
Dear friends,
As we reach the milestone of the 256th issue of The Batch, I’m reflecting on how AI has changed over the years and how society continues to change with it. As AI becomes more widely available, it’s clear that many people — developers and non-developers — will benefit from high-quality training to keep up with the changes and gain useful AI skills.
In my years of working in education, I’ve felt that the world has enough low-quality courses, newsletters, social media posts, and other forms of content. It’s possible to build a business churning out mediocre content in sufficient volume to attract a meaningful amount of attention, but I have no interest in doing that.
At DeepLearning.AI, our core philosophy is to put learners first. Our team obsesses about how to create quality training or other programs that benefit people who want to learn about AI. We have intense debates about what tools to teach, which examples to include, even which partners to work with, based on what we think is best for learners.
For example, I recall vividly how, when working on the Machine Learning Specialization, our team spent ages debating whether to use row or column matrices. Both sides showed up with deep analysis of the pros and cons, made Powerpoint presentations to argue their case, and we spent hours debating over what was better for learners in terms of both ease of picking up the concepts as well as subsequently being able to use these skills with third-party machine learning libraries.
We don’t release a course unless we think it’s a good use of a learner’s time and we’d be proud to recommend it to our own friends and family members. Quality, of course, can mean a lot of things. I expect what we do to be technically accurate, useful, up to date, clear, and time-efficient for learners. And, if possible, fun!
We don’t always get it right, but we scrutinize learner feedback (one of my most important weekly routines is to study a dashboard that summarizes learner ratings of our courses) and work to make sure our courses serve learners well. And yes, we have a large-language model powered application that reads learner reviews to flag important issues quickly.

Earlier this year, we realized that some of the paid content we had launched was below our quality standard, and that I wouldn’t in good conscience recommend it to my friends or family members. Despite this content being profitable, we did what we felt was the right thing for learners. So we decided to retire that content and forgo the revenues, but we feel much better now for having done the right thing for learners.
When we teach courses with partners, we tell them our priorities are “learners first, partners second, ourselves last.” I’m grateful to the many wonderful companies and individuals that work with us to teach cutting-edge techniques, and given an opportunity we try to support our partners’ goals as well. But we never prioritize the interest of our educational partners over that of learners. Fortunately, our partners are onboard with this as well. We have a common goal to serve learners. Without their help, it would be difficult to teach many of the topics we do with high-quality content.
Quite a few companies have tried to offer to pay us to teach a course with them, but we’ve always said no. We work only with the companies that we think help us serve learners best, and are not interested in being paid to teach lower quality courses.
One reason I obsess about building quality training materials is that I think learning must be a habit. Learning a little every week is important to get through the volume of learning we all need, and additionally to keep up with changing technology. High-quality training that’s also fun supports a healthy learning habit!
Fun fact: In addition to taking online courses, I also read a lot. Recently I noticed that my digital reading app says I’ve been on a reading streak for 170 weeks. I’ve used the app for many years, but apparently I had broken and restarted my streak 170 weeks ago. What happened then? That was the week that my son was born, Coursera became a public company, and my grandfather died. While my life has had disruptions since then, I was happy to find that it takes a disruption of this magnitude to make me pause my learning habit for a week.
Keep learning!
Andrew
A MESSAGE FROM AI FUND AND DEEPLEARNING.AI

Join us for a Q&A webinar on July 11, 2024, at 11:00 AM Pacific Time. Andrew Ng and Roy Bahat will discuss business trends and strategies to integrate AI into organizations. Register now
News

