
Dear friends,
While AI is a general-purpose technology that’s useful for many things, it isn’t good for every task under the sun. How can we decide which concrete use cases to build? If you’re helping a business figure out where to apply AI, I’ve found the following recipe useful as a brainstorming aid:
- Consider the jobs of the company’s employees and contractors, and break down the jobs into tasks.
- Examine each commonly done task to see if it’s amenable to either assistance (augmentation) or automation using AI tools such as supervised learning or generative AI.
- Assess the value of doing so.
Rather than thinking of AI as automating jobs — a common narrative in the popular press and in conversations about AI leading to job losses — it’s more useful to think about jobs as collections of tasks, and to analyze AI’s ability to augment or automate individual tasks. This approach is based on a method developed by Erik Brynjolfsson, Tom Mitchell, and Daniel Rock for understanding the impact of AI on the economy. Other researchers have used it to understand the impact of generative AI. Workhelix, an AI Fund portfolio company co-founded by Brynjolfsson, Andrew McAfee, James Milin, and Rock, uses it to help enterprises asses their generative AI opportunities.
In addition to economic analyses, I’ve found this approach useful for brainstorming project ideas. For example, how can AI be used to automate software businesses? Can it do the job of a computer programmer?
Typically, we think of computer programmers as writing code, but actually they perform a variety of tasks. According to O*NET, an online database of jobs and their associated tasks sponsored by the U.S. Department of Commerce, programmers perform 17 tasks. These include:
- Writing programs
- Debugging
- Consulting with others to clarify program intent
- Conducting trial runs of programs
- Writing documentation
and so on. Clearly systems like GitHub Copilot can automate some writing of code. Automating the writing of documentation may be much easier, so an AI team building tools for programmers might consider that too. However, if consulting to clarify the intent behind a program turns out to be hard for AI, we might assign that a lower priority.
Another example: Can AI do the job of a radiologist? When thinking through AI’s impact on a profession, many people gravitate to the tasks that are most unique about that profession, such as interpreting radiological images. But according to O*NET, radiologists carry out 30 tasks. By taking a broader look at these tasks, we might identify ones that are easier or more valuable to automate. For example, while AI has made exciting progress in interpreting radiological images, part of this task remains challenging to fully automate. Are there other tasks on the list that might be more amenable to automation, such as obtaining patient histories?

O*NET listings are a helpful starting point, but they’re also a bit generic. If you’re carrying out this type of analysis, you’re likely to get better results if you capture an accurate understanding of tasks carried out by employees of the specific company you’re working with.
An unfortunate side effect of this approach is that it tends to find human tasks to automate rather than creative applications that no one is working on. Brynjolfsson laments that this leads to the Turing Trap whereby we tend to use AI to do human work rather than come up with tasks no human is doing. But sometimes, if we can do something that humans do but do it 10,000x faster and cheaper, it changes the nature of the business. For example, email automated the task of transmitting messages. But it didn’t make the postal system cheaper; instead it changed what and how frequently we communicate. Web search automated the task of finding articles. Not only did this make librarians more effective, it also changed how we access information. So even if AI tackles a task that humans perform, it could still lead to revolutionary change for a business.
Many jobs in which some tasks can be automated aren’t likely to go away. Instead, AI will augment human labor while humans continue to focus on the things they do better. However, jobs that are mostly or fully automatable may disappear, putting people out of work. In such cases, as a society, we have a duty to take care of the people whose livelihoods are affected, to make sure they have a safety net and an opportunity to reskill and keep contributing. Meanwhile, lowering the cost of delivering certain services is bound to increase the demand for some jobs, just as the invention of the car led to a huge explosion in the number of driving jobs. In this way, AI will create many jobs as well as destroy some.
Some programmers worry that generative AI will automate their jobs. However, programming involves enough different tasks, some of which are hard to automate, that I find it very unlikely that AI will automate these jobs anytime soon. Pursuing a long-term career in software is still a great choice, but we should be sure to adopt AI tools in our work. Many professions will be here for a long time, but workers who know how to use AI effectively will replace workers who don’t.
