
Dear friends,
Last week, DeepLearning.AI invited a group of learners to our Palo Alto office’s courtyard. We had a good time chatting about paths into AI, career trajectories, applications people were working on, and challenges they were facing. You can see the group below.
A few people mentioned the challenge of persuading others to try a machine learning solution. Even at leading tech companies, it’s not uncommon for someone to say, “Yes, machine learning may work well for other applications, but for what we’re doing, non-learning software works fine.”
Still, machine learning might work better. If you believe that a learning algorithm can help optimize server allocations, improve product recommendations, or automate some part of a business process, how can you push your idea forward?
 |
Here are some tips that have worked for me:
- Ask everyone who would be affected for their perspective, and share yours with them. AI projects can be complex, and many things can go wrong. Colleagues can alert you to issues you’ll need to address, such as difficulty gathering data, complexity of software integration, the need to reorganize workflows, how to manage the occasional incorrect prediction, as well as safety, fairness, and regulatory concerns.
- Bring evidence that a machine learning system could work. You might build a quick proof of concept. Or you might find related work, either in the academic literature or reports of other companies, to persuade others that it could work for your organization, too.
- Bring in outside consultants, advisors, or speakers. Their expertise can help persuade your team. (True story: I’ve met several people who have asked their non-technical teammates to take the AI for Everyone course. They’ve found that things move forward more easily when everyone involved has a basic business understanding of AI).
- Find allies. One forward-thinking partner can make all the difference! Persuading the first person is usually the hardest part. The first can help you persuade the second, and together you can persuade the third.
Throughout this process, be open to learning that your idea isn’t sound after all or that it might need to change before it can be successful. I would guess that almost every successful AI application you read about in The Batch required someone to persuade others to give machine learning a shot.
Don’t let the skeptics shut you down. Don’t give up, keep pushing, and . . .
Keep learning!
Andrew
News
 |
Clues to the Secret Identity of Q
Machine learning algorithms may have unmasked the authors behind a sprawling conspiracy theory that has had a wide-ranging impact on U.S. politics.
What’s new: Two research teams analyzed social media posts to identify Q, the anonymous figure at the center of a U.S. right-wing political movement called QAnon, The New York Times reported. Inspired by Q’s claims that U.S. society is run by a Satanic cabal, QAnon members have committed acts of violence. Some U.S. politicians have expressed support for the movement.
CommuniQués: Q posted over three years starting on the website 4chan in October 2017 before migrating later that year to 8chan, which later shut down and relaunched as 8kun. Q stopped posting in December 2020.
Elements of style: Swiss text-analysis firm OrphAnalytics clustered Q’s posts to track changes in authorship over time.
- The analysts divided the posts into five time periods and concatenated posts from each period. Within each period, they split the text into sets of 7,500 characters.
- For each set, they computed a vector representation in which each value represented the frequency of a different three-character sequence, and they computed the distance between each pair of representations.
- Principal component analysis learned to represent each distance using a vector with two values, a measure of an author’s style. They graphed these two-value vectors as points, color-coded by time period.
- Points in the period between October 28, 2017, and December 1, 2017, when Q first appeared, formed a cluster. Later points formed a second cluster. The analysts concluded that two authors wrote most of the earlier posts, and a single author was responsible for the majority of later ones.
Meet the authors: Florian Cafiero and Jean-Baptiste Camps at École Nationale des Chartes built support vector machines (SVMs) to classify various authors as Q or not Q.
- The team collected public online writings — social media, message board posts, blogs, and published articles — attributed to 13 people with connections to QAnon.
- They divided the writings into sets of 1,000 words and trained a separate SVM on three-character sequences from each candidate’s work.
- At inference, they concatenated all Q posts in chronological order and classified words 1 through 1,000, 200 through 1200, and so on to detect changes over time. The most likely candidate was the one whose SVM outputted the highest result.
- The models’ output pointed to Paul Furber and Ron Watkins. Furber, a former 4chan moderator and technology journalist, wrote most of Q’s late-2017 posts on 4chan. Watkins, a son of 8kun’s owner, former site administrator, and current candidate for the U.S. House of Representatives in Arizona, wrote most of the posts after the migration to 8chan/8kun.
