
Dear friends,
AI’s usefulness in a wide variety of applications creates many opportunities for entrepreneurship. In this letter, I’d like to share what might be a counter-intuitive best practice that I’ve learned from leading AI Fund, a venture studio that has built dozens of startups with extraordinary entrepreneurs. When it comes to building AI applications, we strongly prefer to work on a concrete idea, meaning a specific product envisioned in enough detail that we can build it for a specific target user.
Some design philosophies say you shouldn’t envision a specific product from the start. Instead, they recommend starting with a problem to be solved and then carefully studying the market before you devise a concrete solution. There’s a reason for this: The more concrete or precise your product specification, the more likely it is to be off-target. However, I find that having something specific to execute toward lets you go much faster and discover and fix problems more rapidly along the way. If the idea turns out to be flawed, rapid execution will let you discover the flaws sooner, and this knowledge and experience will help you switch to a different concrete idea.
One test of concreteness is whether you’ve specified the idea in enough detail that a product/engineering team could build an initial prototype. For example, “AI for livestock farming” is not concrete; it’s vague. If you were to ask an engineer to build this, they would have a hard time knowing what to build. Similarly, “AI for livestock tracking in farming” is still vague. There are so many approaches to this that most reasonable engineers wouldn’t know what to build. But “Apply face recognition to cows so as to recognize individual cows and monitor their movement on a farm” is specific enough that a good engineer could quickly choose from the available options (for example, what algorithm to try first, what camera resolution to use, and so on) to let us relatively efficiently assess:
- Technical feasibility: For example, do face recognition algorithms developed for human faces work for cows? (It turns out that they do!)
- Business feasibility: Does the idea add enough value to be worth building? (Talking to farmers might quickly reveal that solutions like RFID are easier and cheaper.)
Articulating a concrete idea — which is more likely than a vague idea to be wrong — takes more courage. The more specific an idea, the more likely it is to be a bit off, especially in the details. The general area of AI for livestock farming seems promising, and surely there will be good ways to apply AI for livestock. In contrast, specifying a concrete idea, which is much easier to invalidate, is scary.

The benefit is that the clarity of a specific product vision lets a team execute much faster. One strong predictor of how likely a startup is to succeed is the speed with which it can get stuff done. This is why founders with clarity of vision tend to be desired; clarity helps drive a team in a specific direction. Of course, the vision has to be a good one, and there’s always a risk of efficiently building something that no one wants to buy! But a startup is unlikely to succeed if it meanders for too long without forming a clear, concrete vision.
Building toward something concrete — if you can do so in a responsible way that doesn’t harm others — lets you get critical feedback more efficiently and, if necessary, switch directions sooner. (See my letter on when it’s better to go with a “Ready, Fire, Aim” approach to projects.) One factor that favors this approach is the low cost of experimenting and iterating. This is increasingly the case for many AI applications, but perhaps less so for deep-tech AI projects.
I realize that this advice runs counter to common practice in design thinking, which warns against leaping to a solution too quickly, and instead advocates spending time understanding end-users, deeply understanding their problems, and brainstorming a wide range of solutions. If you’re starting without any ideas, then such an extended process can be a good way to develop good ideas. Further, keeping ideas open-ended can be good for curiosity-driven research, where investing to pursue deep tech with only a vague direction in mind can pay huge dividends over the long term.
If you are thinking about starting a new AI project, consider whether you can come up with a concrete vision to execute toward. Even if the initial vision turns out not to be quite right, rapid iteration will let you discover this sooner, and the learnings will let you switch to a different concrete idea.
Through working with many large corporations, AI Fund has developed best practices for identifying concrete ideas relevant to a business. I’ll share more on this in a later letter.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Learn how to build secure, privacy-focused federated learning systems using the Flower framework in a new two-part short course. Start with the basics in “Intro to Federated Learning,” and explore advanced techniques in “Federated Fine-tuning of LLMs with Private Data.” Enroll for free
News
Mini but Mighty
A slimmed-down version of Open AI’s multimodal flagship packs a low-price punch.