I hope you find this framework useful when you’re coming up with ideas for AI projects. If our projects affect someone else’s work, let’s work hard to protect people’s livelihoods. I hope that by building AI systems, we can create — and fairly share — value for everyone.
Keep learning!
Andrew
News
Music Generation For the Masses
Text-to-music generation has arrived.
What's new: Stability.ai, maker of the Stable Diffusion image generator and StableLM text generator, launched Stable Audio, a system that generates music and sound effects from text. You can play with it and listen to examples here. The service is free for 20 generations per month up to 45 seconds long. The professional tier allows 500 generations per month, up to 90 seconds long, for $11.99 per month. An enterprise tier is negotiable. The company said it would open-source the model eventually.
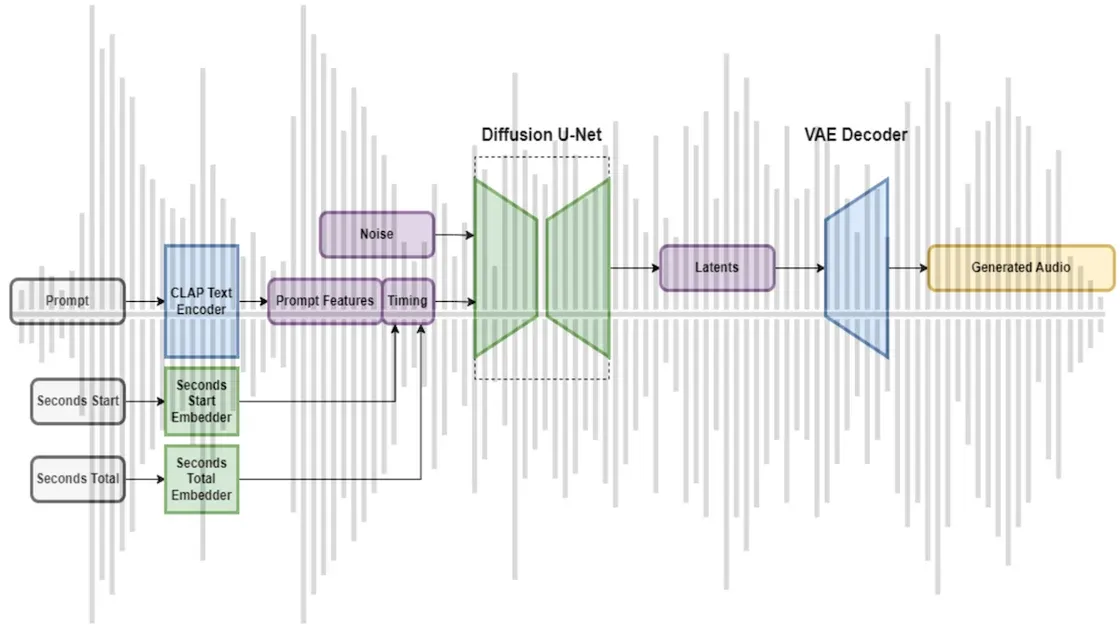
How it works: Stable Audio is a latent diffusion model. It generates audio by a process that’s similar to the way Stable Diffusion generates images, but it uses a variational autoencoder to map audio to an embedding for processing and back to audio for your listening pleasure. The authors trained the system on 800,000 audio files containing music, sound effects, and performances on individual instruments and corresponding descriptions.
- During training, a variational autoencoder learns small embedding representations of audio examples.
- A CLAP transformer pretrained on their dataset produces an embedding for text that describes musical characteristics like style, instrumentation, tempo, mood, or any sort of description. Separate embedding layers represent the duration of the audio to be generated and how many seconds into a given audio file the current training example starts. The latter helps the model to learn how musical compositions are expressed over time.
- Stable Audio adds noise to the audio vector. A U-Net convolutional neural network learns to estimate the added noise and remove it according to the text and timing embeddings.
- At inference, the system starts with a pure-noise embedding and a user-prompted descriptive text and output file length. It removes noise iteratively to produce an embedding of the generated audio. From that embedding, the decoder from the variational autoencoder produces the audio at CD-quality (16-bit, 44.1kHz, stereo) resolution.
