
Dear friends,
Years ago, whenever I had to do something boring or unpleasant — such as drive to work or go for a run — I used to listen to music to provide a distraction. Although I still appreciate music, as I got older I decided to cut out distractions. As a result, I’m more likely to sit in silence and enjoy being alone with my thoughts, or use the time more purposefully to learn something from an online course or audio book.
Many people listen to music while studying or working. When is it helpful, and when is it distracting? People enjoy music — with good reason — and tend to have strong opinions about it. But some research shows that playing background music while trying to solve problems reduces creativity. Many people in the internet era are used to constant stimulation: scrolling of social media, consuming online news, filling empty hours with TV or video games. But finding quiet time when you can mull over your ideas remains an important part of being creative.
 |
To be fair, the findings of research into the effect of music on cognition are mixed. For example, music sometimes improves mood, which in turn leads to better cognitive performance. Music also can drown out background noise that otherwise would be even more distracting. But I’ve found that when working, driving, or exercising, I prefer not to have any distractions and am happy to be left with my own thoughts. Since I stopped listening to music while driving, I’ve noticed that I’m much more likely to end the drive with new ideas for things I want to do.
Does this mean you shouldn’t listen to music? Of course not. Listening to music for sheer pleasure is a worthy use of time as well. But now I use music for enjoyment rather than distraction.
In addition to listening, one of my favorite ways to take a break from work is to play a piano (not very well!), sometimes with my daughter Nova in my lap providing accompaniment via a random banging on the keys. This serves no utilitarian purpose, but it puts me (and her) in a good mood, and I certainly plan to keep up my efforts to play!
Keep learning,
Andrew 🎵
News
 |
How Facebook Fills the Feed
Facebook’s recommendation algorithm is a closely guarded secret. Newly leaked documents shed light on the company’s formula for prioritizing posts in an individual user’s feed.
What happened: The Washington Post analyzed internal documents and interviewed employees to show how the company’s weighting of emojis, videos, subject matter, and other factors have evolved in recent years. The Post’s analysis followed up on an earlier report by The Wall Street Journal.
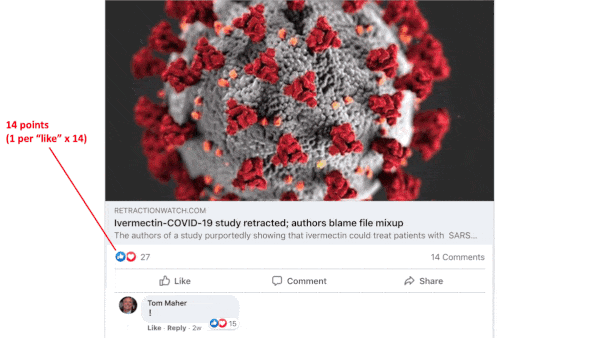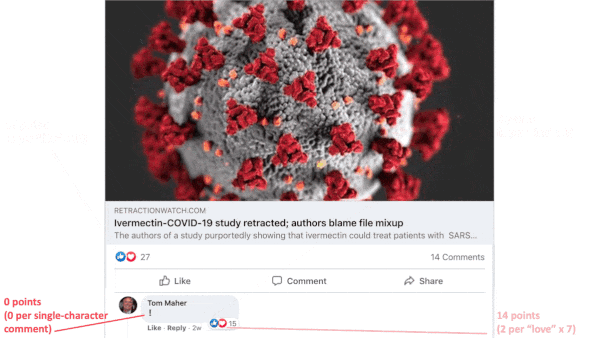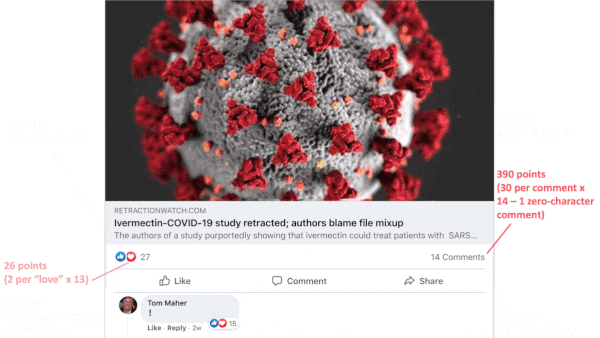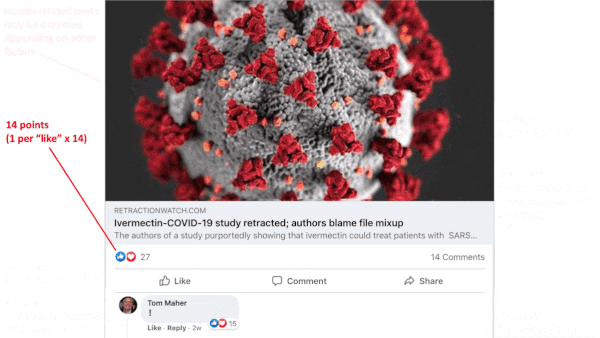
How it works: Facebook’s recommendation algorithm ranks posts for their likelihood to spur engagement according to more than 10,000 variables. Posts earn points for various attributes, and those with the highest score float to the top of a user’s newsfeed. The average post scores a few hundred points, but scores can reach 1 billion or more. Facebook is constantly adjusting the algorithm. The details below were drawn from past documents and may not reflect the current iteration:
- The algorithm awards points depending on the types of stories likely to spur shares and interactions (health and civic information may count for less as of spring 2020), whether video is included (live videos score higher than prerecorded clips), number of likes (1 point each), number of reaction emojis (0 to 2 points as of September 2020), number of reshares (5 points as of January 2018), number of text comments and their length (15 to 30 points as of January 2018, single-character comments don’t count). The algorithm also weighs the user’s friend list (comments by strangers count less), groups the user has joined, pages the user has liked, and advertisers that have targeted the user. In addition, it considers the post’s processing burden and the strength of the user’s internet signal.
