
Dear friends,
Last week, I spoke about AI and regulation at the U.S. Capitol at an event that was attended by legislative and business leaders. I’m encouraged by the progress the open source community has made fending off regulations that would have stifled innovation. But opponents of open source are continuing to shift their arguments, with the latest worries centering on open source's impact on national security. I hope we’ll all keep protecting open source!
Based on my conversations with legislators, I’m encouraged by the progress the U.S. federal government has made getting a realistic grasp of AI’s risks. To be clear, guardrails are needed. But they should be applied to AI applications, not to general-purpose AI technology.
Nonetheless, as I wrote previously, some companies are eager to limit open source, possibly to protect the value of massive investments they’ve made in proprietary models and to deter competitors. It has been fascinating to watch their arguments change over time.
For instance, about 12 months ago, the Center For AI Safety’s “Statement on AI Risk” warned that AI could cause human extinction and stoked fears of AI taking over. This alarmed leaders in Washington. But many people in AI pointed out that this dystopian science-fiction scenario has little basis in reality. About six months later, when I testified at the U.S. Senate’s AI Insight forum, legislators no longer worried much about an AI takeover.
Then the opponents of open source shifted gears. Their leading argument shifted to the risk of AI helping to create bioweapons. Soon afterward, OpenAI and RAND showed that current AI does not significantly increase the ability of malefactors to build bioweapons. This fear of AI-enabled bioweapons has diminished. To be sure, the possibility that bad actors could use bioweapons — with or without AI — remains a topic of great international concern.

The latest argument for blocking open source AI has shifted to national security. AI is useful for both economic competition and warfare, and open source opponents say the U.S. should make sure its adversaries don’t have access to the latest foundation models. While I don’t want authoritarian governments to use AI, particularly to wage unjust wars, the LLM cat is out of the bag, and authoritarian countries will fill the vacuum if democratic nations limit access. When, some day, a child somewhere asks an AI system questions about democracy, the role of a free press, or the function of an independent judiciary in preserving the rule of law, I would like the AI to reflect democratic values rather than favor authoritarian leaders’ goals over, say, human rights.
I came away from Washington optimistic about the progress we’ve made. A year ago, legislators seemed to me to spend 80% of their time talking about guardrails for AI and 20% about investing in innovation. I was delighted that the ratio has flipped, and there was far more talk of investing in innovation.
Looking beyond the U.S. federal government, there are many jurisdictions globally. Unfortunately, arguments in favor of regulations that would stifle AI development continue to proliferate. But I’ve learned from my trips to Washington and other nations’ capitals that talking to regulators does have an impact. If you get a chance to talk to a regulator at any level, I hope you’ll do what you can to help governments better understand AI.
Keep learning,
Andrew
P.S. Two new short courses!
- I’m thrilled to announce our first short course focused on agentic workflows: “Building Agentic RAG with LlamaIndex,” taught by LlamaIndex CEO Jerry Liu. This covers an important shift in RAG. Rather than having a developer write explicit routines to retrieve information to feed into an LLM’s context, we can build a RAG agent that has access to tools to retrieve information. This lets it decide what information to fetch, and lets it answer more complex questions using multi-step reasoning.
- Additionally, I’m delighted to launch “Quantization in Depth,” taught by Hugging Face’s Marc Sun and Younes Belkada. Quantization is a key technique for making large models accessible. You’ll learn about implementing linear quantization variants, quantizing at different granularities, and compressing deep learning models to 8-bit and 2-bit precision.
News
Coding Assistance Start to Finish
GitHub Copilot’s latest features are designed to help manage software development from plan to pull request.
What’s new: GitHub unveiled a preview of Copilot Workspace, a generative development environment that’s designed to encompass entire projects. Users can sign up for a waitlist to gain access to Workspace until the preview ends. Afterward, Copilot Workspace will be available to subscribers to GitHub Copilot (which starts at $10 per month for individuals and $19 per month for businesses).
