
Dear friends,
Large language models, or LLMs, have transformed how we process text. Large vision models, or LVMs, are starting to change how we process images as well. But there is an important difference between LLMs and LVMs:
- Internet text is similar enough to companies' proprietary text that an LLM trained on internet text can usually understand your proprietary documents.
- But many practical vision applications use images that look nothing like internet images. In these settings, you might do much better with a domain-specific LVM that has been adapted to your particular application domain.
This week, Dan Maloney and I announced Landing AI's work on developing domain-specific LVMs. You can learn more about it in this short video (4 minutes).
The internet – especially sites like Instagram – has numerous pictures of people, pets, landmarks, and everyday objects. So a generic LVM (usually a large vision transformer trained using a self-supervised learning objective on unlabeled images scraped from the internet) learns to recognize salient features in such images.
But many industry-specific applications of computer vision involve images that look little like internet images. Pathology applications, for instance, process images of tissue samples captured using high-powered microscopes. Alternatively, manufacturing inspection applications might work with numerous images centered on a single object or part of an object, all of which were imaged under similar lighting and camera configurations.
While some pathology and some manufacturing images can be found on the internet, their relative scarcity means that most generic LVMs do poorly at recognizing the most important features in such images.
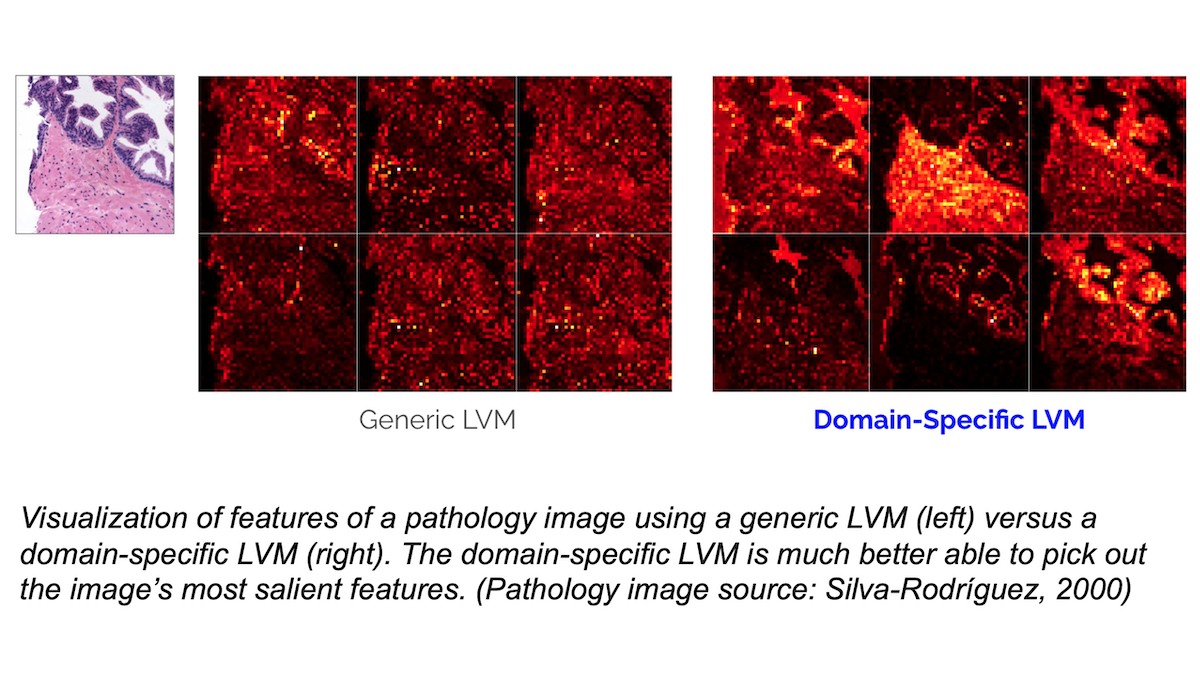
In experiments conducted by Landing AI's Mark Sabini, Abdelhamid Bouzid, and Bastian Renjifo, LVMs adapted to images of a particular domain, such as pathology or semiconductor wafer inspection, do much better at finding relevant features in images of that domain. Building these LVMs can be done with around 100,000 unlabeled images from that domain, and larger datasets likely would result in even better models.
