
Dear friends,
I just finished reading BJ Fogg’s new book, Tiny Habits: The Small Changes That Change Everything. Fogg explains that the best way to build a new habit is to start small and succeed, rather than starting too big and giving up. For example, rather than trying to exercise for 30 minutes a day, he recommends aspiring to do just one push-up, and doing it consistently.

This approach may be helpful to those of you who want to spend more time studying. If you hold yourself accountable for watching, say, 10 seconds of an educational video every day — and you do so consistently — the habit of studying daily will grow naturally. Even if you learn nothing in that 10 seconds, you’re establishing the habit of studying a little every day. On some days, maybe you’ll end up studying for an hour.
Over the years, I have found a few resources for developing personal productivity that I love. My top picks include Getting Things Done by David Allen, the classic The 7 Habits of Highly Effective People by Stephen R. Covey, and Learning How to Learn Barbara Oakley (I recommend the Coursera course). I’m tempted to add Tiny Habits to this list.
Keep learning!
Andrew
DeepLearning.ai Exclusive

Working AI: Science Accelerator
Google, Facebook, and Amazon aren’t the only places to work on cutting-edge AI products. Archis Joglekar parlayed his study of nuclear physics into a job building models at Noble.ai, where he helps other scientists speed up R&D. Read more
News

Stopping Coronavirus
A company that analyzes online information to predict epidemics spotted the upsurge in coronavirus at least a week ahead of public-health authorities.
What’s new: Canadian startup BlueDot alerted customers to the outbreak in the Chinese city of Wuhan on New Year’s Eve, Wired reported. The U.S. Centers for Disease Control and Prevention issued its warning on January 6, and the World Health Organization followed suit three days later. The respiratory illness as of this writing has infected more than 6,000 people and killed more than 130, mostly in China.
How it works: Founded in 2014, BlueDot aims to stop the spread of infectious diseases by giving healthcare workers early warning, so they can identify and treat people who become infected.
- The company’s natural language processing model ingests 100,000 articles in 65 languages daily to track more than 100 infectious diseases. It ignores social media but scans news reports, government information, blogs, and forums related to human, plant, and animal diseases, as well as travel ticketing and local weather data.
- Human analysts vet the model’s predictions. They issue reports to customers in business, government, and nongovernmental organizations, ultimately reaching healthcare facilities and public health officials in a dozen countries.
Behind the news: In 2008, Google undertook a similar effort to forecast influenza outbreaks based on search terms entered by users. In initial research, Google Flu Trends tracked the number of cases two weeks faster than the CDC. However, it dramatically underestimated the peak of the 2013 flu season and was shuttered soon afterward. Subsequent analysis concluded that the algorithm overfit seasonal search terms unrelated to flu.
Why it matters: Rapid detection of new diseases is crucial to avoid global pandemics. Virulent diseases often can be contained if they’re caught early enough, but every hour compounds the number of people exposed and thus the number of cases. An epidemic can quickly overwhelm healthcare systems, leaving people even more exposed.
We’re thinking: It’s hard to know how well today’s techniques will play out tomorrow. But the ability to catch potential pandemics before they explode is too valuable not to try.
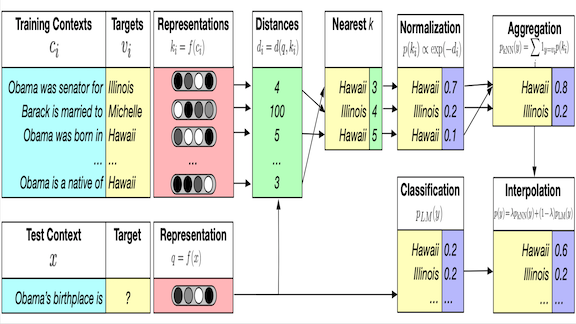
Helpful Neighbors
School teachers may not like to hear this, but sometimes you get the best answer by peeking at your neighbor’s paper. A new language model framework peeks at the training data for context when making a prediction.
What’s new: Facebook AI and Stanford researchers led by Urvashi Khandelwal enhanced language models that predict the next word in an incomplete sentence by enabling them to search for potential answers in the training data. They call their algorithm kNN-LM.
Key insight: It’s much easier for a model to identify two sentence fragments that have similar meanings than it is to complete them. kNN-LM takes advantage of the easier task to improve performance on the harder one. Given a sentence fragment and asked to predict the next words, it searches the training set for sentences similar to that sentence fragment and uses what it finds to help predict the missing words. For example, the model might match a target starting, “Dickens is the author of ___,” with the training sentence, “Dickens wrote Oliver Twist.” The model then knows that “Oliver Twist” may be appropriate to add to the target.
How it works: The authors offer a pretrained model, vector representations of training sentences, and an algorithm for combining information when analyzing a test sentence. Their approach works with any pretrained neural language model, but they used transformer networks in most experiments.
- kNN-LM starts by generating vector representations of every sequence in the training set. Then it searches these vectors for the k-nearest neighbor vector representations of the new input sequence. The closer a training sequence’s vector is to the input’s vector, the more heavily it weights the training sequence’s next token.
- The neural language model also directly predicts the next token for the input.
- Then it factors both the k-nearest neighbors prediction and language model’s prediction into a final decision. A hyperparameter controls how heavily it considers each one.
Results: Tested on a dataset of Wikipedia articles, kNN-LM achieved a score of 15.79 for perplexity, a measure of predictive accuracy, more than 10 percent better than the previous state-of-the-art model.
Why it matters: Language models likely won’t interpret technical terms found in, say, the NuerIPS proceedings, if they’re trained on Wikipedia. kNN-LM lets them find less related words in the training data, potentially improving generalization to obscure subject matter.
We’re thinking: A key step for winning computer vision competitions like ImageNet has been to train multiple models and ensemble (or average) them. This confers perhaps a 1 percent boost in performance, but it’s impractical for most applications because of the computational expense. kNN-LM appears to require a significant computational expense as well, and we look forward to researchers diving deeper into the computational implications.

