
Dear friends,
The effort to protect innovation and open source continues. I believe we’re all better off if anyone can carry out basic AI research and share their innovations. Right now, I’m deeply concerned about California's proposed law SB-1047. It’s a long, complex bill with many parts that require safety assessments, shutdown capability for models, and so on.
There are many things wrong with this bill, but I’d like to focus here on just one: It defines an unreasonable “hazardous capability” designation that may make builders of large AI models potentially liable if someone uses their models to do something that exceeds the bill’s definition of harm (such as causing $500 million in damage). That is practically impossible for any AI builder to ensure. If the bill is passed in its present form, it will stifle AI model builders, especially open source developers.
Some AI applications, for example in healthcare, are risky. But as I wrote previously, regulators should regulate applications rather than technology.
- Technology refers to tools that can be applied in many ways to solve various problems.
- Applications are specific implementations of technologies designed to meet particular customer needs.
For example, an electric motor is a technology. When we put it in a blender, an electric vehicle, dialysis machine, or guided bomb, it becomes an application. Imagine if we passed laws saying, if anyone uses a motor in a harmful way, the motor manufacturer is liable. Motor makers would either shut down or make motors so tiny as to be useless for most applications. If we pass such a law, sure, we might stop people from building guided bombs, but we’d also lose blenders, electric vehicles, and dialysis machines. In contrast, if we look at specific applications, like blenders, we can more rationally assess risks and figure out how to make sure they’re safe, and even ban classes of applications, like certain types of munitions.
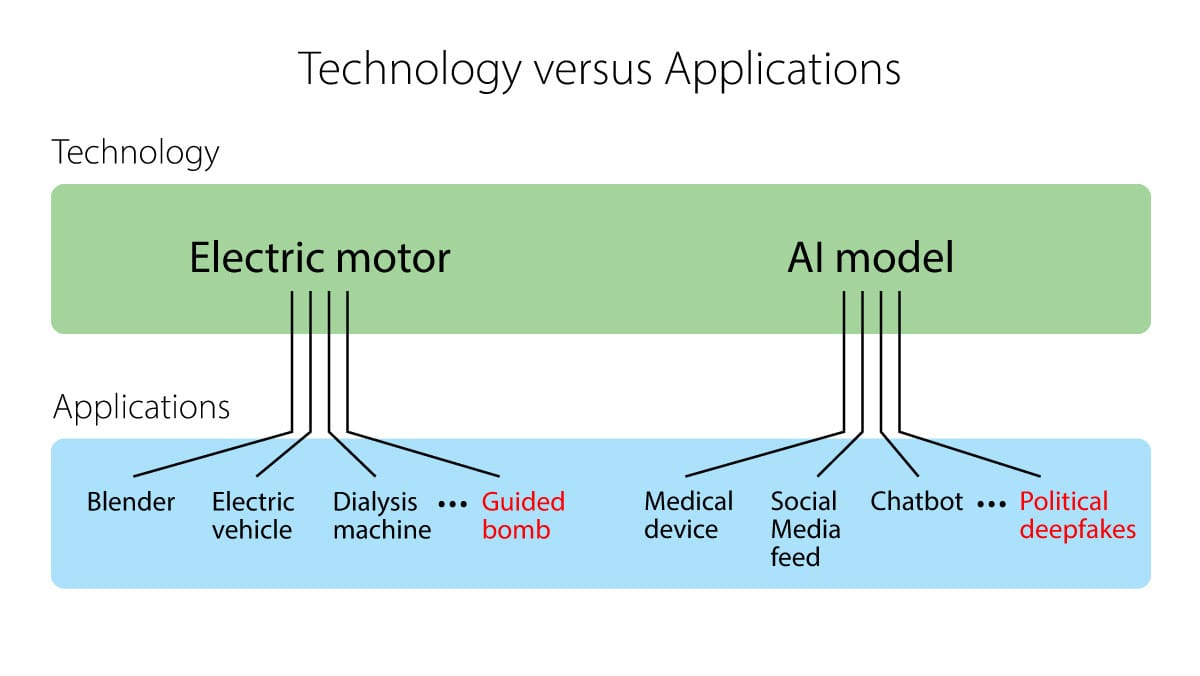
Safety is a property of applications, not a property of technologies (or models), as Arvind Narayanan and Sayash Kapoor have pointed out. Whether a blender is a safe one can’t be determined by examining the electric motor. A similar argument holds for AI.
