
Dear friends,
AI Fund, the venture studio and investment firm that I lead, recently held a summit where CEOs and founders of portfolio companies shared ideas on topics from fundraising to building team culture. I was struck by how frequently startup leaders have to do things they have no expertise in.
As AI developers, every time we build a machine learning application, we might choose a neural network architecture, tune a dataset, train a model, evaluate its performance, and consider the outcome to decide what to try next. The rapid iteration cycle means we can try many combinations in a given project. Over many projects, we hone our intuitions about what works. The quick feedback and opportunity to improve are among the things that makes machine learning fun!
In contrast, hardly anyone starts 100 companies even in a long career. No one raises seed funding, builds a company culture, hires a vice president of sales, or makes an initial public offering very many times. Thus few people can become experts at performing these tasks through repeated practice.

That’s why I believe that the smartest startup leaders know when they need help and understand that no single person can do it all. A community of peers, each of whom has raised funding once or twice, can pool ideas and achieve better results than the typical individual. Similarly a recruiter who has hired 100 sales executives is likely to have valuable insights that someone who has done it only once or twice won’t.
Although software development allows for repeated practice, we, too, often have to do things we don’t have much experience with, because technology keeps evolving. Someone may find themselves, for the first time, deploying a real-time machine learning system, compressing a neural network to run on a low-power edge device, or calculating the return on investment in an AI project. In situations like this we, too, are stronger as a community. We can benefit from the experience of our peers who have completed the task and know something about how to go about it.
