
Dear friends,
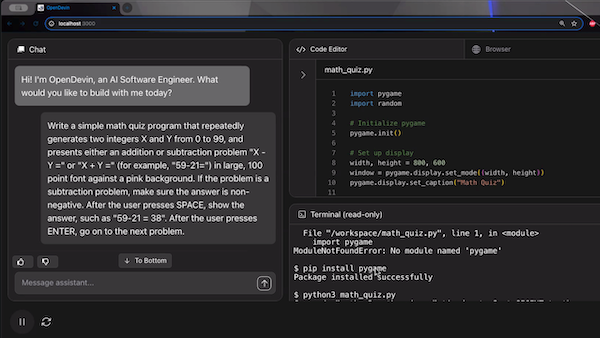
On Father’s Day last weekend, I sat with my daughter to help her practice solving arithmetic problems. To give her practice problems, I used OpenDevin, an open-source agentic coding framework, to write a Python script that generated questions that she enjoyed answering at her own pace. OpenDevin wrote the code much faster than I could have and genuinely improved my and my daughter’s day.
Six months ago, coding agents were a novelty. They still frequently fail to deliver, but I find that they’re now working well enough that they might be genuinely useful to more and more people!
Given a coding problem that’s specified in a prompt, the workflow for a coding agent typically goes something like this: Use a large language model (LLM) to analyze the problem and potentially break it into steps to write code for, generate the code, test it, and iteratively use any errors discovered to ask the coding agent to refine its answer. But within this broad framework, a huge design space and numerous innovations are available to experiment with. I’d like to highlight a few papers that I find notable:
- “AgentCoder: Multiagent-Code Generation with Iterative Testing and Optimisation,” Huang et al. (2024).
- “LDB: A Large Language Model Debugger via Verifying Runtime Execution Step by Step,” Zhong et al., (2024).
- “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering,” Yang et al. (2024).
How can we test the code without requiring the user to write test cases? In a multi-agent system, each “agent” is an LLM prompted to play a particular role. An interesting result from AgentCoder shows that having separate agents for writing code and generating tests results in better performance than letting a single agent do both tasks. This is presumably because, if the agent writing the code is also responsible for writing the tests, the tests might be influenced by the code and fail to consider corner cases that the code does not cover.
When people think of testing code, many initially think of output testing, in which we see if the code generates the correct outputs to a specific set of test inputs. If the code fails a test, an LLM can be prompted to reflect on why the code failed and then to try to fix it. In addition to testing the output, the LDB method is helpful. LDB steps through the code and presents to the LLM values of the variables during intermediate steps of execution, to see if the LLM can spot exactly where the error is. This mimics how a human developer might step through the code to see where one of the computational steps went wrong, and so pinpoint and fix the problem.
A lot of agentic workflows mimic human workflows. Similar to other work in machine learning, if humans can do a task, then trying to mimic humans makes development much easier compared to inventing a new process. However, the authors of SWE-agent noticed that many tools that humans use for coding are very inefficient for agents. For example, giving an agent access to a bash shell and having it find a piece of code by executing numerous cd, ls, and cat commands is inefficient, even though humans can do this rapidly. Similarly, visual coding editors like VSCode, emacs, and vim are easy for humans to use, but hard for LLMs (or LMMs) to navigate. Because agents interact with computers differently than humans do, the authors found that building special-purpose tools (functions) to let an agent search, view, and edit codebases resulted in better performance.
One reason research into coding agents is making rapid progress is that their performance can be evaluated automatically and reliably. With benchmarks like HumanEval, MBPP, and SWE-bench, researchers can try out an idea and automatically test how often it generates correct code. In contrast, even though there’s considerable activity on AI research agents that search the web and synthesize an article (I’ve enjoyed using the open-source STORM system by Stanford's Yijia Shao et al.), they are hard to evaluate and this makes progress harder.
Github Copilot was released in 2021, and many developers have been getting coding help by prompting LLMs. The rapid evolution from that to more sophisticated coding agents is expanding how computers can help us with coding tasks, and the pace of progress is rapid. With these tools, I expect programming to become even more fun and more productive.
Keep coding!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Develop an AI agent that interacts with tabular data and SQL databases using natural language prompts to simplify querying and extracting insights! Start learning for free
News

More New Open Models
A trio of powerful open and semi-open models give developers new options for both text and image generation.