Further, if you use a pretrained LVM together with a small labeled dataset to tackle a supervised learning task, a domain specific LVM needs significantly less (around 10 percent to 30 percent as much) labeled data to achieve performance comparable to using a generic LVM.
Consequently, I believe domain specific LVMs can help businesses with large, proprietary sets of images that look different from internet images unlock considerable value from their data.
Of course, LVMs are still young, and much innovation lies ahead. My team is continuing to experiment with different ways to train domain-specific LVMs, as well as exploring how to combine such models with text to form domain-specific large multimodal models. I'm confident that LVMs will achieve many more breakthroughs in the coming years.
Keep learning!
Andrew
News
Amazon Joins Chatbot Fray
Amazon launched a chatbot for large companies even as internal tests indicated potential problems.
What’s new: Amazon introduced Q, an AI-powered assistant that enables employees to query documents and corporate systems. Days later, the tech newsletter Platformer obtained internal documents that indicate the model can generates falsehood and leak confidential information. (Amazon Q is not to be confused with OpenAI Q*.)
How it works: Currently available as a free preview, Q analyzes private documents, databases, and code to answer questions, generate content, and take actions. Amazon plans to offer two tiers of service: a basic chatbot ($20 per month) and the chatbot plus code generation, troubleshooting, security evaluation, and human assistance from Amazon Web Services ($25 per month). Amazon promises not to train machine learning models on Q users’ data.
The issues: Three days after Amazon unveiled Q, employees began to flag issues on internal Slack and security reporting channels.
- Q provided inaccurate recommendations on issues of digital sovereignty; that is, whether or not data should be stored within a particular jurisdiction, a thorny legal issue in Europe and other parts of the world.
- One employee raised a “sev 2” alert, indicating an issue severe enough to warrant paging engineers after hours and over the weekend.
- Internal tests showed that Q could leak confidential information from Amazon such as internal discount programs, unreleased features, and locations of AWS data centers. Amazon spokespeople called such scenarios hypothetical and denied that Q had leaked such information.
Behind the news: Amazon is not the only major AI company whose chatbot has leaked private information. Google researchers recently found that they could prompt OpenAI’s ChatGPT to divulge personal information found in its training data.
Why it matters: For Amazon, issues with a newly released system are a bump in the road to competing effectively against competitors like Microsoft Copilot and ChatGPT Enterprise. For developers, it’s a sobering reminder that when you move fast, what breaks may be your own product.
We’re thinking: In developing an AI system, often it’s necessary to launch — in a safe and responsible way — and make improvements based on real-world performance. We congratulate the Q team on getting the product out and look forward to seeing where they take it.

Seeing Darker-Skinned Pedestrians
In a study, models used to detect people walking on streets and sidewalks performed less well on adults with darker skin and children of all skin tones.
What’s new: Xinyui Li, Zhenpeng Chen, and colleagues at Peking University, University College London, and King’s College London evaluated eight widely used object detectors for bias with respect to skin color, age, and gender.
Key insight: When it comes to detecting pedestrians, biases with respect to demographic characteristics can be a life-and-death matter. Evaluating them requires a dataset of pedestrians labeled according to characteristics that might influence detection. Skin color, age, and gender are important human differences that can affect a vision model’s performance, especially depending on lighting conditions.
How it works: The authors collected over 8,000 photos from four datasets of street scenes. They annotated each image with labels for skin tone (light or dark), age group (child or adult), and gender (male or female). They tested four general-purpose object detectors: YOLOX, RetinaNet, Faster R-CNN, and Cascade R-CNN — and four pedestrian-specific detectors — ALFNet, CSP, MGAN, and PRNet — on their dataset. They evaluated performance between perceived skin tone, age, and gender groups and under different conditions of brightness, contrast, and weather.
Results: The study revealed significant fairness issues related to skin tone and age.