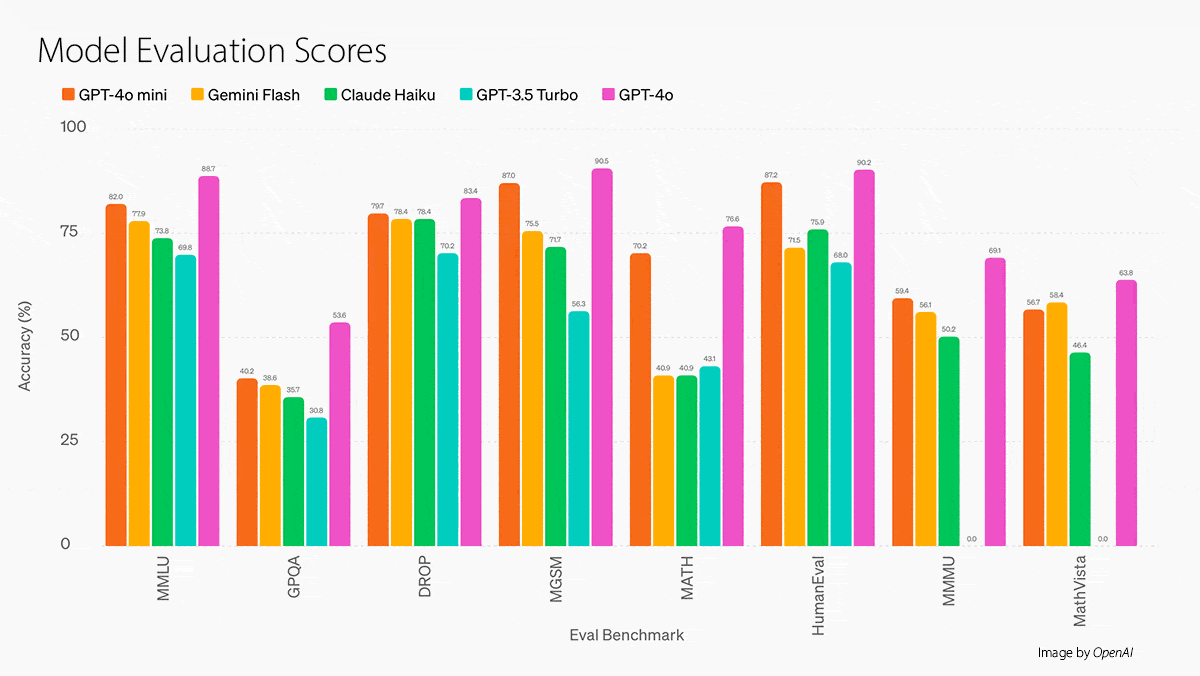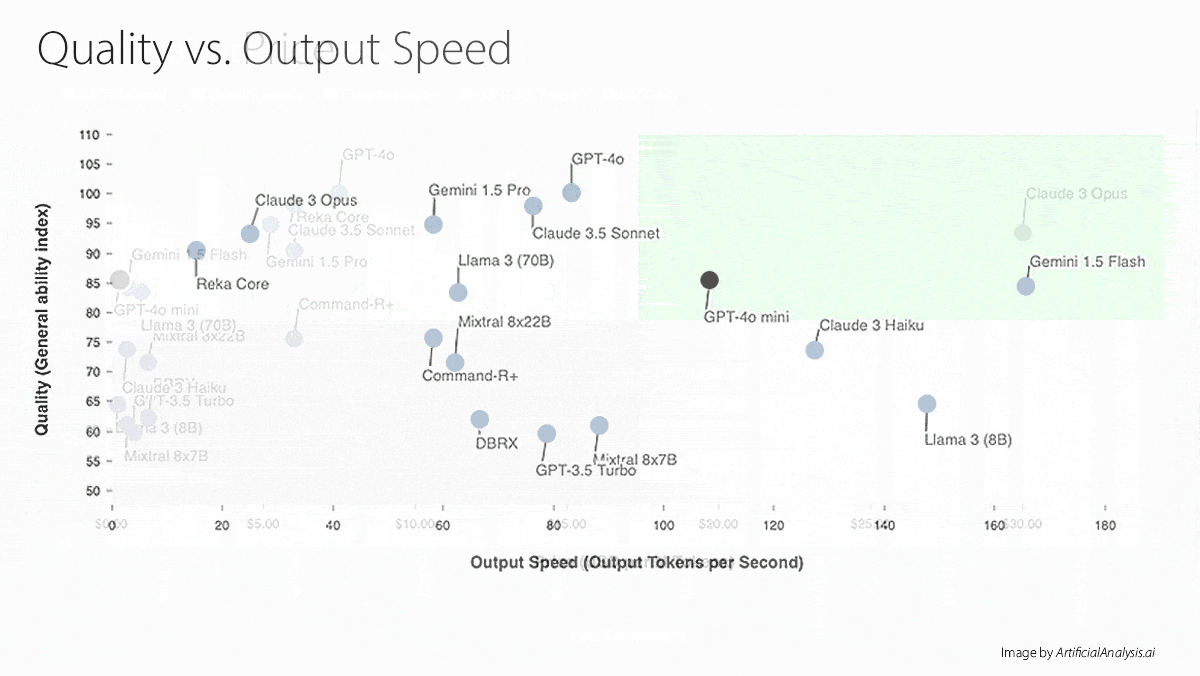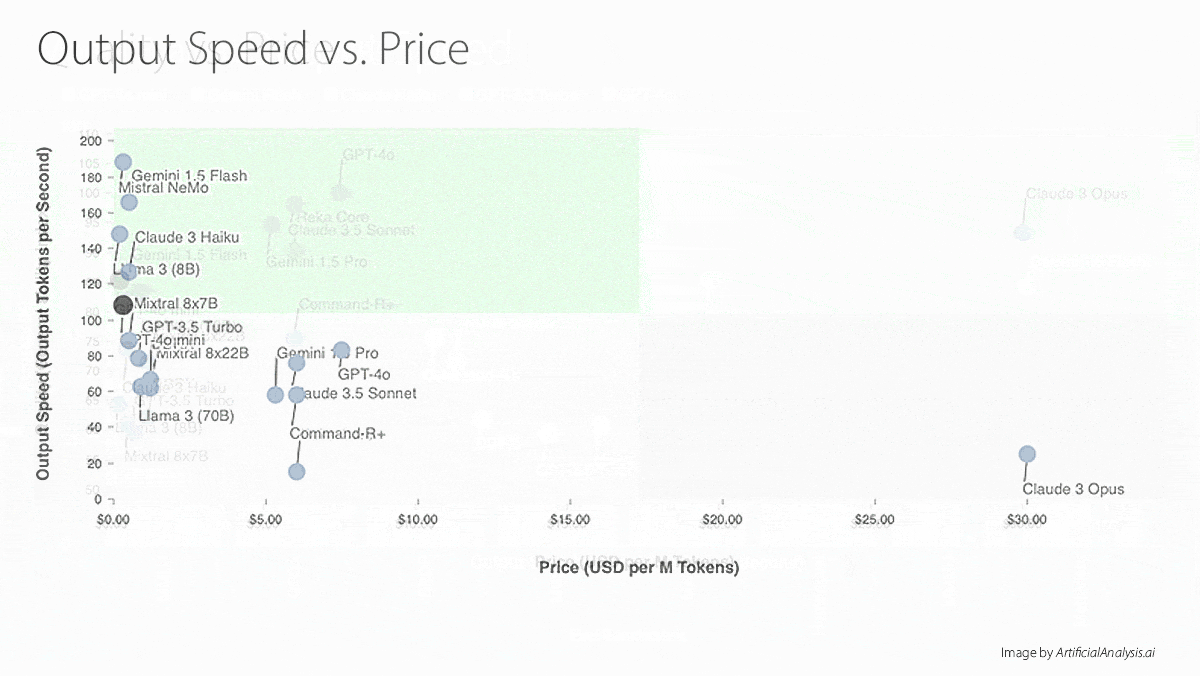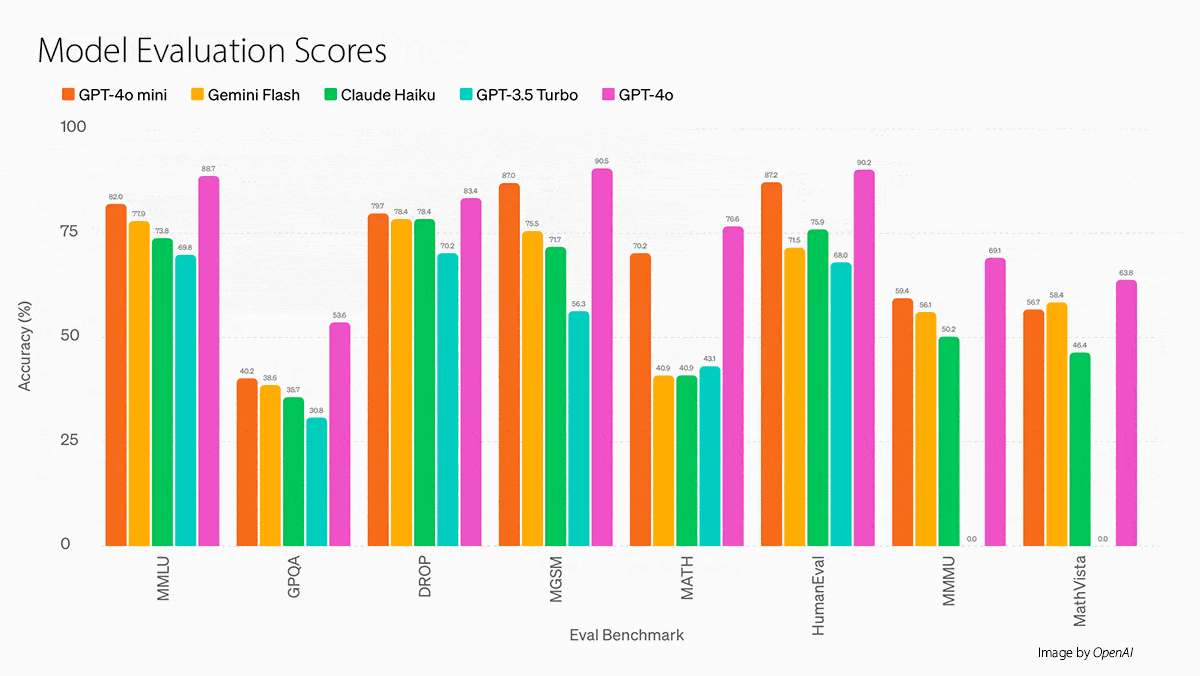
What’s new: OpenAI released GPT-4o mini, a smaller text-image-video-audio generative model that, according to the company, generally outperforms models from Google and Anthropic models of similar size at a lower price for API access. It newly underpins the free version of ChatGPT.
How it works: GPT-4o mini currently accepts text and image inputs and outputs text. Image output as well as video and audio input/output are coming soon. OpenAI did not provide information about its architecture or training but told TechCrunch it’s roughly the size of Claude 3 Haiku, Gemini 1.5 Flash, and the 8-billion-parameter version of Llama 3. It has a context window of 128,000 tokens and can output up to around 16,400 tokens.