What’s new: Nvidia and Alibaba released high-performance large language models (LLMs), while Stability AI released a slimmed-down version of its flagship text-to-image generator.
How it works: The weights for Nvidia’s and Alibaba’s new models are fully open, while Stability AI’s are restricted.
- Nvidia offers the Nemotron-4 340B family of language models, which includes a 340-billion parameter base model as well as versions fine-tuned to follow instructions and to serve as a reward model in reinforcement learning from human feedback. (Nemotron-4 340B-Reward currently tops the HuggingFace RewardBench leaderboard, which ranks reward models.) The models, which can work with 4,096 tokens of context, were pretrained on 9 trillion tokens that divide between English-language text, text in over 50 other natural languages, and code in more than 40 programming languages. 98 percent of the alignment training set was generated, and Nvidia also released the generation pipeline. The license allows people to use and modify the model freely except for illegal uses.
- Alibaba introduced the Qwen2 family of language models. Qwen2 includes base and instruction-tuned versions of five models that range in size from 500 million to 72 billion parameters and process context lengths between 32,000 and 128,000 tokens. The largest, Qwen2-72B, outperforms Llama 3-70B on MMLU, MMLU-Pro, HumanEval, and other benchmarks that gauge performance in natural language, mathematics, and coding. Qwen2-72B and Qwen2-72B-Instruct are available under a license that permits users to use and modify them in commercial applications up to 100 million monthly users. The smaller models are available under the Apache license, which allows people to use and modify them freely. Alibaba said it plans to add multimodal capabilities in future updates.
- Stability AI launched the Stable Diffusion 3 Medium text-to-image generator, a 2 billion-parameter based on the technology that underpins Stable Diffusion 3. The model is intended to run on laptops and home computers that have consumer GPUs and is optimized for Nvidia and AMD hardware. It excels at rendering imaginary scenes and text; early users encountered inaccuracies in depicting human anatomy, a shortcoming that former Stability AI CEO Emad Mostaque, in a social post, attributed to tuning for safety. The license allows use of the model’s weights for noncommercial purposes. Businesses that have less than 1 million users and $1 million in revenue can license it, along with other Stability AI models, for $20 per month.
Why it matters: AI models that come with published weights are proliferating, and this week’s crop further extends the opportunity to build competitive AI applications. Nemotron-4 340B provides an exceptionally large model among open LLMs. Among smaller models, Qwen2-72B