
Dear friends,
“Democracy is the worst form of government, except for all the others,” said Winston Churchill. Last week’s shocking attempt to assassinate former President Trump was a reminder that democracy is fragile.
Democracy lets citizens argue with each other via words and votes. While imperfect, it is a powerful force for making sure that people are governed by leaders of their own choosing, and that these leaders are accountable to making people better off.
That’s why attempts to disrupt the democratic process, such as assassinating a political candidate or attempting to disrupt a peaceful handover of power to a newly elected government, are despicable: They attack a fundamental mechanism for giving everyone a chance to have a say in who governs. I denounce all political violence and grieve for Corey Comperatore, who was killed in the assassination attempt, and for his family. I hope for a quick recovery for former President Trump and the bystanders who were injured. I also hope we can put more resources into strengthening the mechanisms of democracy.
In addition, I wonder what role AI can play in preserving democracy.
Technology can have positive or negative impacts on specific mechanisms of democracy. For instance, data analysis can help citizens and reporters discover facts. Micro-targeting of political ads and social media can increase polarization, while social media can also provide useful information to voters.

But zooming out to a macro view,
- Concentration of power, which is enhanced by concentration of access to technology, tends to make a subset of society more powerful at the expense of the whole and thus weakens democracy. For example, if only major political parties have the resources to place highly targeted voter ads, it’s hard for new parties to break in.
- However, widespread access to new technologies tends to make everyone more powerful, and thus strengthens democracy. For example, widespread access to smartphones, web search, and now large language model chatbots broadens access to information and lets each individual do more. Thus, I believe spreading new technology as far and wide as possible is an important way to strengthen democracy.
I’m glad last week’s assassination attempt failed, just as I’m glad the January 6 insurrection at the U.S. Capitol failed. Both events were close calls and resulted in tragic loss of human life. Looking into the future, in addition to specific applications that strengthen elements of democracy, I hope we keep on promoting widespread access to technology. This will enhance fairness and the ability of individuals to vote wisely. That’s why democratizing access to technology will help democracy itself.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Enhance your software-development workflow with our new course, “Generative AI for Software Development.” Learn how to use generative AI tools to boost efficiency, improve code quality, and collaborate creatively. Pre-enroll today and be the first to join when the course goes live
News

Copyright Claim Fails in GitHub Case
A judge rejected key claims in a lawsuit by developers against GitHub, Microsoft, and OpenAI, the first decision in a series of court actions related to generative AI.
What’s new: A U.S. federal judge dismissed claims of copyright infringement and unfair profit in a class-action lawsuit that targeted GitHub Copilot and the OpenAI Codex language-to-code model that underpins it.
The case: In November 2022, programmer Matthew Butterick and the Joseph Saveri Law Firm filed the lawsuit in U.S. federal court. The plaintiffs claimed that GitHub Copilot had generated unauthorized copies of open-source code hosted on GitHub, which OpenAI Codex used as training data. The copies allegedly infringed on developers’ copyrights. The defendants tried repeatedly to get the lawsuit thrown out of court. In May 2023, the judge dismissed some claims, including a key argument that GitHub Copilot could generate copies of public code without proper attribution, and allowed the plaintiffs to revise their arguments.
The decision: The revised argument focused on GitHub Copilot’s duplication detection filter. When enabled, the filter detects output that matches public code on GitHub and revises it. The plaintiffs argued that the existence of this feature demonstrated GitHub Copilot’s ability to copy code in OpenAI Codex’s training set. The judge was not persuaded.
- The judge stated that the plaintiffs had not presented concrete evidence that Copilot could generate substantial copies of code. He dismissed this copyright claim with prejudice, meaning that the plaintiffs can’t refile it.
- The judge also dismissed a claim that GitHub illicitly profited from coders’ work by charging money for access to GitHub Copilot. To claim unjust enrichment under California law, plaintiffs must show that the defendant enriched itself through “mistake, fraud, coercion, or request.” The judge ruled that the plaintiffs had failed to demonstrate this.
Yes, but: The lawsuit is reduced, but it isn’t finished. A breach-of-contract claim remains. The plaintiffs aim to show that OpenAI and GitHub used open-source code without providing proper attribution and thus violated open-source licenses. In addition, the plaintiffs will refile their unjust-enrichment claim.
