
Dear friends,
Tool use, in which an LLM is given functions it can request to call for gathering information, taking action, or manipulating data, is a key design pattern of AI agentic workflows. You may be familiar with LLM-based systems that can perform a web search or execute code. Indeed, some of the large, consumer-facing LLMs already incorporate these features. But tool use goes well beyond these examples.
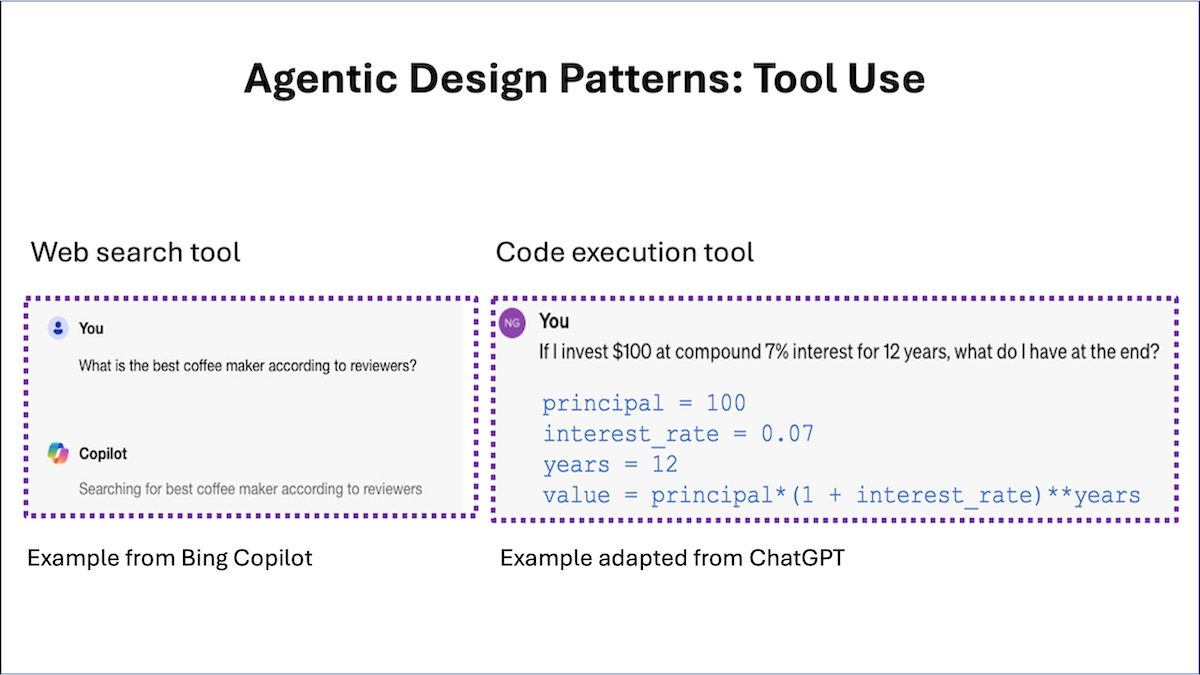
If you prompt an online LLM-based chat system, “What is the best coffee maker according to reviewers?”, it might decide to carry out a web search and download one or more web pages to gain context. Early on, LLM developers realized that relying only on a pre-trained transformer to generate output tokens is limiting, and that giving an LLM a tool for web search lets it do much more. With such a tool, an LLM is either fine-tuned or prompted (perhaps with few-shot prompting) to generate a special string like {tool: web-search, query: "coffee maker reviews"} to request calling a search engine. (The exact format of the string depends on the implementation.) A post-processing step then looks for strings like these, calls the web search function with the relevant parameters when it finds one, and passes the result back to the LLM as additional input context for further processing.
Similarly, if you ask, “If I invest $100 at compound 7% interest for 12 years, what do I have at the end?”, rather than trying to generate the answer directly using a transformer network — which is unlikely to result in the right answer — the LLM might use a code execution tool to run a Python command to compute 100 * (1+0.07)**12 to get the right answer. The LLM might generate a string like this: {tool: python-interpreter, code: "100 * (1+0.07)**12"}.