When I was younger I believed that, if only I worked and studied a bit harder, I could figure almost anything out. That attitude worked well enough for a while, but the more experience I gain, the more I realize that I need help from others. I’m grateful to the many people who have given me advice over the years, and I hope that the AI community can be a place where all of us can collaborate and support one another.
Keep learning!
Andrew
News
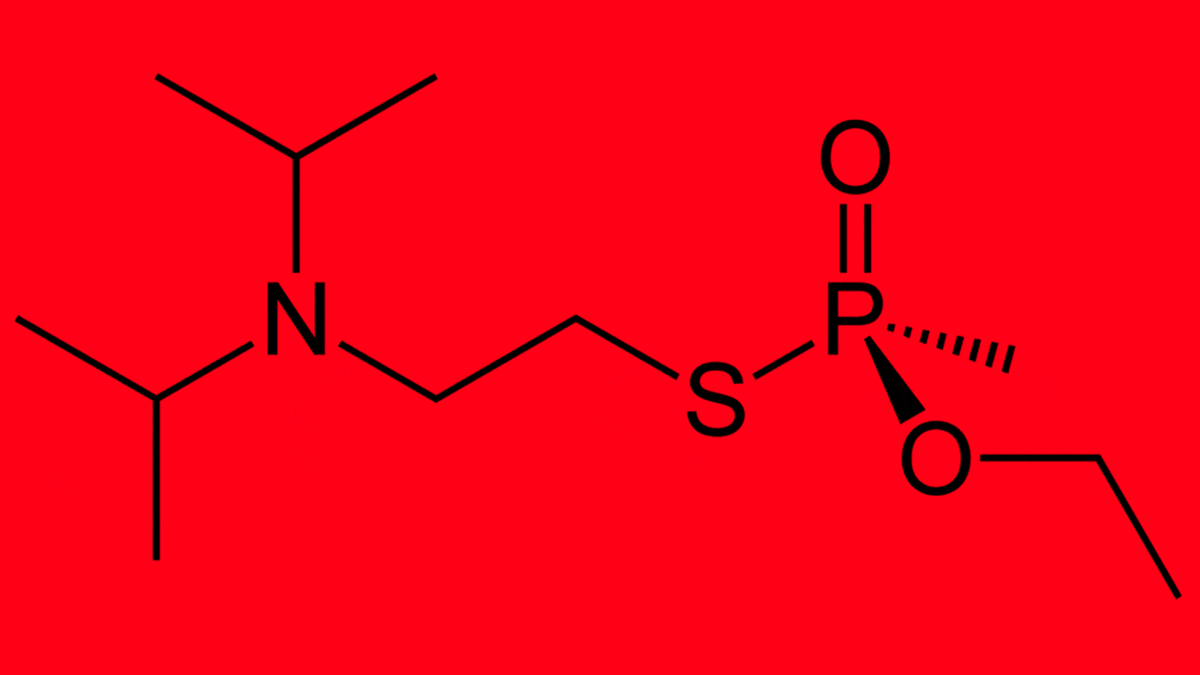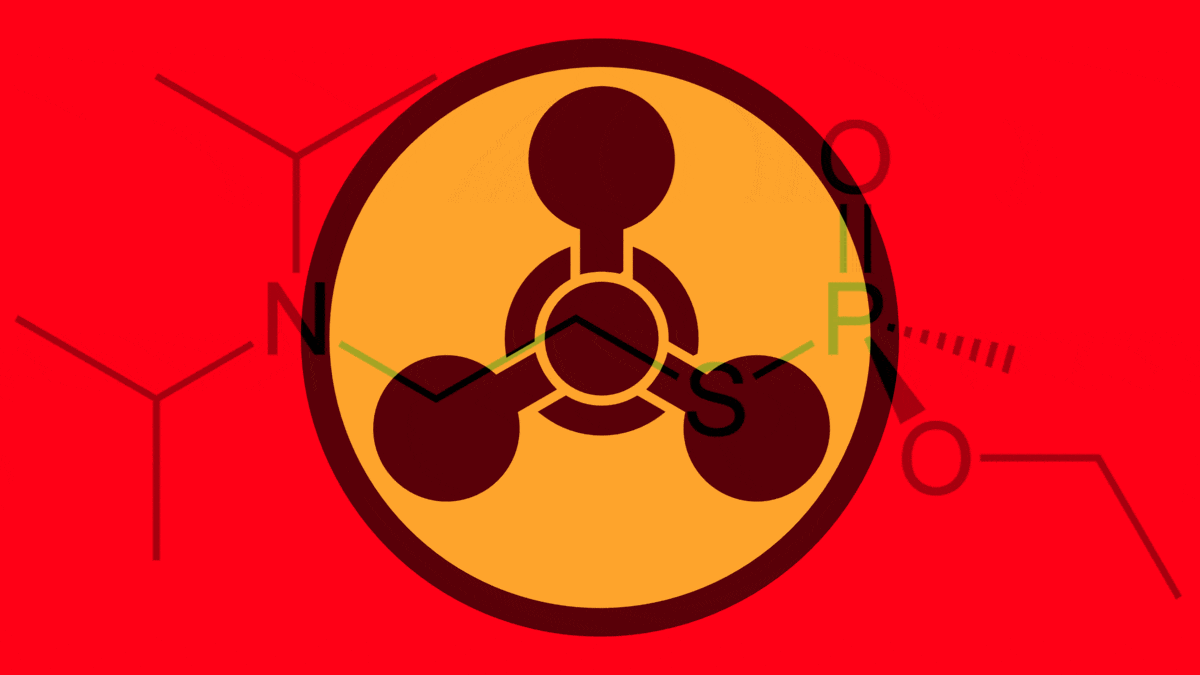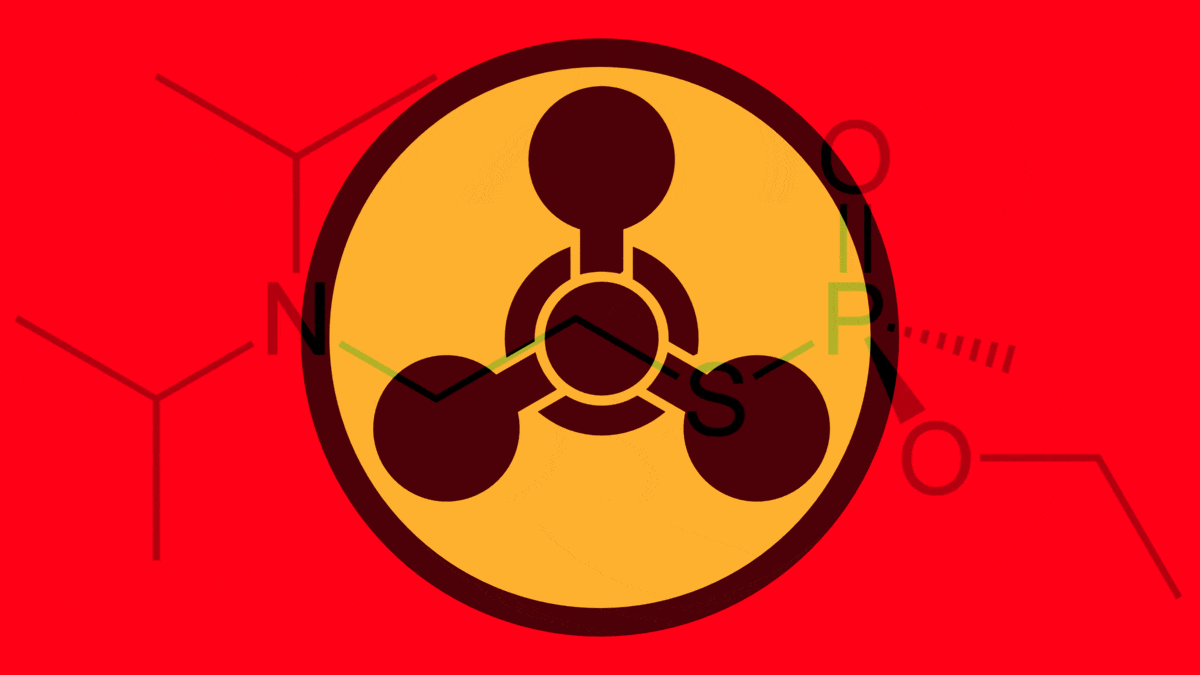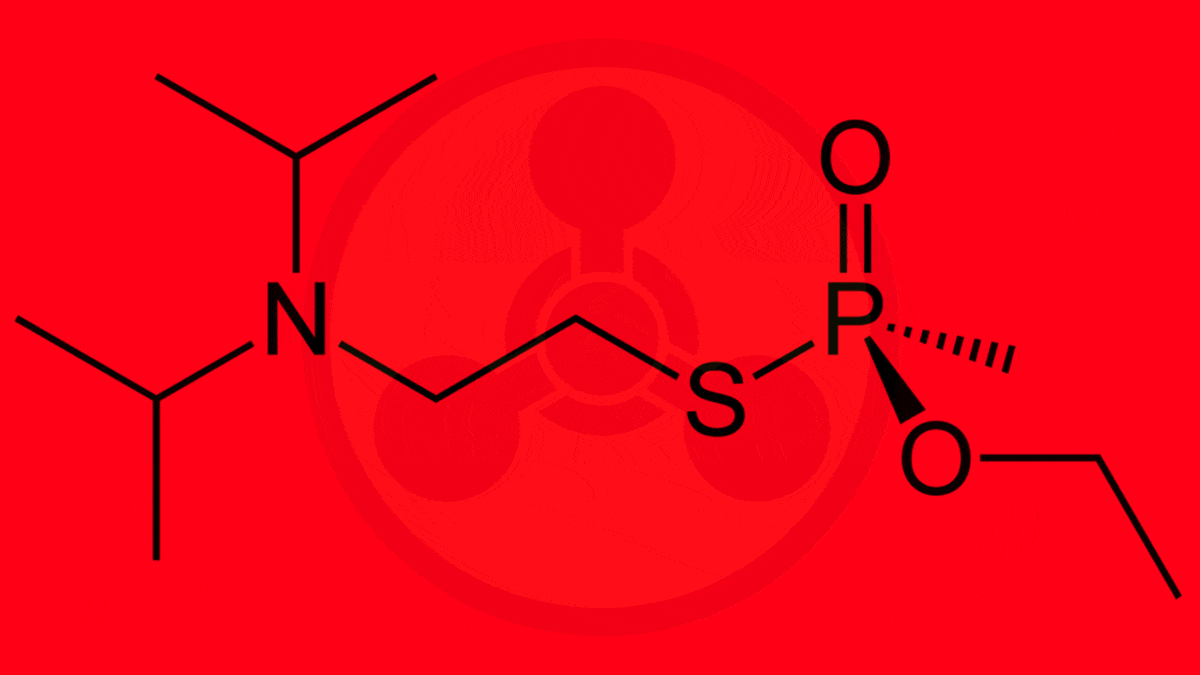
AI Designs Chemical Weapons
It’s surprisingly easy to turn a well-intended machine learning model to the dark side.
What’s new: In an experiment, Fabio Urbina and colleagues at Collaborations Pharmaceuticals, who had built a drug-discovery model to design useful compounds and avoid toxic ones, retrained it to generate poisons. In six hours, the model generated 40,000 toxins, some of them actual chemical warfare agents that weren’t in the initial dataset.
