
Dear friends,
An increasing variety of large language models (LLMs) are open source, or close to it. The proliferation of models with relatively permissive licenses gives developers more options for building applications.
Here are some different ways to build applications based on LLMs, in increasing order of cost/complexity:
- Prompting. Giving a pretrained LLM instructions lets you build a prototype in minutes or hours without a training set. Earlier this year, I saw a lot of people start experimenting with prompting, and that momentum continues unabated. Several of our short courses teach best practices for this approach.
- One-shot or few-shot prompting. In addition to a prompt, giving the LLM a handful of examples of how to carry out a task — the input and the desired output — sometimes yields better results.
- Fine-tuning. An LLM that has been pretrained on a lot of text can be fine-tuned to your task by training it further on a small dataset of your own. The tools for fine-tuning are maturing, making it accessible to more developers.
- Pretraining. Pretraining your own LLM from scratch takes a lot of resources, so very few teams do it. In addition to general-purpose models pretrained on diverse topics, this approach has led to specialized models like BloombergGPT, which knows about finance, and Med-PaLM 2, which is focused on medicine.

For most teams, I recommend starting with prompting, since that allows you to get an application working quickly. If you’re unsatisfied with the quality of the output, ease into the more complex techniques gradually. Start one-shot or few-shot prompting with a handful of examples. If that doesn’t work well enough, perhaps use RAG (retrieval augmented generation) to further improve prompts with key information the LLM needs to generate high-quality outputs. If that still doesn’t deliver the performance you want, then try fine-tuning — but this represents a significantly greater level of complexity and may require hundreds or thousands more examples. To gain an in-depth understanding of these options, I highly recommend the course Generative AI with Large Language Models, created by AWS and DeepLearning.AI.
(Fun fact: A member of the DeepLearning.AI team has been trying to fine-tune Llama-2-7B to sound like me. I wonder if my job is at risk? 😜)
Additional complexity arises if you want to move to fine-tuning after prompting a proprietary model, such as GPT-4, that’s not available for fine-tuning. Is fine-tuning a much smaller model likely to yield superior results than prompting a larger, more capable model? The answer often depends on your application. If your goal is to change the style of an LLM’s output, then fine-tuning a smaller model can work well. However, if your application has been prompting GPT-4 to perform complex reasoning — in which GPT-4 surpasses current open models — it can be difficult to fine-tune a smaller model to deliver superior results.
Beyond choosing a development approach, it’s also necessary to choose a specific model. Smaller models require less processing power and work well for many applications, but larger models tend to have more knowledge about the world and better reasoning ability. I’ll talk about how to make this choice in a future letter.
Keep learning!
Andrew
P.S. We just released “Large Language Models with Semantic Search,” a short course built in collaboration with Cohere and taught by Jay Alammar and Luis Serrano. Search is a key part of many applications. Say, you need to retrieve documents or products in response to a user query. How can LLMs help? You’ll learn about (i) embeddings to retrieve a collection of documents loosely related to a query and (ii) LLM-assisted re-ranking to rank them precisely according to a query. You’ll also go through code that shows how to build a search system for retrieving relevant Wikipedia articles. Please check it out!
News

GPU Shortage Intensifies
Nvidia’s top-of-the-line chips are in high demand and short supply.
What’s new: There aren’t enough H100 graphics processing units (GPUs) to meet the crush of demand brought on by the vogue for generative AI, VentureBeat reported.
Bottleneck: Cloud providers began having trouble finding GPUs earlier this year, but the shortfall has spread to AI companies large and small. SemiAnalysis, a semiconductor market research firm, estimates that the chip will remain sold out into 2024.
- TSMC, which fabricates Nvidia’s designs, can produce only so many H100s. Its high-end chip packaging technology, which is shared among Nvidia, AMD, and other chip designers, currently has limited capacity. The manufacturer expects to double that capacity by the end of 2024.
- Nvidia executive Charlie Boyle downplayed the notion of a shortage, saying that cloud providers had presold much of their H100 capacity. As a result, startups that need access to thousands of H100s to train large models and serve a sudden swell of users have few options.
- An individual H100 with memory and high-speed interface originally retailed for around $33,000. Second-hand units now cost between $40,000 and $51,000 on eBay.