- To limit the spread of posts the company deems harmful — for instance, those that include hateful messages or disinformation — the algorithm slashes their scores between 50 and 90 percent. But there’s no upper limit to the number of points a post can accrue, so this penalty has little effect on the rank of posts with extremely high scores.
- Until January 6, Facebook favored posts that include live video over other media types, weighting them up to 600 times more heavily than those with pre-recorded videos, photos, or text. The company capped the multiplier at 60 after the attack on the U.S. Capitol.
- Facebook introduced emoji reactions in 2017, including the angry emoji. The following year, internal research found that posts that elicited high numbers of angry emojis were more likely to include “civic low quality news, civic misinfo, civic toxicity, health misinfo, and health antivax content.” Reducing its weight limited the spread of such content, and surveys showed that users didn’t like to see it attached to their posts. Recently the company cut its value to zero.
Turning points: Early on, Facebook’s recommendation algorithm prioritized updates from friends, such as a new photo or change in relationship status. In the early 2010s, the company tweaked it to favor likes and clicks. To counteract the resulting flood of clickbait, it was adjusted to promote posts from professional news media. In 2018, the company made changes to promote interaction between users by favoring reaction emojis, long comments, and reshares. This shift displayed more posts from friends and family but led to a surge of divisive content, prompting new rounds of changes in recent months.
Why it matters: Facebook’s membership of nearly 3 billion monthly active users famously exceeds the populations of the largest countries. What information it distributes, and to whom, has consequences that span personal, national, and global spheres. Both users and watchdogs need to understand how the company decides what to promote and what to suppress. Revealing all the details would invite people to game the algorithm, but some degree of transparency is necessary to avoid dire impacts including suicides and pogroms.
We’re thinking: Internet companies routinely experiment with new features to understand how they contribute to their business. But Facebook’s own research told the company that what was good for its bottom line was poisonous for society. The company hasn’t been able to strike a healthy balance on its own. As a society, we need to figure out an appropriate way to regulate social media.
 |
Competition Heats Up in Mobile AI
Google designed its own AI chip for its new smartphone — a snub to Qualcomm, the dominant chip vendor in Android phones.
What’s new: Google debuted the Tensor chip last week along with the global release of the new Pixel 6 smartphones. Company executives say the chip is well over four times faster than Qualcomm’s Snapdragon 765G in the Pixel 5, released last year.
How it works: Tensor serves as a power-efficient AI inference engine for on-device functions like voice transcription, language translation, and some image processing features.
- The chip combines a GPU, CPU, image signal processor, and Tensor processing unit — the proprietary hardware that drives machine learning in Google’s cloud. It also includes a security subsystem that manages encryption and thwarts many types of hardware attack.
- In a demonstration for The Verge, Google snapped a photo of a toddler in motion. The camera automatically shot several photos, recognized the child’s face in each one, and combined them, rendering the face free of motion blur.
- Google also showed off the chip’s language capabilities, transcribing video voice-overs in real time with no internet connection. In one case, it simultaneously translated a French voice-over into English captions.
Behind the news: Qualcomm’s Snapdragon line of processors underpinned the earliest smartphones from Apple, Blackberry, and a wide variety of Android producers, including Pixel. Google's move to design its own chips mimics Apple's decision to do the same over a decade ago. Both companies continue to use Qualcomm chips for cellular communications.
Why It Matters: Advances in chip design and manufacturing are enticing companies with special processing needs to roll their own. Google tailored Tensor to suit its own AI technology while cutting its dependence on an outside supplier. That’s sure to help it make distinctive products. Look for more of the same from makers of all kinds of AI hardware.
We’re thinking: Google controls the Android operating system. The more tightly it binds Tensor and Android, the greater the incentive it has to sell the chip to phone markers, and the harder it will be for Qualcomm and others to compete on performing inference in Android phones.