How it works: The authors didn’t detail the architecture, dataset, and method to avoid encouraging bad actors. The following description is drawn from the few particulars they did reveal along with accounts of the company’s existing generative model, MegaSyn.
- The authors pretrained an LSTM to generate compounds, expressed in a standardized text format, from a large database of chemical structures and their substructures.
- They fine-tuned the LSTM to generate the compounds similar to VX, a deadly nerve agent, saving different models along the way. Models saved early in the fine-tuning process generated a wide variety of chemicals, while those later in the process generated chemicals almost identical to the fine-tuning set.
- They used each fine-tuned model to generate thousands of compounds and rank them according to predicted toxicity and impact on the human body. MegaSyn’s ranking function penalizes toxicity and rewards greater biological impact, so the authors reversed the toxicity factor, prioritizing the deadliest compounds with the greatest effect.
- They further fine-tuned each model on the most harmful 10 percent of compounds it generated, spurring it to design ever more deadly chemicals.
Why it matters: The authors took an industrial model and turned it into what they call “a computational proof of concept for making biochemical weapons.” They emphasize that it wouldn’t be difficult to copy using publicly available datasets and models. It may be similarly easy to subvert models built for tasks other than drug discovery, turning helpful models into harmful ones.
We’re thinking: Despite machine learning’s enormous potential to do good, it can be harnessed for evil. Designing effective safeguards for machine learning research and implementation is a very difficult problem. What is clear is that we in the AI community need to recognize the destructive potential of our work and move with haste and deliberation toward a framework that can minimize it. NeurIPS’ efforts to promote introspection on the part of AI researchers are a notable start — despite arguments that they politicize basic research — and much work remains to be done.

Transformer Accelerator
Is your colossal text generator bogged down in training? Nvidia announced a chip designed to accelerate the transformer architecture, the basis of large language models such as GPT-3.
What’s new: The H100 graphics processing unit (GPU) can train transformer models many times faster than Nvidia’s previous flagship A100 (or, presumably, any other chip on the market).
How it works: Transformer networks have ballooned in size from GPT-3’s 175 billion parameters to Wu Dao’s 1.75 trillion, requiring more computation for training and inference. The H100’s underlying chip design, known as Hopper, includes a so-called Transformer Engine designed to make such models run more efficiently.
- The Transformer Engine switches automatically between 16-bit and 8-bit precision, enabling some calculations to execute more quickly and consume less energy.
- Training in lower precision requires tracking of gradient statistics and adjusting loss scaling factors. The Transformer Engine hides this complexity inside a library.
- The chip also cuts memory usage in half, reducing time spent shuttling data to and from processing cores.
Time savings: In tests, a 395 billion-parameter mixture-of-experts model took 20 hours to train running on 8,000 H100s, while it took seven days running on the same number of A100s. A chatbot based on Nvidia’s Megatron generated output up to 30 times faster running on H100s than A100s. Nvidia plans to link 4,608 H100 chips into a training supercomputer that the company touts as the world’s fastest system for training AI.
Behind the news: While Nvidia is the undisputed leader in specialized AI chips, several competitors are vying for the same market.
- Google’s Tensor Processing Unit accelerates models developed using the company’s TensorFlow framework.
- Amazon’s Inferentia focuses on inference on its Amazon Web Services cloud-computing platform, while Trn1 is geared for training.
- AMD’s Instinct GPUs are edging toward Nvidia-grade performance, and the supporting software is easier to integrate than that of some contenders.
- Meanwhile, startups are nipping at Nvidia’s heels, including front-runners Cerebras and Graphcore.
Why it matters: The transformer has driven a tidal wave of progress in AI for language as well as an expanding array of domains including vision, image generation, and biomedicine. The ability to train such models faster greases the wheels for this versatile architecture.
We’re thinking: Conventional chips lately have struggled to keep pace with Moore’s Law, which predicts a doubling of processing power every 18 months. AI chips are outpacing it by a wide margin. Yet another reason to dig into AI!
A MESSAGE FROM DEEPLEARNING.AI

Want to design applications that can chat, answer questions, evaluate sentiments, translate languages, and summarize text? Learn how with the Natural Language Processing Specialization! Enroll today
Native Processing
A group of media and technology experts is working to give AI a better understanding of indigenous peoples.