The Right Problem for Your Solution
A new tool connects novice programmers with projects that match their experience and interests.
What’s new: Github’s Good First Issues tool uses deep learning to find easy-to-fix issues among the collaborative software development platform’s multitude of open source projects.
How it works: Github, which is owned by Microsoft, enables developers to collaborate freely worldwide. Participants often flag bugs to be fixed or features to be implemented, but beginners may have trouble figuring out which are appropriate to their skill level.
- Github trained a deep learning model on a dataset of issues labeled with designations like “beginner friendly,” “low-hanging fruit,” and “easy bug fix.” The metadata also noted whether issues were closed by someone who had not previously contributed to the repository and how many lines of code were involved.
- The model assigns a probability score to new issues based on how likely they are to be easily fixed. Users can browse by problem type or project. If they’ve been sufficiently active on Github, they can receive a list of open issues suited to their previous contributions.
Behind the news: An earlier version used traditional computing to query a list of 300 beginner-friendly labels. However, it surfaced only about 40 percent of relevant issues, the company said.
Why it matters: Github is a focal point of software development and the heart of the open source movement. Helping people figure out where they can have the most impact can only make it more productive.
We’re thinking: What a great tool for aspiring developers! When jumping into AI (or, indeed, most disciplines), it’s better to start small and succeed than to start too big and fail.
A MESSAGE FROM DEEPLEARNING.AI
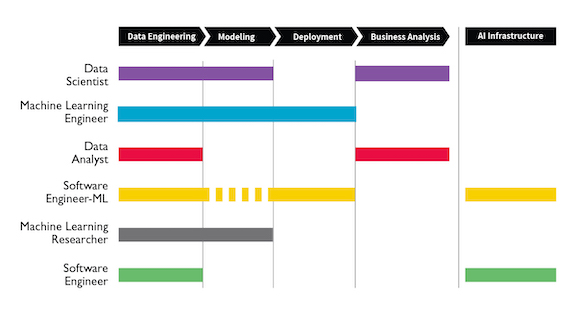
How can you advance your AI career as a machine learning engineer, data scientist, or software engineer? This report from Workera, a deeplearning.ai company, walks you through the career paths you can take, tasks you’ll work on, and skills recruiters are looking for. Download the report
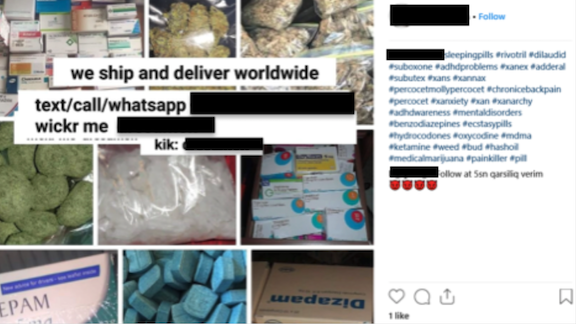
Hunting Online Drug Dealers
Can machine learning help address the scourge of opioid addiction?
What’s new: A public health researcher developed a neural network that spots sellers of opioids on social media, Recode reported.
How it works: The model built by University of California professor Tim K. Mackey sifts through Instagram profiles to find those that offer drugs.
- In past research, Mackey identified Instagram as a popular platform for dealers. His team collected posts mentioning opioids and manually confirmed 12,857 that offered opioids for sale.
- The researchers used half the data to train a model to identify language that correlated with drug advertisements. They used the other half to validate the trained model.
- The neural net found 1,228 ads posted by 267 unique users. It achieved F1 scores of 95 percent for precision and accuracy, outperforming models based on random forests, decision trees, and support vector machines.
- The U.S. Department of Health and Human Services has contracted with Mackey to expand his method to cover Reddit, Tumblr, and YouTube. He’s also building a commercial platform for law-enforcement agencies to monitor social media streams in real time.
Yes, but: Online opioid sales represent only a small fraction of the total, RAND Corporation drug policy expert Bryce Pardo told Recode. Mackey’s tool spots small-scale dealers, but it can’t do much to bring down the cartels responsible for much of the supply, he said.
Why it matters: Shutting down suppliers could save lives. Two million Americans are addicted to opioids, and 130 people die from overdoses every day, according to the National Institute on Drug Abuse.
We’re thinking: Will dealers resort to adversarial examples to thwart such automatic detection algorithms? Unfortunately, there’s plenty of financial incentive to advertise illegal opioids on social networks.
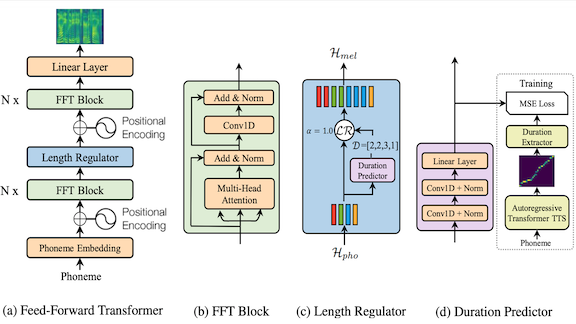
Text to Speech in Parallel
A new system marks a step forward in converting text to speech: It’s fast at inference, reduces word errors, and provides some control over the speed and inflection of generated speech.
What’s new: Yi Ren, Yangjun Ruan, and their co-authors at Zhejiang University and Microsoft propose FastSpeech, a text-to-speech system that processes text sequences in parallel rather than piece by piece.
Key insight: Previous models predict phonemes, or units of sound, sequentially. This so-called autoregressive approach lets the model base each phoneme on those that came before, so the output can flow like natural speech. But it also limits how fast the model can generate output. Instead, FastSpeech uses a duration predictor that determines the length of each phoneme. Knowing durations ahead of time allows the model to generate phoneme representations independently, yielding much faster operation while maintaining the flow.
How it works: Neural text-to-speech models typically generate a mel-spectrogram that represents the frequency spectrum of spoken words. FastSpeech generates mel-spectrograms using a variant on the transformer network known as a feed-forward transformer network (abbreviated FFT, but not to be confused with a fast Fourier transform).
- The model starts by splitting words into the phonemes they represent. A trainable embedding layer transforms the phonemes into vectors.
- The first of two FFTs applies attention to find relationships between the phonemes and generate a preliminary mel-spectrogram.
- The duration predictor (trained by a separate pretrained autoregressive text-to-speech model) determines the length of any given phoneme in spoken form. A length regulator adjusts the FFT’s output to match the predicted durations.
- A second FFT sharpens details of the mel-spectrogram, and a linear layer readies it for final output.
- The WaveGlow speech synthesizer produces speech from the final mel-spectrogram.
Results: Using the LJSpeech dataset for training and evaluation, FastSpeech was 270 times faster at generating mel-spectrograms than a transformer-based autoregressive system, and 38 times faster at generating speech output, with audio quality nearly as good. The generated speech was free of repetitions and omissions.
Why it matters: LSTMs and other autoregressive models have boosted accuracy in generating text and speech. This work highlights an important trend toward research into faster alternatives that don’t sacrifice output quality.
We’re thinking: In the long run, end-to-end systems that synthesize the output audio directly are likely to prevail. Until then, approaches like FastSpeech still have an important role.