A MESSAGE FROM DEEPLEARNING.AI
 |
Have you checked out the updated Natural Language Processing Specialization? Courses 3 and 4 now cover state-of-the-art techniques with new and refreshed lectures and labs! Enroll now
 |
Richer Video Representations
To understand a movie scene, viewers often must remember or infer previous events and extrapolate potential consequences. New work improved a model’s ability to do the same.
What's new: Rowan Zellers and colleagues at University of Washington developed Multimodal Event Representation Learning Over Time (MERLOT), a pretraining method that concentrates knowledge gleaned from videos without requiring labeled data. The resulting representations helped fine-tuned models perform a variety of video-reasoning tasks with state-of-the-art accuracy.
Key insight: Earlier work generated representations of videos by learning either to match video frames with associated text or to re-order scrambled frames in their original sequence. Training on both tasks can enable a model to generate richer representations that integrate visual, linguistic, and temporal information.
How it works: The authors divided six million YouTube videos into 180 million individual frames, each paired with corresponding text from a transcript.
- During pretraining, a ResNet-50 (the image encoder in the illustration above) generated an initial representation of each frame.
- A transformer (the language-only encoder) produced a representation of the associated text (taking into account the entire transcript up to that point).
- In contrastive fashion, the loss function encouraged matching frame and text representations to be similar and mismatches to be dissimilar.
- Another transformer received each frame representation and its corresponding text (not the text representation). It learned to guess masked words in the text as well as the proper order of the frames.
Results: MERLOT set a new state of the art for 14 tasks that involved answering questions about individual frames, answering questions about sequences of frames, and ordering disordered frames. It did especially well on question-answering tasks designed to test spatial and temporal reasoning on GIFs from Tumblr. For instance, MERLOT answered multiple-choice questions about the action performed in a clip with 94.0 percent accuracy versus the previous best score of 82.8 percent accuracy. In other areas, the improvement was less dramatic. For example, on Drama-QA, it answered multiple-choice questions about the story in clips from a TV show with 81.4 percent accuracy versus the previous best score of 81.0 accuracy.
Why it matters: MERLOT learned to pack a range of essential information about video images, accompanying text, and frame order into the representations it generated. The world is swimming in unlabeled video-plus-audio, and self-supervised learning algorithms like this could unlock tremendous value from such data.
We're thinking: We’re glad the authors didn’t keep this work bottled up.
 |
Seeing Through Forgeries
Accusations of fraud hang over some of the world’s most highly valued artworks. Machine learning engineers are evaluating the authenticity of these famous pieces.
What’s new: Independent researchers determined that Salvator Mundi, the most expensive painting ever sold, was not painted entirely by Renaissance master Leonardo da Vinci, as had been claimed. In addition, the Swiss authentication company Art Recognition found that Samson and Delilah, a work credited to Peter Paul Rubens that hangs in London’s National Gallery, probably was painted by someone else.
How it works: Da Vinci produced few paintings, and he was also known to enlist assistants to help with his projects. Because of this, independent researchers Andrea and Steven Frank had just 12 verified da Vincis to train and test their system.
- The team augmented the dataset by dividing each painting into hundreds of overlapping slices of 350x350 pixels. They filtered the slices so that only those whose entropy, roughly indicating the amount of non-redundant information, was greater than average. They gathered similar slices of 33 paintings by other artists for a total of 17,520 training images and trained a convolutional neural network to classify whether or not a slice was painted by da Vinci.
- After training the CNN, they trained a linear model to decide, based on the CNN’s classifications of slices, whether a given painting was created by da Vinci. The system accurately determined that Seated Bacchus, a painting once thought to have been painted by da Vinci but now attributed to a protégé, was not the master’s work.
- By taking into account the classification of each slice of a given painting and their overlap, the researchers created heatmaps that showed areas most (shaded red) and least (shaded blue) likely to have been painted by da Vinci. This analysis showed that Leonardo da Vinci likely did not paint Salvator Mundi’s background or the figure’s raised right hand, but did paint its face and some of its body.
- Art Recognition, whose method appears to work in a similar way based on an unpublished description they provided to The Batch, trained its system on a mixture of 2,392 image segments drawn from works by Rubens and other artists. It determined with 91.78 percent accuracy that Samson and Delilah was not painted by Rubens.
Behind the news: Salvator Mundi was painted in the early 1500s and thought destroyed around a century later. The heavily damaged painting resurfaced in London in 1948. Experts there determined it was painted by one of da Vinci’s pupils, and it sold at auction for less than $50. After another sale, for $10,000 in 2005, evidence obtained during restoration convinced experts that it was an authentic da Vinci. It sold at auction for $450 million in 2017.
Why it matters: Fine art is a big business, and so is art fraud. Human experts often disagree in their assessments — and it may be impossible to establish the provenance of some works with complete certainty — but neural networks can supplement their judgments.
We’re thinking: If a human and a neural network disagreed about who created a picture, we’d just call it a draw.