
Dear friends,
The image below shows two photos of the same gear taken under different conditions. From the point of view of a computer-vision algorithm — as well as the human eye — the imaging setup that produced the picture on the right makes a defect in the gear much easier to spot.
This example illustrates the power of data-centric AI development. If you want to improve a neural network’s performance, often improving the data it analyzes is far quicker and easier than tinkering with its architecture. In this case, adjusting the imaging setup made the difference.
How can you tell that your imaging setup has room for improvement? If you can look at a physical object from a given angle and spot a defect, but you don’t see it clearly in a photo taken from the same angle, then your imaging setup likely could be improved. Parameters that you can control include
- Illumination: Is the scene well lit (with diffuse and/or spot lighting), at angles that make clearly visible the features you want your model to recognize? Have you controlled ambient sources such as windows and reflections that may make images less consistent? Are the resulting images consistent and free of glare?
- Camera position: Make sure the camera is well positioned to capture the relevant features. A defect in, say, a drinking glass or touch screen may be visible from one angle but not from another. And a camera that shakes or moves in response to surrounding vibrations can’t produce consistent images.
- Image resolution: The density of pixels that cover a given area should be high enough to capture the features you need to see.
- Camera parameters: Factors such as focus, contrast, and exposure time can reveal or hide important details. Are the features you aim to detect clearly in focus? Are the contrast and exposure chosen to make them easy to see?
 |
While deep learning has been used successfully with datasets in which the examples vary widely — say, recognizing faces against backgrounds that range from a crowded concert hall to an outdoor campsite — narrowing the data distribution simplifies computer vision problems. For example, if you want to detect diseased plants, deep learning may be your best bet if you have pictures of plants taken at various distances and under various lighting conditions. But if all the pictures are taken at a fixed distance under uniform lighting, the problem becomes much easier. In practical terms, that means the model will be more accurate and/or need a lot fewer examples. With a consistent dataset, I’ve seen neural networks learn to perform valuable tasks with just 50 images per class (even though I would love to have had 5,000!).
Robotics engineers are accustomed to paying attention to the design of imaging systems (as well as audio and other sensor systems). Such attention also can benefit machine learning engineers who want to build practical computer vision systems.
Recently I had the pleasure of writing an article with machine vision guru David Dechow that describes these ideas in greater detail. The article focuses on manufacturing, but the approach it describes applies to many computer vision projects where you can influence the imaging setup. Please take a look!
Keep learning,
Andrew
News
 |
The Social Nightmare
Scrutiny of Facebook intensified after a whistleblower leaked internal research showing the company has known that its ongoing drive to engage users has harmed individuals and society at large.
What’s new: Former Facebook product manager Frances Haugen, in appearances on television and before the U.S. Congress, described how the company’s algorithms reward divisiveness, damage some users’ mental health, and allow prominent members to skirt its rules.
Whistle blown: Haugen, who worked on a team that aimed to combat expressions of hate, violence, and misinformation, revealed her identity this week after passing Facebook documents to The Wall Street Journal and the U.S. Securities and Exchange Commission (SEC), which oversees public companies. The revelations prompted a Senate hearing in which legislators questioned Facebook’s global head of safety and called for regulating the company. The documents revealed that:
- Media companies and political organizations prioritized sharing of divisive and inflammatory content after Facebook in 2018 revised its recommendation algorithm to promote interaction among families and friends. They told the company they didn’t wish to promote such content but feared that they wouldn’t reach users otherwise. Similarly, anti-vaccination activists gamed the system, undermining CEO Mark Zuckerberg’s own goal of promoting awareness of Covid vaccines.