Who’s buying: Demand for H100s is hard to quantify. Large AI companies and cloud providers may need tens of thousands to hundreds of thousands of them, while AI startups may need hundreds to thousands.
- The blog gpus.llm-utils.org ballparked current demand at around 430,000 H100s, which amounts to roughly $15 billion in sales. The author said the tally is a guess based on projected purchases by major AI companies, AI startups, and cloud providers. It omits Chinese companies and may double-count chips purchased by cloud providers and processing purchased by cloud customers.
- Chinese tech giants Alibaba, Baidu, ByteDance, and Tencent ordered $5 billion worth of Nvidia chips, the bulk of them to be delivered next year, the Financial Times reported.
- CoreWeave, a startup cloud computing provider, ordered between 35,000 and 40,000 H100s. It has a close relationship with Nvidia, which invested in its recent funding round, and it secured a $2.3 billion loan — using H100 chips as collateral — to finance construction of data centers that are outfitted to process AI workloads.
- Machine learning startup Inflection AI plans to have 22,000 H100s by December.
Behind the news: Nvidia announced the H100 early last year and began full production in September. Compared to its predecessor, the A100, the H100 performs about 2.3 times faster in training and 3.5 times faster at inference.
Why it matters: Developers need these top-of-the-line chips to train high-performance models and deploy them in cutting-edge products. At a time when AI is white-hot, a dearth of chips could affect the pace of innovation.
We’re thinking: Nvidia’s CUDA software, which undergirds many deep learning software packages, gives the company’s chips a significant advantage. However, AMD’s open source ROCm is making great strides, and its MI250 and upcoming MI300-series chips appear to be promising alternatives. An open software infrastructure that made it easy to choose among GPU providers would benefit the AI community.
China’s LLMs Open Up
The latest wave of large language models trained in Chinese is open source for some users.
What’s new: Internet giant Alibaba released large language models that are freely available to smaller organizations. The internet giant followed Baichuan Intelligent Technology, a startup that contributed its own partly open models, and Beijing Academy of Artificial Intelligence, which announced that its WuDao 3.0 would be open source.
How it works: These pretrained models are small compared to, say, Meta’s LLaMa 2 (70 billion parameters) — but that may be a plus in China, where U.S. export restrictions have made chips for processing AI hard to get.
- Alibaba offers Qwen-7B and Qwen-7B-Chat. The models are freely available to small-scale users, but organizations with more than 100 million monthly active users require a license.
- Baichuan Intelligent Technology, a firm owned by Wang Xiaochuan, founder of search engine Sogou (now owned by Tencent), released Baichuan-13B and Baichuan-13B-Chat. The models are freely available to academic users. Commercial users require a license.
- Beijing Academy of Artificial Intelligence revealed its open source Wu Dao 3.0 model family to IEEE Spectrum. The family includes AquilaChat-7B and AquilaChat-33B (both fine-tuned for conversation), AquilaCode (fine-tuned to generate code from natural-language prompts), and Wu Dao Vision (for computer vision tasks). The new models upgrade and slim down the 1.75-trillion-parameter WuDao 2.0.
Behind the news: Developers in China are racing to cash in on chatbot fever. But they face unique hurdles.
- In September, the United States Commerce Department restricted the sale of high-performance AI chips including Nvidia A100 and H100 GPUs in China. Some Chinese customers have found loopholes, but demand continues to outstrip supply.
- Language models and their output are restricted by law. Interim rules set to take effect on August 15 require government approval for generative AI products before they’re released to the public. Developers have limited recent chatbots to comply with restrictions on internet content.
Why it matters: The March leak of Meta’s LLaMA initiated a groundswell of open models that excel in English and a subsequent explosion of innovation and entrepreneurial activity. Competitive open models trained in Mandarin and other Chinese languages could spark similar developments in one of the world’s biggest countries — as long as developers hew to the law.
We’re thinking: High-profile models like ChatGPT and Bard, having been trained on huge amounts of English-language data, tend to know a lot about the histories, geographies, and societies of English-speaking countries but relatively little about places where other languages are spoken. Models trained on Chinese corpora will serve speakers of China’s languages far better, and open source models fine-tuned for Chinese users likely will play an important role.