Behind the news: The suit against Github et al. is one of several underway that are testing the copyright implications of training AI systems. Getty Images, Authors’ Guild, The New York Times, and other media outlets along with a consortium of music-industry giants have sued OpenAI and other AI companies. All these cases rest on a claim that copying works protected by copyright for the purpose of training AI models violates the law — precisely what the plaintiffs failed to show in the GitHub case.
Why it matters: This lawsuit specifically concerns code written by open-source developers. A verdict could determine how code can be used and how developers can use generative AI in their work. However, it has broader implications. (Note: We are not lawyers and we do not provide legal advice.) This dismissal is not a final verdict, but it supports the view that AI developers may have a broad right to use data for training models even if that data is protected by copyright.
We’re thinking: Broadly speaking, we would like AI to be allowed to do with data, including open source code, anything that humans can legally and ethically do, including study and learn. We hope the judge’s decision gives AI developers further clarity on how they can use training data, and we hope it establishes that it’s ethical to use code-completion tools trained on open-source code.
How Open Are Open Models?
The word “open” can mean many things with respect to AI. A new paper outlines the variations and ranks popular models for openness.
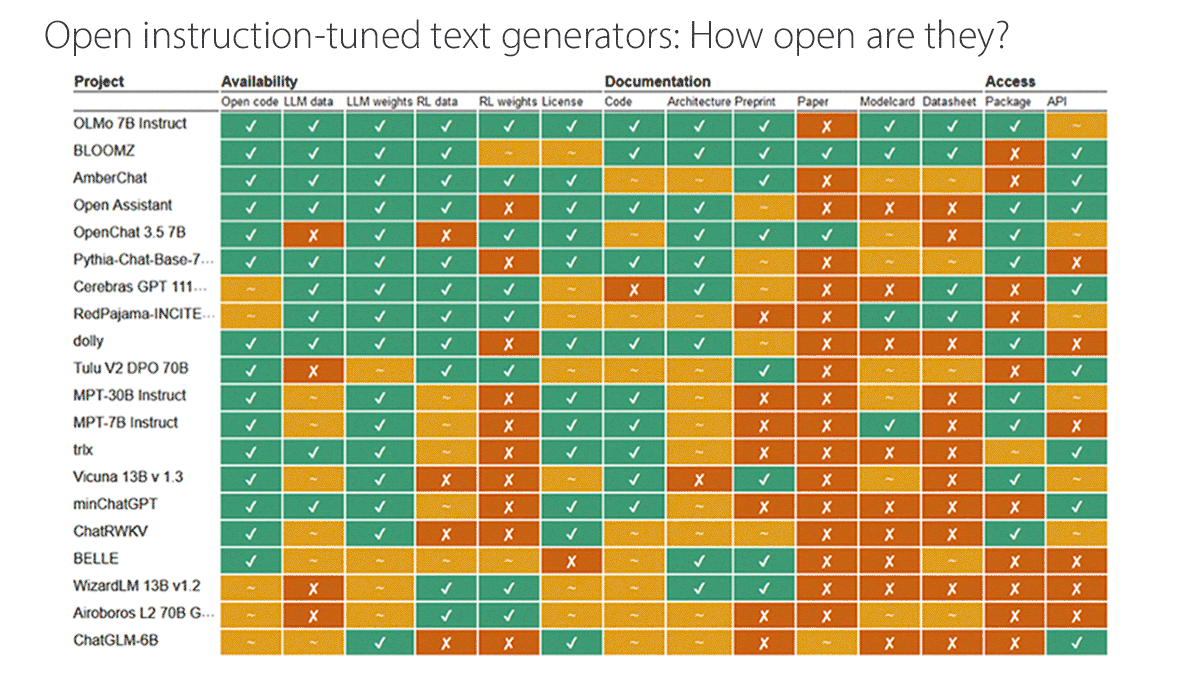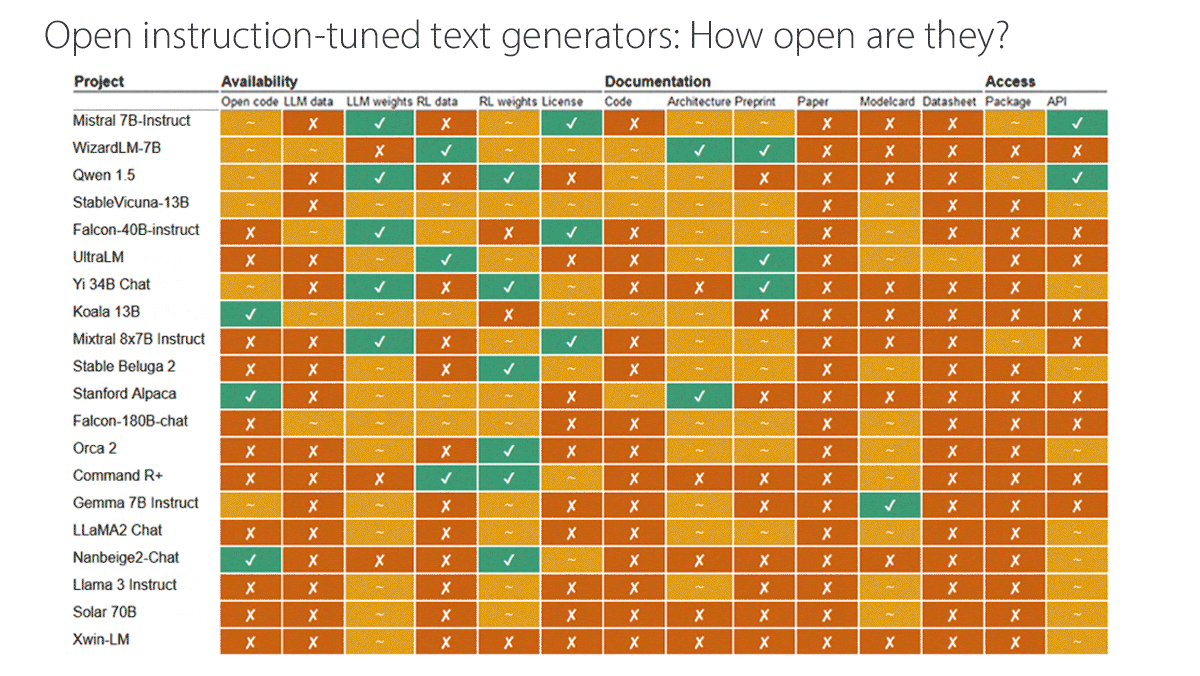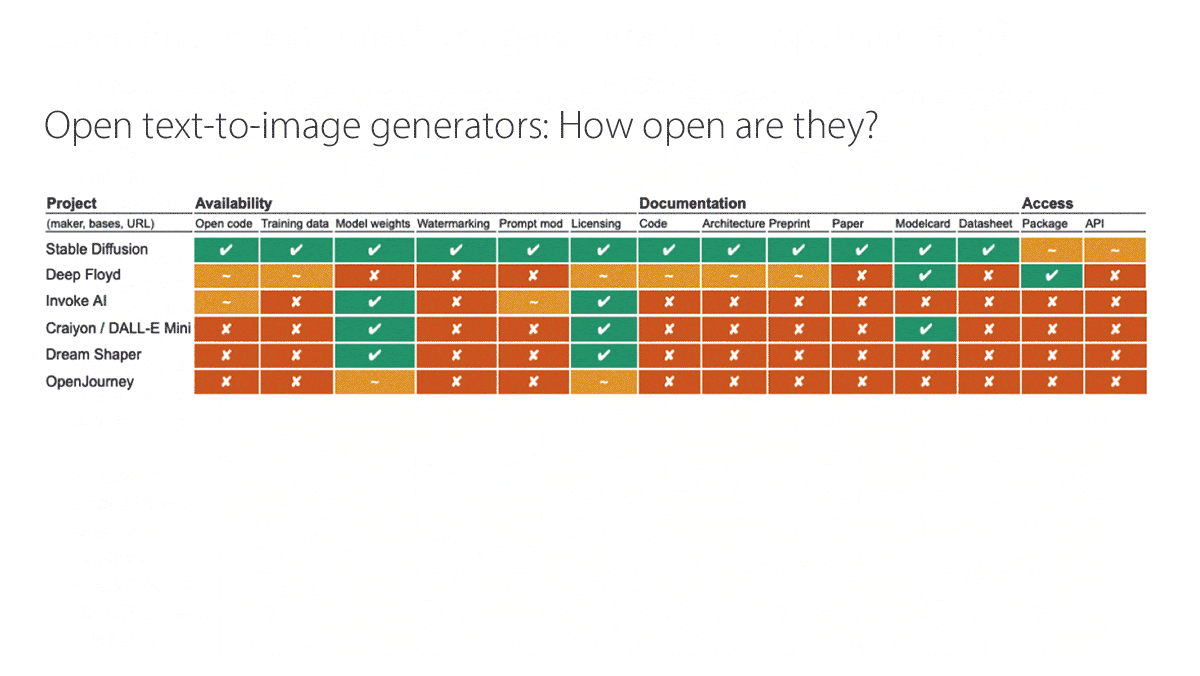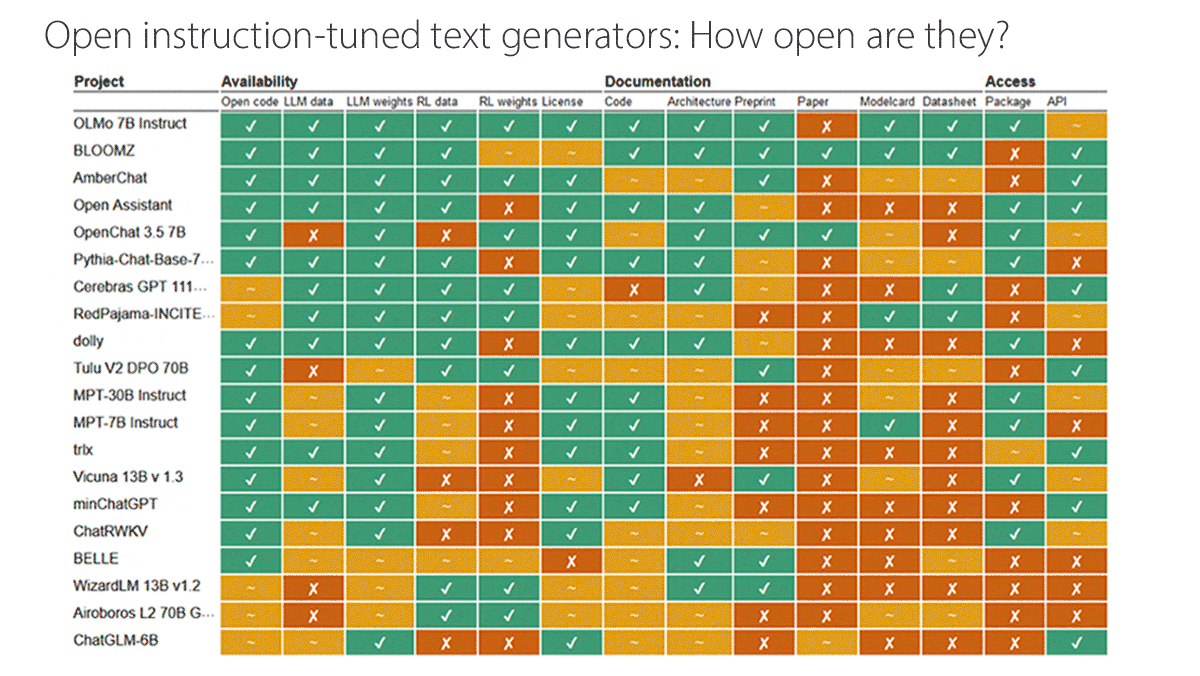
What’s new: Researchers at Radboud University evaluated dozens of models billed as open by their developers. They plan to keep their analysis of language models updated here.
How it works: The authors assessed 40 large language models and six text-to-image generators, adding OpenAI’s closed models ChatGPT and DALL·E 2 as reference points. They evaluated 14 characteristics, scoring each as open (1 point), partially open (0.5 points), or closed (0 points). For example, an API would be described as partially open if using it requires users to register. They divided the characteristics into three categories:
- Availability with respect to source code, pretraining data, base weights, fine-tuning data, fine-tuning weights, and licensing under a recognized open-source license
- Documentation of code, architecture, preprint paper, published peer-reviewed paper, model card, and datasheets that describe how the developer collected and curated the data
- Access to a downloadable package and open API
Results: Of the language models, OLMo 7B Instruct from Allen Institute for AI scored highest with 12 open characteristics and 1 partially open characteristic (it lacked a published, peer-reviewed paper).
