
Dear friends,
In this series exploring why machine learning projects fail, let’s examine the challenge of “small data.”
Given 1 million labeled images, many teams can build a good classifier using open source. But say you are building a visual inspection system for a factory to detect scratches on smartphones. No smartphone manufacturer has made 1 million scratched phones (that would have to be thrown away), so a dataset of 1 million images of scratched phones does not exist. Getting good performance with 100 or even 10 images is needed for this application.
Deep learning has seen tremendous adoption in consumer internet companies with a huge number of users and thus big data, but for it to break into other industries where dataset sizes are smaller, we now need better techniques for small data.
In the manufacturing system described above, the absolute number of examples was small. But the problem of small data also arises when the dataset in aggregate is large, but the frequency of specific important classes is low.
Say you are building an X-ray diagnosis system trained on 100,000 total images. If there are few examples of hernia in the training set, then the algorithm can obtain high training- and test-set accuracy, but still do poorly on cases of hernia.
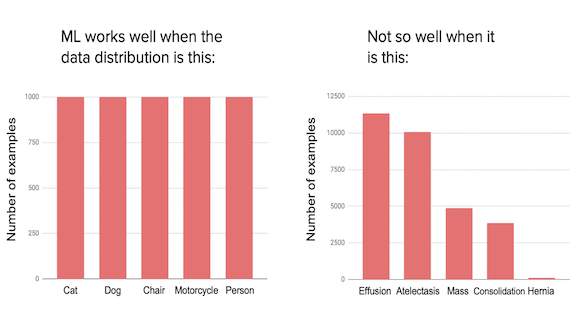
Small data (also called low data) problems are hard because most learning algorithms optimize a cost function that is an average over the training examples. As a result, the algorithm gives low aggregate weight to rare classes and under-performs on them. Giving 1,000 times higher weight to examples from very rare classes does not work, as it introduces excessive variance.
We see this in self-driving cars as well. We would like to detect pedestrians reliably even when their appearance (say, holding an umbrella while pushing a stroller) has low frequency in the training set. We have huge datasets for self-driving, but getting good performance on important but rare cases continues to be challenging.
How do we address small data? We are still in the early days of building small data algorithms, but some approaches include:
- Transfer learning, in which we learn from a related task and transfer knowledge over. This includes variations on self-supervised learning, in which the related tasks can be “made up” from cheap unlabeled data.
- One- or few-shot learning, in which we (meta-)learn from many related tasks with small training sets in the hope of doing well on the problem of interest. You can find an example of one-shot learning in the Deep Learning Specialization.
- Relying on hand-coded knowledge, for example through designing more complex ML pipelines. An AI system has two major sources of knowledge: (i) data and (ii) prior knowledge encoded by the engineering team. If we have small data, then we may need to encode more prior knowledge.
- Data augmentation and data synthesis.
Benchmarks help drive progress, so I urge the development of small data benchmarks in multiple domains. When the training set is small, ML performance is more variable, so such benchmarks must allow researchers to average over a large number of small datasets to obtain statistically meaningful measures of progress.
My teams are working on novel small data techniques, so I hope to have details to share in the future.
Keep learning!
Andrew
News

Blind Spot
In March 2018, one of Uber’s self-driving cars became the first autonomous vehicle reported to have killed a pedestrian. A new report by U.S. authorities suggests that the accident occurred because the car’s software was programmed to ignore jaywalkers.
What happened: The National Transportation Safety Board released the results of an investigation into Uber’s self-driving AI. According to the agency’s analysis, the model failed to classify the victim properly because she wasn’t near a crosswalk — a feature the model used to classify pedestrians in the road.
What the report says: The vehicle’s computer log in the moments leading up to the crash highlights a number of flaws in the system:
- The vehicle’s radar first picked up the victim 5.6 seconds before impact. The self-driving Volvo SUV was in the far right lane, while the pedestrian was walking her bicycle across the street from the left. The system classified her as a vehicle but didn’t recognize that she was moving.
