
Dear friends,
A good way to get started in AI is to start with coursework, which gives a systematic way to gain knowledge, and then to work on projects. For many who hear this advice, “projects” may evoke a significant undertaking that delivers value to users. But I encourage you to set a lower bar and relish small, weekend tinkering projects that let you learn, even if they don’t result in a meaningful deliverable.
Recently, my son and daughter (ages 3 and 5) were building Lego vehicles. They built a beautiful ice-cream truck as well as a . . . umm . . . colorful and asymmetric dinosaur car, shown in the picture below. While most observers would judge the ice-cream truck as the superior creation, my kids built it by following Lego’s instructions, and it is likely identical to thousands of ice-cream trucks built by others. In contrast, building the dinosaur car required creativity and novel thinking. The exercise helped them hone their ability to pick and assemble Lego building blocks.
There is, of course, room for both mimicking others’ designs (with permission) and coming up with your own. As a parent, I try to celebrate both. (To be honest, I celebrated the dinosaur car more.) When learning to build Lego, it’s helpful to start by following a template. But eventually, building your own unique projects enriches your skills.

As a developer, too, I try to celebrate unique creations. Yes, it is nice to have beautiful software, and the impact of the output does matter. But good software is often written by people who spend many hours tinkering and building things. By building unique projects, you master key software building blocks. Then, using those blocks, you can go on to build bigger projects.
I routinely tinker with building AI applications, and a lot of my tinkering doesn’t result in anything useful. My latest example: I built a Streamlit app that would authenticate to Google docs, read the text in a doc, use a large language model to edit my text, and write the result back into the doc. I didn’t find it useful in the end because of friction in the user interface, and I’m sure a commercial provider will soon, if they haven’t already, build a better product than I was able to throw together in a couple of hours on a weekend. But such tinkering helps me hone my intuition and master software components (I now know how to programmatically interface with Google docs) that might be useful in future projects.
If you have an idea for a project, I encourage you to build it! Often, working on a project will also help you decide what additional skills to learn, perhaps through coursework. To sustain momentum, it helps to find friends with whom to talk about ideas and celebrate projects — large or small.
Keep tinkering!
Andrew
P.S. On the heels of Microsoft’s announcement of the Copilot+ PC, which uses on-device AI optimized for a Qualcomm chip, we have a short course on deploying on-device AI created with Qualcomm! In “Introduction to On-Device AI,” taught by Qualcomm’s Senior Director of Engineering Krishna Sridhar, you’ll deploy a real-time image segmentation model on-device and learn key steps for on-device deployment: neural network graph capture, on-device compilation, hardware acceleration, and validating on-device numerical correctness. Please sign up here!
News
Faster, Cheaper Multimodality
OpenAI’s latest model raises the bar for models that can work with common media types in any combination.
What’s new: OpenAI introduced GPT-4o, a model that accepts and generates text, images, audio, and video — the “o” is for omni — more quickly, inexpensively, and in some cases more accurately than its predecessors. Text and image input and text-only output are available currently via ChatGPT and API, with image output coming soon. Speech input and output will roll out to paying users in coming weeks. General audio and video will be available first to partners before rolling out more broadly.
How it works: GPT-4o is a single model trained on multiple media types, which enables it to process different media types and relationships between them faster and more accurately than earlier GPT-4 versions that use separate models to process different media types. The context length is 128,000 tokens, equal to GPT-4 Turbo but well below the 2-million limit newly set by Google Gemini 1.5 Pro.
- The demos are impressive. In a video, one of the model’s four optional voices — female, playful, and extraordinarily realistic — narrates a story while adopting different tones from robotic to overdramatic, translates fluidly between English and Italian, and interprets facial expressions captured by a smartphone camera.
- API access to GPT-4o costs half as much as GPT-4 Turbo: $5 per million input tokens and $15 per million output tokens.
- GPT-4o is 2x faster than GPT-4 Turbo on a per-token basis and expected to accelerate to 5x (10 million tokens per minute) in high volumes.
- Audio processing is much faster. GPT-4o responds to audio prompts in 0.3 seconds on average, while ChatGPT’s previous voice mode took 2.8 or 5.4 seconds on average relying on a separate speech-to-text step and then GPT-3.5 or GPT-4, respectively.