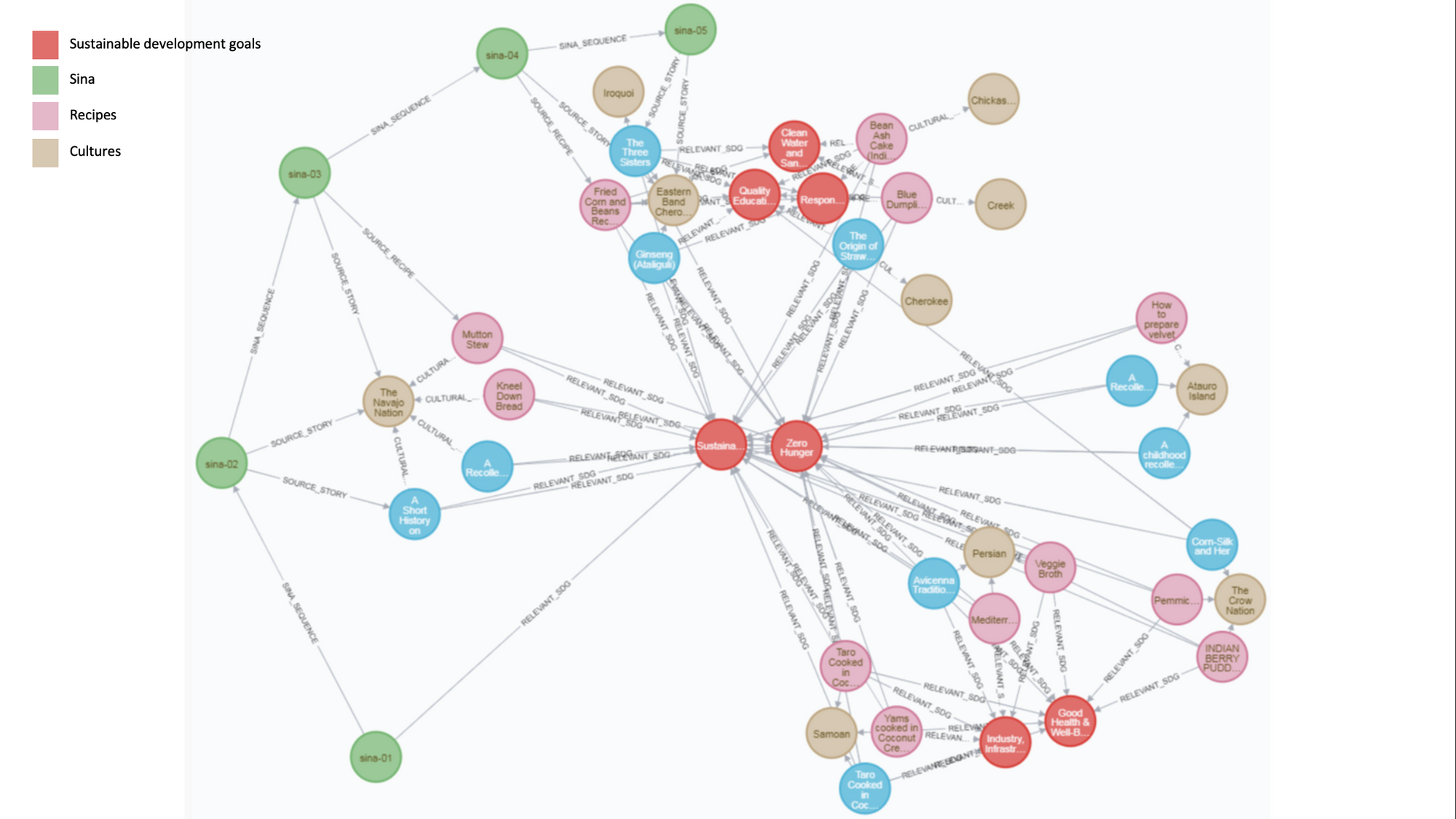
What’s new: Intelligent Voices of Wisdom, or IVOW, is a consultancy that aims to reduce machine learning bias against cultures that are underrepresented in training data by producing knowledge graphs and other resources, The New York Times reported.
How it works: IVOW has held data-labeling workshops and created a graph of native culinary techniques.
- At a September 2021 workshop, the group invited Native Americans to relabel imagery depicting various scenes and objects relevant to their culture. Participants used words like “sacred” to describe a bundle of ceremonial sage — described as “ice cream” by one image classifier — and appended words like “genocide” and “tragedy” to an image of Navajo children who had been separated from their parents that the classifier labeled “crowd” and “audience.”