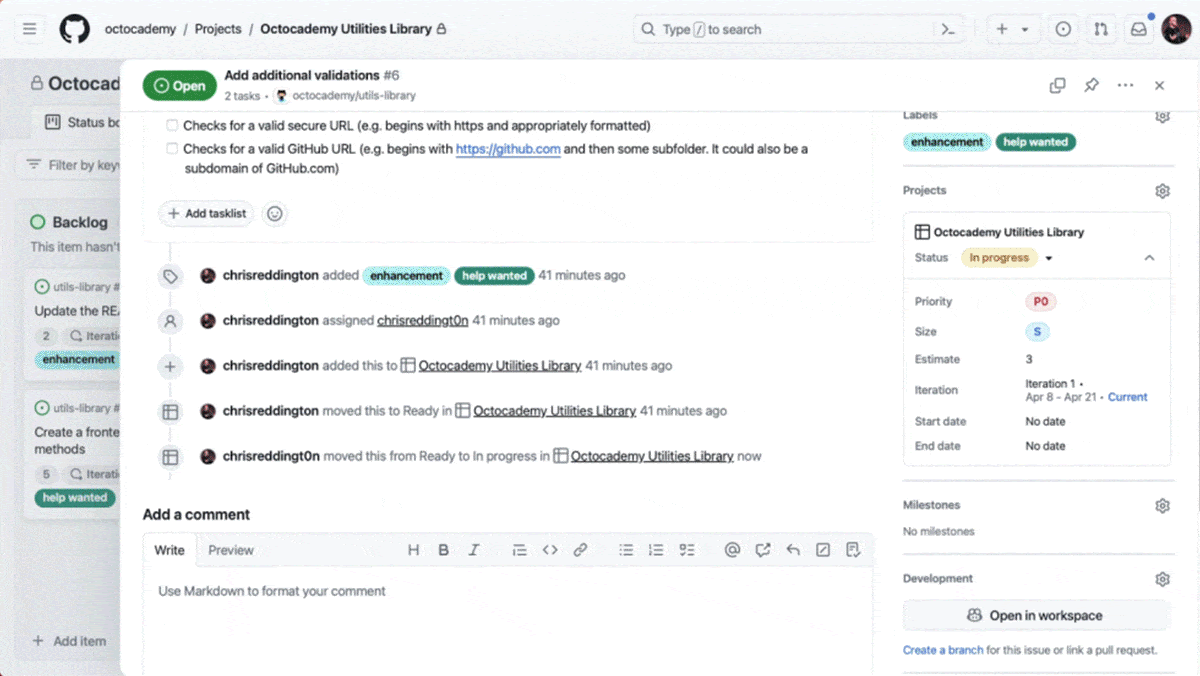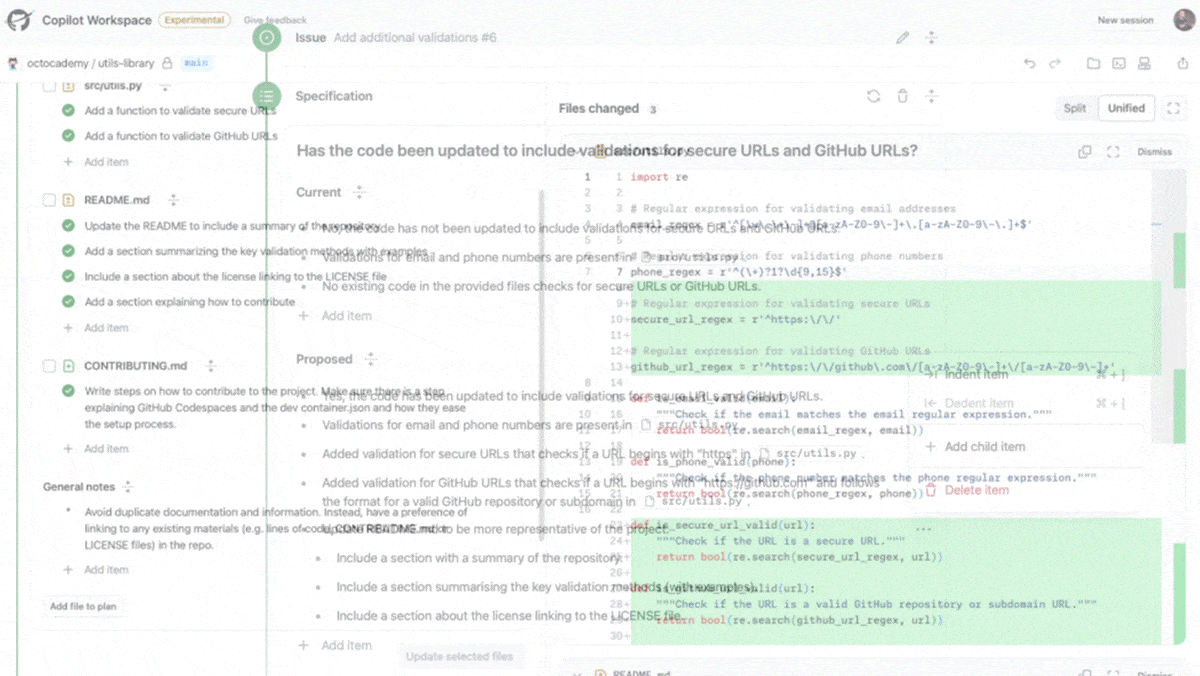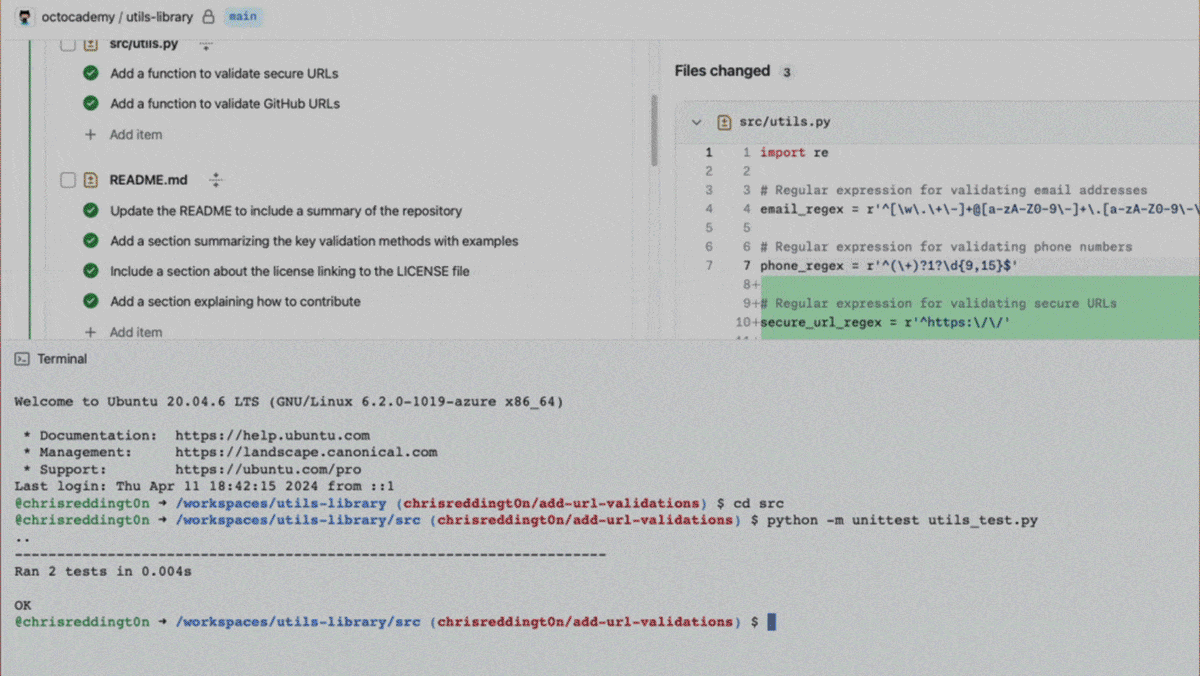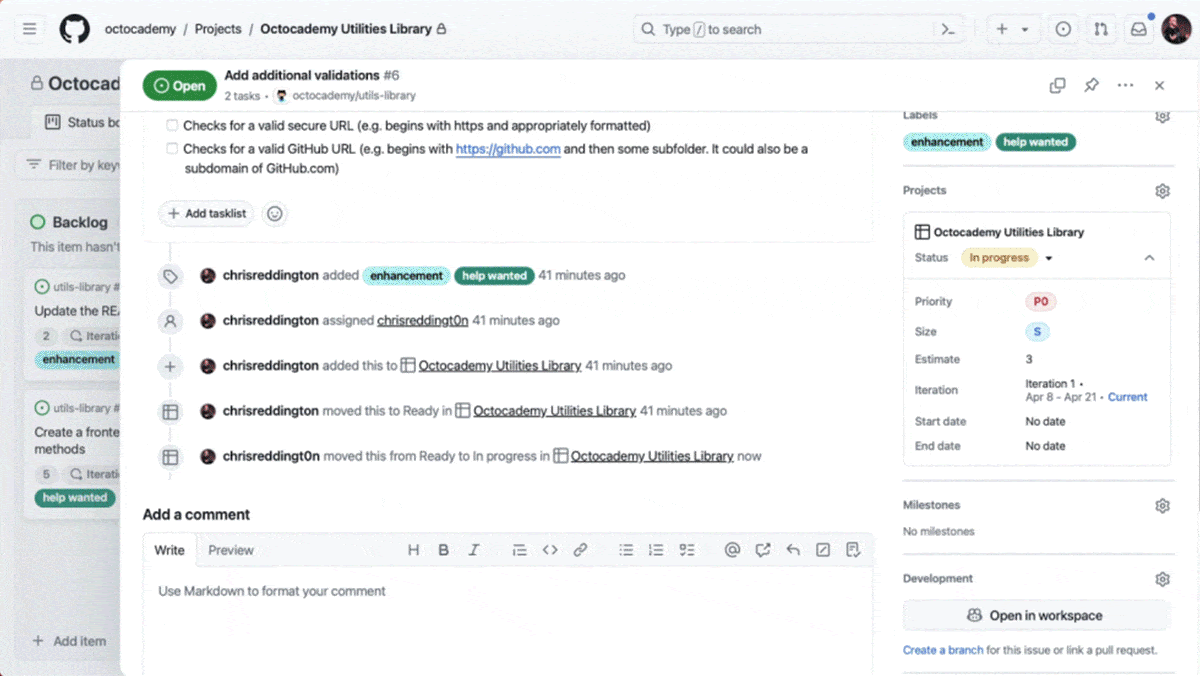
How it works: Copilot Workspace is based on GPT-4 Turbo and integrated with GitHub code repositories and libraries. Where GitHub Copilot previously generated code snippets and provided suggestions for editing code segments, Copilot Workspace integrates these tasks within a larger plan.
- Users begin by providing a known bug, feature request, or codebase and then prompting the system. For instance, a user can provide code for a simple Pong-style video game and request a feature, such as an automated opponent to play against.
- Given the request, the system determines the current state of the codebase, then proposes goals the code will meet once the