Yes, but: Both Furber and Watkins denied writing as Q to The New York Times.
Why it matters: QAnon’s claims have been debunked by numerous fact-checkers, yet a 2022 survey found that roughly one in five Americans agreed with at least some of them. The movement’s appeal rests partly on the belief that Q is an anonymous government operative with a high-level security clearance. Evidence that Q is a pair of internet-savvy civilians may steer believers toward more credible sources of information.
We’re thinking: Machine learning offers an evidence-based way to combat disinformation. To be credible, though, methods must be openly shared and subject to scrutiny. Kudos to these researchers for explaining their work.
 |
Colleague in the Machine
Your next coworker may be an algorithmic teammate with a virtual face.
What’s new: WorkFusion unveiled a line of AI tools that automate daily business tasks. One thing that sets them apart is the marketing pitch: Each has a fictitious persona including a name, face (and accompanying live-action video), and professional résumé.
How it works: WorkFusion offers a cadre of six systems it touts as virtual teammates. Each is dedicated to a role such as customer service coordinator and performs rote tasks such as entering data or extracting information from documents. At this point, their personas are superficial — they don’t affect a system’s operation, just the way it’s presented to potential customers.
- The algorithms are trained using seven years’ worth of data from WorkFusion’s prior robotic process automation software.
- As they work, they can ask a human worker for aid when facing unfamiliar tasks and improve themselves based on the response.
- The company accumulates information from various deployments and improves the algorithms using fusion learning, a variation on federated learning that enhances privacy and cuts bandwidth requirements by transmitting data distribution parameters rather than the data points themselves. In this way, one customer’s data is not shared, but all deployments benefit from the algorithm’s experience in aggregate.
Behind the news: WorkFusion’s virtual teammates are examples of robotic process automation (RPA), which automates office work by interacting with documents like spreadsheets and email. The RPA market is expected to grow 25 percent annually, reaching $7.5 billion by 2028.
- While most RPA software doesn’t rely on AI, vendors including WorkFusion and Thoughtful Automation take advantage of machine learning.
- RPA providers Tangentia and Digital Workforce also personify their products as digital workers.
Yes, but: Giving AI systems a persona raises the questions why a particular role was assigned to a particular sort of person and whether that persona reinforces undesirable social stereotypes. For instance, a 2019 United Nations report criticized voice assistants such as Amazon’s Alexa for using female voices as a default setting.
Why it matters: People already anthropomorphize cars, guitars, and Roombas. Wherever people and AI work together closely, it may make sense to humanize the technology with a name and face, a practice that’s already common in the chatbot biz. Just watch out for the uncanny valley — a creepy realm populated by unsettling, nearly-but-not-quite-human avatars.
We’re thinking: These virtual teammates are no match for HAL 9000, but we hope they’ll open the pod bay doors when you ask them to.
A MESSAGE FROM DEEPLEARNING.AI
 |
Develop practical skills to deploy your data science projects with the Practical Data Science Specialization! Learn how to overcome challenges at each step of the machine learning workflow using Amazon SageMaker. Enroll today
 |
The Global Landscape of AI Power
China is poised to become the dominant national power in AI, new research suggests.
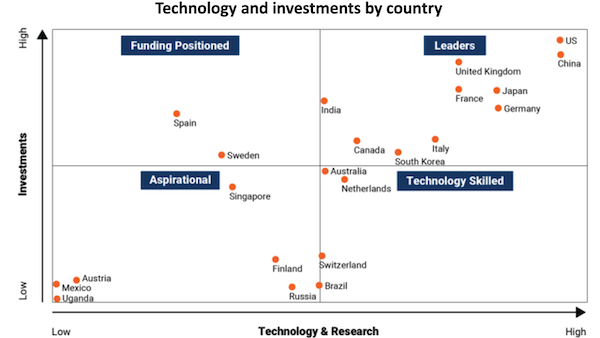
What’s new: The Brookings Institution, a nonprofit public-policy think tank, assessed which of 50 countries are best positioned to become AI powerhouses.
What they found: The analysts examined each country according to 10 data points including total processing power, number of top supercomputers, private and public investments in AI, and volumes of research publications and patent filings.
- The U.S. and China are clear leaders, according to the analysis. The U.S. excels in technology, but China’s much larger population portends future gains in engineering and research.
