
Dear friends,
I’ll be spending Thanksgiving with Nova and watching her taste turkey for the first time. To those of you who celebrate Thanksgiving, I hope you spend time with loved ones, reflect on what you are thankful for, and discuss some very important topics around the dinner table:
- Should you get a real dog or a Boston Dynamics Spot?
- How can we keep the kids from using GPT-2 to write school essays?
- What do you say to Uncle Harold who thinks Siri is sentient?

In AI, all of us should be thankful to stand on the shoulders of those who came before. I’ll leave you with one thought: What can you do now so that, in the future, dozens or more will feel thankful toward you? Let’s work together to help each other, and thereby move the world forward.
Keep learning!
Andrew
News

A Sleeping Giant Stirs
Sony, the consumer-electronics powerhouse behind the PlayStation and other hit gadgets, is launching three research-and-design centers to focus on AI. Staffing up means competing with — and likely poaching talent from — frontrunners like Google, Facebook, and Microsoft.
What’s new: The company next month will open AI offices in Tokyo, Austin, and a European city to be named. The company says it will hire local machine learning engineers. It hasn’t said how many it will employ.
The plan: Hiroaki Kitano, president of Sony’s Computer Science Laboratories, will lead the effort. His vision encompasses three areas: Gaming, sensing and hardware, and — surprise! — gastronomy. Sony provided few details, but other news offers clues:
- Gaming: In September, Sony filed for a patent on an AI assistant to guide gamers through tricky spots by, say, adding markers to health stations. Gaming insiders speculate that AI could produce more realistic enemies and interactions with the game world.
- Sensors: Sony is a top maker of chips that turn light into electrons for devices like digital cameras. Sales of these CMOS sensors brought in $1.8 billion in the second quarter of 2019, 20 percent of total revenue. AI could improve the chips’ ability to sense depth.
- Gastronomy: The company wants to analyze the sensory aspects of food to create new dishes. Food-service automation also may be in the mix: Last year, Kitano oversaw research at Carnegie Mellon University developing robots for meal prep, cooking, and delivery.
Behind the news: Sony’s Computer Science Laboratories is known for its independence, secrecy, and freedom to pursue blue-sky projects. The division’s most notable product is Aibo, the AI-powered robot dog. It also did pioneering research in augmented reality and developed video conferencing protocols.
Why it matters: Sony invested in AI in the 1990s and early 2000s, but it sat out the deep learning revolution. With AI centers in the U.S. and Europe, the Japanese company likely will focus on consumer products and experiences while competing for talent with companies that dove into deep learning head-first.
We’re thinking: Kitano has passion and clout, but he also has an awful lot on his plate. Outside of Sony, he’s the founding president of the RoboCup Federation, an international group of computer scientists aiming to win the 2050 World Cup with a team of robot soccer players. Meanwhile, he runs the nonprofit Systems Biology Institute and holds a professorship at the Okinawa Institute of Research and Technology.
Bias Goes Undercover
As black-box algorithms like neural networks find their way into high-stakes fields such as transportation, healthcare, and finance, researchers have developed techniques to help explain models’ decisions. New findings show that some of these methods can be fooled.
What’s new: Two popular approaches to interpreting black-box algorithms include Local Interpretable Model-Agnostic Explanations (LIME) and Shapley Additive Explanations (SHAP). Researchers at Harvard and the University of California Irvine found a way to trick these methods to make a deliberately biased model appear to be unbiased.
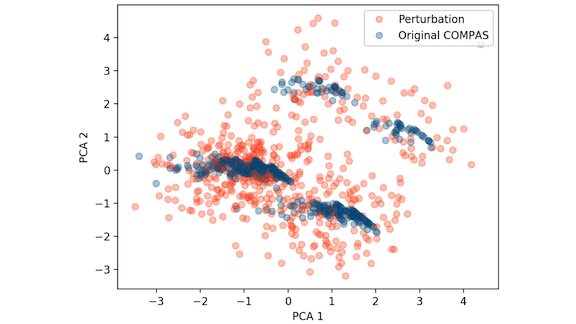
Key Insight: LIME and SHAP expose bias by showing how a model might react to small perturbations in its input. Statistical analysis shows that the distribution of perturbed inputs is distinct from that of the original inputs, as shown in the image above. A malicious actor can take advantage of the difference.