new feature has been implemented. For example, the system might propose, “the computer controls the left paddle automatically, allowing for a single-player game against the computer” and “the game mechanics and logic for the computer’s movement have been added to index.jsx.”
- The goals function as a new prompt, spurring the system to plan intermediate steps to reach them. For instance, the revised plan might include, “add computer player logic for paddle 1 that blocks the ball 95% of the time” and “remove logic for player control of paddle 1.”
- Users can edit all of this before telling the system to carry out the plan. Afterward, the resulting code can be edited, previewed, shared, and subjected to new tests.
- Once the code has passed the tests, users can upload it directly to GitHub as a pull request or fork in the code repository or library.
Yes, but: Initial users noted that Copilot Workspace is best at solving straightforward, well defined problems and struggles with more complex ones. Choices can be difficult to unwind later on, and the system is slower than simpler AI coding assistants.
Behind the news: Generative coding assistants quickly have become central tools for software development. Copilot has attracted 1.3 million paid subscribers as of April 2024, including 50,000 businesses. Amazon’s Q Developer (formerly CodeWhisperer), Google’s Gemini Code Assist (formerly Duet AI), and Cursor offer coding companions that integrate with or fork popular integrated development environments like Microsoft’s VSCode. On the frontier are agentic tools that plan and carry out complex, multi-step coding tasks.
