
Dear friends,
It is only rarely that, after reading a research paper, I feel like giving the authors a standing ovation. But I felt that way after finishing Direct Preference Optimization (DPO) by Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Chris Manning, and Chelsea Finn. (I didn't actually stand up and clap, since I was in a crowded coffee shop when I read it and would have gotten weird looks! 😀)
This beautiful work proposes a much simpler alternative to RLHF (reinforcement learning from human feedback) for aligning language models to human preferences. Further, people often ask if universities — which don't have the massive compute resources of big tech — can still do cutting-edge research on large language models (LLMs). The answer, to me, is obviously yes! This article is a beautiful example of algorithmic and mathematical insight arrived at by an academic group thinking deeply.
RLHF became a key algorithm for LLM training thanks to the InstructGPT paper, which adapted the technique to that purpose. A typical implementation of the algorithm works as follows:
- Get humans to compare pairs of LLM outputs, generated in response to the same prompt, to specify which one they prefer. For example, humans typically prefer the more helpful, less toxic output.
- Use the human preferences to learn a reward function. The reward function, typically represented using a transformer network, is trained to give a higher reward (or score) to the outputs that the humans preferred.
- Finally, using the learned reward, run a reinforcement learning algorithm to tune the LLM to (i) maximize the reward of the answers generated, while (ii) not letting the LLM change too much (as a form of regularization).
This is a relatively complex algorithm. It needs to separately represent a reward function and an LLM. Also, the final, reinforcement learning step is well known to be finicky to the choice of hyperparameters.
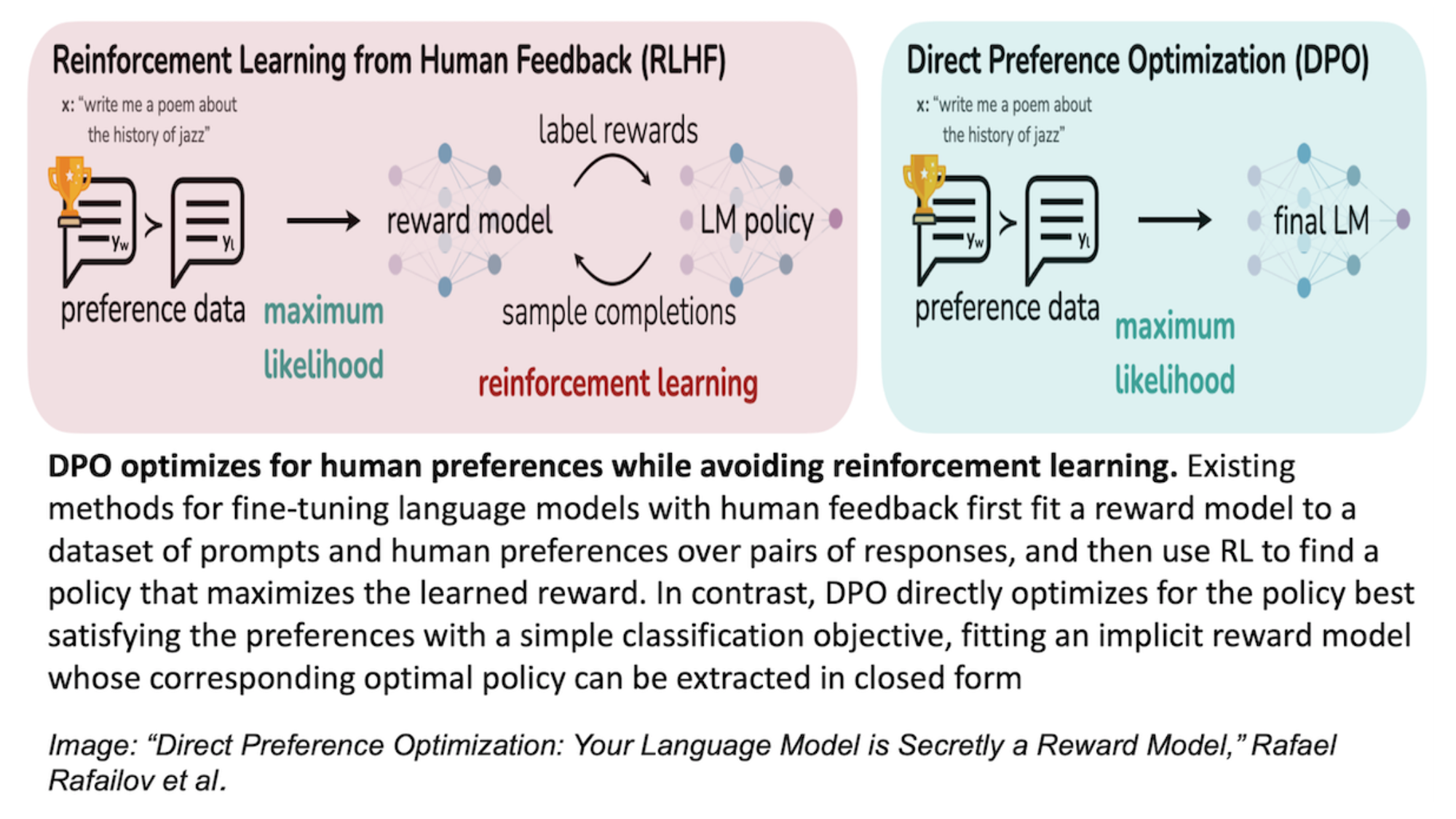
DPO dramatically simplifies the whole thing. Rather than needing separate transformer networks to represent a reward function and an LLM, the authors show how, given an LLM, you can figure out the reward function (plus regularization term) that that LLM is best at maximizing. This collapses the two transformer networks into one. Thus, you now need to train only the LLM and no longer have to deal with a separately trained reward function. The DPO algorithm trains the LLM directly, so as to make the reward function (which is implicitly defined by the LLM) consistent with the human preferences. Further, the authors show that DPO is better at achieving RLHF's optimization objective (that is, (i) and (ii) above) than most implementations of RLHF itself.