How it works: LIME and SHAP use a linear model, which is highly explainable, to mimic a black-box model’s decision with respect to any given input sample. The explainable model is built by feeding perturbed inputs to the black-box model and measuring how its output changes in response to the perturbations. Once the model is built, we can rank the features most important to the decision, highlighting any bias in the original model. Dylan Slack, Sophie Hilgard, and their colleagues introduce a way to hide such bias from LIME and SHAP by learning to recognize data they’ve altered.
- The authors’ malicious system includes a distribution classifier, a biased model, and an unbiased LIME/SHAP model.
- The distribution classifier learns to categorize incoming data as either unperturbed or perturbed.
- The classification determines whether to use the biased or unbiased model. Unperturbed data are sent to the biased model. Perturbed data go to the unbiased LIME/SHAP model.
- If the classifier is accurate, LIME/SHAP will see, and thus explain, only the unbiased model’s output, not the biased model’s output.
- When the malicious system is deployed, the real-world data are not perturbed, so the system uses the biased model.
Results: The authors created malicious systems to run COMPAS (a criminal recidivism dataset), Communities And Crime (a dataset of violent crime and demographic information), and the German Credit loan-application dataset. The embedded biased models deliberately abused discriminatory features such as race and gender, while the unbiased models used only features which were uncorrelated with discriminatory features. A malicious system biased on one feature (say, race) fooled LIME every time and SHAP in 85 percent of cases. A malicious system biased on two features fooled LIME over 90 percent of the time and SHAP 67 percent of the time.
Why it matters: The authors’ approach highlights LIME’s and SHAP’s reliance on generating novel data. If these methods were to generate data more similar to the training data’s distribution, the method would fail. This may be a promising avenue for explainability research. Meanwhile, Duke University computer scientist Cynthia Rudin proposes avoiding black-box models in high-stakes situations. The AI community needs to hold a vigorous discussion about when such models are and aren’t appropriate.
We’re thinking: If a major AI provider were caught using this technique, likely it would be vilified, which should provide some disincentive. We can imagine changes to LIME and SHAP that would counter a specific implementation, but this paper provides a dose of caution that checking for bias is not easy.
A MESSAGE FROM DEEPLEARNING.AI

What are the basic building blocks of a convolutional neural network? Learn how to implement convolutions and pooling in Course 4 of the Deep Learning Specialization.

Not Your Father’s GPU
Intel, which dominates the market for general-purpose processors, is shipping its long-awaited AI chips.
What happened: The chip giant announced that two so-called neural network processors are available to data-center customers.
How they work: One of the new chips is intended for training deep learning models, the other for inferencing. They’re designed to balance computational horsepower, communications speed, and memory capacity.
- The NNP-T1000, also called Spring Crest, takes on the Nvidia GPUs that process many AI training workloads. The new chip focuses on matrix multiplication, linear algebra, and convolution. It’s designed to scale out efficiently from small clusters to supercomputers and comes in the form of a card that plugs into a rack.
- The NNP-I1000, also known as Spring Hill, is a modified version of Intel’s latest 10th-generation Core design. It trades some parts of that architecture for specialized inference engines. It scores competitively on the MLPerf benchmark running a ResNet50 compared to Nvidia’s T4 inference chip. It comes in the form of a sleeve that can be plugged into a general-purpose server.
- At a separate event, Intel announced its first data-center GPU, known as Ponte Vecchio, scheduled for delivery in 2021 — a direct shot at Nvidia’s market.