Why it matters: Copilot Workspace attempts to extend Copilot’s code-completion and chat capabilities to a wider swath of the software development cycle. Simpler coding assistants have been shown to boost productivity markedly. Bringing natural-language prompting to tasks like planning, testing, and reading documentation is a natural step.
We’re thinking: There are many ways to use AI in coding. To learn about a few more, check out our short course, “Pair Programming With a Large Language Model,” taught by Google AI advocate Laurence Moroney.
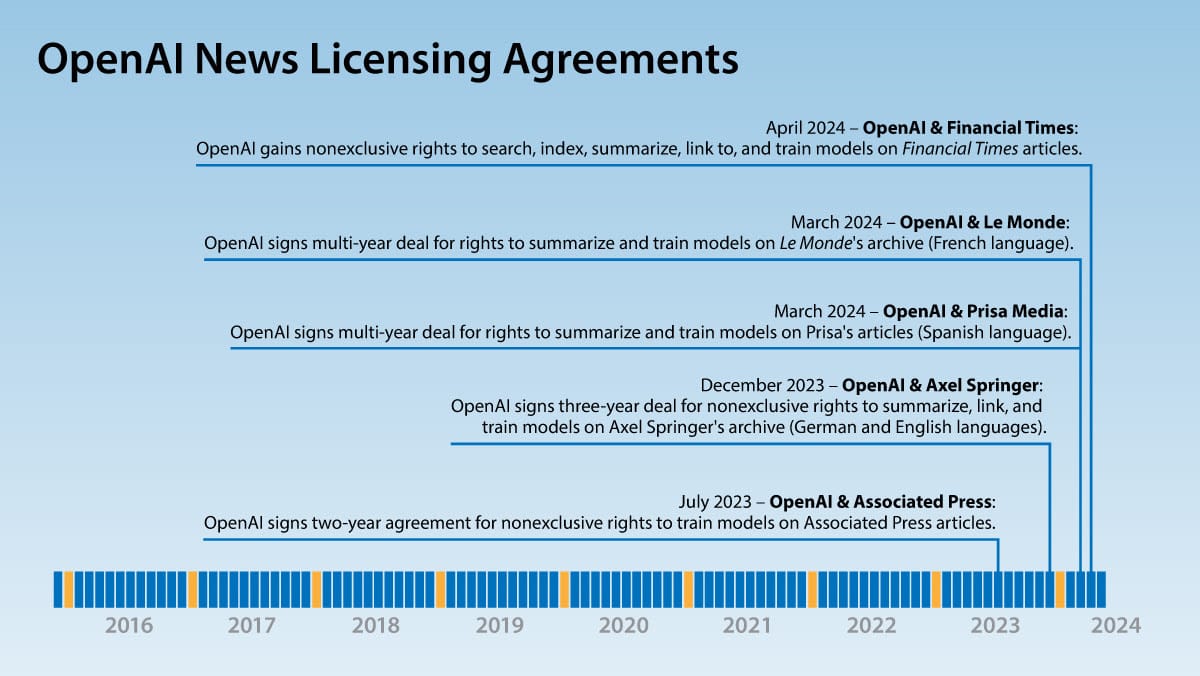
OpenAI Licenses News Archives
OpenAI has been making deals with publishers to gain access to high-quality training data. It added Financial Times to the list.
What’s new: OpenAI licensed the archive of business news owned by Financial Times (FT) for an undisclosed sum. The agreement lets OpenAI train its models on the publisher’s articles and deliver information gleaned from them. This is OpenAI’s fifth such agreement with major news publishers in the past year.
How it works: Although the parties didn’t disclose the length of their agreement, OpenAI’s other news licensing deals will end within a few years. The limited commitment suggests that these arrangements are experimental rather than strategic. The deal includes articles behind the publisher’s paywall; that is, not freely available on the open internet. This enables OpenAI to train its models on material that competitors may not have. Other deals have given OpenAI exclusive access, shutting competitors out.
- The deal with FT gives OpenAI nonexclusive rights to search, index, and train its models on the publisher’s articles, including articles behind its paywall. It also lets OpenAI enable ChatGPT to cite, summarize, and link to the publishers’ works. The parties called the deal a “strategic partnership” as well as a licensing agreement, although it’s unclear whether OpenAI will share technology or data with FT.