But tool use in agentic workflows now goes much further. Developers are using functions to search different sources (web, Wikipedia, arXiv, etc.), to interface with productivity tools (send email, read/write calendar entries, etc.), generate or interpret images, and much more. We can prompt an LLM using context that gives detailed descriptions of many functions. These descriptions might include a text description of what the function does plus details of what arguments the function expects. And we’d expect the LLM to automatically choose the right function to call to do a job.
Further, systems are being built in which the LLM has access to hundreds of tools. In such settings, there might be too many functions at your disposal to put all of them into the LLM context, so you might use heuristics to pick the most relevant subset to include in the LLM context at the current step of processing. This technique, which is described in the Gorilla paper cited below, is reminiscent of how, if there is too much text to include as context, retrieval augmented generation (RAG) systems offer heuristics for picking a subset of the text to include.
Early in the history of LLMs, before widespread availability of large multimodal models (LMMs) like LLaVa, GPT-4V, and Gemini, LLMs could not process images directly, so a lot of work on tool use was carried out by the computer vision community. At that time, the only way for an LLM-based system to manipulate an image was by calling a function to, say, carry out object recognition or some other function on it. Since then, practices for tool use have exploded. GPT-4’s function calling capability, released in the middle of last year, was a significant step toward general-purpose tool use. Since then, more and more LLMs are being developed to similarly be facile with tool use.
If you’re interested in learning more about tool use, I recommend:
- “Gorilla: Large Language Model Connected with Massive APIs,” Patil et al. (2023)
- “MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action,” Yang et al. (2023)
- “Efficient Tool Use with Chain-of-Abstraction Reasoning,” Gao et al. (2024)
Both Tool Use and Reflection, which I described in last week’s letter, are design patterns that I can get to work fairly reliably on my applications — both are capabilities well worth learning about. In future letters, I’ll describe the Planning and Multi-agent collaboration design patterns. They allow AI agents to do much more but are less mature, less predictable — albeit very exciting — technologies.
Keep learning!
Andrew
P.S. Learn to carry out red-teaming attacks against your own LLM-based applications to spot and patch vulnerabilities! In our new short course, “Red Teaming LLM Applications,” Matteo Dora and Luca Martial of LLM testing company Giskard teach how to simulate malicious actions to discover vulnerabilities and improve security. We start with prompt injection, which can trick an LLM into bypassing safeguards to reveal private information or say something inappropriate. There is no one-size-fits-all approach to security, but this course will help you identify some scenarios to protect against.
We believe that widespread knowledge of red-teaming capabilities will result in greater transparency and safer LLM-based systems. However, we ask you to use the skills you gain from this course ethically.
News

Microsoft Absorbs Inflection
Microsoft took over most of the once high-flying chatbot startup Inflection AI in an unusual deal.
What’s new: Microsoft hired Inflection CEO Mustafa Suleyman and much of the startup’s staff and paid roughly $650 million for access to its models and legal protections, Bloomberg reported. Inflection will shift from serving consumers to focusing on large companies.
How it works: Microsoft did not formally purchase any assets of Inflection, which remains a separate, independent company. $650 million is significantly less than the $1.3 billion in investment that Inflection received last year at a $4 billion valuation.
- Microsoft paid $620 million for a non-exclusive license to serve Inflection’s models, including the Inflection-2.5 large language model, which will be available on the Microsoft Azure cloud service. Inflection said APIs will be available soon on Azure and other services.
- Microsoft hired most of Inflection’s 70-person staff, including Suleyman and co-founder Karén Simonyan. The ex-Inflection hires joined a new Microsoft division called Microsoft AI. Inflection waived legal rights related to Microsoft’s hiring activity in return for a roughly $30 million payment.
- Inflection will use its gains plus cash on hand to compensate its investors at $1.10 or $1.50 per dollar invested. Investors will retain their equity in Inflection.
- The new organization, which includes some of Microsoft’s prior AI teams, will oversee the company’s AI efforts. Microsoft AI will develop and deploy consumer AI products like the Bing search engine and the company’s various Copilot assistants. Former Bing chief Mikhail Parakhin, who would have reported to Suleyman, departed.