poses stiff competition for Llama 3-70B, which has energized the developer community since its May release. And Stable Diffusion 3 puts Stability AI’s image generation technology into the hands of developers working on edge devices.
We’re thinking: Given the difficulty of acquiring high-quality data to train LLMs, and that the terms of service for many leading models prohibit generating data to train other models, Nvidia’s choice to equip Nemotron-4 to generate synthetic data is especially welcome. And it makes sense from a business perspective: Making it easier for developers to train their own LLMs may be good for GPU sales.
Private Benchmarks for Fairer Tests
Scale AI offers new leaderboards based on its own benchmarks.
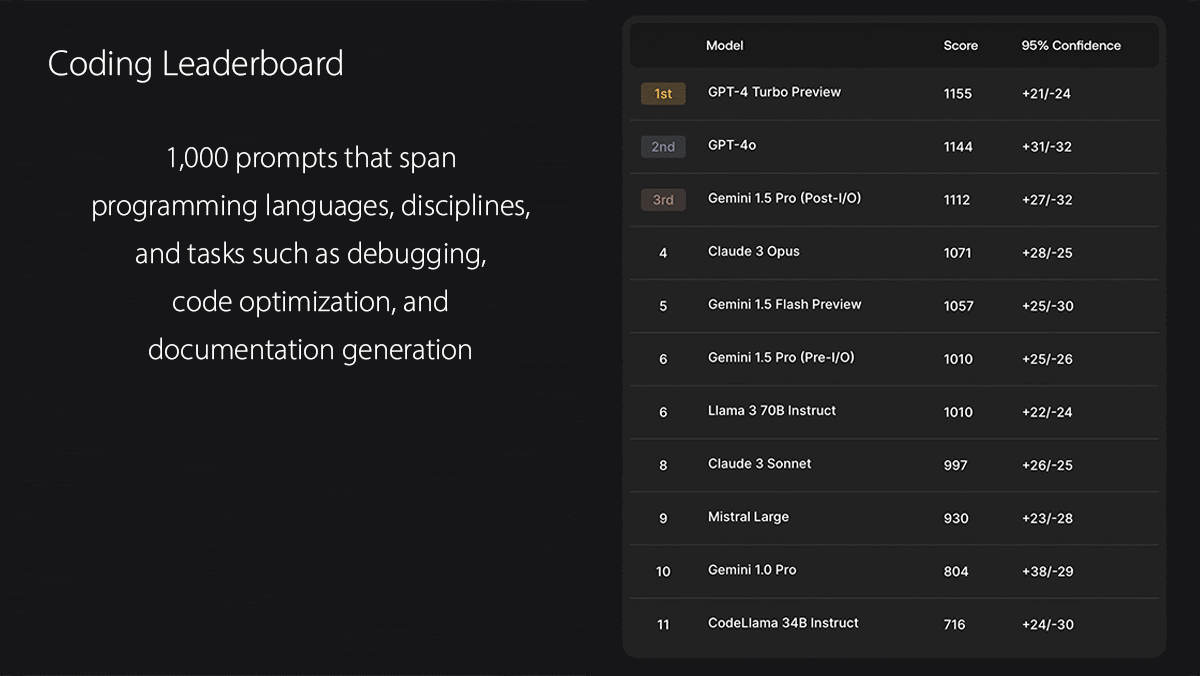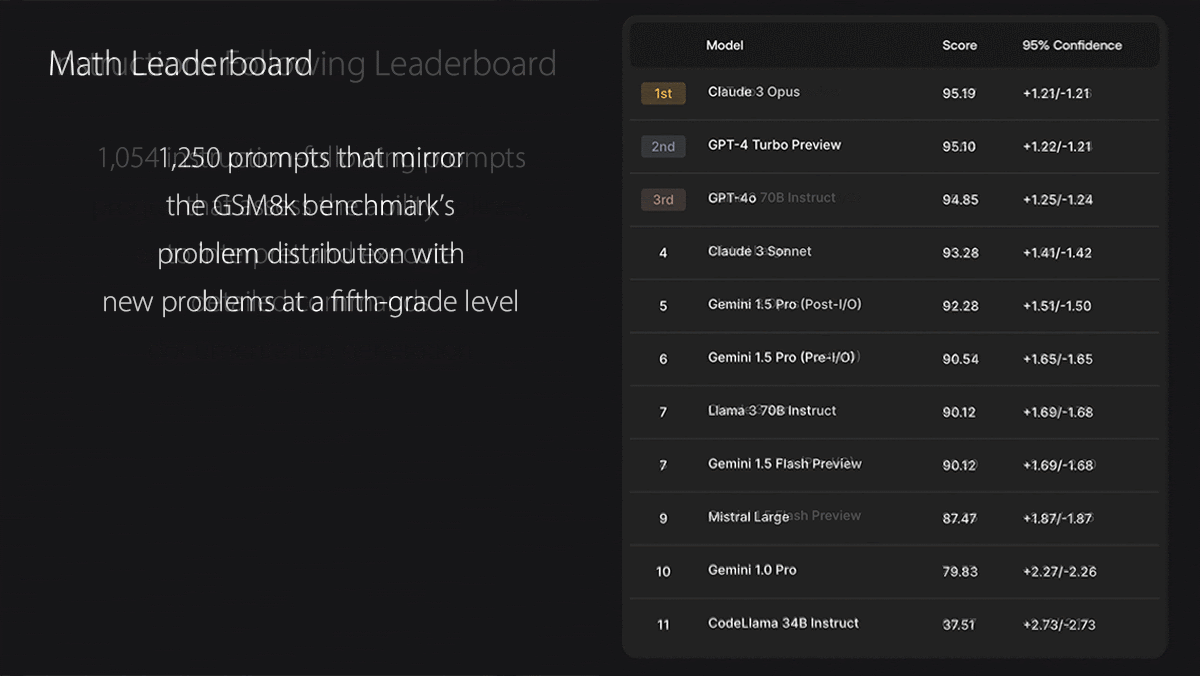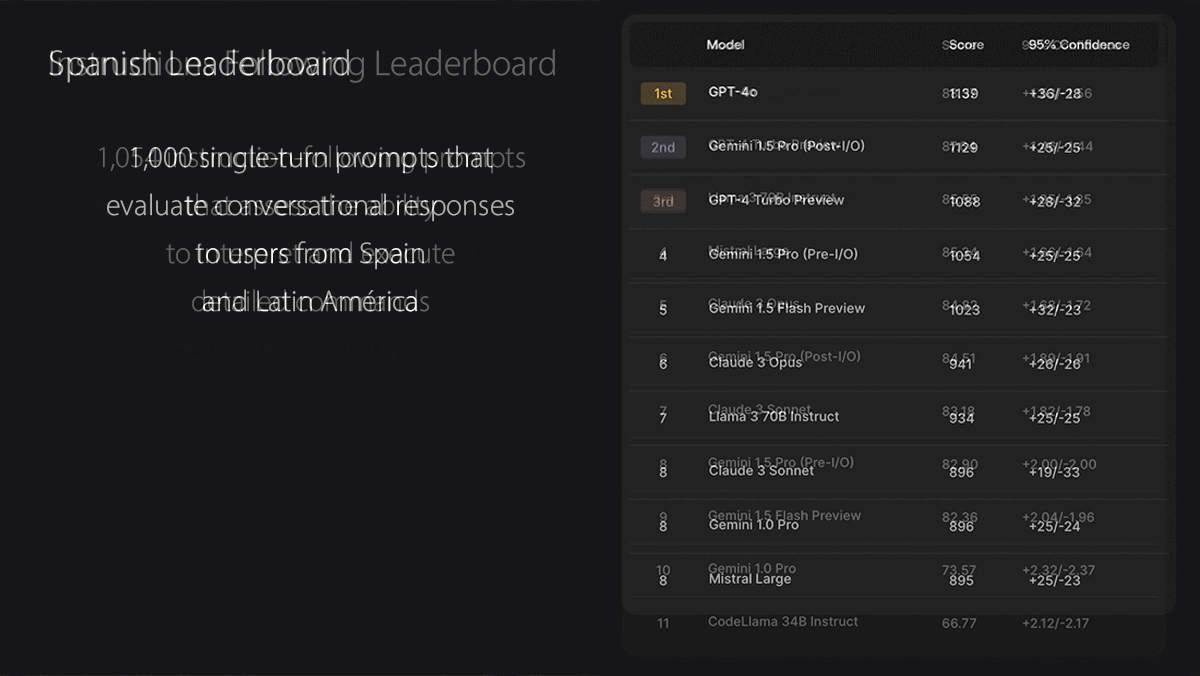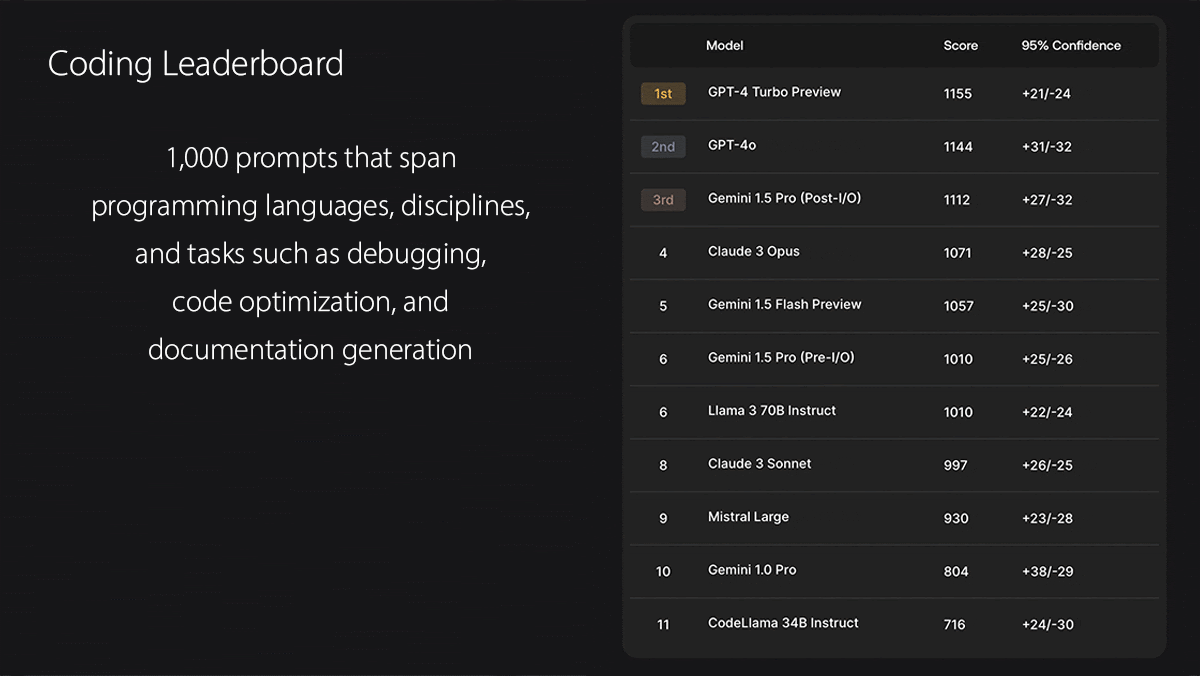
What’s new: Scale AI, which helps companies prepare and manage training data, introduced the Safety, Evaluations and Alignment Lab (SEAL) Leaderboards. Four leaderboards test models’ abilities to (i) generate code, (ii) work on Spanish-language inputs and outputs, (iii) follow detailed instructions, and (iv) solve fifth-grade math problems. The company currently tests 11 models from Anthropic, Google, Meta, Mistral, and OpenAI. Developers who want to have their model ranked can contact Scale AI via email.