- Six models detected people with light and dark skin tones equally well, but two — YOLOX and RetinaNet — were 30.71 and 28.03 percent less likely to detect darker-skinned people. In all cases, darker-skinned pedestrians were less likely to be detected under conditions of low contrast and low brightness.
- All eight models showed worse performance with children than adults For instance, YOLOX detected children 26.06 less often, while CSP detected children 12.68 percent less often. On average, the models failed to detect 46.57 percent of children, but only 26.91 percent of adults.
- Most of the models performed equally well regardless of gender. However, all eight had difficulty detecting women in the EuroCity-Night dataset, which contains photos shot after dark.
Behind the news: Previous work has shown that computer vision models can harbor biases that make them less likely to recognize individuals of certain types. In 2019, MIT showed that commercial face recognition performed worse on women and darker skinned individuals. A plethora of work evaluates bias in datasets typically used to train vision models.
Why it matters: As more road vehicles gain self-driving capabilities and as expanded robotaxi services come to major cities, a growing number of pedestrians’ lives are in the hands of computer vision algorithms. Auto makers don’t disclose what pedestrian detection systems they use or the number of real-world accidents involving self-driving cars. But co-author Jie Zhang claims that the proprietary systems used in self-driving cars are “usually built upon the existing open-source models,” and “we can be certain that their models must also have similar issues.”
We’re thinking: Computer vision isn’t the only technology used by self-driving cars to detect objects. Most self-driving car manufacturers rely on lidar and radar in addition to cameras. Those technologies are blind to color and gender differences and, in the view of many engineers, make better choices for this application.
A MESSAGE FROM DEEPLEARNING.AI

Want to learn how to fine-tune large language model-based agents? In our upcoming webinar with Weights and Biases, you’ll gain insights and techniques to enhance agent performance and specificity in automating applications. Register now

Limits on AI in Life Insurance
The U.S. state of Colorado started regulating the insurance industry’s use of AI.
What’s new: Colorado implemented the first law that regulates use of AI in life insurance and proposed extending the limits to auto insurers. Other states have taken steps to rein in both life and auto insurers under earlier statutes.
How it works: States are responsible for regulating the insurance industry in the U.S. Colorado’s rules limit kinds of data life insurers can use and how they can use it. They took effect in November based on a law passed in 2021.
- Data considered “traditional” is fair game. This category includes medical information, family history, occupation, criminal history, prescription drug history, and finances.
- Insurers that use models based on nontraditional data such as credit scores, social media activity, and shopping histories must report their use, with a description of each model, its purpose, and what data it’s based on. Insurers must test such models for biases and report the results.
- Insurers are required to document guiding principles for model development and report annual reviews of both their governance structures and risk-management frameworks.
Other states: California ordered all insurers to notify regulators when their algorithm results in an increase to a customer’s premium; regulators can then evaluate whether the effect of the rate increase is excessive and/or discriminatory. Agencies in Connecticut and New York ordered all insurers to conform their use of AI with laws against discrimination. Washington D.C. opened an investigation to determine whether auto insurers’ use of data resulted in outcomes that discriminated against certain groups.
Behind the news: Colorado shared an initial draft of its life-insurance regulations earlier this year before revising it. Among other changes, the initial draft prohibited AI models that discriminate not only on the basis of race but with respect to all protected classes; prevent unauthorized access to models; create a plan to respond to unforeseen consequences of their models; and engage outside experts to audit their models. The final draft omits these requirements.
Why it matters: Regulators are concerned that AI could perpetuate existing biases against marginalized groups, and Colorado’s implementation is likely to serve as a model for further regulation. Insurance companies face a growing number of lawsuits over claims that their algorithms wrongfully discriminate by age or race. Regulation could mitigate potential harms and ease customers’ concerns.
We’re thinking: Reporting of models that use social posts, purchases, and the like is a good first step, although we suspect that further rules will be needed to govern the complexities of the insurance business. Other states’ use of Colorado's regulations as a blueprint would avoid a state-by-state patchwork of contradictory regulations.

Robot, Find My Keys
Researchers proposed a way for robots to find objects in households where things get moved around.
What's new: Andrey Kurenkov and colleagues at Stanford University introduced Node Edge Predictor, a model that learned to predict where objects were located in houses.