Behind the news: Inflection was co-founded in 2022 by Suleyman (a founder of DeepMind, now a division of Google), Simonyan, and LinkedIn chairman Reed Hoffman with funding partly from Microsoft. The startup initially positioned itself as a competitor to OpenAI and Anthropic, seeking to develop AI assistants for consumers. Its flagship product was Pi, a chatbot trained to provide emotional support. Microsoft CEO Satya Nadella began courting Suleyman several months ago, and Suleyman wanted to bring Inflection’s staff along with him. Microsoft made a similar offer to OpenAI in November, during that company’s leadership shakeup, when the tech giant proposed hiring briefly-ousted CEO Sam Altman and many of his co-workers to staff a new organization at Microsoft.
Yes, but: The unusual nature of the deal — with Microsoft absorbing most of Inflection’s staff while leaving the startup intact as a company — may have been designed to avoid the antitrust scrutiny that comes with acquisitions. The deal doesn’t automatically trigger a review by U.S. regulators because Microsoft did not acquire Inflection assets. Microsoft’s close relationship with OpenAI has attracted attention from regulators in the U.S., UK, and EU.
Why it matters: Tech giants are searching for an edge in AI development after being briefly leapfrogged in the market by large language model startups. Microsoft invested $13 billion in OpenAI, and Nadella says that partnership remains a strategic priority. This year, Microsoft has sought to diversify its AI interests, sealing deals with Mistral and now Inflection, while also beefing up its internal efforts. The distribution channel for AI models increasingly runs through large companies and their cloud services.
We’re thinking: Even with strong talent, powerful backing, and a multibillion-dollar valuation, Inflection struggled to gain traction. Its journey from hot consumer startup to streamlined enterprise software provider shows how competitive the chatbot sector has become.

Nvidia Revs AI Engine
Nvidia’s latest chip promises to boost AI’s speed and energy efficiency.
What’s new: The market leader in AI chips announced the B100 and B200 graphics processing units (GPUs) designed to eclipse its in-demand H100 and H200 chips. The company will also offer systems that integrate two, eight, and 72 chips.
How it works: The new chips are based on Blackwell, an updated chip architecture specialized for training and inferencing transformer models. Compared to Nvidia’s earlier Hopper architecture, used by H-series chips, Blackwell features hardware and firmware upgrades intended to cut the energy required for model training and inference.
- Training a 1.8-trillion-parameter model (the estimated size of OpenAI’s GPT-4 and Beijing Academy of Artificial Intelligence’s WuDao) would require 2,000 Blackwell GPUs using 4 megawatts of electricity, compared to 8,000 Hopper GPUs using 15 megawatts, the company said.
- Blackwell includes a second-generation Transformer Engine. While the first generation used 8 bits to process each neuron in a neural network, the new version can use as few as 4 bits, potentially doubling compute bandwidth.
- A dedicated engine devoted to reliability, availability, and serviceability monitors the chip to identify potential faults. Nvidia hopes the engine can reduce compute times by minimizing chip downtime.
- An upgraded version of the NVLink switch, which allows GPUs to communicate with each other, accommodates up to 1.8 terabytes of traffic in each direction, compared to Hopper’s maximum of 900 gigabytes. The architecture can handle up to 576 GPUs in combination, compared to Hopper’s cap of 256.
- Nvidia doesn’t make it easy to compare the B200 with rival AMD’s top offering, the MI300X. Here are a few comparisons based on specs reported for Nvidia’s eight-GPU system: The B200 processes 4.5 dense/9 sparse PFLOPS at 8-bit precision, while the MI300X processes 2.61 dense/5.22 sparse PFLOPS at 8-bit precision. The B200 has 8TB/s peak memory bandwidth and 192GB of memory, while the MI300X has 5.3TB/s peak memory bandwidth and 192GB of memory.
Price and availability: The B200 will cost between $30,000 and $40,000, similar to the going rate for H100s today, Nvidia CEO Jensen Huang told CNBC. Nvidia did not specify when the chip would be available. Google, Amazon, and Microsoft stated intentions to offer Blackwell GPUs to their cloud customers.
Behind the news: Demand for the H100 chip has been so intense that the chip has been difficult to find, driving some users to adopt alternatives such as AMD’s MI300X. Moreover, in 2022, the U.S. restricted the export of H100s and other advanced chips to China. The B200 also falls under the ban.