Behind the News: Stable Audio joins earlier services including Boomy, Mubert, plugger.ai, Soundful, and VEED.IO. It follows tantalizing advances in audio generation.
- Google MusicLM learned to generate music from text descriptions by setting the problem up as a sequence-to-sequence modeling task.
- Riffusion turned spectrograms generated by Stable Diffusion into audio.
- OpenAI Jukebox learned to compress their training set and generated audio from this compressed space. The researchers guided generation using metadata including artist, lyrics, and style.
Yes, but: Stable Audio excels when generating instrumental and ambient music, but its output tends to suffer from some of the same flaws as previous text-to-music generators: Longer outputs often lack a coherent structure, and the clarity and detail of individual instruments and sound effects varies wildly. It also doesn’t effectively generate the sound of a vocalist pronouncing words.
Why it matters: AI has demonstrated its prowess at generating convincing text and images. Generated audio has implications for producers not only of music but also of videos, video games, and podcasts. Stable Audio sounds like an early step, but it stands out for its speed, high-resolution output, and the inclusion of a mechanism for learning musical structure.
We're thinking: Stable Audio is impressive, but this doesn’t quite feel like music’s GPT moment. Text and image generation took off as soon as highly capable generative models appeared. Music generation may yet await models that can produce not only high-res output but also sonorities and structures coherent and varied enough to be widely useful.

Machine Translation at the Border
For some asylum seekers, machine translation errors may make the difference between protection and deportation.
What’s new: Faced with a shortage of human translators, United States immigration authorities are relying on AI to process asylum claims. Faulty translations are jeopardizing applications, The Guardian reported.
How it works: The Department of Homeland Security has said it would provide human translators to asylum seekers with limited English proficiency, but this doesn’t always happen. They often resort to machine translation instead.
- Immigration authorities use a variety of models. The Department of Homeland Security works with Lionbridge and TransPerfect. Immigration Services officials use Google Translate. U.S. Customs and Border Patrol developed a bespoke app, CBP Translate, that uses translations from Google Cloud.
- Minute errors frequently result in rejected asylum applications. For example, models sometimes translate first-person pronouns from asylum seekers’ native languages into “we” in English, leading authorities to believe that multiple people filed an application, which is illegal. In one instance, authorities dismissed a woman’s application after a translator rendered a colloquial reference for her abusive father as her “boss.”
- Some translations are barely comprehensible. An illiterate Brazilian Portuguese speaker was separated from his family and subsequently detained because a model mistranslated his asylum application into gibberish.
Behind the news: Diverse factors can mar a translation model’s output:
- Even widely spoken languages may suffer from a lack of training data. For instance, on Wikipedia, roughly the same number of articles are written in Swahili, which is spoken by roughly 80 million people, as Breton, a language with fewer than 250,000 speakers.
- Many models are trained to translate among several languages using English as an intermediary, but English words don’t always account for meanings in other languages. For instance, English uses one word for rice, while Swahili and Japanese have different words for cooked and uncooked rice. This may cause inaccurate or nonsensical Swahili-to-Japanese translations of sentences that include “rice.”
- A model trained on a language’s formal variation may not translate casual usage accurately. A translator trained on a language’s most common dialect may output more errors faced with a less common one.
- Translations of spoken language may suffer if a model’s training data did not contain audio examples of the speaker’s accent, pitch, volume, or pace.
Why it matters: Machine translation has come a long way in recent years, (as has the U.S. government’s embrace of AI to streamline immigration). Yet the latest models, as impressive as they are, were not designed for specialized uses like interviewing asylum candidates at border crossings, where people may express themselves in atypical ways because they’re exhausted, disoriented, or fearful.
We’re thinking: Justice demands that asylum seekers have their cases heard accurately. We call for significantly greater investment in translation technology, border-crossing workflows, and human-in-the-loop systems to make sure migrants are treated kindly and fairly.
A Message from DeepLearning.AI

Learn about text embeddings and how to apply them to common natural language processing tasks in our new course with Google Cloud! Sign up for free

U.S. Plans to Expand Drone Fleet
The United States military aims to field a multitude of autonomous vehicles.