Key insight: A popular way to represent objects and their locations is a graph, in which each node is either an object or its location and an edge connects the two. If we want to track objects over time, a recurrent model could predict the locations of objects using a separate graph for each time step, but that would require a prohibitive number of graphs. Instead, a model can predict locations using a single graph in which each edge is annotated, additionally, with the time elapsed since the associated object was seen in the associated location. The model learns to predict the next most likely place to find an object based on the object’s most recent, frequent, and longstanding locations.
How it works: The authors simulated a robot looking for things in a household. They built (i) a simulator of houses, object locations, and when and where they moved; (ii) a graph that represented a house containing objects; and (iii) a machine learning system that predicted where objects might be found.
- The simulator presented a household in which objects moved randomly over time — as if people were moving them — according to predefined probabilities. For example, a mug might move from a cabinet to a table. At each time step, a simulated robot observed one piece of furniture and the objects on or inside it.
- The robot represented its observations as a graph. The nodes included rooms, furniture, and objects, while edges connected each object to every piece of furniture and every piece of furniture to a room. The node and edge embeddings represented the robot’s past observations; for example, where it last saw the mug, time elapsed since that observation, and how many times it had seen the mug there.
- The authors simulated the robot moving through 100 households with various floor plans. They built a training set of 10,000 graphs.
- They trained the machine learning system to predict whether an object was on/in a given piece of furniture (that is, whether an edge connected a given object and location at the current timestep). The system embedded previously observed nodes and edges using a separate vanilla neural network for each, concatenated the embeddings, and fed them to a graph neural network followed by a two-layer transformer. A vanilla neural network at the end of the transformer generated probabilities for all edges that connected a given object to various pieces of furniture.
Results: The authors tested their system’s ability to find a single object in a house versus a few baseline methods. The baselines included random guessing, always guessing the piece of furniture where the object was last seen, and a Bayesian model that guessed whether the object was on/in a given piece of furniture based on the percentage of times it had been seen there. On average, their system found the object in 3.2 attempts, while the next best model (Bayesian) took 3.6 attempts. Guessing the last-seen location required 6.0 attempts, and random guessing required 8.8 attempts.
Why it matters: Feature engineering helps to find the best way to represent data so a model can learn from it. In this work, engineering time-related features (such as the time elapsed since an object was on a piece of furniture or the number of times an object was observed on a piece of furniture over time) enabled a non-recurrent model to learn how graphs change over time.
We’re thinking: A physical robot likely would use object detection on its camera feed instead of a simulator that told it directly which objects were associated with which pieces of furniture. We look forward to future work that proves the concept using this more realistic setup.
Data Points
Microsoft announces £2.5 billion investment to boost the UK’s AI capabilities
The investment aims to double Microsoft’s UK datacenter footprint by 2026, train or retrain over one million people for the AI economy, and extend Microsoft’s Accelerating Foundation Models Research (AFMR) program to prioritize GPU access for the UK’s research community. (Read more at Microsoft)
Research finds opportunities and risks as heritage organizations embrace AI
A new study focuses on what innovation in AI looks like in the UK heritage sector, and showcases its diverse uses in museums, galleries, libraries, and archives. Notable examples include predictive analytics for exhibition popularity at the National Gallery. However, the study also highlighted risks such as discrimination, misinformation, copyright infringement, and transparency issues. (Read more at Museum Association)
U.S. mandates Saudi venture capital firm must sell stake in Silicon Valley AI firm
The Biden administration has instructed Prosperity7 to sell its shares in Rain AI, a Silicon Valley AI chip startup backed by OpenAI co-founder Sam Altman. Rain AI, which designs AI chips inspired by brain functionality, had Prosperity7 as a lead investor in a funding round that raised $25 million in 2022. (Read the news story at Bloomberg)
Generative AI regulation allegedly stalls EU legislation talks