Why it matters: Nvidia holds about 80 percent of the market for specialized AI chips. The new chips are primed to enable developers to continue pushing AI’s boundaries, training multi-trillion-parameter models and running more instances at once.
We’re thinking: Cathie Wood, author of ARK Invest’s “Big Ideas 2024” report, estimated that training costs are falling at a very rapid 75 percent annually, around half due to algorithmic improvements and half due to compute hardware improvements. Nvidia’s progress paints an optimistic picture of further gains. It also signals the difficulty of trying to use model training to build a moat around a business. It’s not easy to maintain a lead if you spend $100 million on training and next year a competitor can replicate the effort for $25 million.
NEW FROM DEEPLEARNING.AI

In our new short course “Red Teaming LLM Applications,” you will learn industry-proven manual and automated techniques to proactively test, attack, and improve the robustness of your large language model (LLM) applications. Join now!

Toward Managing AI Bio Risk
Scientists pledged to control their use of AI to produce potentially hazardous biological materials.
What’s new: More than 150 biologists in Asia, Europe, and North America signed a voluntary commitment to internal and external oversight of machine learning models that can be used to design proteins.
How it works: The scientists made 10 voluntary commitments regarding synthetic biology research. They promised broadly to avoid research likely to enable harm and to promote research that responds to infectious disease outbreaks or similar emergencies.
- The signatories committed to evaluating the risks of AI models that generate protein structures based on user-defined characteristics such as shape or length. They also promised to improve methods for evaluating and mitigating risks.
- They vowed to acquire synthetic DNA — fabricated gene sequences that can instruct cells to produce proteins designed by AI — only from providers that rigorously screen the DNA for potential to create hazardous molecules. They agreed to support development of new screening methods.
- They promised to disclose potential benefits, risks, and efforts to mitigate the risks of their research. They pledged to review the capabilities of synthetic biology at regular, secure meetings and report unethical or concerning research practices.
- They also agreed to revise their commitments “as needed.”
Behind the news: The potential role of AI in producing bioweapons is a major focus of research in AI safety. The current pledge arose from a University of Washington meeting on responsible AI and protein design held late last year. The AI Safety Summit, which took place at around the same time, also addressed the topic, and Helena, a think tank devoted to solving global problems, convened a similar meeting in mid-2023.
Why it matters: DeepMind’s AlphaFold, which finds the structures of proteins, has spawned models that enable users to design proteins with specific properties. Their output could help scientists cure diseases, boost agricultural production, and craft enzymes that aid industrial processes. However, their potential for misuse has led to scrutiny by national and international organizations. The biology community’s commitment to use such models safely may reassure the public and forestall onerous regulations.
We’re thinking: The commitments are long on general principles and relatively short on concrete actions. We’re glad they call for ongoing revision and action, and we hope they lead to the development of effective safeguards.