RLHF is a key building block of the most advanced LLMs. It’s fantastic that these Stanford authors — through clever thinking and mathematical insight — seem to have replaced it with something simpler and more elegant. While it's easy to get excited about a piece of research before it has stood the test of time, I am cautiously optimistic that DPO will have a huge impact on LLMs and beyond in the next few years. Indeed, it is already making its way into some top-performing models, such as Mistral’s Mixtral.
That we can replace such fundamental building blocks of LLMs is a sign that the field is still new and much innovation lies ahead. Also, while it's always nice to have massive numbers of NVIDIA H100 or AMD MI300X GPUs, this work is another illustration — out of many, I want to emphasize — that deep thinking with only modest computational resources can carry you far.
A few weeks ago at NeurIPS (where DPO was published), I found it remarkable both (i) how much highly innovative research there is coming out of academic labs, independent labs, and companies small and large, and (ii) how much our media landscape skews attention toward work published by the big tech companies. I suspect that if DPO had been published by one of the big LLM companies, it would have made a huge PR splash and been announced as a massive breakthrough. Let us all, as builders of AI systems, make sure we recognize the breakthroughs wherever they occur.
Keep learning!
Andrew
P.S. We just launched our first short course that uses JavaScript! In “Build LLM Apps with LangChain.js,” taught by LangChain’s founding engineer Jacob Lee, you’ll learn many steps that are common in AI development, including how to use (i) data loaders to pull data from common sources such as PDFs, websites, and databases; (ii) different models to write applications that are not vendor-specific; and (iii) parsers that extract and format the output for your downstream code to process. You’ll also use the LangChain Expression Language (LCEL), which makes it easy to compose chains of modules to perform complex tasks. Putting it all together, you’ll build a conversational question-answering LLM application capable of using external data as context. Please sign up here!
News
Deep Learning Discovers Antibiotics
Biologists used neural networks to find a new class of antibiotics.