A MESSAGE FROM DEEPLEARNING.AI

Join our new course, “Large Language Models with Semantic Search,” and learn the techniques you need to integrate LLMs with search and how to use your website’s information to generate responses. Enroll for free

ChatGPT’s Best Friend
The latest robot dog is smarter — and less expensive — than ever.
What’s new: Unitree Robotics of Hangzhou, China, unleashed Go2, a quadruped robot that trots alongside its owner, stands on two legs, jumps, talks, takes photos, and retails for less than a high-end MacBook.
How it works: Go2 is made of aluminum and plastic, weighs around 15 kilograms, and moves using 12 joints. A robotic arm mounted on the unit’s back is optional. It comes in three versions with a starting price of $1,600.
- All three models include a 360-degree LIDAR sensor and object detection and avoidance capability. They can connect to other devices using either Wi-Fi or Bluetooth and take pictures with a front-facing camera.
- The Go2 Pro, priced at $2,800, contains an eight-core CPU and foot-end force sensors that enable it to navigate autonomously at around 3.5 meters per second. It can communicate via 4G cellular as well as converse and follow plain-language verbal commands using an unspecified “GPT” language model.
- The Go2 Edu, the price of which is not listed, adds an Nvidia Jetson Orin computer and a more powerful, faster-charging battery.
Why it matters: Boston Dynamics’ industrial-strength robodog Spot is manipulating high-voltage electrical equipment, inspecting nuclear power plants, and helping to monitor urban areas. But its price — from $74,500 to $200,000 — puts it out of reach of many potential users. With its dramatically lower price, Go2 suggests that such mechanical beasts may find a wider range of uses.
We’re thinking: While wheels are great on flat ground, four legs with backward-facing joints are more stable on uneven terrain. Plus, robot dogs are cute!
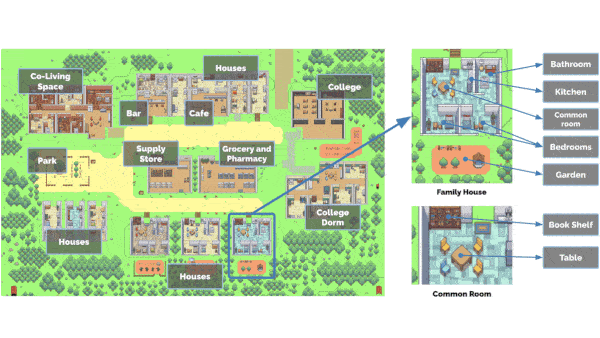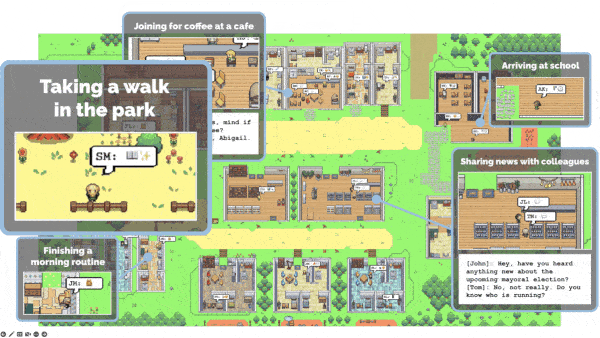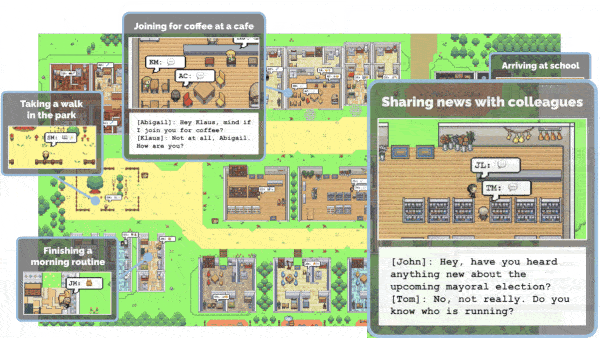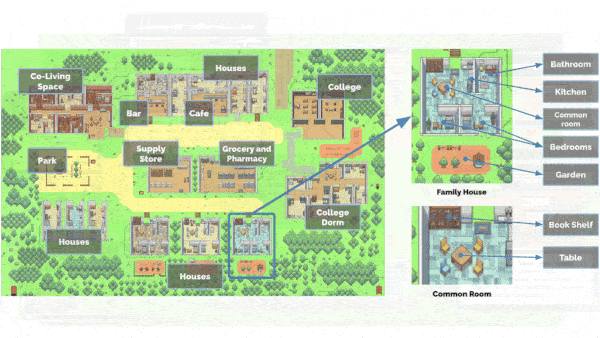
LLMs Get a Life
Large language models increasingly reply to prompts with a believably human response. Can they also mimic human behavior?