What’s new: The Department of Defense announced an initiative to develop autonomous systems for surveillance, defense, logistics, and other purposes, The Wall Street Journal reported. The department aims to deploy several thousands of such systems within 18 to 24 months, a timeline motivated by rapid drone development by China.
How it works: The Pentagon shared details about a program called Replicator that it had announced in August.
- Replicator will cost hundreds of millions of dollars. The Pentagon requested a total of $1.8 billion for AI in its 2024 defense budget.
- Defense Department officials will consult with military personnel and determine a list of initial investments by year’s end. The program may build swarms of surveillance drones that gather information in the air, on land, and at sea. Other products could include ground-based logistics and automated missile defense.
- These products are intended as stepping stones to more capable systems. The military might use them for three to five years before upgrading.
- The program follows previous initiatives including Task Force 59, which deployed a network of sensors and surveillance systems in the waters off Iran, and Sea Hunter, an autonomous ship developed by the U.S. Defense Advanced Research Projects Agency.
Behind the news: The U.S. is not alone in pursuing autonomous military applications. The Russian invasion of Ukraine spurred a homegrown Ukrainian drone industry and encouraged government and independent researchers to harness face recognition systems for identifying combatants. China is developing autonomous ships designed to carry fleets of air, surface, and submarine drones.
Why it matters: Replicator marks a significant, very public escalation of military AI. Other nations are certain to follow suit.
We’re thinking: We’re concerned about the potential for an international AI arms race, and we support the United Nations’ proposed ban on fully autonomous weapons. Yet the unfortunate state of the world is that many countries — even large, wealthy democracies — have little choice but to invest in defenses against aggressors both actual and potential. The ethics of military AI aren’t simple. We call on the AI community to help ensure that they encourage a safer and more democratic world.

How Vision Transformers See
While transformers have delivered state-of-the-art results in several domains of machine learning, few attempts have been made to probe their inner workings. Researchers offer a new approach.
What's new: Amin Ghiasi and colleagues at the University of Maryland visualized representations learned by a vision transformer. The authors compared their results to earlier visualizations of convolutional neural networks (CNNs).
Key insight: A method that has been used to visualize the internal workings of CNNs can also reveal what’s happening inside transformers: Feeding the network images that maximize the output of a particular neuron makes it possible to determine what individual neurons contribute to the network’s output. For instance, neurons in earlier layers may generate high outputs in response to an image with a certain texture, while neurons in later layers may generate high outputs in response to images of a particular object. Such results would suggest that earlier layers identify textures, and later layers combine those textures to represent objects.
How it works: The authors experimented with a pretrained ViT-B16 vision transformer.
- They chose a neuron to visualize. Then they fed ViT-B16 an image of random noise. Using a loss function that maximized the neuron’s output, they backpropagated through the network to alter the image.
- Separately, they fed every ImageNet image to ViT-B16 to find one that maximized the same neuron’s output. They compared the image they found with the generated image to identify commonalities.
- They repeated this process for neurons in various parts of the network.
- They also performed these steps with CLIP to gauge the behavior of neurons in a transformer that had been pretrained on both text and images.
Results: ViT-B16’s fully connected layers were most revealing: Neurons in fully connected layers yielded images that contained recognizable features, while those in attention layers yielded images that resembled noise.
- Comparing visualizations associated with fully connected layers showed that, like CNNs, vision transformers learn representations that progress from edges and textures in early layers to parts of objects and entire objects in deeper layers.
- Unlike CNNs, vision transformers make more use of an image’s background. (In a classification task, they outperformed CNNs when shown only an image’s background.) However, they’re not dependent on backgrounds (they also outperformed CNNs when shown only the foreground).
- In their experiments with CLIP, the authors found neurons that generated high outputs in response to images that were dissimilar visually but related conceptually. For instance, a CLIP neuron was activated by pictures of a radio and a concert hall, as though it had learned the concept of music. ViT-B16 did not exhibit this behavior.