- An improved tokenizer makes text processing more token-efficient depending on the language. Gujarati, for instance, requires 4.4x fewer tokens, Telegu 3.5x fewer, and Tamil 3.3x fewer. English, French, German, Italian, Portuguese, and Spanish require between 1.1x and 1.3x fewer tokens.
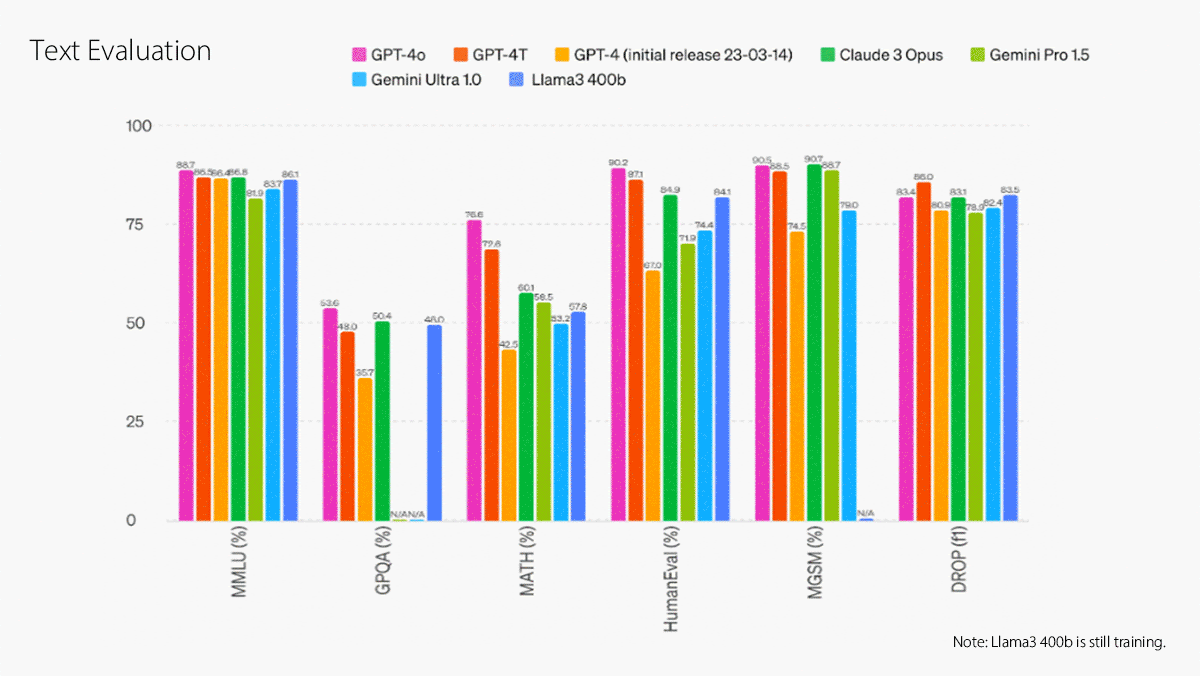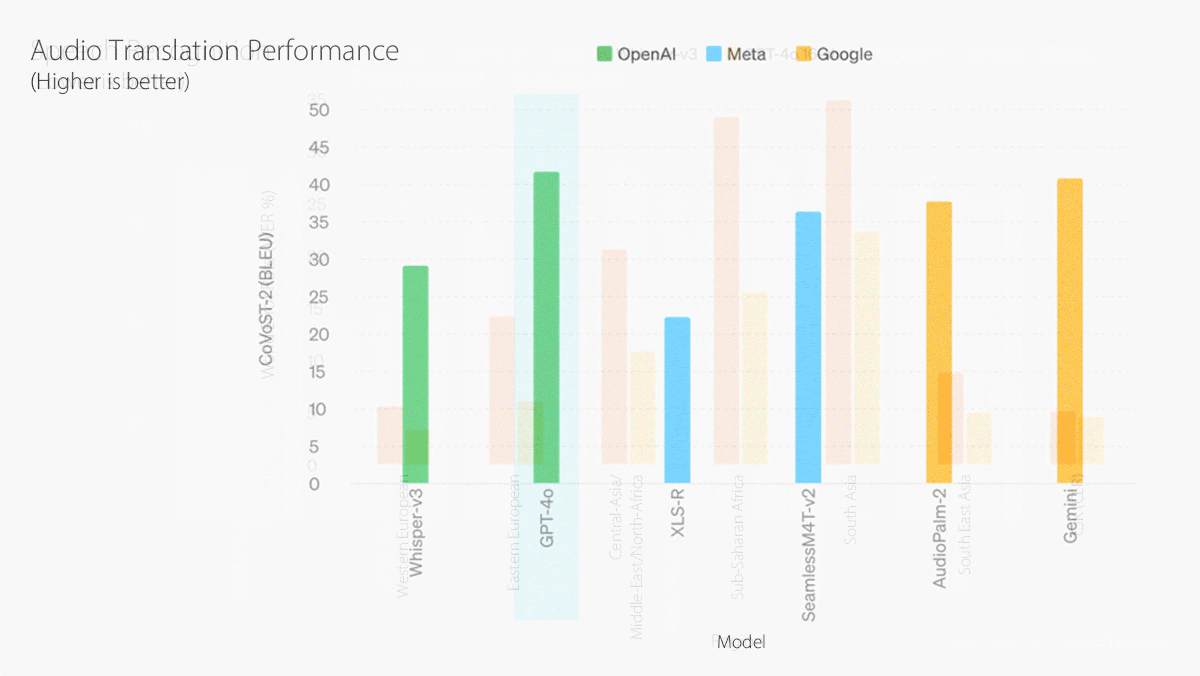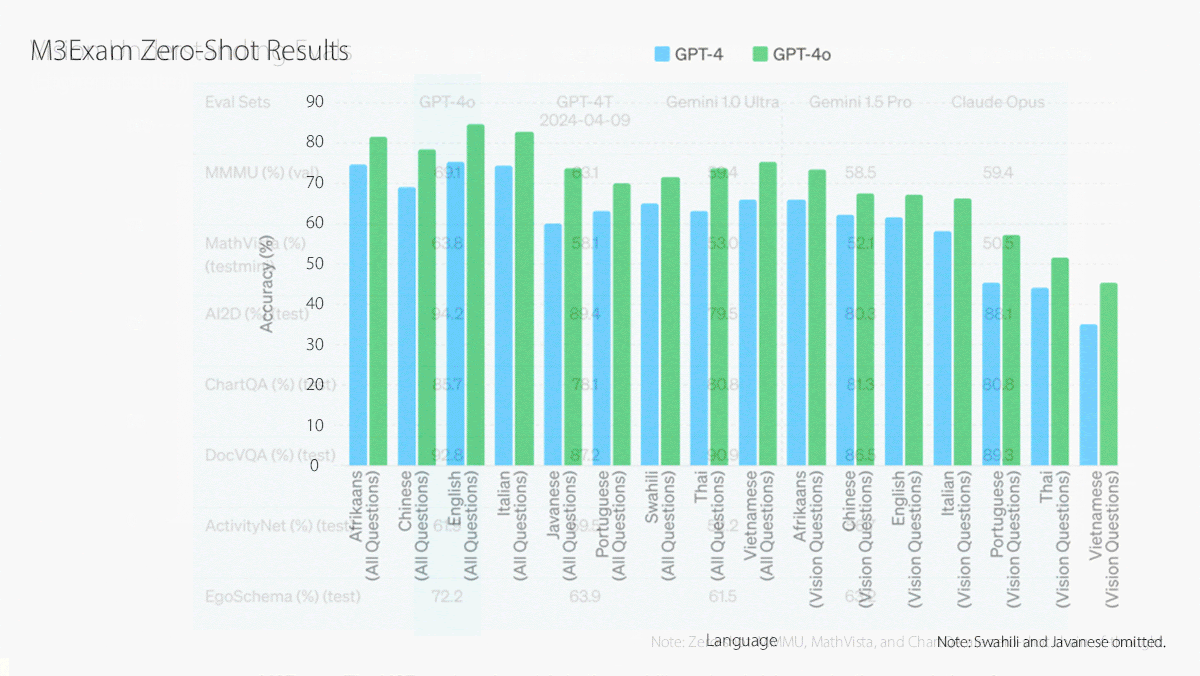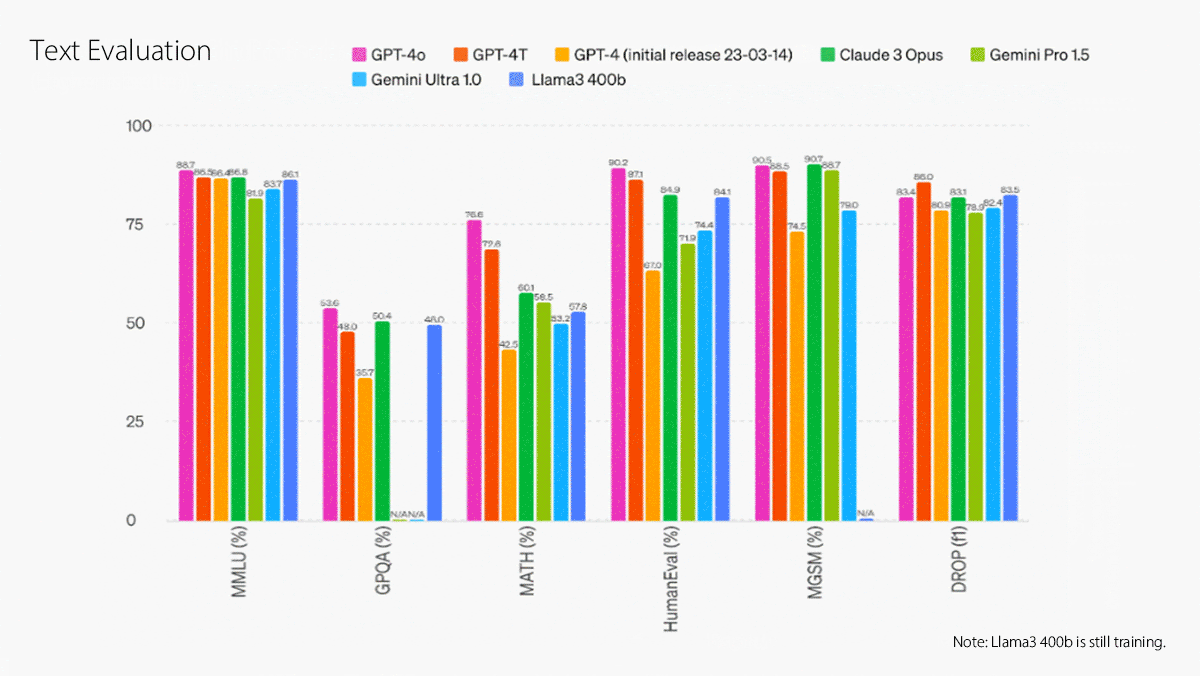
GPT-4o significantly outperforms Gemini Pro 1.5 at several benchmarks for understanding text, code, and images including MMLU, HumanEval, MMMU, and DocVQA. It outperformed OpenAI’s own Whisper-large-v3 speech recognition model at speech-to-text conversion and CoVoST 2 language translation.
Aftershocks: As OpenAI launched the new model, troubles resurfaced that had led to November’s rapid-fire ouster and reinstatement of CEO