SB-1047 doesn’t account for this distinction. It ignores the reality that the number of beneficial uses of AI models is, like electric motors, vastly greater than the number of harmful ones. But, just as no one knows how to build a motor that can’t be used to cause harm, no one has figured out how to make sure an AI model can’t be adapted to harmful uses. In the case of open source models, there’s no known defense to fine-tuning to remove RLHF alignment. And jailbreaking work has shown that even closed-source, proprietary models that have been properly aligned can be attacked in ways that make them give harmful responses. Indeed, the sharp-witted Pliny the Prompter regularly tweets about jailbreaks for closed models. Kudos also to Anthropic’s Cem Anil and collaborators for publishing their work on many-shot jailbreaking, an attack that can get leading large language models to give inappropriate responses and is hard to defend against.
California has been home to a lot of innovation in AI. I’m worried that this anti-competitive, anti-innovation proposal has gotten so much traction in the legislature. Worse, other jurisdictions often follow California, and it would be awful if they were to do so in this instance.
SB-1047 passed in a key vote in the State Senate in May, but it still has additional steps before it becomes law. I hope you will speak out against it if you get a chance to do so.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

In this course, you’ll learn how to build and implement highly controllable AI agents with LangGraph and use agentic search to enhance your agents’ built-in knowledge. Enroll today
News

Rise of the AI PC
Generative AI plays a starring role in the latest Windows PCs.
What’s new: Microsoft introduced its Copilot+ PCs, an AI-first laptop specification that offers features unavailable to other Windows users. Copilot+ PCs will be available from Microsoft as well as Acer, Asus, Dell, HP, Lenovo, and Samsung starting in mid-June.
How it works: Copilot+ PCs provide AI-powered generative and search functions thanks to unnamed AI models that run on-device.
- A feature called Recall enables users to search their activities in apps, documents, and websites to find, say, topics discussed in a text conversation or items viewed on a website. Every five seconds, the PC takes a screenshot of its current status. Users can browse the timeline of screenshots or call an unidentified AI model to find images and/or text via a semantic index.
- Other features include Cocreator, which generates images from text prompts using models that run on-device, and Live Captions, which generates subtitles for English-language audio in any of 40 languages.
- Developers have access to these features via a software stack called Windows Copilot Runtime. This includes Copilot Library, a set of APIs that call more than 40 models that run on-device, and DiskANN, a set of search algorithms that quickly sort through a vector database.
- The first machines will be based on the Qualcomm Snapdragon X processor. The chip comes with 10 and 12 CPU cores, a GPU and a neural processing unit (NPU) that accelerates neural networks while using less energy and memory than a typical CPU or GPU.
Nvidia’s rejoinder: Nvidia plans to launch Copilot+-compatible RTX AI PCs that run Nvidia’s own toolkit for calling and customizing models with on-device GPUs. These computers, initially built by Asus and MSI based on AMD CPUs, eventually will deliver all Copilot+ features. Nvidia criticized Microsoft’s NPU specification, which calls for 45 trillion operations per second (TOPS), claiming that that speed is enough to process only basic AI workloads. Meanwhile, Nvidia’s game-focused GPUs deliver more than 1,000 TOPS.
Why it matters: Microsoft is betting that on-device AI will change the PC experience. The Copilot+ PC specification gives developers a versatile toolkit for adding AI to existing apps while opening the door to fundamentally new functionality like Recall.
We’re thinking: As we wrote earlier, makers of chips and operating systems alike have a strong incentive to promote on-device (or edge) AI. The growing presence of AI accelerators in consumer devices brings significant privacy benefits for consumers and opens exciting new opportunities for developers.

Disinformation Documented
OpenAI models were used in five disinformation campaigns, the company said.