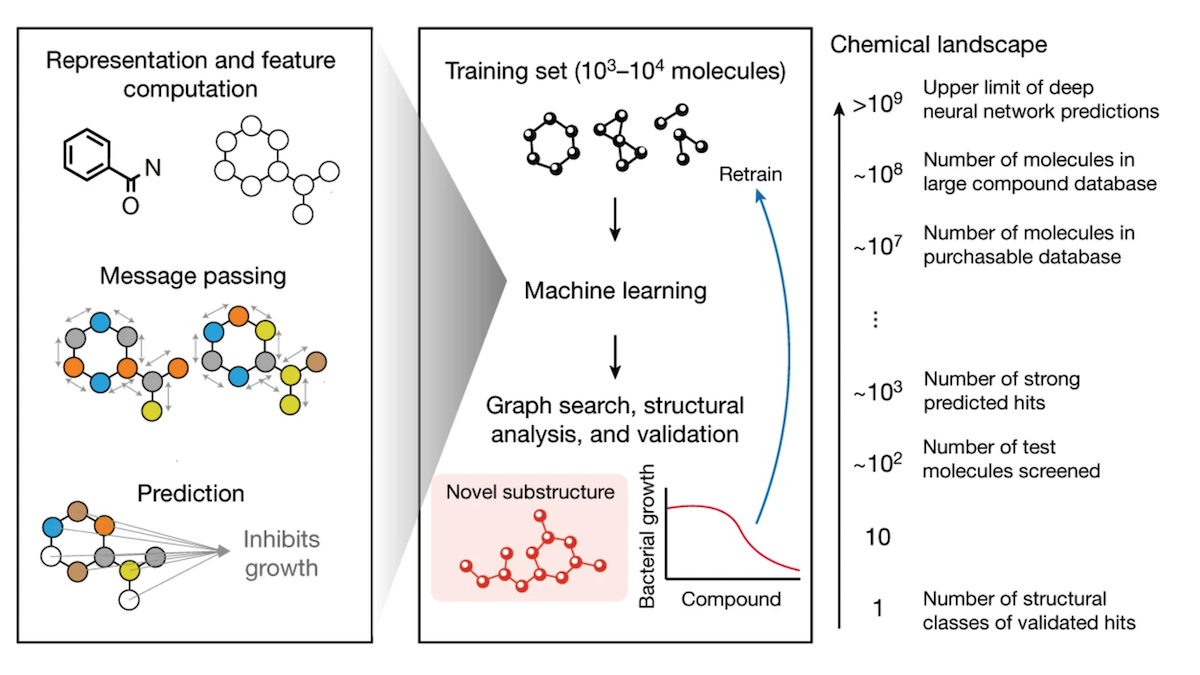
What’s new: Researchers at MIT and Harvard trained models to screen chemical compounds for those that kill methicillin-resistant Staphylococcus aureus (MRSA), the deadliest among bacteria that have evolved to be invulnerable to common antibiotics, and aren’t toxic to humans.
How it works: The authors built a training set of 39,312 compounds including most known antibiotics and a diverse selection of other molecules. In a lab, they tested each compound for its ability to inhibit growth of MRSA and its toxicity to human liver, skeletal muscle, and lung cells. Using the resulting data, they trained four ensembles of 20 graph neural networks each to classify compounds for (i) antibiotic properties, (ii) toxicity to the liver, (iii) toxicity to skeletal muscles, and (iv) toxicity to the lungs.
- They ran their four ensembles on 12 million compounds from the Mcule database and a Broad Institute database. They filtered out compounds with the lowest probability of being antibiotics and the highest probability of being toxic to humans, leaving 3,646 antibiotic, low-toxicity compounds.
- Within these compounds, they found the minimal chemical structure responsible for the antibiotic properties. To do this, they removed atoms or rings of atoms from a molecule’s edges, predicted the probability that the modified molecule was an active antibiotic, and repeated these steps until the probability fell below a threshold. Compounds that share a chemical structure are likely to work in similar ways within the body, giving scientists a pathway to discover further compounds with similar benefits.
Results: Of the compounds predicted to be likely antibiotics and nontoxic, the authors lab-tested 241 that were not known to work against MRSA. Of those, 8.7 percent inhibited the bacterium’s growth. This exceeds the percentage of antibiotics in the training set (1.3 percent), suggesting that the authors’ approach could be a useful first step in finding new antibiotics. The authors also tested 30 compounds predicted not to be antibiotics. None of them (0 percent) inhibited the bacterium’s growth — further evidence that their approach could be a useful first step. Two of the compounds that inhibited MRSA share a similar and novel mechanism of action against bacteria and also inhibited other antibiotic-resistant infections in lab tests. One of them proved effective against MRSA infections in mice.