- The lidar pinged the victim repeatedly over the next several seconds. The system assigned various classifications — car, bicycle, “other” — but it didn’t associate one classification with the next. It reset the tracking system each time and thus didn’t recognize that she was moving into the car’s path.
- 1.5 seconds before impact, the victim was partially in the SUV’s lane, so the system generated a plan to swerve around the obstacle, which it considered to be unmoving.
- A few milliseconds later, the lidar identified her as a moving bicycle on a collision course. It abandoned its previous plan, since that didn’t account for the bicycle’s motion.
- Uber’s developers had previously disabled the system’s emergency steering and braking systems because they were known to behave erratically. Instead, the vehicle began to decelerate gradually. 1.2 seconds before impact, the car was moving at 40 miles per hour.
- One second later, the self-driving system alerted its human safety driver that it had initiated a controlled slowdown. The safety driver grabbed the wheel, disengaging the self-driving system. The SUV struck the victim, and the driver slammed on the brakes.
Aftermath: Immediately after the accident, Uber took its autonomous test vehicles off the road. The victim’s family sued the company and settled out of court. Uber has since resumed self-driving tests in Pittsburgh (issuing a safety-oriented promotional video, excerpted above, to mark the occasion). Responding to the NTSB report, Uber issued a statement saying the company “has adopted critical program improvements to further prioritize safety” and “look[s] forward to reviewing their recommendations.”
Why it matters: Next week, the NTSB will hold a hearing where it will announce its judgment of Uber’s role in the accident. Federal legislators and state authorities will be watching these hearings, which are likely to bring forth a number of recommendations on ways to ensure the self-driving car industry is operating safely.
We’re thinking: Government oversight is critical for progress on autonomous vehicles, both to hold companies accountable for safety and to ensure that safety information is widely disseminated. Regulation has made safety a given in commercial aviation; airlines compete on routes, pricing, and service, not how safe they are. Similarly, the autonomous vehicle industry’s commitment to safety is something that consumers should be able to take for granted. And, while we’re at it, let’s build sensible rules for testing AI in other critical contexts such as health care, education, and criminal justice.

Spotlight on Stock Scammers
The world’s largest stock market is using AI to flag suspicious trading in real time.
What’s new: Nasdaq is testing a deep learning system to monitor trading of its U.S. equities. Named Chiron, the system watches for behaviors that indicate potential market manipulation.
How it works: Nasdaq will spend a year training Chiron on trade data annotated for signs of manipulation.
- The system is designed to alert human overseers when it sees patterns that suggest scams such as spoofing, in which a trader attempts to devalue a stock by selling a huge volume to trigger others to dump their shares as well.
- Nasdaq’s fraud-detection team reviews around 750,000 trades annually. The system is intended to reduce false positives so the team can focus on serious cases.
- The company aims to integrate Chiron with its broader SMARTS trade surveillance program, which watches the markets using human analysts and traditional computing.
Behind the news: This isn’t Nasdaq’s first foray into AI. In 2001, the company launched a program called Sonar to monitor sources like news stories and SEC filings for suspicious activity.
Why it matters: Nasdaq operates 29 exchanges in the U.S., Canada, UK, and EU, and it licenses its surveillance technology to other exchanges, regulatory agencies, and financial firms around the world. It has the highest volume of trades of any exchange in the world. Widespread fraud within Nasdaq’s network not only would be catastrophic for its business, it could send shock waves through the global economy.
We’re thinking: Fraudsters have access to deep learning, too. Expect a high-stakes game of cat and mouse in the years to come.
Finer Tuning
A word-embedding model typically learns vector representations from a large, general-purpose corpus like Google News. But to make the resulting vectors useful in a specialized domain, such as veterinary medicine, they must be fine-tuned on a smaller, domain-specific dataset. Researchers from Facebook AI offer a more accurate method.
What’s new: Rather than fine-tuning, Piotr Bojanowski and colleagues developed a model that aligns word vectors learned from general and specialized corpora.