OpenAI Blocks China and Elsewhere
OpenAI will stop serving users in China and other nations of concern to the U.S. government as soon as next week.
What’s new: Open AI notified users in China they would lose API access on July 9, Reuters reported. The move affects users in countries where the company doesn’t support access to its services officially (which include Cuba, Iran, Russia, North Korea, Syria, Venezuela, and others), but where it appears to have been serving API calls anyway.
How it works: Previously OpenAI blocked requests from outside supported countries if it detected a virtual private network or other method to circumvent geographic restrictions, but it had enforced such limits lightly according to Securities Times. The email warning started a race among AI companies in China to attract cast-off OpenAI users.
- Baidu said it would give former OpenAI users 50 million free tokens for its Ernie model, additional tokens equivalent to a customer’s OpenAI credits, and unlimited access to older models like Wenxin. Alibaba Cloud offered 22 million free tokens for Qwen-plus. Zhipu AI, a lesser-known startup, promised 50 million free tokens for its GPT-4 competitor GLM-4 and 100 million tokens for the lower-cost GLM-4 Air.
- Microsoft announced that customers in Hong Kong would be able to address OpenAI models via Azure, which has served the models there despite lack of official support by OpenAI. For the rest of China, Microsoft posted on WeChat a guide to migrating from Open AI’s API to equivalent service by Microsoft’s Chinese partner 21Vianet.
Behind the news: OpenAI’s crackdown on non-supported countries comes amid rising technological rivalry between the governments of the United States and China. The U.S. has taken several steps to try to curb China’s access to U.S.-built AI hardware and software, and some U.S. AI companies such as Anthropic and Google don’t operate in China. The Commerce Department plans to attempt to restrict China’s access to the most advanced AI models built by U.S. developers such as OpenAI. The Treasury Department issued draft restrictions on U.S. investments in AI companies based in China, Hong Kong, and Macau. Moreover, the U.S. imposed controls on exports of advanced GPUs to Chinese customers.
Why it matters: Many startups in China and elsewhere relied on OpenAI’s models. However, China’s development of AI models is already quite advanced. For example, Alibaba’s Qwen2, which offers open weights, currently tops Hugging Face’s Open LLM Leaderboard (see below), ahead of Meta's Llama 3.
We’re thinking: Efforts to restrict U.S. AI technology can go only so far. At this point, the U.S. seems to have at most a six-month lead over China. OpenAI’s move encourages other nations to make sure they have robust, homegrown models or access to open source alternatives.
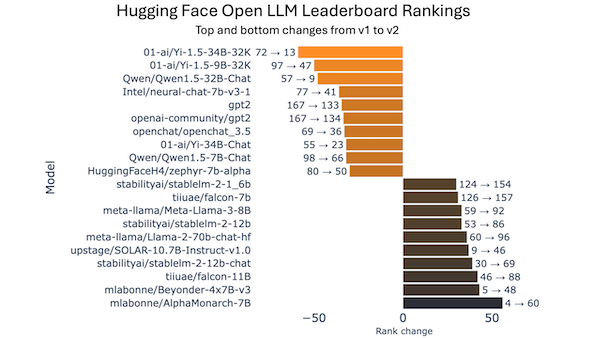
Challenging Human-Level Models
An influential ranking of open models revamped its criteria, as large language models approach human-level performance on popular tests.
What’s new: Hugging Face overhauled its Open LLM Leaderboard, reshuffling its assessments of the smartest contenders. The revised leaderboard is based on new benchmarks designed to be more challenging and harder to game.
Intelligence reordered: The new Open LLM Leaderboard paints a very different picture than the earlier version: Some models moved up or down as many as 59 places. In the debut rankings, Qwen2’s recently released 72-billion-parameter, instruction-tuned version topped the list with an average score of 43.02 out of 100. Meta’s Llama 3-70B-Instruct came in second with 36.67.
Addressing saturation and contamination: Launched last year, the earlier version (which is still operating) ranks open large language models according to an aggregate of scores on six popular benchmarks. However, in the intervening months, the best models approached human-level scores, partly due to technical improvements and partly because the test answers leaked into the models’ training sets. The revised leaderboard replaces the old tests and corrects earlier flaws and errors:
- MMLU-Pro updates the MMLU set of multiple-choice questions. MMLU-Pro offers 10 choices, while the earlier version offered four. The authors eliminated questions deemed too easy and made many others more difficult by, for instance, adding misleading answers. The results correlate well with human preferences as determined by the LMSYS Chatbot Arena.
- GPQA includes PhD-level questions in biology, physics, and chemistry. It’s intended to be very difficult for non-experts even with access to web search.
- MuSR asks models to answer lengthy, complex word problems that test multi-step reasoning. To do well, a model must solve murder mysteries, assign characters to perform tasks, and identify the locations of objects in a narrative.
- MATH lvl 5 includes multi-step math problems. The dataset covers five levels based on difficulty, but the benchmark includes only the hardest level.
- IFEval asks models to respond to prompts that include specific instructions like “no capital letters are allowed” and “your response must have three sections.”
- BIG-Bench Hard covers 23 diverse, complex tasks, such as understanding boolean expressions, detecting sarcasm, and determining shapes from graphics vectors. Examples are drawn from the most formidable problems in BIG-Bench. Like MMLU-PRo, BIG-Bench Hard scores correlate well with those of the LMSYS Chatbot Arena.
Behind the news: Leakage of training examples into test sets is a rising challenge to evaluating model performance. While Hugging Face relies on open benchmarks, other groups have attempted to address the issue by limiting access to the test questions or changing them regularly. Vals.AI, an independent model testing company, developed proprietary industry-specific tests for finance and law. Data consultancy Scale AI introduced its own leaderboards, measuring models on proprietary tests in natural languages, math, and coding.
Why it matters: Two million unique visitors browsed the Open LLM Leaderboard in the past year, and over 300,000 Hugging Face community members use and collaborate on it each month. Developers trust its scores, both individually and in aggregate, to decide which models to use and to judge the progress of their own efforts based on open models.
We’re thinking: As its name implies, the Open LLM leaderboard measures performance in natural language skills. Hugging Face also maintains an Open VLM Leaderboard, which tests vision-language skills.

