
Dear friends,
One of the challenges of building an AI startup is setting customer expectations. Machine learning is a highly experiment-driven field. Until you’ve built something, it’s hard to predict how well it will work. This creates a unique challenge when you’re trying to inform customers about what they should expect a new product to do.
For instance, the entire self-driving industry, which I was once part of, did a poor job of setting expectations about when fully autonomous cars would be ready for widespread deployment. This shortcoming led to elevated expectations that the industry failed to meet.
Compared to traditional software that begins with a specification and ends with a deliverable to match, machine learning systems present a variety of unique challenges. These challenges can affect the budget, schedule, and capabilities of a product in unexpected ways.
How can you avoid surprising customers? Here’s a non-exhaustive checklist of ways that a machine learning system might surprise customers who are more familiar with traditional software:
- We don’t know how accurate the system will be in advance.
- We might need a costly initial data collection phase.
- After getting the initial dataset, we might come back and ask for more data or better data.
- Moreover, we might ask for this over and over.
- After we’ve built a prototype that runs accurately in the lab, it might not run as well in production because of data drift or concept drift.
- Even after we’ve built an accurate production system, its performance might get worse over time for no obvious reason. We might need help monitoring the system and, if its performance degrades over time, invest further to fix it.
- A system might exhibit biases that are hard to detect.
- It might be hard to figure out why the system gave a particular output. We didn’t explicitly program it to do that!
- Despite the customer’s generous budget, we probably won’t achieve AGI. 😀

That’s a lot of potential surprises! It’s best to set expectations with customers clearly before starting a project and keep reminding them throughout the process.
As a reader of The Batch, you probably know a fair amount about AI. But AI and machine learning are still very mysterious to most people. Occasionally I speak with executives, even at large companies, whose thinking about AI gravitates more toward artificial general intelligence (AGI) — a system that can learn to perform any mental task that a typical human can — than practical applications in the marketplace today. Entrepreneurs who aspire to build AI systems usually have to work extra hard to convey the significant promise of their solution while avoiding setting elevated expectations that they can’t meet. The fact that we ourselves can incorrectly assess the capabilities of the systems we’re building — which is what happened with self-driving — makes this even harder.
Fortunately, in many application areas, once you’ve acquired one or two happy customers, things get much easier. You can (with permission) show those successes to later customers and, with a couple of successful deployments under your belt, your own sense of what to expect also improves.
The first deployment is always hardest, and each subsequent one gets easier. Keep at it!
Keep learning,
Andrew
News
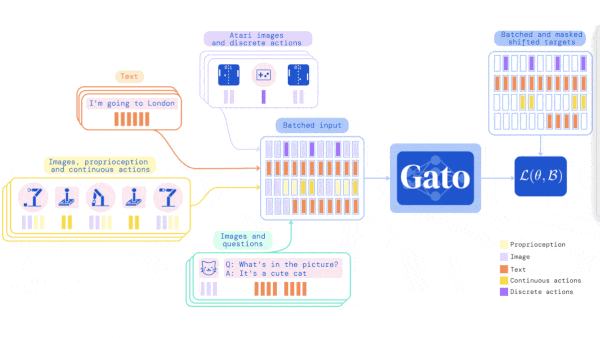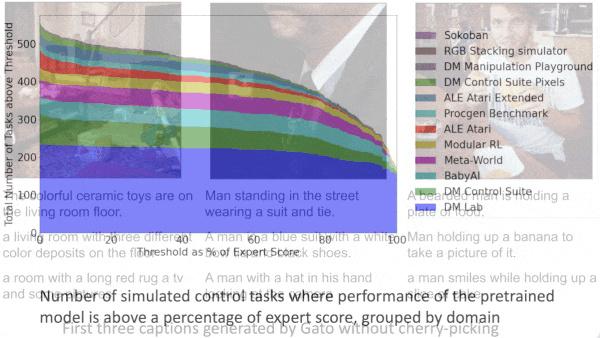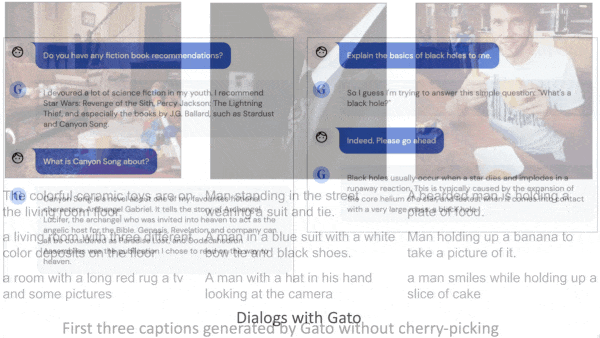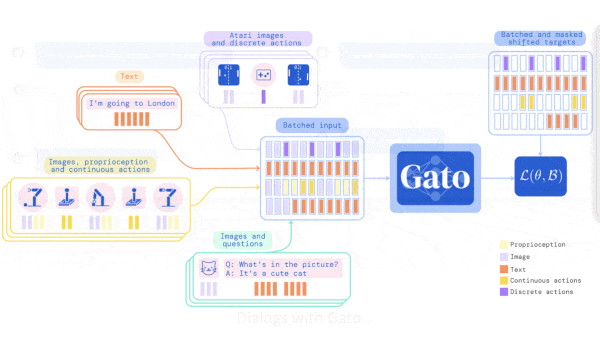
One Model, Hundreds of Tasks
Researchers took a step toward achieving a longstanding goal: One model that performs a whole lot of very different tasks.