- The analysts ranked France, Germany, Japan, and the UK in the next group. They deemed the UK to have the highest potential to compete with China and the U.S.
- They assigned Canada, India, Italy, and South Korea to the next tier. Of these, India offers outstanding education but lacks technology, they concluded.
- The remaining countries lack competitive investments, technology, or both. This group includes relatively prosperous countries like Austria and Singapore as well as historically underdeveloped countries like Mexico and Uganda.
Behind the news: The new report adds to Brookings’ growing body of research into national AI postures. Last November, the organization concluded that Singapore, India, and Germany ranked highest in terms of AI talent due to high numbers of STEM graduates and tech workers already in the market. The previous month, it ranked the efforts of 44 nations to fulfill their AI aspirations, giving high marks to China, Germany, and India.
Why it matters: AI is an emerging arena for geopolitical competition. Understanding the global distribution of AI development and investment can help leaders make appropriate decisions and aspiring AI practitioners find sources of knowledge and employment.
We’re thinking: Many observers frame global competition in AI as a winner-take-all tournament. We believe there are great opportunities for international collaboration that would lift everyone.
-2.gif?upscale=true&width=1200&upscale=true&name=ezgif.com-gif-maker%20(5)-2.gif) |
Weather Forecast by GAN
A new deep learning technique increased the precision of short-term rainfall forecasts.
What's new: Suman Ravuri, Karel Lenc, Matthew Willson, and colleagues at DeepMind, UK Meteorological Office, University of Exeter, and University of Reading developed the Deep Generative Model of Radar (DGMR) to predict amounts of precipitation up to two hours in advance.
Key insight: State-of-the-art precipitation simulations struggle with short time scales and small distance scales. A generative adversarial network (GAN) can rapidly generate sequences of realistic images. Why not weather maps? A conditional GAN, which conditions its output on a specific input — say, previous weather history — could produce precipitation maps of future rainfall in short order.
How it works: Given a random input, a GAN learns to produce realistic output through competition between a discriminator that judges whether output is synthetic or real and a generator that aims to fool the discriminator. A conditional GAN works the same way but adds an input that conditions both the generator’s output and the discriminator’s judgment. The authors trained a conditional GAN, given radar images of cloud cover, to generate a series of precipitation maps that represent future rainfall.
- The generator took as input four consecutive radar observations recorded at five-minute intervals in the UK between 2016 and 2019. It used a series of convolutional layers to generate a representation of each and concatenated the representations. Given these observations and a random vector, a series of convGRU blocks (a type of convolutional recurrent neural network block) generated 18 grids that represented a 90-minute sequence of predicted precipitation per square kilometer.
- Two discriminators evaluated the generator’s output. A spatial discriminator made up of a convolutional neural network randomly selected eight of the 18 generated maps (for the sake of memory efficiency) and decided whether they were real. A temporal discriminator used 3D convolutions to process the 18 generated maps concatenated with the four input maps. Then it decided whether the generated sequence was real.
- In addition to the comparative loss terms, the discriminators used a loss term that encouraged the generator to minimize the difference, in each grid square, between real radar measurements and the average of six generated maps. This loss term increased the output resolution.
- At inference, the authors ran the generator multiple times and averaged the outputs. They used the variance to estimate uncertainty (for instance, a 20 percent chance of rain).
Results: The authors tested their approach at multiple time intervals and distance scales according to the continuous ranked probability score, a modified version of mean average error in which lower is better. Its output was on par with or slightly more accurate than that of the next-best competitor, Pysteps. Of 56 meteorologists who compared the generated and ground-truth precipitation maps, roughly 90 percent found that the authors’ predictions had higher “accuracy and value” than the Pysteps output with respect to medium and heavy rain events.
Why it matters: GANs can produce realistic images whether they’re cat photos or precipitation maps. A conditional GAN can turn that capability into a window on the future. Moreover, by averaging multiple attempts by the conditional GAN, it’s possible to compute the certainty of a given outcome.
We're thinking: Predicting the weather isn’t just hard, it’s variably hard — it’s far harder at certain times than at others. An ensemble approach like this can help to figure out whether the atmosphere is in a more- or less-predictable state.