Behind the news: Most antibiotics currently in use were discovered in the mid-20th century, a golden age of antibiotics, which brought many formerly deadly pathogens under control. Modern techniques, including genomics and synthetic antibiotics, extended discoveries through the end of the century by identifying variants on existing drugs. However, in the 21st century, new antibiotics have either been redundant or haven’t been clinically successful, a report by the National Institutes of Health noted. At the same time, widespread use of antibiotics has pushed many dangerous bacteria to evolve resistance. Pathogens chiefly responsible for a variety of ailments are generally resistant even to antibiotics reserved for use as a last resort.
Why it matters: Antibiotic-resistant infections are among the top global public health threats directly responsible for 1.27 million deaths in 2019, according to the World Health Organization. New options, as well as efforts to fight the emergence of resistant strains, are needed.
We’re thinking: If neural networks can identify new classes of medicines, AI could bring a golden age of medical discovery. That hope helps to explain why pharmaceutical companies are hiring machine learning engineers at unprecedented rates.

OpenAI Revamps Safety Protocol
Retrenching after its November leadership shakeup, OpenAI unveiled a new framework for evaluating risks posed by its models and deciding whether to limit their use.
What’s new: OpenAI’s safety framework reorganizes pre-existing teams and forms new ones to establish a hierarchy of authority with the company’s board of directors at the top. It defines four categories of risk to be considered in decisions about how to use new models.
How it works: OpenAI’s Preparedness Team is responsible for evaluating models. The Safety Advisory Group, whose members are appointed by the CEO for year-long terms, reviews the Preparedness Team’s work and recommends approaches to deploying models and mitigating risks, if necessary. The CEO has the authority to approve and oversee recommendations, overriding the Safety Authority Group if needed. OpenAI’s board of directors can overrule the CEO.
- The Preparedness Team scores each model in four categories of risk: enabling or enhancing cybersecurity threats, helping to create weapons of mass destruction, generating outputs that affect users’ beliefs, and operating autonomously without human supervision. The team can modify these risk categories or add new categories in response to emerging research.
- The team scores models in each category using four levels: low, medium, high, or critical. Critical indicates a model with superhuman capabilities or, in the autonomy category, one that can resist efforts to shut it down. A model’s score is its highest risk level in any category.
- The team scores each model twice: once after training and fine-tuning, and a second time after developers have tried to mitigate risks.
- OpenAI will not release models that earn a score of high or critical prior to mitigation, or a medium, high, or critical after mitigation.
Behind the news: The Preparedness Team and Safety Advisory Group join a number of safety-focused groups within OpenAI. The Safety Systems Team focuses on mitigating risks after a model has been deployed; for instance, ensuring user privacy and preventing language models from providing false information. The Superalignment Team, led by Ilya Sutskever and Jan Leike, is charged with making sure hypothetical superintelligent systems, whose capabilities would surpass humans, adhere to values that benefit humans.
Why it matters: AI is an extraordinarily powerful technology whose ultimate impacts are difficult to foresee. OpenAI has invested consistently in AI safety since its inception — even if purportedly cautious moves like keeping its GPT-2 large language model under wraps often looked as much like publicity stunts as safety measures — and its practices are likely to influence those of other AI companies. Furthermore, OpenAI has faced internal chaos partly over concerns about safety and governance. Clear protocols in these areas could prevent future strife and stabilize the company to the benefit of its users, employees, and investors.
We’re thinking: OpenAI’s safety framework looks like a step forward, but its risk categories focus on long-term, low-likelihood outcomes (though they stop short of considering AI’s hypothetical, and likely mythical, existential risk to humanity). Meanwhile, clear and present safety issues, such as social bias and factual accuracy, are well known to afflict current models including OpenAI’s. We hope that the Preparedness Team promptly adds categories that represent safety issues presented by today’s models.