What’s new: OpenAI discovered that operations based in Russia, China, Iran, and Israel had used the company’s models to create and/or revise text in attempts to influence international political opinion. The generated media failed to reach a mass audience, the company said. It banned the accounts.
How it works: Most of the groups primarily used OpenAI’s language models to generate inauthentic social media comments for posting on dummy accounts intended to create the illusion of popular support for certain causes. Some groups used the company’s models to debug code, generate text for websites, and produce images such as political cartoons. Four of the five groups already were known to disinformation researchers.
- A Russian organization previously unknown to researchers generated large volumes of pro-Russia and anti-Ukraine comments in Russian and English and distributed them via messaging service Telegram. The comments often included poor grammar or telltale phrases such as, “As an AI model, . . .”
- Another Russian group that researchers call Doppelganger generated pro-Russia social media comments in English, French, and German. It also used OpenAI models to translate articles from Russian into other languages for publication on websites. Doppelganger used a third-party API to circumvent OpenAI’s restrictions on Russian users. OpenAI has suspended the API.
- A Chinese operation known to researchers as Spamouflage generated Chinese-language social media comments that supported the Chinese government. It also used OpenAI technology to debug code for a website dedicated to criticizing opponents of the government.
- An Iranian organization called the International Union of Virtual Media (IUVM) generated English and French articles, headlines, and other text for its website. IUVM is considered a mouthpiece for the Iranian government.
- STOIC, an Israeli company that runs political social media campaigns, generated articles and social media comments. It also created fictitious bios for inauthentic social media accounts that included images apparently created by other AI models. STOIC created both pro-Israel and anti-Palestine comments as well as comments critical of India’s ruling Bharatiya Janata Party.
Behind the news: AI-produced misinformation on the internet — mostly images, videos, and audio clips — rose sharply starting in the first half of 2023, research found at Google and several fact-checking organizations. By the end of that year, generative AI was responsible for more than 30 percent of media that was manipulated by computers.
Why it matters: Many observers are concerned about potential proliferation of political disinformation as AI models that generate realistic text, images, video, and audio become widely available. This year will see elections in at least 64 countries including most of the world’s most populous nations — a rich opportunity for AI-savvy propagandists. While propagandists have taken advantage of OpenAI’s models, the company was able to detect them and shut them down. More such efforts are bound to follow.
We’re thinking: Generative AI’s potential to fuel propaganda is worth tracking and studying. But it’s also worth noting that the accounts identified by OpenAI failed to reach significant numbers of viewers or otherwise have an impact. So far, at least, distribution, not generation, continues to be the limiting factor on disinformation.

U.S. and China Seek AI Agreement
The United States and China opened a dialogue to avert hypothetical AI catastrophes.
What’s new: Officials of the two nations met in Geneva for an initial conversation intended to prevent AI-driven accidents or worse, The Washington Post reported.
How it works: The meeting followed up on a November meeting between U.S. president Joe Biden and Chinese president Xi Jinping. The discussion was conceived as an opportunity for the nuclear-armed superpowers, both of which have pegged their strategic ambitions to AI technology, to air their concerns. It resulted in no public statements about concrete actions or commitments.
- The meeting aimed to prevent a “miscalculation” that might lead to unintended conflict, U.S. officials said. They ruled out the possibility that it might promote technical collaboration.
- U.S. diplomats wished to discuss China’s “misuse” of AI, a U.S. government spokesperson said without further clarification. Chinese envoys expressed dissatisfaction with “U.S. restrictions and pressure in the field of artificial intelligence,” such as U.S. restrictions on the sale of AI chips to Chinese customers.
- Neither side indicated whether or when further meetings would occur.
Behind the news: AI-related tensions between the two countries have intensified in recent years. The U.S. government, in an effort to maintain its technological advantage and hamper China’s AI development, has imposed controls on the export of specialized AI chips like the Nvidia A100 and H100 to Chinese customers. Restrictions on the development of models that bear on U.S. national security may follow if further proposed export controls are enacted. Such controls have rankled the Chinese government. Meanwhile, both countries have developed and deployed autonomous military vehicles, and autonomous weapons are proliferating. In November 2023, both countries signed the Bletchley Park declaration to mitigate AI-related risks including cybersecurity, biotechnology, and misinformation.