- API access to GPT-4o mini, which costs $0.15/$0.60 per 1 million input/output tokens. That’s significantly less than the more capable GPT-4o ($5/$15 per 1 million input/output tokens with the same context window). It’s also more cost-effective and significantly better performing than GPT-3.5 Turbo ($0.50/$1.50 per 1 million input/output tokens with a 16,000-token context window).
- On the MMLU language understanding benchmark, GPT-4o mini beats Gemini 1.5 Flash at a lower cost, according to tests by Artificial Analysis. It’s just behind Llama 3 70B and Reka Core but costs around half as much as the former and 1/20th as much as the latter.
- GPT-4o mini (which generates 108 tokens per second) is slower than Llama 3 8B (166 tokens per second), Gemini 1.5 Flash (148 tokens per second), and Claude 3 Haiku (127 tokens per second) according to Artificial Analysis. However, GPT-4o mini speeds past GPT-4o, which produces 63 tokens per second.
Behind the news: GPT-4o mini part of a July wave of smaller large language models.
- Mistral and Nvidia jointly released Mistral NeMo (12 billion parameters). Its context window is 128,000 tokens, equal to GPT-4o mini and larger than most models of its size. It’s available under the Apache 2.0 open source license.
- Hugging Face debuted SmolLM, a family of three even smaller models — 135 million, 362 million, and 1.71 billion parameters — designed to run on mobile devices. The base and instruction-tuned versions including weights are freely available for download with no restrictions on commercial use. SmolLM is licensed under Apache 2.0.
Why it matters: Powerful multimodal models are becoming ever more widely available at lower prices, creating opportunities for developers and researchers alike. GPT-4o mini sets a new standard for others to beat. Its price may be especially appealing to developers who aim to build agentic workflows that require models to process large numbers of tokens on their way to producing output.