- In March, OpenAI announced multi-year agreements with French newspaper Le Monde and Prisa Media (Spanish owner of the newspapers El País, Diario AS, and Cinco Días). The agreements give OpenAI rights to summarize and train AI models on their articles and make the publishers, respectively, OpenAI’s exclusive providers of French- and Spanish-language news.
- In December 2023, OpenAI signed a three-year, nonexclusive deal with German publisher Axel Springer, owner of German-language newspapers Bild and Die Welt as well as English-language websites Politico and Business Insider. The deal allows OpenAI to train on, summarize, and link to Axel Springer’s articles, including paywalled content, and makes the publisher OpenAI’s exclusive supplier of German-language news. It was worth “tens of millions of euros,” according to Bloomberg.
- In July 2023, OpenAI gained nonexclusive rights for two years to train its models on some of the text of the Associated Press (AP) archive of news articles, which freely is available on the open web. In return, AP received undisclosed access to OpenAI’s “technology and product expertise.” Unlike the other agreements, the deal with AP (which does not have a paywall) does not grant OpenAI specific rights to summarize or link to AP’s stories.
Behind the news: Archives of news articles may be handy if OpenAI proceeds with a rumored search service reported by in February by The Information. Licensing is a way to get such material that is unambiguously legal. Although AI researchers commonly scrape data from the web and use it for training models without obtaining licenses for copyrighted works, whether a license is required to train AI models on works under copyright in the U.S. has yet to be determined. Copyright owners lately have challenged this practice in court. In December 2023, The New York Times sued OpenAI and Microsoft, claiming that OpenAI infringed its copyrights by training models on its articles. In April 2024, eight U.S. newspapers owned by Alden Global Capital, a hedge fund, filed a lawsuit against the same defendants on similar grounds. Licensing material from publishers gives OpenAI access to their works while offering them incentives to negotiate rather than sue.
Why it matters: AI developers need huge amounts of media to train larger and larger models. News publishers have huge archives with high-quality text, relatively well written and fact-checked, that’s relevant to current events of interest to a broad audience. Licensing those archives gives developers access to what they need without incurring legal risk. Furthermore, making news archives available for retrieval augmented generation makes chatbots more capable and reliable.
We’re thinking: We support efforts to clarify the legal status of training AI models on data scraped from the web. It makes sense to treat the open web pages and paywalled content differently, but we advocate that AI models be free to learn from the open internet just as humans can.
NEW FROM DEEPLEARNING.AI

Explore the newest additions to our short courses with “Quantization in Depth,” where you’ll build a quantizer in PyTorch, and “Building Agentic RAG with LlamaIndex,” which teaches how to build agents capable of tool use, reasoning, and making decisions based on your data. Sign up now!

Landmine Recognition
An AI system is scouring battlefields for landmines and other unexploded ordnance, enabling specialists to defuse them.
What’s new: The military hardware firm Safe Pro Group developed Spotlight AI, a computer vision system that identifies mines based on aerial imagery, IEEE Spectrum reported. Nongovernmental organizations that remove landmines, including the Norwegian People's Aid and the HALO Trust, are using the system in Ukraine.
How it works: SpotlightAI processes visual-light imagery taken by flying drones. The system provides centimeter-resolution maps that guide mine-removal teams through the territory.
- The system includes an unidentified vision model trained to recognize 150 types of explosive munitions, primarily of U.S. and Russian origin. In a test, the model detected 87 percent of munitions scattered across a munitions test range in Hungary.
- With sufficient computational resources, the system can analyze an image in around 0.5 seconds. A human reviewer typically takes three minutes.
- The system struggles to identify explosives concealed by earth or dense vegetation. To address this limitation, Safe Pro Group has begun to test it with infrared, lidar, magnetometry, and other types of imagery. In addition, the company has developed a system that converts drone imagery into a heat map that shows a machine learning model’s estimated probability that it can detect explosives in a given location. A patch of grass, for example, may have a higher estimated probability than a dense thicket of trees and bushes.