How it works: The leaderboards track performance on proprietary datasets of roughly 1,000 examples. In all but the math tests, models to be evaluated are grouped and pitted against each other. Each pair receives 50 prompts at a time. Human annotators evaluate the models’ responses and grade which was superior and by how much. Then the models receive another 50 prompts. Models are ranked using a variation on Elo, which scores competitors relative to each other. To keep the test sets from leaking, a given model will be tested only once except in “exceptional cases” where Scale AI believes the risk of overfitting is low.
- The coding evaluation tests models’ abilities to generate code, analyze code, fix errors, and solve problems in SQL, Python, Java, JavaScript, HTML, CSS, C++, C, and C#. Annotators judge the code based on correctness, efficiency, readability, adherence to the prompt, and overall quality.
- The Spanish dataset tests the ability to respond to prompts written in European and Latin American Spanish, covering both general and cultural subject matter. Annotators evaluate the responses on 16 criteria including style, correctness, harmfulness, and internal contradiction. (The company plans to extend its multilingual evaluation to other languages.)
- Instruction Following asks models to fulfill detailed, multi-step instructions in a single response. The dataset includes prompts that ask a model to generate poetry, fiction, social posts, or responses playing a particular role. Annotators evaluate the responses using 12 criteria, including how well they reflect the prompt and how useful they are. They rate how well each model followed the instructions and how well they performed relative to each other.
- The Math leaderboard evaluates models on Scale AI’s GSM1k benchmark of fifth-grade arithmetic and algebra problems written in English. Unlike the other three tests, it tests whether responses are correct rather than pitting models against one another.
Results: As of this writing, GPT-4 Turbo tops the Coding leaderboard with GPT-4o a very close second. GPT-4o tops the Spanish and Instruction Following leaderboards, just ahead of Gemini 1.5 Pro in Spanish and GPT-4 Turbo in Instruction Following. On the Math leaderboard, Claude 3 Opus holds a narrow lead over GPT-4 Turbo (second) and GPT-4o (third).
Behind the news: As more models are trained on data scraped from the web, leakage of test data into training sets has made it more difficult to evaluate their performance on common benchmarks. Earlier this year, researchers at Shanghai Jiao Tong University evaluated 31 open-source large language models and found that several had a high probability of inaccurate benchmark results due to data leakage. Scale AI built the GSM1k math dataset partly to show that some high-profile language models show evidence of overfitting to the common math benchmark GSM8k.
Why it matters: Traditionally, benchmarks have been open source efforts. But proprietary benchmarks are emerging to help developers evaluate their models and applications with greater confidence. By keeping their datasets under wraps, companies like Scale AI and Vals AI ensure that models haven’t been exposed to test questions and answers previously, making evaluations more reliable. However, private benchmarks lack the transparency of their open counterparts. A mix of public, private, and internal evals may be necessary to get a well rounded picture of a given model’s capabilities.
We’re thinking: We welcome Scale AI’s contribution to the important field of evals, which also includes open benchmarks, LMSYS Chatbot Arena, and HELM.

From Clip to Composition
Is your song’s verse in need of a chorus? A popular text-to-music generator can extend existing recordings while maintaining their musical character.