Sources revealed that negotiations on foundation models have become the primary hurdle, with a risk of shelving the act before European parliamentary elections next year unless an agreement is reached. France, Germany, and Italy form an important bloc of countries opposing foundation models. Pending issues also include establishing a definition of AI and national security exceptions. Critics argue that self-regulation may fall short of safety standards for foundation models, creating legal uncertainty and impeding European industries' planning. (Read the article at Reuters)
AI fuels innovations in Pennsylvania's infrastructure projects
In Pennsylvania, U.S., where 13 percent of bridges face structural deficiencies, engineers are leveraging AI to address challenges like the development of lighter concrete blocks for construction and noise-absorbing walls along highways. The projects aim to create more resilient structures at a reduced cost. The use of AI in civil engineering could revolutionize project development, early damage detection, and real-time incident analysis, but careful consideration and regulations are urged to ensure safety and reliability. (Read the article in The New York Times)
Anduril's Roadrunner: AI combat drone takes flight
Anduril's latest innovation combines AI technology and jet-powered capabilities to counter the escalating threat of low-cost, sophisticated aerial attacks. The modular and autonomous Roadrunner drone aims to provide rapid response and heightened resilience against evolving threats such as suicide drones. (Read more at Wired)
General Motors to reduce investment in Cruise self-driving division next year
Following recent accidents involving its self-driving taxis in San Francisco, the company, initially planning expansion to multiple cities, now focuses on rebuilding trust with regulators and communities. The decision to reduce spending follows the suspension of Cruise's robotaxi license in California and a need to regain public trust in the wake of safety incidents, including a pedestrian fatality. (Read the article at The New York Times)
Sam Altman returns as OpenAI CEO
Besides Altman’s return, Mira Murati reassumed her role as CTO, and Greg Brockman returned as President. For now, the new board comprises former Salesforce CEO Bret Taylor (Chair), economist Larry Summers, and Quora CEO Adam D’Angelo. (Read the blog post at OpenAI)
Consortium of major companies develops data provenance standards to enhance trust in AI
Many companies (including American Express, IBM, and Walmart) formed the Data & Trust Alliance, introducing new standards for data provenance in AI applications. These standards cover eight basic criteria, including lineage, source, legal rights, and data type. The goal is to offer clear data documentation and bolster efficiency and trust in AI developments. (Read more at The New York Times)
Amazon Web Services (AWS) introduces Titan models in Amazon Bedrock
Amazon’s Titan Image Generator and Titan Multimodal Embeddings offer image, multimodal, and text options through a fully managed API. The Titan Image Generator enables content creators to generate images using natural language prompts, targeting applications in advertising, e-commerce, and media. The Titan Multimodal Embeddings facilitate the creation of contextually relevant multimodal search and recommendation experiences. (Read the blog post at AWS)
Voicemod launches feature to craft and share custom synthetic voices
The app, known for its AI voice-changing program popular in the gaming and streaming communities, now enables users to craft and share their unique AI voices by modifying their own voices or choosing from various genders, ages, and tones. (Read more at The Verge)
Demand keeps soaring for prompt engineers
Prompt engineering emerged as a lucrative and sought-after skill in the year since the public launch of ChatGPT. Google searches for "prompt engineering" have skyrocketed, and LinkedIn reports substantial increases in related terms on member profiles. The skillset, involving coaxing AI systems for better results and training colleagues in using generative AI, is in high demand. Newly-created roles offer significant compensation, often upwards of $335,000 annually. (Read the analysis at Bloomberg)
Research: Deep learning model offers precision in predicting breast cancer outcomes
The Histomic Prognostic Signature (HiPS), which evaluates both cancerous and non-cancerous cell patterns, outperformed expert pathologists in predicting disease progression. By identifying breast cancer patients classified as high or intermediate risk who could become long-term survivors, the tool offers the potential to reduce the duration or intensity of chemotherapy, sparing patients from harmful side effects. (Read the article via Northwestern University)
IBM expands geospatial AI collaboration to tackle climate challenges globally
The initiative involves mapping urban heat islands in the UAE, supporting Kenya's reforestation campaign, and enhancing climate resiliency in the UK's aviation sector. Additionally, IBM is collaborating with NASA to develop a new model for weather and climate, aiming to improve the precision and efficiency of weather forecasting and address climate-related challenges on a global scale. (Read more at IBM)