavors and projects. It didn’t sit well with me to implement models without first understanding how they worked.
My first formal introduction to AI was through Andrew Ng’s Deep Learning specialization. I finished the entire course in the first few weeks of summer 2021. This knowledge directly contributed to winning the inaugural Data-Centric AI competition. Asfandyar and I are the AI track representatives at the Honors Academy at our university, and as such we strive to democratize AI by teaching more students about it and its benefits. Following Andrew Ng’s lead, we want to continue advocating the data-centric approach to AI as we aim to build a data-centric AI course with the support of one of our professors. I look forward to seeing what the next chapter of AI has in store for everyone.
2. Why you decided to participate in the competition
With our first-ever AI internships set for the summer, we wanted to fill time with other learning opportunities that were not coursework-based. Essentially, we were looking for an experience where we could apply and practice the deep learning fundamentals we had learned so far. We thought about partaking in competitions like NetHack but found that our prerequisite knowledge was somewhat lacking.
We were familiar with DeepLearning.ai through Andrew Ng’s courses.It only seemed natural to apply what we learned from the DeepLearning.ai courses to their own competition!
3. The techniques you used
Here you can find a brief introduction of the techniques we used in our 3rd place (85.45% on the leaderboard). For a full report on everything team Synaptic-AnN tried during the competition, please refer to documentation here.
Manual data cleaning:
Like most other competitors, our initial instinct led us to manually sift through the dataset and remove any outliers, noisy, and ambiguous images. This reduced the competition dataset from 2880 images to 2613 images. Let’s call this dataset D.
Generating more data:
Since the competition allowed us to submit a maximum of 10,000 images amid training and validation sets (we did a 95/5 train-val split) we recruited friends and family to help us write 4353 additional Roman numerals. Let’s call this dataset H.
The reason we got multiple people to handwrite Roman numerals is because we wanted to stay as authentic to the nature of the task as possible. Augmenting over D to fill out the rest of the possible images did not seem like the best of ideas as we wanted to make sure the ResNet50 generalized well. Using GANs was something we wanted to explore, but realized it would have introduced unwanted artifacts and would have been computationally expensive. Having Roman numerals from a wide variety of distributions is what we were going for here.
Distribution and Style Replication:
It was theorized that humans have consistent handwriting (Figure 1). As a result, an attempt was made to replicate the handwriting style for each number. The images of the label book were used assuming that the label book would be a subset of the hidden test set. This concept aimed to replicate the distribution of the hidden test set. An example of this method can be seen in Figure 2 and Figure 3. Let’s call this dataset L.

Figure 1: Images from the label book with the same style.

Figure 2: Style replication applied on class I of the label book — images bordered in blue are the original label book images.

Figure 3: Style replication applied on class IV of the label book — images bordered in blue are the original label book images.
And so, the combination of D, H, and L happened to be our base dataset to be refined by the following data-centric approaches.
Five Crops:
For an image, top-right, top-left, bottom-right, bottom-left and centre crops were performed (Figure 4). Images that could lead to misclassification due to improper crops were discarded (e.g. an image of a badly cropped III could look like a II).

Figure 4: Five Crops applied to an image of class IX.
Aspect Ratio Standardization:
All images with width-height or height-width ratio being larger than 1.75 (and in some cases larger than 1.5) were cropped into a square the size of their minimum dimension. This ensured the quality of the images when resized to 32-by-32.
Auto Augmentation:
We had set up an augmentation pipeline that would generate submission datasets based on parameters we had to manually tweak (eg; the degree of rotations, magnitude of shearing, etc.).
We explored the viability of using AutoAugment to learn the augmentation technique parameters, but due to limited computational resources and insufficient data, the results of the paper on the SVHN dataset were used on the competition dataset. We observed that augmentation techniques such as Solarize and Invert were ineffective and hence removed them from the final SVHN-policy. This method resulted in a significant performance boost and was chosen because the SVHN dataset is grayscale and has to do with number representations (housing plates). We also explored other auto augment policies based on CIFAR10 and ImageNet ,but these were not as effective as SVHN.
Filtering by Vote:
A voting ensemble was deployed for filtering of noisy and ambiguous images. The ensemble comprised of 5 models:
- ResNet34 (denoted as m0 — a “close relative” to the competition model)
- AlexNet (denoted as m1)
- LeNet5 (denoted as m2)
- AllConvNet (denoted as m3)
- VGG-16 (denoted as m4)
Approximately 70,000 training images were used. Data was collected from the internet (use of online tools), through surveys (asked people to handwrite roman numerals for us), and using our augmentation pipeline (this helped us get up to 70k images). Again, the augmentation pipeline applied specific augmentation parameters set by us and would generate a balanced dataset. Given an image, I, the ensemble outputs a softmax probability matrix, ∑, where each row represents the softmax probability vector from a model, mi, within the ensemble and where the columns correspond to a certain class label, c.