What’s new: Paying users of Udio, a web service that generates pop-song productions from prompts, can upload audio clips and extend or alter them according to a text description. The service also increased its context window from 30 seconds to 2 minutes for more coherent output. You can hear the new capability here. Subscriptions start at $10 per month.
How it works: Given a prompt, Udio generates a 30-second passage and lets you assemble passages into compositions (previously up to four minutes long, now 15 minutes). Now users can create passages by uploading audio clips and extending them or modifying them by, say, adding or removing instruments or vocals complete with lyrics.
- In the demonstration video linked above, Udio adds a singing voice to an instrumental backing track using the prompt “funk, female vocalist.” Other examples enhance an electronic beat with a guitar melody and fill out hard-rock drums with a guitar riff and wailing voice.
- Users are responsible for securing legal rights to use audio files they upload. They retain commercial rights to audio that they produce using the software, as long as they specify that Udio generated the recording.
- Udio has shared few details about how it built its model. “A large amount of publicly available and high-quality music” was in the training set, CEO David Ding told Music Ally. The company has “very strong artist filters and a copyright focus” to avoid generating output that sounded too much like copyrighted music, he added.
Behind the news: Udio competes with Suno, whose service also generates audio output with vocals, lyrics, and song structures. Also in the mix is Stability AI, whose Stable Audio 2.0 enables users to upload and extend brief instrumental recordings to a length of around three minutes.
Why it matters: Udio is quickly becoming not just a song generator, but a song editor and builder. Just as the ability of text-to-image generators to edit, extend, and infill existing images made those applications more useful in a variety of creative situations, Udio’s audio-to-audio capabilities give composers and producers new horizons for enhancing, orchestrating, and structuring their own productions.
We’re thinking: Udio offers impressive capabilities for musicians (and wanna-be musicians), but its developer tools are lacking. A public-facing API would enable producers to automate the service and integrate it with other applications.

For Faster Diffusion, Think a GAN
Generative adversarial networks (GANs) produce images quickly, but they’re of relatively low quality. Diffusion image generators typically take more time, but they produce higher-quality output. Researchers aimed to achieve the best of both worlds.
What's new: Axel Sauer and colleagues at Stability AI accelerated a diffusion model using a method called adversarial diffusion distillation (ADD). As the name implies, ADD combines diffusion with techniques borrowed from GANs and teacher-student distillation.
Key insight: GANs are fast because they produce images in a single step. Diffusion models are slower because they remove noise from a noisy image over many steps. A diffusion model can learn to generate images in a single denoising step if, like a GAN, it learns to fool a discriminator, while the discriminator learns to identify generated output. The resulting one-step output doesn’t match the quality of multi-step diffusion, but distillation can improve it: While learning to fool the discriminator, the diffusion model (the student) can simultaneously learn to emulate the output of a different pretrained diffusion model (the teacher).
How it works: The authors paired a pretrained Stable Diffusion XL (SDXL) generator (the student) with a pretrained DINOv2 vision transformer discriminator. The teacher was another pretrained Stable Diffusion XL with frozen weights. They didn’t specify the training dataset.
- The researchers added noise to images in the training dataset. Given a noisy image and the corresponding caption, the student model removed noise in a single step.
- Given the student’s output, the discriminator learned to distinguish it from the images in the dataset.
- Given the student’s output with added noise plus the caption, the teacher removed the noise from the image in a single step.
- The student’s loss function encouraged the model to produce images that the discriminator could not distinguish from images in the dataset and to minimize the difference between the student’s and teacher’s output.
Results: The authors tested their method using 100 prompts from PartiPrompts. They compared the student’s output after either one or four denoising steps to a pretrained SDXL after 50 denoising steps. Human judges were asked which they preferred with respect to (i) image quality and (ii) alignment with the prompt. They preferred the student’s four-step images about 57 percent of the time for image quality and about 55 percent of the time for alignment with the prompt. They preferred SDXL to the student’s one-step images around 58 percent of the time for image quality and 52 percent of the time for alignment with the prompt.
Why it matters: In this work, the key steps — having a student model learn from a teacher model, and training a generator against a discriminator — are established techniques in their own right. Combining them conferred upon the student model the advantages of both.
We're thinking: With the growing popularity of diffusion models, how to reduce the number of steps they take while maintaining their performance is a hot topic. We look forward to future advances.