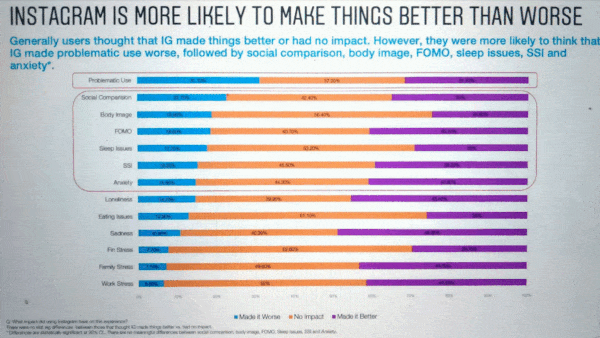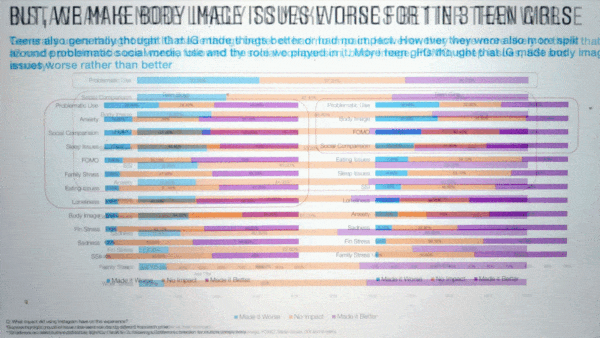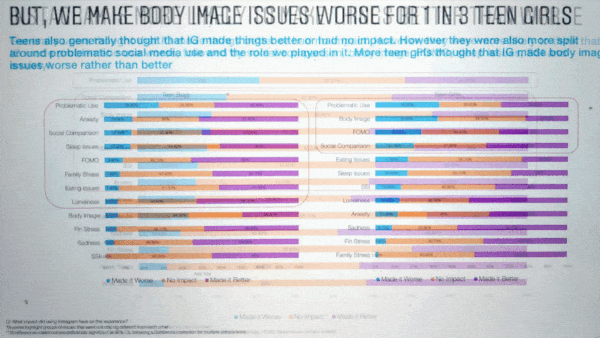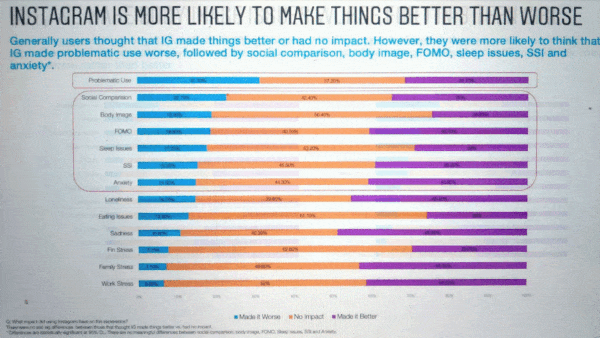
- Facebook subsidiary Instagram found that its app exacerbated feelings of inadequacy and depression in young people. Of teenage girls who used the app, 32 percent reported feeling worse about their bodies afterward, and 6 percent of U.S. teen users said the app caused them to consider suicide. In the wake of the revelations, Instagram suspended plans for a service tailored to kids.
- Facebook exempts millions of so-called VIP users from its rules that prohibit posts that contain disinformation, calls for violence, and information that its fact-checkers deem to be false.
Facebook’s response: The company said that press coverage of the documents had minimized its successes at blocking harmful content, pointing out that vaccine hesitancy among Facebook users declined by 50 percent since January. Instagram said that building a service for kids is “the right thing to do,” especially since many younger users lie about their age to gain access, which is limited to those 13 and older. Nonetheless, it has paused plans to build such a service while it works to persuade parents and policymakers that it’s a good idea.
Behind the news: Facebook has aimed to counter adverse effects of its recommendation algorithms with ever more sophisticated content-moderation algorithms. It has developed AI systems to detect hate speech, harmful memes, and misinformation. Yet it hasn’t addressed longstanding complaints that it torpedoes any program that has a negative impact on user engagement — including the unit Haugen worked for, which the company dissolved after the 2020 election.
Why it matters: Algorithms that optimize engagement are a key driver of profit for social networks — yet, as the leaked documents show, they can have severe consequences. The resulting harms undermine public trust in AI, and they build support for laws that would limit social media platforms and possibly recommendation algorithms in general.
We’re thinking: Facebook has been under fire for years. Despite the company’s testimony in several congressional hearings, apologies, and promises to do better, little has changed. An investigation by the SEC could break the logjam. Meanwhile, if you work in AI, we urge you to consider whether your employment, net-net, improves society and, if not, begin the transition into a situation that does.
 |
Guard Bot
Amazon unveiled a robot that patrols users’ homes, scopes out strangers, and warns of perceived dangers.
What’s new: Astro maps users’ homes while using face recognition to decide whether or not to act on perceived threats such as intruders. It also plays music and delivers teleconferences, and it has storage space for ferrying small items around the house. It’s scheduled to hit the market later this year for an introductory price of $999.
How it works: Astro is designed to learn about users’ homes and habits over time. Built on Amazon’s Alexa platform, it uses that system’s software for voice recognition and connects to the same security system as Ring doorbells.
- Astro maps optimal positions in each room from which to watch for intruders and hazards such as fires. It also keeps track of high-traffic areas to avoid.
- Users enroll the faces and voices of housemates and frequent visitors. The robot tracks everyone who enters a house using microphones and a telescoping camera that rises up to 42 inches above its body. If it detects an unfamiliar person, it will follow them, moving among vantage points in each room to receive a complete view of their activities.
- Users can start and stop patrols via a mobile app and can designate certain rooms off-limits.
Yes, but: Leaked documents published by Vice raise significant privacy concerns. For instance, law enforcement officials might serve warrants to Amazon, rather than homeowners, enabling them to monitor Astro’s output. Or they might use the robot to execute sting operations, as they have used Ring doorbells. Moreover, developers who worked on Astro told Vice the robot is fragile, prone to falling down stairs, and often misidentifies people.
Why it matters: Ring was an unqualified success, having sold over 1.4 million last year. Astro is a logical next step to further capitalize on that market. And there’s the added benefit that a rolling robot can provide an unprecedented view of a customer’s home and habits.
We’re thinking: No doubt many users will find Astro a fun addition to their gadget menagerie. However, we hope that Amazon will make it easy for users to opt out of (or, better yet, not opt into) undisclosed or unconsented uses of the data it collects.