Sam Altman. Co-founder and chief scientist Ilya Sutskever, who co-led a team that focused on mitigating long-term risks, resigned. He did not give a reason for his departure; previously he had argued that Altman didn’t prioritize safety sufficiently. The team’s other co-leader Jan Leike followed, alleging that the company had a weak commitment to safety. The company promptly dissolved the team altogether and redistributed its responsibilities. Potential legal issues also flared when actress Scarlett Johansson, who had declined an invitation to supply her voice for a new OpenAI model, issued a statement saying that one of GPT-4o’s voices sounded “eerily” like her own and demanding to know how the artificial voice was built. OpenAI denied that it had used or tried to imitate Johansson’s voice and withdrew that voice option.
Why it matters: Competition between the major AI companies is putting more powerful models in the hands of developers and users at a dizzying pace. GPT-4o shows the value of end-to-end modeling for multimodal inputs and outputs, leading to significant steps forward in performance, speed, and cost. Faster, cheaper processing of tokens makes the model more responsive and lowers the barrier for powerful agentic workflows, while tighter integration between processing of text, images, and audio makes multimodal applications more practical.
We’re thinking: Between GPT-4o, Google’s Gemini 1.5, and Meta’s newly announced Chameleon, the latest models are media omnivores. We’re excited to see what creative applications developers build as the set of tasks such models can perform continues to expand!

2 Million Tokens of Context & More
Google’s annual I/O developers’ conference brought a plethora of updates and new models.