What's new: Scott Reed, Konrad Żołna, Emilio Parisotto and a team at DeepMind announced Gato, a model that performs over 600 diverse tasks including generating image captions, manipulating a physical robot arm, and playing Atari.
How it works: The authors trained the 1.2 billion-parameter transformer on seven vision-language tasks like MS-COCO Captions, an image and joint-angle dataset of stacking blocks with a real robot, recorded state-of-the-art simulations of 595 tasks like ALE Atari, plus the language dataset MassiveText.
- The authors tokenized the data before input, turning images, text, button presses, robot arm torques, and so on into a sequence of vectors. Custom tokenizers were designed for different input types. For the simulated tasks, they interleaved observation tokens and action tokens.
- They trained the transformer to predict the next token in a sequence. Given an image, it predicted captions; given observations, it predicted actions; given text, it predicted the following text. However, it didn’t predict tokens that represented images or agent observations.
- During training, to cue the model about which simulated task it should perform, they added a prompt to the beginning of the input sequence 25 percent of the time. Half of those prompts consisted of a randomly sampled segment of observations and actions of the task at hand. For the other half, the prompt consisted of observations and actions from the end of the sequence, which served the dual purpose of telling the model what the goal was. This way, during inference, the model could be prompted with an example segment and then emulate it.
Results: In the simulated tasks, Gato achieved at least 50 percent of the score achieved in the recorded simulations of over 450 tasks. In ALE Atari, Gato matched or exceeded an average human score in 23 of 51 games, and it did at least twice as well in 11 of those 23. Gato successfully piloted a robot arm to stack a red block on top of a blue block (while ignoring a green block), in roughly 50 percent of the trials with previously unseen block shapes, comparable to a specialized baseline model, which achieved 49 percent.
What they’re saying: DeepMind’s research director, Nando de Frietas, used Gato’s achievements to argue that “it’s all about scale”: That larger models and better data are the keys to artificial general intelligence. New York University professor Gary Marcus rebutted this claim, pointing out that, alongside their increasingly brilliant results, large neural networks often generate baffling sentences, images, and behaviors.
Why it matters: This work is the latest, and most expansive, in a line of improvements in multimodal AI recently lately showcased by the impressive UNiT from Facebook. Transformers are well suited to a variety of tasks partly because they find patterns in long input sequences and because a variety of data types lend themselves to being divided into sequences to feed them.
We're thinking: Gato is an impressive engineering feat. We don’t find it so interesting that a giant neural network can do what 600 distinct, smaller networks could do. But evidence that Gato might generalize across different tasks is fascinating. Specifically, the authors pretrained Gato, fine-tuned it on four new tasks, and showed that, in three cases, the fine-tuned model outperformed models trained specifically for those tasks. We look forward to more research that evaluates the extent to which such networks, beyond memorizing various unrelated tasks, generalize across tasks and to new tasks. In other words, further progress in the direction indicated by the paper’s title: A Generalist Agent.