![]() then I is deemed as “noisy” or “ambiguous”. This method saved hours of manual cleaning and helped to clean noisy labels. The images deemed as noisy or ambiguous were also manually checked by humans to ensure robustness. Originally, higher values for the threshold parameter were used for image selection but given time constraints and an unoptimized ensemble (some hyperparameters were left untuned due to time constraints), this was a limited approach.
then I is deemed as “noisy” or “ambiguous”. This method saved hours of manual cleaning and helped to clean noisy labels. The images deemed as noisy or ambiguous were also manually checked by humans to ensure robustness. Originally, higher values for the threshold parameter were used for image selection but given time constraints and an unoptimized ensemble (some hyperparameters were left untuned due to time constraints), this was a limited approach.
The Winning Submission:
Now that you are aware of the concepts and techniques used to produce our winning submission, here are the steps we took to refine the final dataset.
- Merge D, H, and L and generate 1500 SVHN-policy auto augmented images per class — let the resulting dataset be denoted by X.
- Note: Images in D and H had an aspect ratio less than 1.75. This was done by manual cropping. Furthermore, these datasets were ran through the voting ensemble at
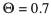 while retaining some high entropy images (manually selected).
while retaining some high entropy images (manually selected).
- Note: Images in D and H had an aspect ratio less than 1.75. This was done by manual cropping. Furthermore, these datasets were ran through the voting ensemble at
- Run D and H through the voting ensemble at
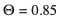 Merge the resulting dataset with L then perform 80 Five Crops per class — let the resulting dataset be denoted by Y.
Merge the resulting dataset with L then perform 80 Five Crops per class — let the resulting dataset be denoted by Y. - Any excess images in X and Y are randomly deleted while considering the combined size of the original D, H, and L.
- Finally merge D, H, L, X, and Y (class are balanced).
4. Your advice for other learners
Asfandyar:
I am a major advocate of life-long learning, and in the context of AI, I would advise others to become an “all-rounder.” What I mean by this is to be open-minded to the various topics in AI and build an adequate level of knowledge in MLOps, natural language processing, computer vision, reinforcement learning, data analytics, and so on. I believe it is better to be an 8/10 on multiple things, rather than a 10/10 in one or two things and a 4/10 in everything else. This way, no matter who you are speaking to, what project you are working on, or what career opportunities may arise, you will always be prepared.
This approach naturally instilled in me a growth mindset, and I hope it can be beneficial for others. I was never the most enthusiastic about data cleaning.. The Data-Centric AI competition helped put into perspective how basic methods such as data cleaning and augmentation can increase performance on state-of-the-art models by up to 20%. This helped me to fall in love with the data-centric movement. I plan to be an ambassador for it wherever my career takes me. Keep an open mind, never stop learning, and try to be a jack of all trades!
Nidhish:
My advice would be to adopt experiential learning. Take a few courses, like the ones by DeepLearning.ai, and then jump right into a project. Build up your portfolio on GitHub and work on topics you are truly passionate about. It is very hard to define what path you should take to get started on your AI journey, and you do not want to get stuck in “tutorial hell”. You want to dip your toes in various sub-fields and applications of AI through various projects. This will ultimately help you decide what your calling is!
In our conference with Andrew Ng, he advised us to watch his CS230 lecture on career advice — and boy, was it helpful! All in all, AI practitioners are needed everywhere, so be yourself and keep learning!