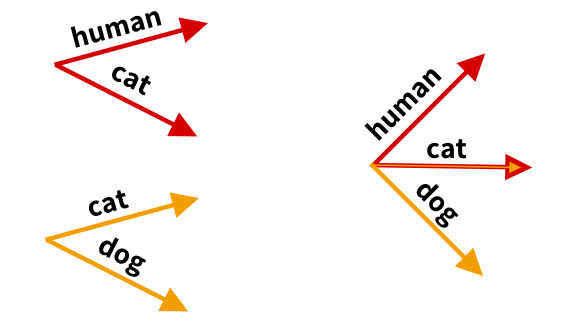
Key insight: The authors drew inspiration from the way multilingual word vectors are learned. They treated general-purpose and domain-specific corpora as separate languages and used a word-embedding model to learn independent vectors from each. Then they aligned the vectors from one corpus with those from another.
How it works: To align word vectors from two corpora, common words are used to find a consistent way to represent all words. For example, if one corpus is {human,cat} and the other is {cat,dog}, the model applies a transformation that unifies the dog word vectors while retaining the relative positions of the word vectors between cats, dogs, and humans.
- A word-embedding model learns independent word vectors from both corpora.
- For words that appear in both corpora, the alignment model learns a linear mapping from general-purpose vectors to domain-specific vectors. The mapping solves a linear equation that minimizes the distance between the general-purpose vectors and the domain-specific vectors.
- The authors use a loss function called RCSLS for training. RCSLS balances two objectives: General-purpose vectors that are close together remain close together, while general-purpose vectors that are far apart remain far apart.
- Common words in the two corpora now have duplicate vectors. Averaging them produces a single vector representation.
Results: The authors tested this approach to learning word vectors on tasks that include predicting analogies and text classification in a dataset where the test set has a slightly different word usage than the training set. Models that use word vectors learned via alignment outperformed those that use word vectors fine-tuned in the usual way. The new method’s advantage was more pronounced when the domain-specific dataset was relatively small.
Why it matters: Machine learning engineers need tools that enable existing word representations to capture specialized knowledge. The alignment technique could be a boon in any situation where general-purpose word vectors don’t capture the meanings at play.
We’re thinking: Open-source, pretrained word embeddings have been a boon to NLP systems. It would be great to have freely available word embeddings that captured knowledge from diverse fields like biology, law, and architecture.
A MESSAGE FROM DEEPLEARNING.AI

How do you find good values for hyperparameters? Learn how to organize your hyperparameter tuning process in Course 2 of the Deep Learning Specialization. Enroll now
Survival of the Overfittest
Neuroevolution, which combines neural networks with ideas drawn from Darwin, is gaining momentum. Its advocates claim that they can achieve faster, better results by generating a succession of new models, each slightly different than its predecessors, rather than relying on a purpose-built model.
What’s new: Evolutionary strategies racked up a number of successes in the past year. They contributed to DeepMind’s AlphaStar, which can beat 99.8 percent of players of StarCraft 2, and to models that bested human experts in the videogames Montezuma’s Revenge and Pitfall Harry. An article in Quanta surveys the field, focusing on neuroevolution pioneer and Uber senior researcher Kenneth Stanley.
How it works: Traditionally, evolutionary approaches have been used to generate algorithms that solve a specific problem or perform best on a particular task. The best solutions are randomly mutated to find variations that improve performance. Neuroevolution applies random mutations to neural network weights and sometimes activation functions, hyperparameters, or architectures. Good models emerge over many iterations, sometimes crossing traits among many behavioral niches.