Recognizing Workplace Hazards
A wearable device may help warehouse workers avoid injuries.
What’s new: Modjoul, maker of a system that evaluates risks to people engaged in physical labor, received an undisclosed sum from Amazon as part of a $1 billion investment in technologies that might enhance the retailer giant’s operations.
How it works: Mounted on a belt, the device monitors the wearer's behavior and surrounding conditions. External software analyzes the data and directs the device to deliver feedback. Supervisors can view the results on a software dashboard.
- The device uses six sensors to monitor, in real time, the user’s posture, movement, and location as well as ambient noise, lighting, temperature, and air quality.
- Machine learning models that run in the cloud assign each user a score. For instance, lifting a heavy object using muscles in the lower back yields a lower score than using leg muscles.
- Given a high score, the system delivers feedback such as a haptic vibration that signals a hazardous motion. It may alert supervisors of danger signs, for instance if a wearer stops moving or air quality degrades.
- The belts are equipped with radio-frequency identification tags, allowing the system to track their locations. The system can send an alert if a worker isn’t wearing a belt in a designated area or if a belt leaves the facility.
Behind the news: Modjoul is one of five companies that received investments last week from Amazon’s Industrial Innovation Fund. Several are developing AI products. For instance, California-based Vimaan is building a computer vision system to track inventories in real time by scanning barcodes, expiration dates, and serial numbers. BionicHIVE, an Israeli startup, is working on robots that use cameras and other sensors to track the locations of products on warehouse shelves.
Why it matters: AI holds potential to make traditional industries more efficient and hopefully more humane. This system’s ability to recognize hazards related to physical posture means that everyone on the factory floor can benefit from moment-to-moment ergonomic evaluation. Protecting workers from injury is a win-win for employers and employees.
We’re thinking: Monitoring workers raises obvious concerns about privacy and fairness. While we hope that employers will use such technology to improve the lives of workers, we also see potential for abuse by managers who, say, aim to maximize productivity at the cost of driving people to exhaustion. Automated monitoring of worker performance demands clear policies that govern its use, periodic auditing that documents its benefits and exposes its harms, and transparent mechanisms that make employers accountable for its impacts. Amazon is in an ideal position to take the lead in developing such policies and procedures.
A MESSAGE FROM DEEPLEARNING.AI

Looking to get a certification to launch your machine learning career? #BreakIntoAI with the updated Machine Learning Specialization, launching in June on Coursera! Sign up to be notified
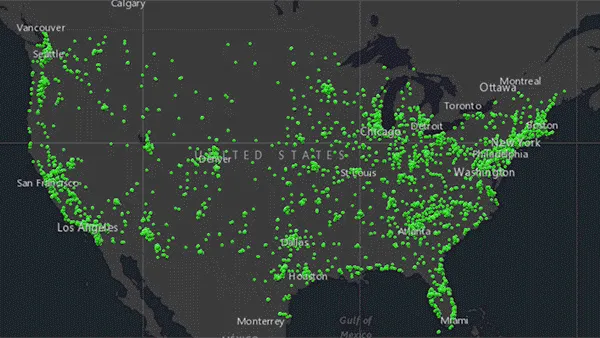
When Data = Danger
Amid rising social tension in the United States over reproductive freedom, a company that analyzes location data on abortion clinics stopped distributing its findings after a critical press report.
What’s new: SafeGraph, a company that analyzes consumer behavior based on location data, provided anonymized data on locations of Planned Parenthood, a chain of clinics that offer family-planning services including abortion, Vice reported. After the article was published, the company removed data related to Planned Parenthood citing the risk that it might be misused.
How it works: Based in Denver, SafeGraph purchases anonymized location data gathered by third-party apps installed on consumers’ phones. It uses machine learning algorithms to estimate where consumers live, which buildings they visit, how long they remain at each location. Customers can purchase reports that show foot traffic with respect to individual companies, type of business, or commercial category (such as “family planning centers”).
- Reporters purchased a week’s worth of data on 600 Planned Parenthood locations across the U.S. for around $160.
- They received information on when consumers visited these facilities, how long they stayed, where they traveled afterwards, and areas (as small as a city block) where they reside.