We’re thinking: Not long ago, pushing the edge of large language models meant making them larger, with higher computing costs to drive rising parameter counts. But building bigger models has made it easier to develop smaller models that are more cost-effective and nearly as capable. It’s a virtuous circle: Costs fall and productivity rises to everyone’s benefit.
Meta Withholds Models From Europe
European users won’t have access to Meta’s multimodal models.
What’s new: Meta said it would withhold future multimodal models from the European Union (EU) to avoid being charged, banned, or fined for running afoul of the region’s privacy laws, according to Axios. (The newly released Llama 3.1 family, which processes text only, will be available to EU users.)
How it works: EU data regulators have said that Meta may be violating EU privacy laws by training models on data from Facebook, Instagram, and its other properties. Meta’s move in Europe follows its withdrawal of generative models from Brazil, after that country’s national data-protection authority struck down the part of Meta’s privacy policy that allowed it to use personal data from users of Meta products to train AI models.
- EU companies will not be able to build applications on future multimodal models from Meta. Companies outside the EU that build products based on these models will not be able to deliver them to EU customers. Text-only versions including Llama 3.1, as well as applications built on them, will continue to be available in the EU.
- In a blog post in May, Meta announced that it would train models on text and images that are publicly visible on Meta-owned services; for example, public Facebook posts and public Instagram photos and their captions. The data-protection authorities of 11 EU member states (including Ireland, where Meta’s European headquarters is located), objected to Meta’s collection of this data from EU users. Meta responded by delaying its collection of user data in the EU.
- The UK has a nearly identical data-protection law, but Meta does not plan to restrict its models there. That’s because UK regulators have been clearer than their EU counterparts about the law’s requirements, a Meta representative told Axios.
Apple and OpenAI in Europe: Meta is not the only global AI company that’s wary of EU technology regulations.
- In June, Apple announced it would withhold generative AI features from iOS devices in the EU. Apple said the EU’s Digital Markets Act, which requires that basic applications like web browsers, search engines, and messaging be able to work together regardless of the operating systems they run on, prevented it from deploying the features to EU customers without compromising user privacy.
- Early in the year, OpenAI drew attention from Italian regulators, who briefly banned ChatGPT in 2023 for violating EU law. As of May, a multinational task force was investigating the matter.
Why it matters: Different regions are taking different paths toward regulating AI. The EU is more restrictive than others, creating barriers to AI companies that develop new technology and products. Meta and Apple are taking proactive steps to reduce their risks even if it means foregoing portions of the European market.
We’re thinking: We hope regulators everywhere will think hard about how to strike a balance between protecting innovation and other interests. In this instance, the EU’s regulations have prompted Meta to make a decision that likely likely set back European AI while delivering little benefit to citizens.

AI Investors Hoard GPU Power
Investors have been gathering AI chips to attract AI startups.
What’s new: Venture-capital firms are stockpiling high-end graphics processing units (GPUs), according to a report by The Information. They’re using the hardware to provide processing power to their portfolio companies at reduced or no cost.
How it works: Andreessen Horowitz (A16Z), a prominent Silicon Valley venture investment firm, has amassed the largest known stock of GPUs dedicated to venture-funded startups. The firm plans to acquire more than 20,000 GPUs including top-of-the-line Nvidia H100s, which can sell for tens of thousands of dollars each — roughly enough to train a competitive large language model.
- A16Z offers access at below-market rates or in exchange for equity in startups it funds.
- Whether A16Z purchased GPUs or ia paying a third-party cloud provider for access is not clear.
- Luma AI, funded by A16Z, used the venture firm’s compute resources and, in June, released the Dream Machine video generator. Luma AI CEO and co-founder Amit Jain said the company turned down funders who offered more lucrative terms because A16Z offered GPUs.
Behind the news: High-end GPUs were in short supply early last year. The shortage has eased significantly, but getting access to enough processing power to train and run large models still isn’t easy. A16Z follows several other investors that have sought to fill the gap for startups.
- Ex-GitHub CEO Nat Friedman and Daniel Gross, who has provided capital to startups including Github, Character.ai, Perplexity.ai, and Uber, established the Andromeda Cluster, a group of supercomputers with more than 4,000 GPUs between them, including over 2,500 H100s. They offer access to startups in their portfolio at below-market rates.