Music Industry Sues AI Startups
A smoldering conflict between the music industry and AI companies exploded when major recording companies sued up-and-coming AI music makers.
What’s new: Sony Music, Universal Music Group (UMG), and Warner Music — the world’s three largest music companies — and a trade organization, Recording Industry Association of America (RIAA), sued Suno and Udio, which offer web-based music generators, for alleged copyright violations.
How it works: The music powers filed separate lawsuits against Suno and Udio in U.S. federal courts. The plaintiffs allege that the startups used copyrighted songs owned by RIAA members as training data, in the process making unauthorized copies without receiving permission or compensating the owners. They seek damages of at least $150,000 per song and cessation of further AI training on their catalogs.
- The recording companies argue that training AI models on songs involves making a number of unauthorized copies of the original music, first by scraping the audio files, then cleaning, converting file formats, dividing songs into subunits, and fine-tuning.
- To show that the startups had trained their models on copyrighted music, the recording companies presented examples (most of which are no longer available) in which they prompted a model to generate a copyrighted work. For instance, given the prompt, “m a r i a h c a r e y, contemporary r&b, holiday, Grammy Award-winning American singer-songwriter, remarkable vocal range,” Udio allegedly generated a facsimile of “All I Want for Christmas is You” by Mariah Carey. Other prompts that caused a model to generate an existing song included the song’s lyrics but not the artist’s name.
- The lawsuits claim that generated music directly competes with original music because Suno and Udio charge for their services and generated music can be used in lieu of copyrighted music. Furthermore, they claim the models’ outputs are not sufficiently transformative of copyrighted works for the copying to be considered fair use.
- Udio did not address the specific allegations. In a blog post, it compared its models to music students learning and taking inspiration from accomplished musicians. Suno’s CEO told Billboard, a music-industry trade magazine, that the company’s technology is transformative rather than copying.
Behind the news: Although major music companies have a history of taking action against AI companies, music streamers, and musicians who distributed generated likenesses of music they owned, they’re also working with AI startups on their own terms. For instance, UMG is collaborating with voice-cloning startup Soundlabs to create authorized synthetic voices of UMG artists. UMG, Sony, and Warner are also negotiating with YouTube to license music for a song generator to be launched this year.
Why it matters: As in similar lawsuits that involve text generators, the outcome of these actions could have an important impact on AI developers and users alike. Copyright law in the United States (and many other countries) does not address whether training AI models on copyrighted materials is a use that requires permission from copyright owners. In lieu of further legislation that answers the question, courts will decide. Assuming these cases go to trial, a verdict in favor of Suno or Udio would set a precedent that copyright doesn’t necessarily protect copyrighted works from AI training. Conversely, a verdict in favor of the music industry could restrict the use of copyrighted works in training, impeding a range of AI technologies that historically have been trained on data from the open internet.
We’re thinking: Copyright aims to prohibit unauthorized copying of intellectual property, but routine copying of data is built into the infrastructure of digital communications, never mind training AI systems. A web browser makes a temporary copy of every web page it displays, and web search engines typically copy the page they’ve indexed. It’s high time to revise copyright law for the AI era in ways that create the most value for the most people.

Model Merging Evolves
The technique of model merging combines separate models into a single, more capable model without further training, but it requires expertise and manual effort. Researchers automated the process.
What's new: Takuya Akiba and colleagues at Sakana, a research lab based in Tokyo, devised an automated method for merging models. It combines models trained for general tasks to produce models that perform well at the intersection of those tasks.
Key insight: Researchers have demonstrated various approaches to model merging. Earlier work showed that vision models of the same architecture can be combined with good results simply by averaging their corresponding weights, although subsequent studies revealed limitations in this approach. (When models have different architectures, averaging weights can combine parts they have in common.) An alternative is to stack layers drawn from different models. These methods can be varied and integrated to offer a wide variety of possible model combinations. An automated process that tries various combinations at random, finds the best performers among the resulting models, and recombines them at random can discover the high-performance combinations of these approaches without relying on intuition and experience.
How it works: The authors aimed to build a large language model that would solve problems in Japanese. They used the algorithm known as Covariance Matrix Adaptation Evolution Strategy (CMA-ES) to merge the Japanese-language LLM Shisa-Gamma and two math-specific, English-language LLMs: Abel and WizardMath. All three models were fine-tuned from Mistral 7B, which was pretrained on text from the web.
- The authors produced dozens of 10 billion-parameter models by merging the three initial ones. They merged the models by (i) combining weights of two or more layers from each model according to TIES-Merging and DARE and (ii) stacking either the combined layers or the original ones.
- They evaluated the merged models on 1,069 examples translated into Japanese from GSM8k, which contains grade-school word problems.
- They saved the models that performed best and repeated the process more than 100 times, merging the saved models and measuring their performance. The final model was the one with the highest accuracy on the translated GSM8k examples.
Results: The authors evaluated their model on the Japanese subset of Multilingual Grade School Math (MGSM). The merged model achieved 55.2 percent accuracy. Among the source models, Abel achieved 30.0 percent accuracy, WizardMath 18.4 percent accuracy, and Shisa Gamma 9.6 percent accuracy. The merged model’s performance fell between that of GPT-3.5 (50.4 percent accuracy) and GPT-4 (78.8 percent accuracy), which presumably are an order of magnitude larger.
Why it matters: Combining existing models offers a way to take advantage of their strengths without further training. It can be especially valuable in building models at the intersection between tasks, such as understanding Japanese language and solving math problems.
We're thinking: In addition to building new models, how can we make best use of the ones we already have? Merging them may be an efficient option.