- The company aims to fine-tune its model to detect unexploded ordnance in other current or former conflict zones such as Angola, Iraq, and Laos.
Behind the news: In addition to drones, satellites can help machine learning models to find deadly remnants of warfare. In 2020, Ohio State University researchers estimated the number of undetonated explosives in Cambodia by collating bomb craters in satellite images identified by a computer vision model with records of U.S. military bombing campaigns in that country in the 1960s and 1970s.
Why it matters: Unexploded mines, bombs, and other types of munitions killed or injured more than 4,700 people — 85 percent of them civilians and half of them children where military status and age were known — in 2022 alone. Efforts to remove every last mine from a former battlefield likely will continue to rely on traditional methods — manual analysis of overhead imagery along with sweeps by human specialists and explosive-sniffing dogs — but machine learning can significantly reduce the hazard and accelerate the work.
We’re thinking: Although this system locates unexploded mines and shells, removing them often still falls to a brave human. We hope for speedy progress in robots that can take on this work as well.

Streamlined Inference
It’s not necessary to activate all parts of a large language model to process a given input. Using only the necessary parts saves processing.
What’s new: Zichang Liu and collaborators at Rice University, Zhe Jiang University, Stanford, University of California San Diego, ETH Zürich, Adobe, Meta, and Carnegie Mellon proposed Deja Vu, an algorithm that accelerates inferencing of large language models (LLMs) by using small vanilla neural networks to predict which parts of it to use.
Key insight: Transformer-based neural networks can save a lot of time at inference by activating only a fraction of (i) attention heads and (ii) neurons in fully connected layers. But it’s necessary to activate the right neurons, because different parts of the network learn about different patterns of inputs. By using the input to decide which parts of the network to activate, the network can maintain accuracy using only the parts relevant for the current input.
How it works: The authors used pretrained OPT models of various sizes (175, 66, and 30 billion parameters). They built a dataset by feeding examples from OpenBookQA and Wiki-Text to the OPTs and recording the outputs of all attention heads and fully-connected-layer neurons. By activating various portions of these networks, they learned that, for a given input, they could discard most of an OPT’s lowest-output attention heads and fully-connected-layer neurons without degrading its performance.
- The authors used their dataset to train a sparsity predictor for each of an OPT’s fully connected layers. This small vanilla neural network classified which neurons in a fully connected layer to activate (because they produced large outputs), given the output of the previous fully connected layer.
- Using the same dataset, they trained, for each attention layer, a small vanilla neural network to classify which attention heads to activate (because they produced large outputs), given the output of the previous attention layer.
- At inference, an OPT and its predictor networks ran in parallel. While the OPT computed an attention layer, a predictor network predicted the neurons to activate in the following fully connected layer. Similarly, while the OPT computed each fully connected layer, a predictor network predicted the heads to activate in the following attention layer.
Results: Deja Vu (175 billion parameters) produced a sequence of 128 tokens in 20 milliseconds, while an Nvidia implementation of OPT of the same size needed 40 milliseconds and a Hugging Face implementation of OPT of the same size needed 105 milliseconds. Moreover, Deja Vu achieved these speedups without reducing accuracy. On WikiText and C4, Deja Vu’s ability to predict the next word held steady while activating 25 percent of attention heads and fully-connected-layer neurons. On datasets such as WinoGrande and OpenBookQA, it maintained its accuracy while activating 35 percent of attention heads and fully-connected-layer neurons.
Why it matters: Efficient use of processing power becomes increasingly important as models become larger. Moreover, faster token generation benefits agentic workflows, which can consume large numbers of tokens.
We’re thinking: Deja Vu’s design is in the spirit of the mixture of experts (MoE) architecture: For each transformer layer, MoE uses a neural-network layer to choose which fully connected layer to use. In contrast, for each attention head and fully-connected-layer neuron, Deja Vu uses small neural networks to decide which to activate.
NEW FROM DEEPLEARNING.AI

New course with Qualcomm coming soon! In “Introduction to On-Device AI,” you’ll learn how to deploy AI models on edge devices using local computation for faster inference and privacy. Join the next wave of AI as models go beyond the cloud. Sign up for the waitlist!