What’s new: Google announced improvements to its Gemini 1.5 Pro large multimodal model — notably increasing its already huge input context window — as well as new open models, a video generator, and a further step in digital assistants. In addition, Gemini models will power new features in Google Search, Gmail, and Android.
How it works: Google launched a variety of new capabilities.
- Gemini 1.5 Pro’s maximum input context window doubled to 2 million tokens of text, audio, and/or video — roughly 1.4 million words, 60,000 lines of code, 2 hours of video, or 22 hours of audio. The 2 million-token context window is available in a “private preview” via Google’s AI Studio and Vertex AI. The 1 million-token context window ($7 per 1 million tokens) is generally available on those services in addition to the previous 128,000 window ($3.50 per 1 million tokens).
- Gemini 1.5 Flash is a faster distillation of Gemini 1.5 Pro that features a 1 million token context window. It’s available in preview via Vertex AI. Due to be generally available in June, it will cost $0.35 per million tokens of input for prompts up to 128,000 tokens or $0.70 per million tokens of input for longer prompts.
- The Veo video generator can create videos roughly a minute long at 1080p resolution. It can also alter videos, for instance keeping part of the imagery constant and regenerating the rest. A web interface called VideoFX is available via a waitlist. Google plans to roll out Veo to YouTube users.
- Google expanded the Gemma family of open models. PaliGemma, which is available now, accepts text and images and generates text. Gemma 2, which will be available in June, is a 27 billion-parameter large language model that aims to match the performance of Llama 3 70B at less than half the size.
- Gemini Live is a smartphone app for real-time voice chat. The app can converse about photos or video captured by the phone’s camera — in the video demo shown above, it remembers where the user left her glasses! It’s part of Project Astra, a DeepMind initiative that aims to create real-time, multimodal digital assistants.
Precautionary measures: Amid the flurry of new developments, Google published protocols for evaluating safety risks. The “Frontier Safety Framework” establishes risk thresholds such as a model’s ability to extend its own capabilities, enable a non-expert to develop a potent biothreat, or automate a cyberattack. While models are in development, researchers will evaluate them continually to determine whether they are approaching any of these thresholds. If so, developers will make a plan to mitigate the risk. Google aims to implement the framework by early 2025.
Why it matters: Gemini 1.5 Pro’s expanded context window enables developers to apply generative AI to multimedia files and archives that are beyond the capacity of other models currently available — corporate archives, legal testimony, feature films, shelves of books — and supports prompting strategies such as many-shot learning. Beyond that, the new releases address a variety of developer needs and preferences: Gemini 1.5 Flash offers a lightweight alternative where speed or cost is at a premium, Veo appears to be a worthy competitor for OpenAI’s Sora, and the new open models give developers powerful options.
We’re thinking: Google’s quick iteration on its Gemini models is impressive. Gemini 1.0 was announced less than six months ago. White-hot competition among AI companies is giving developers more choices, faster speeds, and lower prices.
NEW FROM DEEPLEARNING.AI

In our new short course “Introduction to On-Device AI,” made in collaboration with Qualcomm, you’ll learn to deploy AI models on edge devices using local compute for faster inference and privacy. Join the next wave of AI as models go beyond the cloud! Enroll for free

Music Titan Targets AI
The world’s second-largest music publisher accused AI developers of potential copyright violations.
What’s new: Sony Music Group declared that AI developers had trained models on Sony’s intellectual property without permission and that any method of collecting media or other data owned by the company violated its copyrights. Whether AI developers actually have violated copyrights has not been established.
How it works: In a statement posted on the company’s website and letters to developers, Sony forbade the use of its music or other media such as lyrics, music videos, album art for “training, developing, or commercializing any AI systems.”
- Sony Music Group sent letters to more than 700 AI developers and streaming services. Letters to AI developers demanded that they reveal which works they had used for training by the following week. Recipients included Google, Microsoft, and text-to-music startups Suno and Udio. Letters sent to streaming services, including Apple and Spotify, asked them to modify their terms of service to prohibit anyone from using streaming services to collect data owned by Sony, among other measures.
- It reserved the right to grant specific developers permission to use its material as training data, asking interested parties to contact Sony by email if they wanted to make a deal.
Behind the news: In April, more than 200 music artists called for streaming services and AI developers to stop using their work for training and stop generating music in the styles of specific musicians without compensation. Universal Music Group (UMG), which is Sony Music’s top competitor, has also opposed unrestricted AI-generated music.