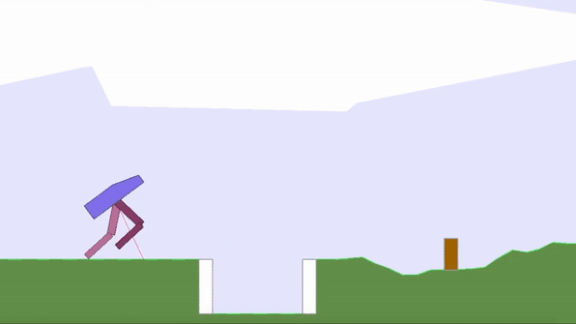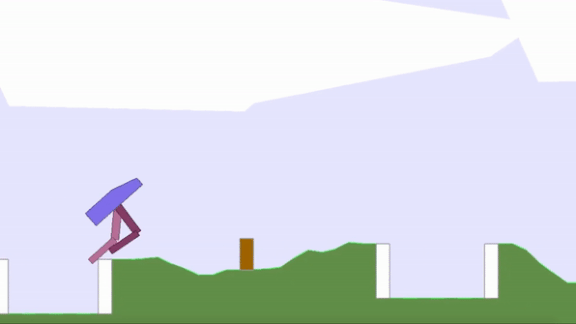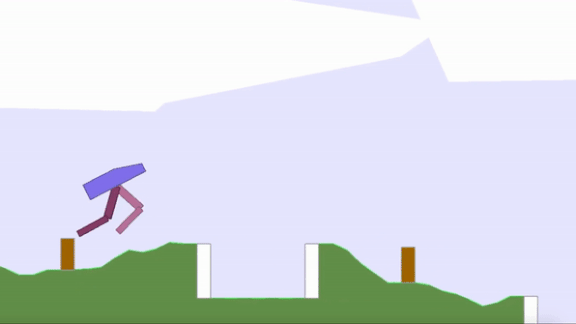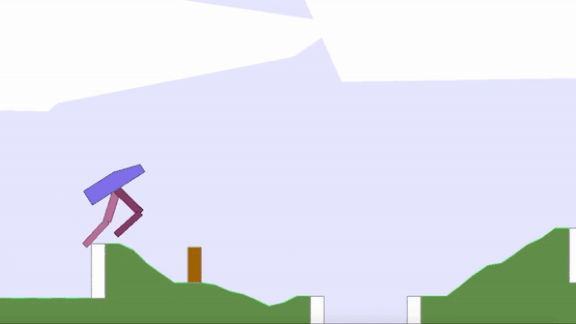
- Uber AI Labs developed an algorithm called Paired Open-Ended Trailblazer and used it to evolve populations of virtual bipedal robots as well as obstacle courses for the robots to master (shown in the animation above). As the bots learned how to walk over, say, hills, the algorithm randomly moves them to environments where they encountered trenches. Agent-obstacle pairs are mutated, ranked for fitness and novelty, and then interbred. Ultimately, the agents learn skills they couldn’t learn through direct optimization.
- DeepMind used evolutionary techniques along with deep learning and reinforcement learning to sharpen AlphaStart’s StarCraft 2 skills. The researchers bred models not to defeat one another outright but to employ off-kilter tactics and exploit weak points encountered in previous matches. The resulting model proved to be robust against a wide variety of strategies.
Yes, but: Evolutionary strategies require huge amounts of computation, even by the power-hungry standards of deep learning. Weights and other variables evolve randomly, so finding good models can take a long time. The random path itself is a drawback. Although researchers may set out to solve one problem, the evolutionary process may lead in other directions before wending its way back to the intended path — if it ever does.
Why it matters: Neuroevolution is a radical departure from typical neural networks and, by some accounts, a useful complement. Evolutionary approaches assign a far larger role to randomness, and randomly beneficial effects can compound over generations to find solutions or generate networks more effective than a human would have designed.
We’re thinking: Randomized search algorithms are a powerful approach to optimization, but their relation to biological evolution has been a subject of debate. With rising computational power and more complex challenges, such algorithms — whether evolutionary or not — may be poised to grow.

Fish Recognition
A deep learning system is helping biologists who survey offshore fish populations to prevent overfishing.
What’s new: The U.S. agency in charge of protecting ocean resources is using an underwater camera and neural network to count fish in real time.
How it works: Alaska’s walleye pollock fishery is America’s largest by volume. (You may not recognize a walleye pollock, but you’ve probably eaten one in fish sticks, fast-food sandwiches, or imitation crab meat. They are delicious!) Scientists with the U.S. National Oceanic and Atmospheric Administration chose this fishery as a pilot in their automatic fish-identification program.
