
Dear friends,
In June, I announced the first Data-centric AI Competition. The deadline for submissions was in early September, and today I’m thrilled to announce the winners!
A total of 489 individuals and teams submitted 2,458 unique datasets. By improving the data alone — not the model architecture, which was fixed — many contestants were able to improve on the baseline performance of 64.4% by over 20%. The winners in the Best Performance category achieved between 86.034% and 86.405%. The winners in the Most Innovative category, as well as the honorable mentions, achieved high performance using novel approaches.
Congratulations to Divakar Roy, Team Innotescus, and Team Synaptic-AnN, who took the top three spots for Best Performance. Congratulations also to Mohammad Motamedi, Johnson Kuan, and Team GoDataDriven, winners of the Most Innovative category. Pierre-Louis Bescond and Team KAIST-AIPRLab earned honorable mentions. I couldn’t be more proud of you all.
You can learn more about their approaches here. I hope you’ll apply these ideas to your own work.
 |
The winners joined me at a private roundtable event to discuss how to grow the data-centric AI movement. I was surprised to learn that almost all of them — some of whom have been involved in AI for a long time, and some of whom have little AI background — already have seen positive effects of data-centric techniques in their own work.
We chatted about the potential benefits of data-centric AI development to entrepreneurs and startups that may not have access to large datasets, and how it opens machine learning to non-engineers who, although they may not have the skills to build models, can make important contributions by gathering and refining data.
 |
We also discussed how working with data is often wrongly viewed as the boring part of machine learning even though, in reality, it’s a critical aspect of any project. I was reminded that, 10 years ago, working with neural networks was viewed in a similar light — people were more interested in hand-engineering features and viewed neural networks as uninteresting. I’m optimistic that the AI community before long will take as much interest in systematically improving data as architecting models.
Thank you to all the participants for helping build a foundation for future data-centric AI benchmarks. I hope this competition spurs you to innovate further systematic approaches to improving data. And I hope you’ll compete again in future data-centric AI challenges!
Keep learning,
Andrew
News
 |
White House Supports Limits on AI
As governments worldwide mull their AI strategies and policies, the Biden administration called for a “bill of rights” to mitigate adverse consequences.
What’s new: Top advisors to the U.S. president announced a plan to issue rules that would protect U.S. citizens against AI-powered surveillance, discrimination, and other kinds of harm. The dispatch coincided with a call for public comment on how to regulate systems like face recognition used to scan airline passengers, activity monitors that track employee productivity, and classroom management tools that alert teachers when their students tune out.
What they said: U.S. Office of Science and Technology Policy director Eric Lander and deputy director Alondra Nelson argue that certain AI applications threaten individual liberty and outline limits:
- U.S. citizens would be free from “pervasive or discriminatory surveillance” in their homes, communities, and workplaces. They would be informed when AI is behind any decisions that affect their civil rights or liberties. The systems involved would be audited to ensure that their output is accurate and free of bias.
- Citizens whose rights have been violated by an automated system would have ways to seek redress.
- The federal government could use its spending power to withhold funds from certain applications. For instance, agencies and contractors could be barred from developing or deploying non-compliant systems. Individual states could choose to do the same.
Behind the news: Momentum is building worldwide to restrict certain uses of AI. Last week, the European Parliament passed a non-binding ban on law enforcement’s use of face recognition and a moratorium on predictive policing algorithms except for serious offenses like child exploitation, financial crimes, and terrorism. Less than a month before, the UN’s human rights commissioner called on member states to institute restrictions. In August, China’s cyberspace administration announced forthcoming rules to limit the influence of recommendation algorithms.
Why it matters: An AI bill of rights is notional for the time being. But it could serve as a blueprint for national legislation, and it certainly would influence some states. And government funding could be a powerful carrot and stick: The U.S. paid $1.9 billion in contracts to AI companies between 2018 and 2020, and many state and local governments rely on federal money for law enforcement, health care, and other services where the use of AI is both growing and controversial.
We’re thinking: We support regulations to help AI maximize benefit and minimize harm, and the president’s endorsement is an important step. That said, we wonder: Would an Electricity Bill of Rights have made sense 100 years ago? We urge regulators to focus not on AI as a whole but on applications in vertical areas such as surveillance, advertising, consumer software, health care, law enforcement, social media, and many other areas. Meanwhile, the deadline for public comment is January 15, 2022. Let’s make ourselves heard!
 |
Your Voice, Your Choice
A startup enables people who participate in voice chat to use realistic artificial voices in real time.