What's new: Joon Sung Park and colleagues at Stanford and Google extended GPT-3.5 to build generative agents that went about their business in a small town and interacted with one another in human-like ways. The code is newly available as open source.
Key insight: With the right prompts, a text database, and a server to keep track of things, a large language model (LLM) can simulate human activity.
- Just as people observe the world, an LLM can describe its experiences. Observations can be stored and retrieved to function like memories.
- Just as people consolidate memories, an LLM can summarize them as reflections for later use.
- To behave in a coherent way, an LLM can generate a plan and revise it as events unfold.
How it works: The authors designed 25 agents (represented by 2D sprites) who lived in a simulated town (a 2D background depicting the layout and the contents of its buildings) and let them run for two days. Each agent used GPT 3.5; a database of actions, memories, reflections, and plans generated by GPT 3.5; and a server that tracked agent and object behaviors, locations (for instance, in the kitchen of Isabella’s apartment), and statuses (whether a stove was on or off), and relayed this information to agents when they came nearby.
- At each time step, the server gave each agent an observation that comprised what it last said it was doing, the objects and people in view, and their statuses.
- Given an observation, an agent retrieved a memory based on recency, relevance, and importance. It measured relevance according to cosine similarity between embeddings of the observation and the memory. It rated importance by asking GPT-3.5 to score memories on a scale from “mundane” (1) to “poignant” (10). Having retrieved the memory, the agent generated text that described its action, upon which the server updated the appropriate locations and statuses.
- The reflection function consolidated the latest 100 memories a couple of times a day. Given 100 recent memories (say, what agent Klaus Mueller looked up at the library), the agent proposed 3 high-level questions that its memories could provide answers to (for instance, “What topic is Klaus Mueller passionate about?”). For each question, the agent retrieved relevant memories and generated five high-level insights (such as, “Klaus Mueller is dedicated to his research on gentrification”). Then it stored these insights in the memory.
- Given general information about its identity and a summary of memories from the previous day, the agent generated a plan for the current day. Then it decomposed the plan into chunks an hour long, and finally into chunks that are minutes long (“4:00 p.m.: grab a light snack, such as a piece of fruit, a granola bar, or some nuts. 4:05 p.m.: …”. The detailed plans went into the memory.
- At each time step, the agent asked itself whether and how it should react to its observation given general information about its identity, its plan, and a summary of relevant memories. If it should react, the agent updated its plan and output a statement that describes its reactions. Otherwise, the agent generated a statement saying it would continue the existing plan. For example, a father might observe another agent and, based on a memory, identify it as his son who is currently working on a project. Then the father might decide to ask the son how the project is going.
Results: The complete agents exhibited three types of emergent behavior: They spread information initially known only to themselves, formed relationships, and cooperated (specifically to attend a party). The authors gave 100 human evaluators access to all agent actions and memories. The evaluators asked the agents simple questions about their identities, behaviors, and thoughts. Then they ranked the agents’ responses for believability. They also ranked versions of each agent that were missing one or more functions, as well as humans who stood in for each agent (“to identify whether the architecture passes a basic level of behavioral competency,” the authors write). These rankings were turned into a TrueSkill score (a variation on the Elo system used in chess) for each agent type. The complete agent architecture scored highest, while the versions that lacked particular functions scored lower. Surprisingly, the human stand-ins also underperformed the complete agents.
Yes, but: Some complete agents “remembered” details they had not experienced. Others showed erratic behavior, like not recognizing that a one-person bathroom was occupied or that a business was closed. And they used oddly formal language in intimate conversation; one ended exchanges with her husband, “It was good talking to you as always.”