A MESSAGE FROM DEEPLEARNING.AI
.png?upscale=true&width=1200&upscale=true&name=blog%20banner_The%20Batch%20Image%20(1).png) |
Are you an educator looking to develop your skills? DeepLearning.AI’s Curriculum Architect Program will show you how to design and build online courses like the ones we build ourselves! Learn more about the Curriculum Architect Program here
 |
Only Safe Drivers Get Self-Driving
Tesla’s autonomous driving capability has inspired hair-raising antics on the road. Now the company is deploying an algorithm to determine whether customers have shown sufficiently sound judgement to use its “Full Self-Driving” software.
What’s new: Starting this week, the beta-test version of Tesla’s latest self-driving update will be available only to drivers who have demonstrated safe driving. The beta program previously was open to about 2,000 drivers.
How it works: Drivers can request the software through a button on their car’s dashboard screen.
- The car then collects data about five factors: forward collision warnings per 1,000 miles, hard braking, aggressive turning, unsafe following, and forced disengagement of self-driving features when the car determines that drivers aren’t paying attention.
- Customers who maintain a high safety score for a week will be allowed to use the Full Self-Driving beta. The software will enable Tesla vehicles to autonomously brake for traffic lights and decide when to change lanes.
- Most drivers have a safety score of 80, which they can view in the Tesla app, the company said. It didn’t specify the score necessary to gain access to the beta.
Behind the news: The engineering association SAE International has graded Tesla’s Full Self-Driving system at Level 2 autonomy, which means it must be supervised constantly by a human driver. National Transportation Safety Board (NTSB) chair Jennifer Homendy recently said that Tesla’s use of the term “full self-driving” is irresponsible and called on the company to address basic safety issues before expanding the test program. The National Highway Traffic Safety Administration, which has the authority to demand recalls, is investigating the culpability of Tesla’s software in 11 accidents.
Why it matters: Self-driving technology is still developing and has not yet been proven safe under the vast variety of circumstances that arise in real-world driving. Most companies that are developing such technology hire safety drivers to test their systems within tightly constrained boundaries. In contrast, Tesla is enrolling the best drivers of Tesla vehicles to test its system on the open road.
We’re thinking: Scoring driver behavior and limiting the distribution of special features only to the safest drivers is a good idea, assuming the score is well designed and implemented. It both ensures that only excellent drivers can use the riskiest features and incentivizes all drivers to do their best. But recruiting customers to test unproven technology is reckless. We urge Tesla, and any company that would consider following its lead, to prove its technology’s safety under controlled conditions before putting the general public at risk. And can we stop calling a great driver assistance system “full self-driving”?
 |
Oddball Recognition
Models trained using supervised learning struggle to classify inputs that differ substantially from most of their training data. A new method helps them recognize such outliers.
What’s new: Abhijit Guha Roy, Jie Ren, and colleagues at Google developed Hierarchical Outlier Detection (HOD), a loss function that helps models learn to classify out-of-distribution inputs — even if they don’t conform to a class label in the training set.
Key insight: Previous work has proposed two general approaches to handling out-of-distribution inputs. One is to include a catch-all outlier class in the training set. Given the diversity of examples in this class, however, it’s difficult to learn to recognize outliers consistently. The other is to label separate outlier classes in the training set. This enables a trained model to recognize certain kinds of outliers but leaves it unable to identify outlier classes that aren't represented in the training set. HOD attempts to cover the gamut by encouraging a model to classify images both as outliers in general and as specific classes of outlier.
How it works: The authors started with a ResNet pretrained on JFT (Google's proprietary collection of 300 million images). They fine-tuned it on images of roughly 10,000 cases of skin disease, each labeled according to 225 different conditions. Of these, 26 conditions were represented by at least 100 cases; these were assigned an additional “inlier” label. The remaining 199 were assigned an additional “outlier” label. The training, validation, and test sets included a a variety of inlier classes, but the outlier classes were divided among them; that is, the datasets had no outlier classes in common.
- The ResNet generated a representation of each image in a case. It averaged the representations and passed them through a fully connected layer, forming a single representation of the case.
- A softmax layer used this representation to identify the condition. Then the model assigned an inlier or outlier label depending on whether the sum of the probabilities of predicting an outlier class exceeded a threshold set by the user.
- The HOD loss function contains two terms. One encourages the algorithm to identify the correct condition. The other encourages it to assign an accurate inlier or outlier label.
Results: Training the model on both outlier status and specific outlier classes helped it learn to recognize outliers in general — although the task still proved difficult. The authors’ approach achieved .794 AUC, while the same architecture trained on only a general outlier label (plus labels for all inlier classes) achieved .756 AUC. When classifying inliers, the model trained on all labels achieved 74 percent accuracy, while the one given only a general outlier label achieved 72.8 percent accuracy.
Why it matters: Real-world applications can be rife with out-of-distribution data. This approach helps models detect both examples that are similar to those in the training dataset but not labeled (for example, new skin conditions) and examples that are substantially different (for example, pictures of iguanas).
We're thinking: Giving models the ability to recognize edge cases could build greater trust in their output.