What’s new: Massachusetts-based Modulate offers a voice-masking tool to forestall harassment of people, particularly women and trans individuals, whose vocal tone may trigger abuse in online conversations, Wired reported.
How it works: Modulate’s VoiceWear system acts like a generative adversarial network. A Parallel WaveNet model generates a speaker’s words in a synthetic voice. It tries to fool a convolutional neural network, which evaluates whether its output is real or synthesized.
- VoiceWear was trained on audio samples from hundreds of voice actors who read scripts using a wide range of intonation and emotional affect.
- Modulate originally conceived it as a way for gamers to play as specific characters. But feedback from the trans community persuaded the company that it also could help a person’s voice match their gender identity.
- The company has launched two voices, one male and one female, within an app called Animaze, which creates digital avatars for use during video calls or livestreams. It’s working with several game studios to bring VoiceWear to a wider market, CEO Mike Pappas told The Batch.
Behind the news: Other voice-changing systems are available, but most simply shift a voice’s pitch up or down using basic computational techniques, causing it to sound distorted or robotic.
Why it matters: Women, LGBT+ people, and various racial groups online are often targeted for harassment due to the way they sound. The abuse drives many away from popular video games, social media, and other experiences that encourage audio engagement, making such sites less inclusive and hurting their bottom line.
We’re thinking: Enabling people who are at risk of harassment to hide their identity is helpful. But online moderators — human or AI — also need to play an active role in curbing abuse.
A MESSAGE FROM DEEPLEARNING.AI
.png?upscale=true&width=1200&upscale=true&name=AI%20Access%2011.3_The%20Batch%20Image%20(3).png) |
We’re updating our Natural Language Processing Specialization to reflect the latest advances! Instructor Younes Bensouda Mourri and Hugging Face engineer Lewis Tunstall will host a live Ask Me Anything session on November 3, 2021. Join us for answers to your NLP-related questions!
 |
Different Strokes for Robot Folks
A neural network can make a photo resemble a painting via neural style transfer, but it can also learn to reproduce an image by applying brush strokes. A new method taught a system this painterly skill without any training data.
What’s new: Songhua Liu, Tianwei Lin, and colleagues at Baidu, Nanjing University, and Rutgers developed Paint Transformer, which learned to render pictures as paintings by reproducing paintings it generated randomly during training.
Key insight: A human painter generally starts with the background and adds details on top of it. A model can mimic this process by generating background strokes, generating further strokes over the top, and learning to reproduce these results. Dividing the resulting artwork into smaller pieces can enable the model to render finer details. Moreover, learning to reproduce randomly generated strokes is good training for reproducing non-random graphics like photos.
How it works: Paint Transformer paints eight strokes at a time. During training, it randomly generates an eight-stroke background and adds an eight-stroke foreground. Then it learns to minimize the difference between the background-plus-foreground image and its own work after adding eight strokes to the background.
- During training, separate convolutional neural networks generated representations of background and background-plus-foreground paintings.
- A transformer accepted the representations and computed the position, shape, and color of eight strokes required to minimize the difference between them.
- The transformer sent those parameters to a linear model, the stroke renderer, which transformed a generic image of a stroke accordingly and laid the strokes over the background.
- The system combined two loss terms: (a) the difference between the pixels in the randomly generated background-plus-foreground and the system’s output and (b) the difference between the randomly generated stroke parameters and those computed by the transformer.
- At inference, it minimized the difference between a photo and a blank canvas by adding eight strokes to the blank canvas. Then it divided the photo and canvas into quadrants and repeated the process for each quadrant, repeating the cycle four times. Finally, it assembled the output subdivisions into a finished painting.
Results: Qualitatively, Paint Transformer used fewer and bolder strokes than an optimization method, while a reinforcement learning approach produced output that looked overly similar to the input. Quantitatively, Paint Transformer trained faster than RL (3.79 hours versus 40 hours) and took less time at inference than either alternative (0.30 seconds versus 0.32 seconds for RL and 521.45 seconds for optimization).
Why it matters: The system learned to paint without seeing any existing paintings, eliminating the need for matched pairs of photos and paintings, never mind tens of thousands or millions of them. This kind of approach might bear fruit in art forms from photo editing to 3D modeling.
We’re thinking: Hook this thing up to a robot holding a brush! We want to see what its output looks like in oils or acrylics.
 |
AI Hubs Are Few and Far Between
A new study warns that the geographic concentration of AI in the United States is making the industry too insular.
What’s new: A report by the Brookings Institution documents the extent to which a few metropolitan areas dominate AI in the U.S., risking group-think, geographic bias, and other pitfalls.