- Studies show that anonymize data can be re-identified. Moreover, anonymized and aggregated data can motivate bad actors to target people for harassment, whether or not they are actual subjects of the data. A recent Texas law incentivizes such harassment by offering a $10,000 bounty to citizens who successfully sue suspected abortion patients and anyone who helps them.
Behind the news: Activists, politicians, and others are using data collected by mobile apps to model and track individual behavior in increasingly invasive ways.
- Last summer, The Pillar, a newsletter that covers the Catholic church, reported that a priest was homosexual based on data from the dating app Grindr that tracked his visits to gay bars and private residences. The priest resigned following the report.
- In 2020, Vice revealed that the U.S. military purchased data from X-Mode (now known as Outlogic), a geolocation service that collected data from apps including Muslim dating and prayer apps.
- A 2018 investigation by The New York Times found at least 75 companies that obtain, analyze, and repackage location data.
Why it matters: As the political winds in the U.S. shift against abortion, women who consider or undergo the procedure, doctors who perform it, and clinic workers who support reproductive services are increasingly at risk of harassment and violence. Tracking their movements, analyzing the details, and distributing the analysis far and wide only increases the risks.
We’re thinking: Personal data is revealing. Coupled with machine learning, it can be revealing on a grand scale. We commend SafeGraph for withholding data about Planned Parenthood, but the business of analytics calls for a much more proactive stance. Companies that profit from personal data have a special responsibility to protect privacy and provide information only to customers with a legitimate interest.

Upgrade for Vision Transformers
Vision Transformer and models like it use a lot of computation and memory when processing images. New work modifies these architectures to run more efficiently while adopting helpful properties from convolutions.
What’s new: Pranav Jeevan P and Amit Sethi at the Indian Institute of Technology Bombay proposed Convolutional Xformers for Vision (CXV), a suite of revamped vision transformers.
Key insight: The amounts of computation and memory required by a transformer’s self-attention mechanism rises quadratically with the size of its input, while the amounts required by linear attention scale linearly. Using linear attention instead should boost efficiency. Furthermore, self-attention layers process input images globally, while convolutions work locally on groups of adjacent pixels. So adding convolutions should enable a transformer to generate representations that emphasize nearby pixels, which are likely to be closely related. Convolutions offer additional benefits, too, such as translation equivariance (that is, they generate the same representation of a pattern regardless of its location in an image).
How it works: In each of three transformers, the authors added convolutions and replaced self- attention with a different variety of linear attention. One used Performers’ variation on linear attention, another used Nyströmformer’s, and the third used Linear Transformer’s. The models were trained to classify images in CIFAR-10, CIFAR-100, and TinyImageNet.
- Given an image, the models divided it into patches and applied a stack of convolutional layers that learned to generate a representation of each pixel.
- They processed the representations through consecutive modified transformer layers, each containing a convolutional layer, linear attention layer, and fully connected layer.
- The convolutional layer produced a different representation if an input image were rearranged so identical patches arrived in a different order. This obviated the need for a transformer’s usual position embeddings — vectors that encode the order of input data — which typically serve this purpose.
- A fully connected layer performed classification.
Results: All three CXV models consistently outperformed not only Vision Transformer but also previous models of the same size that used linear attention mechanisms from Performers, Nyströformer, and Linear Transformer models. They also outperformed ResNets an order of magnitude larger. For example, the CXV model (1.3 million parameters) outfitted with Performer’s linear attention achieved 91.42 percent accuracy on CIFAR-10 and required 3.2 GB of memory. A ResNet-18 (11.2 million parameters) achieved 86.29 percent, though it required only 0.6 GB of memory. Hybrid ViP-6/8 (1.3 million parameters), which also used Performer’s linear attention mechanism without convolutions, achieved 77.54 percent while using 5.9 GB of memory.
Yes, but: The authors experimented with low-resolution images (32x32 in CIFAR and 64x64 in TinyImageNet). Their results may have been more dramatic had they used higher-res images.
Why it matters: Researchers have looked to linear attention to make vision transformers more efficient virtually since the original Vision Transformer was proposed. Adding convolutions can give these architectures even more capability and flexibility, as shown by this work as well as LeViT, CvT, and ConvMixer.
We’re thinking: To paraphrase the great author Mark Twain, reports of the convolution’s death are greatly exaggerated.