Why it matters: This work reveals that vision transformers base their output on hierarchical representations in much the same way that CNNs do, but they learn stronger associations between image foregrounds and backgrounds. Such insights deepen our understanding of vision transformers and can help practitioners explain their outputs.
We're thinking: The evidence that CLIP learns concepts is especially intriguing. As transformers show their utility in a wider variety of tasks, they’re looking smarter as well.

"Practical Computer Vision" by Andrew Ng: In this live event, you’ll learn how to identify and scope vision applications, choose vision models, apply data-centric AI, and develop an MLOps pipeline. Join us on Tuesday, October 3, at 10:00 a.m. Pacific Time!
Data Points
U.S. investment in AI grows outside Silicon Valley, Cambridge, and NYC
The big three research and startup hubs still collectively make up about half of venture capital investment, but Seattle, Colorado, Texas, and the rest of the Sun Belt are gaining. Big companies like Tesla and Oracle have relocated or expanded, and funders like Steve Case argue that startups in once-overlooked cities can offer a better return on investment. (Bloomberg)
MLPerf tests chips’ ability to process large language models
How fast can your data center-class hardware process large language model (LLM) inferences? MLPerf's new benchmark tests measured LLM performance on systems from fifteen companies. Nvidia’s new Grace Hopper 72-core CPU + H100 GPU superchip paced the field, but Intel and Qualcomm also made strong showings. (MLCommons)
UK regulator publishes principles to guide AI use
The UK’s Competition and Markets Authority specified guidelines for AI regulations, focusing on large language models like GPT-4 and Llama 2. The CMA’s seven principles (accountability, access, diversity of business models, choice, flexibility, fair dealing, and transparency) aim to ensure competitive markets for both AI companies and their customers. “There remains a real risk that the use of AI develops in a way that undermines consumer trust or is dominated by a few players who exert market power that prevents the full benefits being felt across the economy,” said CMA CEO Sarah Cardell. (Gov.UK)
IRS expands machine learning program to spot tax evasion
The United States Treasury Department’s revenue compliance office is partnering with experts in AI and data science to detect tax fraud. Its Large Partnership Compliance (LPC) program, launched in 2021, targets the largest and most complex tax returns, which are also the most opaque for human auditors. The IRS said it was using “cutting-edge machine learning technology to identify potential compliance risk” but would not disclose specifics. (IRS.gov)
Startup monitors pollution and biodiversity with big data (and lots of bees)
BeeOdiversity analyzes data gathered by six bee colonies to measure pollutants and invasive species across hundreds of thousands of acres in Europe. The bees’ pollen, soil analysis, groundwater data, and satellite imagery are fed into an AI system called BeeOImpact that can infer the presence of heavy metals, pesticides, and colony collapse across a larger area. (Microsoft.com)
AI is designing cities
Some automated urban design tools are more like Sim City-style games or landscape-inspired art projects, but they are also solving real problems for planners and democratizing who can create a new vision of a city. AI can augment existing computer-aided design programs and determine where to locate water pipes and electric lines in buildings and neighborhoods. In Istanbul, city planners are creating an innovation district designed for drones, data sensors, and autonomous vehicles with the aid of AI. But critics say current datasets are biased towards replicating modern cities and their problems. (Bloomberg)
Japan builds large language models
Japan’s government and tech giants are investing heavily in developing its own versions of generative text models like GPT, LLaMA, and BARD. Using a typical multilingual large language model, prompts in Japanese are translated internally into English and return an English response that’s translated back into Japanese, sometimes resulting in misunderstandings or gibberish. Moreover, current models aren’t optimized for Japanese cultural norms of politeness and professionalism. But development is hampered by the fact that Japanese-only datasets are smaller than those used to train western models, and the country has fewer resources to develop them. (Nature)
Research: DeepMind reads DNA to find harmful mutations
AlphaMissense adapts DeepMind’s AlphaFold to read proteins and identify which are common (and probably benign) or unusual (or potentially harmful). Trained on DNA data from humans and closely related primates, the model identifies new mutations and predicts how risky the genetic change may be. AlphaMissense may help experts identify which mutations drive diseases and guide doctors to better treatments. (Science)