What they’re saying: “The real verdict on whether these talks were successful will be whether they continue into the future.” — Helen Toner, analyst at Georgetown University’s Center for Security and Emerging Technology and former OpenAI board member, quoted by Associated Press.
Why it matters: Officials and observers alike worry that rivalry between the U.S. and China may lead to severe consequences. However, just as the red telephone enabled U.S. and Soviet leaders to communicate during emergencies in the Cold War, face-to-face dialogue can help bring the two countries into alignment around AI-related risks and ways to reduce them.
We’re thinking: We support harmonious relations between the U.S. and China, but we’re deeply concerned that export controls could stifle open source software. This might slow down China’s progress in AI, but would also hurt the U.S. and its allies.

Better Teachers Make Better Students
A relatively small student LLM that learns to mimic a larger teacher model can perform nearly as well as the teacher while using much less computation. It can come even closer if the teacher also teaches reasoning techniques.
What’s new: Arindam Mitra and colleagues at Microsoft proposed Orca 2, a technique that improves the output of student LLMs an order of magnitude smaller than their teachers.
Key insight: Large language models can provide better output when they’re prompted to use a particular reasoning strategy such as think step by step, recall then generate, or explain then generate. Different reasoning strategies may yield better output depending on the task at hand. Moreover, given the same task, different models may perform better using different reasoning strategies. Consequently, in a teacher-student situation, the teacher and student models may need to use different strategies to achieve their highest performances on a given task. The student will achieve its best performance if it mimics the teacher's reasoning and response when the teacher uses not its own best-performing strategy, but the student’s best-performing strategy.
How it works: The teacher, GPT-4, helped generate a fine-tuning dataset to improve the output of the student, Llama 2 (13 billion parameters), both of which had been pretrained. They created the fine-tuning dataset and fine-tuned Llama 2 as follows:
- The authors assembled an initial dataset that included examples (prompts and responses) of roughly 1,500 tasks. They drew from datasets including FLAN (which includes text classification, math questions, logic questions, and multiple choice questions), math problems from 10 datasets not in FLAN, few-shot prompts in the Orca dataset, and summarizations generated using GPT-4.
- The authors fed each prompt to Llama 2 using each of several reasoning strategies including direct answer, think step by step, explain then answer, and more. (The authors don’t specify all the strategies they used.) They measured its performance on each task per reasoning strategy.
- For each task, they prompted GPT-4 with all examples of that task, specifying the reasoning strategy that had enabled Llama 2 to achieve its highest performance on that task. In this way, GPT-4 augmented the dataset to include, for each prompt, both the response and the reasoning it used to arrive at it.
- They fine-tuned Llama 2, given a prompt — without specifying the reasoning strategy — to produce the detailed reasoning and response generated by GPT-4.
Results: The authors compared their model to models of similar size including WizardLM-13B (also based on Llama 2) and larger models including GPT-3.5 Turbo (an order of magnitude larger) and GPT-4 (parameter count undisclosed). They evaluated the percentage of correct responses on average over six reasoning benchmarks such as AGIEval, which includes multiple-choice and fill-in-the-blank questions from the Scholastic Aptitude Test, American Mathematics Competitions, and other tests designed for humans. Their model exactly matched the correct answer 66.92 percent of the time compared to WizardLM-13B (50.32 percent). It performed nearly as well as the 10x larger GPT-3.5 Turbo (which achieved 67.65 percent) but much less well than GPT-4 (which achieved 79.03 percent).
Why it matters: Learning how to reason is an important complement to learning facts and perspectives. A model that has been trained to reason using its most effective strategy generally will provide better output. Users don’t need to tell it which strategy to apply. They can simply enter a prompt, and the model will figure out how to reason its response.
We’re thinking: Perhaps a similar approach could be used to prompt a model to improve its own output. In effect, this would be similar to an agentic workflow designed to enable a model to produce its own training data, as recently described in The Batch.