More Factual LLMs
Large language models sometimes generate false statements. New work makes them more likely to produce factual output.
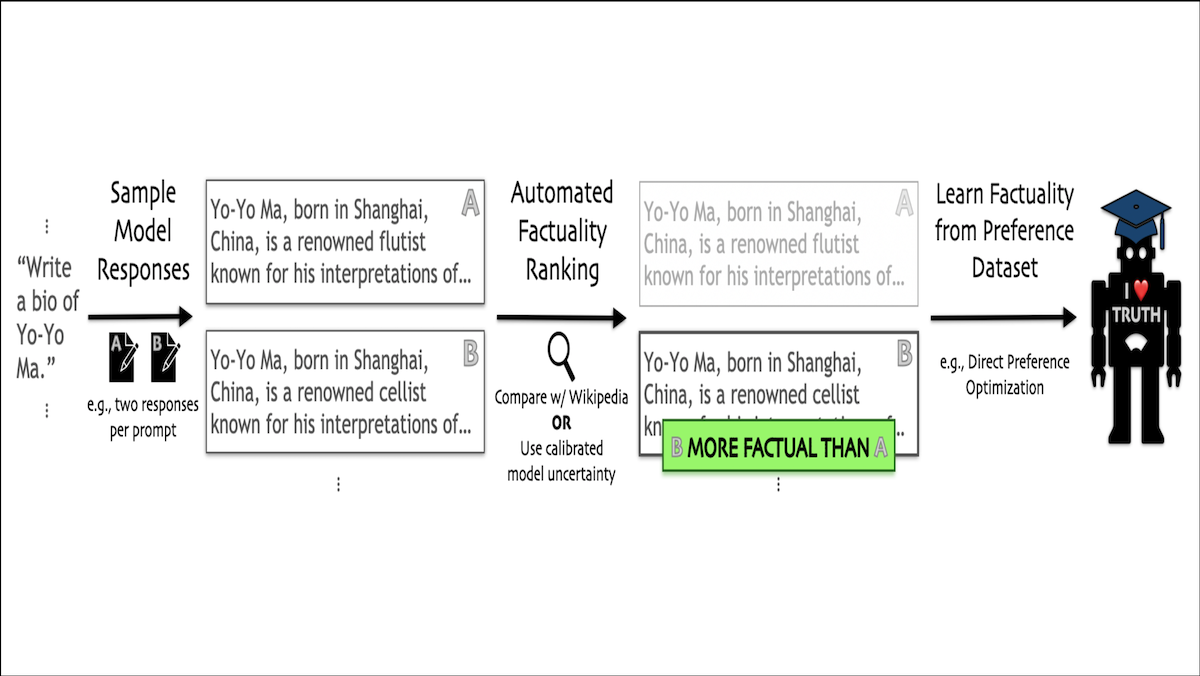
What’s new: Katherine Tian, Eric Mitchell, and colleagues at Stanford and University of North Carolina proposed FactTune, a procedure that fine-tunes large language models (LLMs) to increase their truthfulness without collecting human feedback.
Key insight: Just as fine-tuning based on feedback has made LLMs less harmful, it can make them more factual. The typical method for such fine-tuning is reinforcement learning from human feedback (RLHF). But a combination of direct preference optimization (DPO) and reinforcement learning from AI feedback (RLAIF) is far more efficient. DPO replaces cumbersome reinforcement learning with a simpler procedure akin to supervised learning. RLAIF eliminates the cost of collecting human feedback by substituting model-generated preferences for human preferences.
How it works: The authors built models designed to deliver factual output within a specific domain.
- The authors asked GPT-3.5 to prompt LLaMA-7B to generate 10 biographies of roughly 300 people profiled by Wikipedia.
- Instead of human fact checking, which would be prohibitively expensive, they relied on FActScore, an automated fact checker that uses a separate LLaMA fine-tuned for fact-checking to determine whether a separate model’s output is supported by Wikipedia. FActScore asked GPT-3.5 to extract claims in the biographies and determined whether each claim was supported by Wikipedia. Then it scored the biographies according to the percentage of supported claims.
- The authors built a dataset by choosing two biographies of the same person at random. They annotated the one with the higher factuality score as preferred and the one with the lower score as not preferred.
- They used the dataset to fine-tune the LLaMA-7B via Direct Preference Optimization (DPO).
Results: Fine-tuning by the authors’ method improved the factuality of models in two domains.
- The authors generated biographies of people in the test set using LLaMA-7B before and after fine-tuning via their method. Human judges who used Wikipedia as a reference deemed factual 58 percent of the claims generated by the model without fine-tuning and 85 percent of claims generated by the fine-tuned model.
- The authors generated answers to a wide variety of medical questions drawn from Wikipedia using LLaMA-7B before and after fine-tuning via their method. Judges gave factual ratings to 66 percent of answers generated by the model without fine-tuning and 84 percent of answers generated by the fine-tuned model.
Why it matters: LLMs are known to hallucinate, and the human labor involved in fact checking their output is expensive and time-consuming. The authors applied well tested methods to improve the factuality of texts while keeping human involvement to a minimum.
We’re thinking: This work, among others, shows how LLMs can bootstrap their way to better results. We’ve only just begun to explore combinations of LLMs working together as well as individual LLMs working iteratively in an agentic workflow.
Data Points
The latest AI news in brief is yours with Data Points, a spinoff of The Batch:
OpenAI is cautiously probing the synthetic voice market with Voice Engine.
Also, a city in California is testing an AI tool to identify homeless encampments.
Plus, a tech coalition plans on challenging Nvidia's lock-in of its chip users by developing new open-source cloud software..
Find these stories and more. Read Data Points now.