Limits on AI Job Interviews
As employers turn to AI to evaluate job applicants, a U.S. state imposed limits on how such tools can be used.
What’s new: The Illinois legislature passed the AI Video Act, which gives candidates a measure of control over how hiring managers collect and store video interviews.
How it works: The latest generation of video screening tools typically requires applicants to record themselves answering pre-determined questions. A model analyzes their verbal performance and body language to evaluate how well they fit the bill.
- The law requires employers to notify candidates that AI may be used in their interview. They must explain what the technology does and how it works.
- Applicants can opt out of such interviews, and employers must provide an alternative that doesn’t involve AI.
Yes, but: The Illinois law does not define artificial intelligence, lawyers at Reed Smith LLC pointed out in Technology Law Dispatch. Such lack of precision could lead to disputes if candidates believe they’re being evaluated by AI while the company disagrees. Another ambiguity: The law doesn’t specify consequences for violations.
Why it matters: The move in Illinois is a concrete step amid a rising chorus of calls to rein in AI. Last week, Alphabet’s Sundar Pichai spoke out in favor of regulation, and IBM proposed guidelines for reducing algorithmic bias. The EU will vote on limits for automated decision making in February.
We’re thinking: The new law may soon run up against the Trump Administration’s recent mandate to keep barriers to innovation in AI low. Nonetheless, it’s important to strike a balance between supporting technology development and protecting the public.