- OLMo 7B Instruct and AmberChat (based on Llama-7B) were the only language models for which availability was fully open. BigScience’s BLOOMZ was the only language model whose documentation was fully open.
- Some prominent “open” models scored less well. Alibaba’s Qwen 1.5, Cohere’s Command R+, and Google’s Gemma-7B Instruct were judged closed or partially open for most characteristics. Falcon-40B-Instruct scored 2 open and 5 partially open characteristics. Neither Meta’s Llama 2 Chat nor Llama 3 Instruct achieved any open marks.
- Among text-to-image generators, Stability AI’s Stable Diffusion was far and away the most open. The authors deemed it fully open with respect to availability and documentation, and partially open with respect to access.
Behind the News: The Open Source Initiative (OSI), a nonprofit organization that maintains standards for open-source software licenses, is leading a process to establish a firm definition of “open-source AI.” The current draft holds that an open-source model must include parameters, source code, and information on training data and methodologies under an OSI-recognized license.
Why it matters: Openness is a cornerstone of innovation: It enables developers to build freely on one another’s work. It can also lubricate business insofar as it enables developers to sell products built upon fully open software. And it has growing regulatory implications. For example, the European Union’s AI Act regulates models that are released under an open source license less strictly than closed models. All these factors raise the stakes for clear, consistent definitions. The authors’ framework offers clear, detailed guidelines for developers — and policymakers — in search of clarity.
We’re thinking: We’re grateful to AI developers who open their work to any degree, and we especially appreciate fully open availability, documentation, and access. We encourage model builders to release their work as openly as they can manage.

Image Generators in the Arena
An arena-style contest pits the world’s best text-to-image generators against each other.
What’s new: Artificial Analysis, a testing service for AI models, introduced the Text to Image Arena leaderboard, which ranks text-to-image models based on head-to-head matchups that are judged by the general public. At the time of this writing, Midjourney v6 beats more than a dozen other models models in its ability to generate images that reflect input prompts, though it lags behind competitors in speed.
How it works: Artificial Analysis selects two models at random and feeds them a unique prompt. Then it presents the prompt and resulting images. Users can choose which model better reflects the prompt. The leaderboard ranks the models based on Elo ratings, which scores competitors relative to one another.
- Artificial Analysis selects models to test according to “industry significance” and unspecified performance tests. The goal is to identify and compare the most popular, high-performing models, especially those that are available via APIs. (Midjourney, which has no API, is an exception.) Only 14 models meet this threshold, but Artificial Analysis says it is refining its criteria and may include more models in the future.
- Users who have voted at least 30 times can see a personalized leaderboard based on their own voting histories.
- Separate from the Text to Image Arena, Artificial Analysis compares each model’s average time to generate and download an image, calculated by prompting each model four times a day and averaging the time to output over 14 days. It also tracks the price to generate 1,000 images.
Who’s ahead?: As of this writing, Midjourney v6 (Elo rating 1,176), which won 71 percent of its matches, holds a slim lead over Stable Diffusion 3 (Elo rating 1,156), which won 67 percent. DALL·E 3 HD holds a distant third place, barely ahead of the open-source Playground v2.5. But there are tradeoffs: Midjourney v6 takes 85.3 seconds on average to generate an image, more than four times longer than DALL·E 3 HD and more than 13 times longer than Stable Diffusion 3. Midjourney v6 costs $66 per 1,000 images (an estimate by Artificial Analysis based on Midjourney’s policies, since the model doesn’t offer per-image pricing), nearly equal to Stable Diffusion 3 ($65), less than DALL·E 3 HD ($80), and significantly more than Playground v2.5 ($5.13 per 1,000 images via the Replicate API).
Behind the news: The Text to Image Arena is a text-to-image counterpart of the LMSys Chatbot Arena, which lets users write a prompt, feed it to two large language models, and pick the winner. imgsys and Gen-AI Arena similarly let users choose between images generated by different models from the same prompt (Gen-AI Arena lets users write their own). However, these venues are limited to open models, which excludes the popular Midjourney and DALL·E.
Why it matters: An image generator’s ability to respond appropriately to prompts is a subjective quality. Aggregating user preferences is a sensible way to measure it. However, individual tastes and applications differ, which makes personalized leaderboards useful as well.