Last year, UMG ordered Apple Music and Spotify to block AI developers from downloading its recordings and issued takedown notices to YouTube and Spotify uploaders who generated music that sounds like artists who are under contract to Universal.
Why it matters: Sony Music Group’s warning comes as generated audio is approaching a level of quality that might attract a mainstream audience, and it could chill further progress. Although it is not yet clear whether training AI systems on music recordings without permission violates copyrights, Sony Music Group has demonstrated its willingness to pursue both individuals and companies for alleged copyright violations. The company accounted for 22 percent of the global music market in 2023. (UMG accounted for 32 percent.) Its catalog includes many of the world’s most popular artists including AC/DC, Adele, Celine Dion, and Harry Styles.
We’re thinking: We believe that AI developers should be allowed to let their software learn from data that’s freely available on the internet, but uncertainty over the limits of copyright protection isn’t good for anyone. It’s high time to update to intellectual property laws for the era of generative AI.

Interpreting Image Edit Instructions
The latest text-to-image generators can alter images in response to a text prompt, but their outputs often don’t accurately reflect the text. They do better if, in addition to a prompt, they’re told the general type of alteration they’re expected to make.
What’s new: Developed by Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar and colleagues at Meta, Emu Edit enriches prompts with task classifications that help the model interpret instructions for altering images. You can see examples here.
Key insight: Typical training datasets for image-editing models tend to present, for each example, an initial image, an instruction for altering it, and a target image. To train a model to interpret instructions in light of the type of task it describes, the authors further labeled examples with a task. These labels included categories for regional alterations such as adding or removing an object or changing the background, global alterations such as changing an image’s style, and computer-vision tasks such as detecting or segmenting objects.
How it works: Emu Edit comprises a pretrained Emu latent diffusion image generator and pretrained/fine-tuned Flan-T5 large language model. The system generates a novel image given an image, text instruction, and one of 16 task designations. The authors generated the training set through a series of steps and fine-tuned the models on it.
- The authors prompted a Llama 2 large language model, given an image caption from an unspecified dataset, to generate (i) an instruction to alter the image, (ii) a list of which objects to be changed or added, and (iii) a caption for the altered image. For example, given a caption such as, “Beautiful cat with mojito sitting in a cafe on the street,” Llama 2 might generate {"edit": "include a hat", "edited object": "hat", "output": "Beautiful cat wearing a hat with mojito sitting in a cafe on the street"}.
- Given Llama 2’s output, the Prompt-to-Prompt image generator produced initial and target images.
- The authors modified Prompt-to-Prompt with unique enhancements for each task. For instance, to alter only parts of an image, Prompt-to-Prompt usually computes and applies a mask to the initial image while generating the target image. The authors noted that the masks tend to be imprecise if original and target captions differ by more than simple word substitutions. To address this, they modified the method for computing masks. In the change-an-object task, a multi-step procedure involving SAM and Grounding DINO (a DINO variant fine-tuned for object recognition) generated a mask of the list of objects to be changed.
- Following the typical diffusion process for generating images, Emu learned to remove noise from noisy versions of the target images, given the initial image, the instruction, and the task label.
- The authors fine-tuned Flan-T5. Given a generated instruction, Flan-T5 learned to classify the task. At inference, given the instruction, Flan-T5 provided the task to Emu Edit.
Results: Judges compared altered images produced by the authors’ method, InstructPix2Pix, and MagicBrush using the MagicBrush test set. Evaluating how well the generated images aligned with the instruction, 71.8 percent of the time, the judges preferred Emu Edit over InstructPix2Pix, and 59.5 percent of the time, they preferred Emu Edit over MagicBrush. Evaluating how well the generated images preserve elements from the input images, 71.6 percent preferred Emu Edit over InstructPix2Pix, and 60.4 percent preferred Emu Edit over MagicBrush.
Why it matters: Richer data improves machine learning results. Specifying tasks and generating images that reflect them improved Emu Edit’s data compared to other works, enabling it to achieve better results.
We’re thinking: Text-to-image generators are amazing and fun to use, but their output can be frustratingly unpredictable. It’s great to see innovations that make them more controllable.
A MESSAGE FROM FOURTHBRAIN

Join FourthBrain's two live workshops next week! In these interactive sessions, you’ll build useful applications with large language models and walk away with practical skills. Enroll as an individual or register as a team for a group discount. Learn more