- NOAA scientists dragged a long, funnel-shaped net through the water. Fish caught in the wide mouth are allowed to escape through the narrow, open end, passing in front of a stereoscopic CamTrawl camera system as they exit.
- Next to CamTrawl, a computer in a hermetically-sealed container runs a fish-recognition network called Viame. This video shows the user interface in action.
- The biologists do more than count fish. They also need to know the fishes’ average age to calculate a healthy number for fishermen to catch. Viame triangulates each specimen’s length, a reliable indicator of its age.
- NOAA is also using Viame to count scallops, reef fish, and endangered seals.
Behind the news: Congress passed the Sustainable Fisheries Act in 1996, requiring NOAA to track U.S. commercial fish populations. For some fisheries, the biologists venture out on boats, casting nets to capture samples of what’s in the water. They dump the contents onto the deck, count and measure each creature, release the haul, and cast the net again. NOAA launched the initiative to automate these counts using artificial intelligence in 2014.
Why it matters: Fish stock assessments, and the limits they impose on commercial fishing, keep fish populations sustainable and fisheries productive over the long term. Automating the process reduces error and frees up biologists for other work.
We’re thinking: Deep learning is producing more and better data for environmental stewardship. It’s up to citizens to put that data to best use.
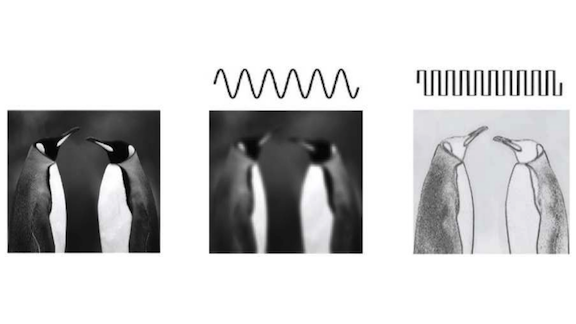
Convolution Revolution
Looking at images, people see outlines before the details within them. A replacement for the traditional convolutional layer decomposes images based on this distinction between coarse and fine features.
What’s new: Researchers at Facebook AI, National University of Singapore, and Yitu Technology devised OctConv, a convolutional filter that reduces the computational cost and memory footprint of image processing networks without degrading performance.
Key insight: Yunpeng Chen and collaborators took their inspiration from signal processing: An audio signal can be represented as a set of discrete frequencies rather than a single waveform. Similarly, an image can be said to contain low-frequency information that doesn’t change much across space and high-frequency imagery that does. Low-frequency image features are shapes, while high-frequency image features comprise details such as textures. By capturing them separately, OctConv can reduce redundant information.
How it works: The outputs of a convolutional layer’s hidden units are feature maps that hold 2D spatial information. Feature maps often encode redundant information across an image’s color channels. OctConv cuts this redundancy by using a frequency-channel representation instead of the usual color-channel representation.
- In OctConv, each channel of a convolutional layer encodes either low- or high-frequency data. Low-frequency channels downsample the feature map, while high-frequency channels retain the feature map’s original resolution. A user-defined parameter controls the ratio of low- to high-frequency channels.
- Separate resolution filters share information between high- and low-frequency channels. Four filters account for all combinations of the channel inputs and outputs. While this arrangement may appear to require four times as many parameters as a standard convolutional layer, low-frequency channels have 50 percent resolution, resulting in fewer total parameters.
Results: A ResNet-152 with OctConv rather than CNN filters was 0.2 percent more accurate on ImageNet than the next best model, with 15 percent less computation during testing. An I3D model pair with OctConv filters was 2 percent more accurate on Kinetics-600, a video dataset for predicting human actions, with 10 percent less computation.
Why it matters: OctConv filters can substitute for standard convolutional filters for better performance, reduced computation, and smaller footprint. The authors suggest subdividing beyond their low- and high-frequency scheme. That would yield greater savings in size and training time, but its impact on performance is a subject for further experimentation.
Takeaway: Memory compression and pruning techniques have been important for deploying neural networks on smartphones and other low-powered, low-memory devices. OctConv is a fresh approach to shrinking image-processing networks that takes into account memory and computation primitives.