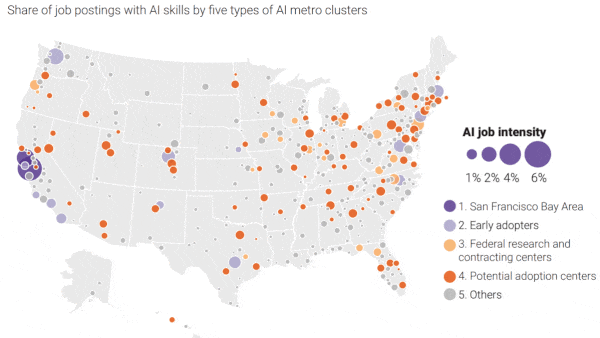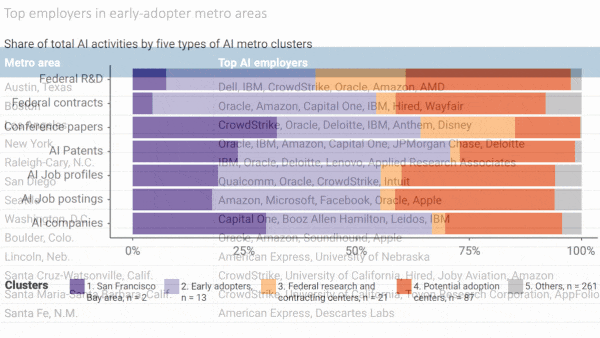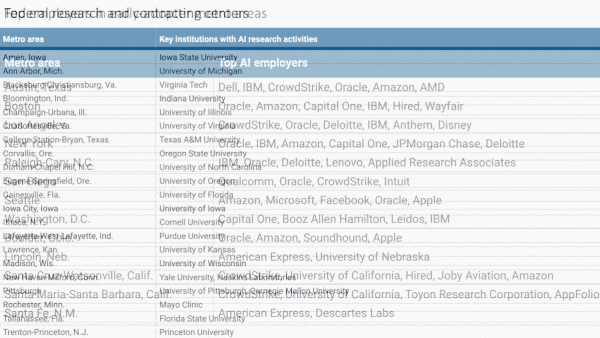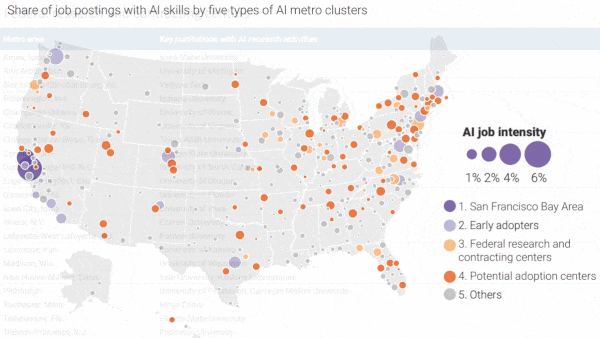
AI Hubs Actual and Potential: The report scores AI research and commercialization in 384 regions based on an analysis of federal grants, research papers, patent filings, job postings, and companies.
- The San Francisco Bay Area, which comprises San Francisco, Silicon Valley, and adjacent cities, is the undisputed AI capital in the U.S., accounting for one quarter of all papers, patents, and companies.
- A dozen-plus other cities including Austin, New York, and Seattle dominate the rest. Combined with the Bay Area, they make up two-thirds of the national AI industry.
- Another 21 cities host universities with strong AI programs, thanks largely to government funding. However, they lack commercial AI activity.
- The report also spotlights nearly 90 cities with high potential to commercialize AI. These areas are buoyed by startups such as Salt Lake City’s Recursion, a healthcare venture, and large, non-tech firms that are making big investments in automation such as Target in Minneapolis.
Behind the news: The Bay Area’s dominance in AI dates to the late 1950s, when the nascent semiconductor industry spawned what became the modern tech industry. Owing partly to this history, the region hosts a thriving ecosystem of universities, businesses, and financiers that focus on technological innovation.
Why it matters: AI’s lopsided geographic concentration not only undermines demographic and intellectual diversity, it “locks in a winner-take-most dimension to this sector,” Mark Muro, the study’s coauthor, told Wired. This imbalance between risk and reward highlights a need for policy and investment that promotes AI in other parts of the country, he said.
We’re thinking: Other industries are geographically concentrated; for instance entertainment, fashion, and finance. But AI has a special need for a diverse talent pool to ensure that the systems we build are fair and broadly beneficial.