A MESSAGE FROM DEEPLEARNING.AI

In this short course, you’ll dive into LangChain.js, a JavaScript framework for building applications based on large language models, and learn how to craft powerful, context-aware apps. Elevate your machine learning-powered development skills using JavaScript. Sign up today

AGI Defined
How will we know if someone succeeds in building artificial general intelligence (AGI)? A recent paper defines milestones on the road from calculator to superintelligence.
What’s new: Researchers at Google led by Meredith Ringel Morris propose a taxonomy of AI systems according to their degree of generality and ability to perform cognitive tasks. They consider today’s large multimodal models to be “emerging AGI.”
AGI basics: Artificial general intelligence is commonly defined as AI that can perform any intellectual task a human can. Shane Legg (who co-founded DeepMind) and Ben Goertzel (co-founder and CEO of SingularityNet) coined the term AGI for a 2007 collection of essays. Subsequently, companies like DeepMind and OpenAI, which explicitly aim to develop AGI, propelled the idea into the mainstream.
How it works: The taxonomy categorizes systems as possessing narrow skills (not AGI) or general capabilities (AGI). It divides both narrow and general systems into five levels of performance beyond calculator-grade Level 0. It also includes a metric for degree of autonomy.
- Narrow systems perform one distinct task; they may perform at one of the five levels, but they are not AGI. General systems perform a range of tasks (which the authors don’t specify) that align with real-world activities of broad value to people, including but not limited to linguistic, mathematical, logical, spatial reasoning, social, learning, and creative tasks. Crucially, they can learn how to learn new skills and when to ask humans for more information. The authors classify general systems as AGI at various levels of performance.
- Level 1 (“emerging”) matches or slightly exceeds unskilled humans. Levels 2 (“competent”), 3 (“expert”), and 4 (“virtuoso”) systems surpass the 50th, 90th and 99th percentiles of skilled human performance, respectively. Level 5 (“superhuman” or “artificial superintelligence”) outperforms 100 percent of skilled humans.
- Most current systems that perform at Level 2 or higher are narrow. For example, AlphaFold, which finds the shapes of protein molecules, achieves Level 5 performance but only in a single task. On the other hand, the authors consider large language models like Bard, ChatGPT, and Lama 2 to be general systems at Level 1 (although their performance may achieve Level 2 in some tasks).
- The authors’ autonomy scale ranges from tools for which humans control the task while the system automates subtasks (the first level of autonomy) to agents that act independently (the fifth). Higher levels of performance can unlock higher levels of autonomy. For instance, Level 4 AGI may be necessary to enable fully autonomous vehicles that are safe and trustworthy.
Yes, but: The authors’ definition identifies some classes of tasks that contribute to generality, but it includes neither a list of tasks a system must perform to be considered general nor a method for selecting them. Rather, the authors call on the research community to develop a “living benchmark” for generality that includes a mechanism for adding novel tasks.
Why it matters: AGI is one of the tech world’s hottest buzzwords, yet it has had no clear definition, and various organizations propose different definitions. This lack of specificity makes it hard to talk about related technology, regulation, and other topics. The authors’ framework, on the other hand, supports a more nuanced discussion of the path toward AGI. And it may have high-stakes business implications: Under the terms of their partnership, OpenAI can withhold from Microsoft models that attain AGI. Applying the authors’ taxonomy would make it harder for one of the parties to move the goalposts.
We’re thinking: Defining AGI is tricky! For instance, OpenAI defines AGI as “a highly autonomous system that outperforms humans at most economically valuable work.” This definition, had it been formulated in the early 1900s, when agriculture accounted for 70 percent of work globally, would have described the internal combustion engine.

Text or Images, Input or Output
GPT-4V introduced a large multimodal model that generates text from images and, with help from DALL-E 3, generates images from text. However, OpenAI hasn’t fully explained how it built the system. A separate group of researchers described their own method.
What's new: Jing Yu Koh, Daniel Fried, and Ruslan Salakhutdinov at Carnegie Mellon University proposed Generating Images with Large Language Models (GILL), a training method that enables a large language model and a text-to-image generator to use both text and images as either input or output. Given text and/or image input, it decides whether to retrieve existing images or generate new ones.