- Last year, Index Ventures agreed to pay Oracle for access to H100 and A100 GPUs. In turn, it made them available to portfolio companies for free.
- Microsoft provides free access to GPUs via its Azure cloud service to startups funded by its venture fund M12 and the venture accelerator Y Combinator.
Yes, but: David Cahn, a partner at A16Z rival Sequoia Capital, argues that stockpiling GPUs is a mistake that could leave venture funds holding large quantities of expensive, rapidly depreciating, hardware. Cahn believes startups and small developers soon may have an easier time getting their hands on the processing power they need. Nvidia recently announced its new B100 and B200 GPUs, whose arrival should stanch demand for older units like the H100.
Why it matters: AI startups are hot, and venture-capital firms compete for early equity in the most promising ones. In addition to funding, they frequently offer advice, contacts, office support — and now processing power to empower a startup to realize its vision.
We’re thinking: Venture investors who use GPUs to sweeten a deal give new meaning to the phrase “bargaining chips.”

Expressive Synthetic Talking Heads
Previous systems that produce a talking-head video from a photo and a spoken-word audio clip animate the lips and other parts of the face separately. An alternative approach achieves more expressive results by animating the head as a whole.
What’s new: Sicheng Xu and colleagues at Microsoft developed VASA-1, a generative system that uses a facial portrait and spoken-word recording to produce a talking-head video with appropriately expressive motion. You can see its output here.
Key insight: When a person speaks, the facial expression and head position change over time, while the overall shapes of the face and head don’t. By learning to represent an image via separate embeddings for facial expression and head position — which change — as well as for facial structure in its 2D and 3D aspects — which don’t — a latent diffusion model can focus on the parts of the image that matter most. (Latent diffusion is a variant of diffusion that saves computation by processing a small, learned vector of an image instead of the image itself.)
How it works: VASA-1 comprises four image encoders (three 2D CNNs and one 3D CNN), one image decoder (another 2D CNN), Wav2Vec 2.0, and a latent diffusion image generator. The authors trained the system, given an image of a face and a recorded voice, to generate a series of video frames that conform to the voice. The training set was VoxCeleb2, which includes over 1 million short videos of celebrities talking. The authors added labels for gaze direction, head-to-camera distance, and an emotional intensity score computed by separate systems.
- Given an image of a face, the encoders learned to generate embeddings that represented the 2D facial structure (which the authors call “identity”), 3D contours (“appearance”), head position, and facial expression. Given the embeddings, the decoder reconstructed the image. The authors trained the encoders and decoder together using eight loss terms. For instance, one loss term encouraged the system to reconstruct the image. Another encouraged the system, when it processes a different image of the same person (with different head positions and facial expressions), to produce a similar identity embedding.
- Given a video, the trained encoders produced a sequence of paired head-position and facial-expression embeddings, which the authors call a “motion sequence.”
- Given the accompanying voice recording, a pretrained Wav2Vec2 produced a sequence of audio embeddings.
- Given the audio embeddings that correspond to a series of consecutive frames, the latent diffusion model learned to generate the corresponding embeddings in the motion sequence. It also received other inputs including previous audio and motion sequence embeddings, gaze direction, head-to-camera distances, and emotional-intensity scores.
- At inference, given an arbitrary image of a face and an audio clip, VASA produced the appearance and identity embeddings. Then it produced audio embeddings and motion-sequence embeddings. It generated the final video by feeding the appearance, identity, and motion sequence embeddings to its decoder.
Results: The authors measured their results by training a model similar to CLIP that produces a similarity score on how well spoken audio matches a video of a person speaking (higher is better). On the VoxCeleb2 test set, their approach produced a similarity score of 0.468 compared to 0.588 for real video. The nearest contender, SadTalker, which generates lip, eye, and head motions separately, achieved a similarity score of 0.441.
Why it matters: By learning to embed different aspects of a face separately, the system maintained the face’s distinctive, unchanging features while generating appropriate motions. This also made the system more flexible at inference: The authors demonstrated its ability to extract a video’s facial expressions and head movements and apply them to different faces.
We’re thinking: Never again will we take talking-head videos at face value!
A MESSAGE FROM WORKERA

Test, benchmark, and grow your skills with new assessments from Workera! Available domains include AI Foundations, Machine Learning, GenAI, and MLOps. Try Workera today for $0!