We’re thinking: The user interface for some image generators implicitly asks users to judge images. For example, Midjourney defaults to generating four images and asks users which they want to render at higher resolution. This can give the image generator valuable feedback about which image users like. Perhaps data gathered by an arena could feed an algorithm like reinforcement learning from human feedback to help generators learn to produce output that people prefer.
Hallucination Detector
Large language models can produce output that’s convincing but false. Researchers proposed a way to identify such hallucinations.
What’s new: Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal at University of Oxford published a method that indicates whether a large language model (LLM) is likely to have hallucinated its output.
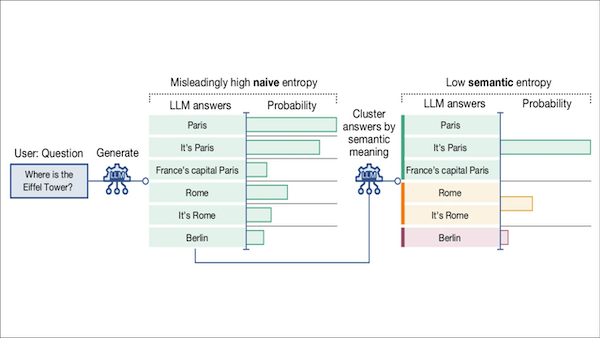
Key insight: One way to estimate whether an LLM is hallucinating is to calculate the degree of uncertainty, or entropy, in its output based on the probability of each generated token in the output sequences. The higher the entropy, the more likely the output was hallucinated. However, this approach is flawed: Even if the model mostly generates outputs with a uniform meaning, the entropy of the outputs can still be high, since the same meaning can be phrased in many different ways. A better approach is to calculate entropy based on the distribution of generated meanings instead of generated sequences of words. Given a particular input, the more likely a model is to respond by generating outputs with a variety of meanings, the more likely that a response to that input is a hallucination.
How it works: The authors generated answers to five open-ended question-and-answer datasets using various sizes of Falcon, LLaMA 2-chat, and Mistral. They checked the answers for hallucinations using the following method:
- Given a question, the model generated 10 answers.
- The authors clustered the answers based on their meanings. They judged two answers to have the same meaning if GPT-3.5 judged that the first followed logically from the second and vice versa.
- They computed the probabilities that the model would generate an answer in each cluster. Then they computed the entropy using those probabilities; that is, they calculated the model’s uncertainty in the meanings of its generated answers.
- All answers to a given question were considered to have been hallucinated if the computed entropy exceeded a threshold.
Results: The authors measured the classification performance of their method using AUROC, a score between .5 (the classifier is uninformative) and 1 (the classifier is perfect). On average, across all five datasets and six models, the authors’ method achieved .790 AUROC while the baseline entropy achieved .691 AUROC and the P(True) method achieved .698 AUROC. P(True) asks the model (i) to generate up to 20 answers and (ii) whether, given those answers, the one with the highest probability of having been generated is true or false.
Yes, but: The authors’ method fails to detect hallucinations if a model consistently generates wrong answers.
Behind the news: Hallucinations can be a major obstacle to deploying generative AI applications, particularly in fields like medicine or law where missteps can result in injury. One study published earlier this year found that three generative legal tools produced at least partially incorrect or incomplete information in response to at least one out of every six prompts. For example, given the prompt, “Are the deadlines established by the bankruptcy rules for objecting to discharge jurisdictional,” one model cited a nonexistent rule: “[A] paragraph from the Federal Rules of Bankruptcy Procedure, Rule 4007 states that the deadlines set by bankruptcy rules governing the filing of dischargeability complaints are jurisdictional.”
Why it matters: Effective detection of hallucinations not only fosters trust in users — and consequently rising adoption — but also enables researchers to determine common circumstances in which hallucinations occur, helping them to address the problem in future models.
We’re thinking: Researchers are exploring various approaches to mitigate LLM hallucinations in trained models. Retrieval augmented generation (RAG) can help by integrating knowledge beyond a model’s training set, but it isn’t a complete solution. Agentic workflows that include tool use to supply factual information and reflection to prompt the model to check itself are promising.
A MESSAGE FROM DEEPLEARNING.AI

In “Pretraining LLMs,” a short course built in collaboration with Upstage, you’ll learn about pretraining, the first step of training a large language model. You’ll also learn innovative pretraining techniques like depth upscaling, which can reduce training costs by up to 70 percent. Join today