Key insight: Models like CLIP and ImageBind map text and image inputs to a similar embedding space, so closely related text and images have similar embeddings. This approach enables a large multimodal model to process both data types. Text outputs, too, can be mapped to the same embedding space, so an image decoder, such as a diffusion model, can use them to produce images or an image retriever to retrieve images.
How it works: The authors used a pretrained OPT large language model, ViT-L image encoder (taken from CLIP), and pretrained Stable Diffusion text-to-image generator. The authors trained ViT-L to map its embeddings to those produced by OPT. They trained OPT to recognize prompts that request an image and enabled the system to either generate or retrieve images. Finally, a separate linear classifier learned whether to retrieve or generate images.
- The authors froze the ViT-L, added a linear layer, and trained it as follows: Given an image, the ViT-L-plus-linear-layer produced an image embedding, as usual. Given the image embedding and the first part of the corresponding caption, OPT iteratively tried to predict the next word. The linear layer learned how to modify the embedding so OPT could complete the caption. This enabled OPT to take images as input.
- They added 8 tokens to OPT’s vocabulary and trained the model to emit them at the end of every image caption — a signal that an image should be either retrieved or generated. (Typically a single token is sufficient to denote the end of a caption. However, these tokens corresponded to embeddings that, later, would be used to generate an image, and the authors found that a single token was not sufficiently expressive.)
- Then they enabled Stable Diffusion to produce an image when OPT generated the 8 new tokens. They trained a separate transformer to map OPT’s embeddings associated with the 8 tokens (that is, embeddings produced by the layer before the one that generated the tokens) to those produced by Stable Diffusion’s text encoder.
- Next they enabled the system to retrieve images when OPT generated the 8 tokens. They added linear layers to ViT-L and OPT and trained them to map the ViT-L’s embeddings to the OPT embedding associated with the first token. Specifically, the linear layers learned to minimize the difference between their outputs.
- The authors trained a linear classifier, given the 8 OPT embeddings associated with the tokens, to decide whether to retrieve or generate an image. To build the classifier’s training set, they selected captions from a collection of diverse human-written prompts and, for each one, both generated an image and retrieved the most similar image from CC3M. 5 human judges selected the image that best matched the prompt. This process yielded 900 examples annotated according to whether the image was retrieved or generated.
- At inference, OPT generated tokens and fed the associated embeddings directly to the classifier, which activated the pipeline for either the generation or retrieval.
Results: VIST is a dataset of 20,000 visual stories, each of which comprises five captioned images. The authors evaluated GILL’s and Stable Diffusion’s abilities, given the final caption or all five captions, to generate the final image in each story based on CLIP similarity scores between generated and ground-truth images. Given one caption, GILL achieved 0.581 similarity and Stable Diffusion achieved 0.592 similarity. Given five captions, GILL achieved 0.612 similarity and Stable Diffusion scored 0.598 similarity, highlighting GILL’s ability to use the context afforded by more extensive input. It did even better (0.641 similarity) given both captions and images, which Stable Diffusion couldn’t handle. The authors also evaluated how well their system retrieved the correct last image from VIST given the 5 captions and the first 4 images. GILL retrieved the correct image 20.3 percent of the time, while their own FROMAGe retrieved the correct image 18.2 percent of the time. In comparison, CLIP, given the 5 captions (without the images), retrieved the correct image 8.8 percent of the time.
Why it matters: Models that wed text and images are advancing rapidly. GILL and other recent models extend single-image input and/or output to any combination of images and text. This capability — which GILL achieves by mapping embeddings of image and text to one another — gives the models more context to generate more appropriate output.
We’re thinking: The authors add an interesting twist: Rather than generating images, the system can choose to retrieve them. Sometimes an existing image will do.
A MESSAGE FROM LANDING AI

Join a free webinar on January 11, 2024, featuring experts from Snowflake and Landing AI to explore how large vision models (LVMs) are transforming the image processing landscape. Learn more about the session and register here
Data Points
What happens when beloved cartoon Mickey Mouse enters the public domain in the era of generative AI? What’s the latest AI-driven addition to PC keyboards?
These items and other AI news are explored in a new edition of Data Points, a spinoff of our weekly newsletter, The Batch.