Behind the news: While Intel chips process most AI inferencing in data centers, Nvidia leads in GPUs that speed up AI training. In 2016, Intel acquired Nervana, a startup devoted to next-generation AI chips. Meanwhile, however, the field has become crowded. Specialized designs have proliferated at a host of startups like Cerebras and tech giants like Google, while Qualcomm has been building inferencing capability into chips for low-powered devices like smartphones.
Why it matters: There’s no such thing as too much processing power for machine learning. The faster we can train models, the more data we can absorb, and the faster we can innovate new network architectures and applications. And the faster users can run our models, the more value we can deliver. As for chip makers, they recognize that AI is the future: Neural networks’ voracious appetite for processing power likely will drive silicon sales for years.
We’re thinking: Large cloud providers are consolidating computation, and that’s having a big impact on the chip business. Their concentrated buying power puts them in a strong position to demand lower prices. The cloud companies also want to make sure they have alternative providers of deep learning chips, so they’ll buy chips from several vendors rather than only the top one. All this is playing out against a backdrop of rapid growth of AI workloads. Expect intense competition and in the years ahead.
Melding Transformers with RL
Large NLP models like BERT can answer questions about a document thanks to the transformer network, a sequence-processing architecture that retains information across much longer sequences than previous methods. But transformers have had little success in reinforcement learning — until now.
What’s new: Research in reinforcement learning (RL) has focused primarily on immediate tasks such as moving a single object. Transformers could support tasks that require longer-term memory. However, past research struggled to train transformer-based RL models. Emilio Parisotto and a DeepMind team combined them successfully with Gated Transformer-XL, or GTrXL. This network can substitute directly for an LSTM in RL applications.
Key insight: A transformer’s attention component models out-of-sequence relationships. Consider a block-stacking task where the first and sixth actions taken are the most important to predicting whether the stack will be in the right order. GTrXL modifies the transformer architecture to allow it to learn sequential relationships early on (say, between the first and second actions, where the first action places the initial block and the second identifies which block needs to be picked up next) before it has learned out-of-sequence relationships.
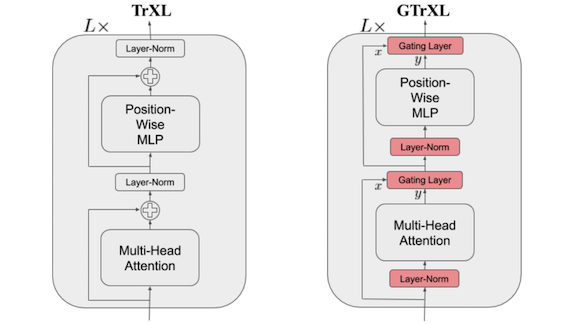
How it works: GTrXL modifies the transformer network (TrXL) as shown in the diagram above.
- GTrXL replaces the typical transformer’s residual connections with gated connections. This reduces errors that otherwise could flow through the residual connections.
- GTrXL applies layer normalization to the transformer’s sub-components but not to the gated connections. This allows the network to preserve information, including information derived directly from the input, over many residual connections while maintaining the attention mechanism’s performance.
- These modifications allow the network to learn from the order of input data while the attention mechanism hasn’t learned to model longer-term relationships. The shorter-term relationships are easier to model early on in training, making the network more stable during training.
Results: On DMLab 30, an RL environment that supports puzzle tasks requiring long-term memory, GTrXL outperformed the previous state of the art (MERLIN) averaged across all 30 tasks. It also outperformed an LSTM, the ubiquitous recurrent layer in RL research.
Why it matters: LSTMs have been essential to sequence-processing neural networks that work on short-term data. GTrXL give such networks longer-term memory. Longer time horizons eventually may help boost performance in life-long learning and meta-learning.
We’re thinking: Since the original paper describing transformer networks was published in 2017, researchers have developed extensions. This work continues to show that, when it comes to transformers, there’s more than meets the eye.