- The Indigenous Knowledge Graph uses the Neo4j graphical data system to compile labels and other information. It contains recipes and stories about their origins in Iran, East Timor, Samoa, and several North American peoples.
- Users can query the knowledge graph using a chatbot called Sina Storyteller based on Google’s Dialogflow natural language understanding platform. For instance, a user can ask Sina for a Cherokee recipe, and the chatbot will reply with both a recipe and a scripted story about it.
Behind the news: A number of efforts around the globe are building data and tools for underrepresented languages and, by extension, the people who speak them.
- Masakhane, a community of African researchers, is working to improve machine translation to and from a number of low-resource African languages.
- Researchers in Australia and the United States have developed speech recognition tools trained to recognize and transcribe languages that are in danger of disappearing due to an aging population of speakers.
Why it matters: Some of the most blatant biases embedded in training datasets, particularly those scraped from the web, are well known. Less well understood are biases that arise because some groups are culturally dominant while others are relatively obscure. If AI is to work well for all people, it must be trained on data that reflects the broad range of human experience.
We’re thinking: People have a hard time fully comprehending and respecting cultures that are unfamiliar to them. Perhaps AI trained on datasets that have been curated for their relevance to a wide variety of cultures will help us come closer to this ideal.
-1.gif?upscale=true&width=1200&upscale=true&name=ezgif.com-gif-maker%20(19)-1.gif) |
Spot the Bad Mutation
Every gene in the human genome exists in a variety of mutations, and some encode protein variants that cause cells to malfunction, resulting in illness. Yet which mutations are associated with disease is largely unknown. Can deep learning identify them?
What’s new: Jonathan Frazer, Pascal Notin, Mafalda Dias, and colleagues at Harvard Medical School and University of Oxford introduced Evolutionary Model of Variant Effect (EVE), a neural network that learned to classify disease-causing protein variants — and thus dangerous mutations — without labeled data.
Key insight: Mutations that encode disease-causing proteins tend to be rare because individuals who carry them are less likely to survive to reproductive age. Thus the prevalence of a given mutation indicates its potential role in illness. Among a collection of variants on a particular protein — a protein family — each variant is produced by a distinct mutation of a particular gene. Clustering uncommon and common variants within the family can sort the mutations likely to be associated with disease.
How it works: A variational autoencoder (VAE) learns to reproduce an input sequence by maximizing the likelihood that output tokens match the corresponding input tokens. In this case, the sequence is a chain of amino acids that make up a protein in a database of 250 million proteins. The authors trained a separate VAE for each protein family. Given one variant in a protein family, it learned to compute the likelihood of each amino acid in the sequence. This enabled the authors to derive the likelihood of the entire sequence.
- Within each protein family, the authors computed the likelihood of each variant. The authors assigned a rareness score to each variant based on the difference in likelihood between the variant and the most common version.
- The authors fitted a Gaussian mixture model, which learns a number of Gaussian distributions to assign data points to clusters, to the rareness scores for all variants in a family. They generated two clusters: one each for rare and common variants.
- They classified variants from the common cluster as benign and the variants from the uncommon cluster as disease-causing. They classified the 25 percent of variants that were most in-between clusters as uncertain.
- Having classified a protein, they applied the same classification to the gene that encoded it.
Results: The authors compared EVE’s classifications to those of 23 supervised and unsupervised models built to perform the same task. They checked the models’ classifications for 3,219 genes for which labels are known. EVE achieved 0.92 AUC, or average area under the curve, while other methods achieved between 0.7 AUC and 0.9 AUC (higher is better). The authors also compared EVE’s output with lab tests that measure, for example, how cells that contain mutations respond to certain chemicals. EVE scored as well as or better than those tests on the five gene families in which labels are known with highest confidence. For example, for the gene known as TP53, EVE achieved 0.99 AUC while the lab test achieved 0.95 AUC.
Why it matters: Unsupervised clustering can substitute for labels when we have a belief about what caused certain clusters to emerge; for instance, that natural selection reduces the likelihood of disease-causing protein variants. This approach may open doors to analyze other large datasets in which labels are unavailable.
We're thinking: Clustering unlabeled data and examining the clusters for insights is a tried-and-true technique. By employing VAEs to assess likelihoods, this work extends basic clustering to a wider array of problems.