Why it matters: Large language models produce surprisingly human-like output. Combined with a database and server, they can begin to simulate human interactions. While the TrueSkill results don’t fully convey how humanly these agents behaved, they do suggest a role for such agents in fields like game development, social media, robotics, and epidemiology.
We're thinking: The evaluators found the human stand-ins less believable than the full-fledged agents. Did the agents exceed human-level performance in the task of acting human, or does this result reflect a limitation of the evaluation method?
A MESSAGE FROM DEEPLEARNING.AI

Join our upcoming workshop with Predibase and learn how to use open source tools to overcome challenges like the “host out of memory” error when fine-tuning models like Llama-2. Register now
Data Points
Publisher surprised to find it published AI-generated art
Wizards of the Coast, the publisher of Dungeons & Dragons guidebooks and stories, admitted the use of AI-generated artwork in a digital book. The company, which claimed to have been unaware that it had published generated content prior to the book’s release, said it would update its policies to prevent AI art from being included in future publications. (Polygon)
Brookings shows the uneven geography of AI activity in the U.S.
A report from Brookings Institute highlights the concentration of AI activity in tech-focused cities like San Francisco, New York, and Seattle. It proposes policy actions at federal, state, and local levels to promote more widespread AI development. (Brookings)
AI and robotics make recycling more efficient
Companies such as EverestLabs and AMP Robotics are using AI to streamline the recycling process. Their robotic arms identify recyclable items to boost object recovery rates by up to three times compared to human efforts. (CNBC)
Research: A deep learning model recognizes laptop keystrokes by sound
Researchers trained a model to analyze sound profiles of laptop keystrokes. They achieved 93 percent accuracy when interpreting individual key sounds in Zoom audio recordings. This approach raises security concerns, especially for laptops used in public settings. (Ars Technica)
Commercialized deepfakes raise questions about control and misuse
Synthesia touts its AI avatars, which look like video recordings of people, to enhance corporate presentations and training sessions. However, the photorealistic avatars have been put to use by scammers and propagandists (Wired)
Tech giants rally behind AI in resurgent quarter
AI helped companies like Google, Meta, and Microsoft rebound from a financial slump in the most recent quarter. Now they’re doubling down on AI to revitalize their product lines and fuel innovation. Some are already benefiting from the AI fever. (The New York Times)
Disney forms AI task force
The Walt Disney Company established a dedicated group to explore the applications of AI across its entertainment empire. The initiative aims to develop in-house solutions and forge partnerships that can drive innovation and cut costs. (Reuters)
Google and Universal Music explore licensing for AI-generated music
Alphabet's Google is in early discussions with Universal Music over licenses to use artists' voices and melodies in AI-generated songs. The companies aim to develop technology that would enable fans to make their own sound-alike productions while compensating copyright owners. (Reuters)
Report highlights AI's role in promoting eating disorders
A study conducted by the Center for Countering Digital Hate (CCDH) found that ChatGPT and Stable Diffusion produced harmful output around 41 percent of the time when tested with prompts related to eating disorders. Experts emphasize the need to ensure that AI-generated content doesn't promote unhealthy body-image ideals or provide dangerous advice to users who may suffer from eating disorders. (The Washington Post and CCDH)
Zoom promises not totrain its AI systems on customer data
The video conferencing platform added a line to its terms of service stating that it will not employ customer audio, video, or chat content for training AI models without consent. The company updated its terms after users discovered language that granted the right to use customer data to build AI systems. In July, Zoom had revised its terms to broaden its access to customer data in developing AI products and services. (The Washington Post)
Stack Overflow adapts to survive in the age of LLMs
The longstanding community for developers faces a decline in traffic as AI models increasingly answer technical questions. Some language models, partly trained on Stack Overflow's data, compete with Stack Overflow directly. The company plans to develop its own question-answering models and charge AI companies to use its data. (Business Insider)
Google's AI seeks to continue training AI on published content
Google submitted a proposal to the Australian government suggesting that generative AI systems should be allowed to use publishers' content to train AI systems while providing an opt-out for those that want to keep their content out of training datasets. Google's position sparked discussions about content creators' rights. (The Guardian)
OpenAI allows content providers to opt out of its training datasets
GPTBot, a web crawler that collects online data used by OpenAI to train its models, offers website operators the ability to opt out. The crawler will not scrape data from sites that exercise the option.(The Verge)