
Dear friends,
Last week, I wrote about why working on a concrete startup or project idea — meaning a specific product envisioned in enough detail that we can build it for a specific target user — lets you go faster. In this letter, I’d like to share some best practices for identifying promising ideas.
AI Fund, which I lead, works with many corporate partners to identify ideas, often involving applications of AI to the company’s domain. Because AI is applicable to numerous sectors such as retail, energy, logistics and finance, I’ve found working with domain experts who know these areas well immensely helpful for identifying what applications are worth building in these areas.
Our brainstorming process starts with recommending that a large number of key contributors at our partner corporation (at least 10 but sometimes well over 100) gain a non-technical, business-level understanding of AI and what it can and can’t do. Taking DeepLearning.AI’s “Generative AI for Everyone” course is a popular option, after which a company is well positioned to assign a small team to coordinate a brainstorming process, followed by a prioritization exercise to pick what to work on. The brainstorming process can be supported by a task-based analysis of jobs in which we decompose employees’ jobs into tasks to identify which ones might be automated or augmented using AI.
Here are some best practices for these activities:
Trust the domain expert’s gut. A domain expert who has worked for years in a particular sector will have well honed instincts that let them make leaps that would take a non-expert weeks of research.
Let’s say we’re working with a financial services expert and have developed a vague idea (“build a chatbot for financial advice”). To turn this into a concrete idea, we might need to answer questions such as what areas of finance to target (should we focus on budgeting, investing, or insurance?) and what types of user to serve (fresh graduates, mortgage applicants, new parents, or retirees?) Even a domain expert who has spent years giving financial advice might not know the best answer, but a choice made via their gut gives a quick way to get to one plausible concrete idea. Of course, if market-research data can be obtained quickly to support this decision, we should take advantage of it. But to avoid slowing down too much, we’ve found that experts’ gut reactions work well and are a quick way to make decisions.
So, if I’m handed a non-concrete idea, I often ask a domain expert to use their gut — and nothing else — to quickly make decisions as needed to make the idea concrete. The resulting idea is only a starting point to be tweaked over time. If, in the discussion, the domain expert picks one option but seems very hesitant to disregard a different option, then we can also keep the second option as a back-up that we can quickly pivot to if the initial one no longer looks promising.

Generate many ideas. I usually suggest coming up with at least 10 ideas; some will come up with over 100, which is even better. The usual brainstorming advice to go for volume rather than quality applies here. Having many ideas is particularly important when it comes to prioritization. If only one idea is seriously considered — sometimes this happens if a senior executive has an idea they really like and puts this forward as the “main” idea to be worked on — there’s a lot of pressure to make this idea work. Even if further investigation discovers problems with it — for example, market demand turns out to be weak or the technology is very expensive to build — the team will want to keep trying to make it work so we don’t end up with nothing.
In contrast, when a company has many ideas to choose from, if one starts to look less interesting, it’s easy to shift attention to a different one. When many ideas are considered, it’s easier to compare them to pick the superior ones. As explained in the book Ideaflow, teams that generate more ideas for evaluation and prioritization end up with better solutions.
Because of this, I’ve found it helpful to run a broad brainstorming process that involves many employees. Specifically, large companies have many people who collectively have a lot of wisdom regarding the business. Having a small core team coordinate the gathering of ideas from a large number of people lets us tap into this collective fountain of invention. Many times I’ve seen a broad effort (involving, say, ~100 people who are knowledgeable about the domain and have a basic understanding of AI) end up with better ideas than a narrow one (involving, say, a handful of top executives).
Make the evaluation criteria explicit. When evaluating and prioritizing, clear criteria for scoring and ranking ideas helps the team to judge ideas more consistently. Business value and technical feasibility are almost always included. Additionally, many companies will prioritize projects that can be a quick win (to build momentum for their overall AI efforts) or support certain strategic priorities such as growth in a particular part of the business. Making such criteria explicit can help during the idea-generation phase, and it’s critical when you evaluate and prioritize.
In large companies, it can take a few weeks to go through a process to gather and prioritize ideas, but this pays off well in identifying valuable, concrete ideas to pursue. AI isn’t useful unless we find appropriate ways to apply it, and I hope these best practices will help you to generate great AI application ideas to work on.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Join our new short course and gain an in-depth understanding of embedding models! Learn to train and use Word2Vec and BERT in semantic search systems, and build a dual-encoder model with a contrastive loss to enhance question-answer accuracy. Sign up today
News
The State of the Art Is Open
Meta raised the bar for large language models with open weights and published details about how it built one that outperforms GPT-4o and Claude 3.5 Sonnet by some measures.
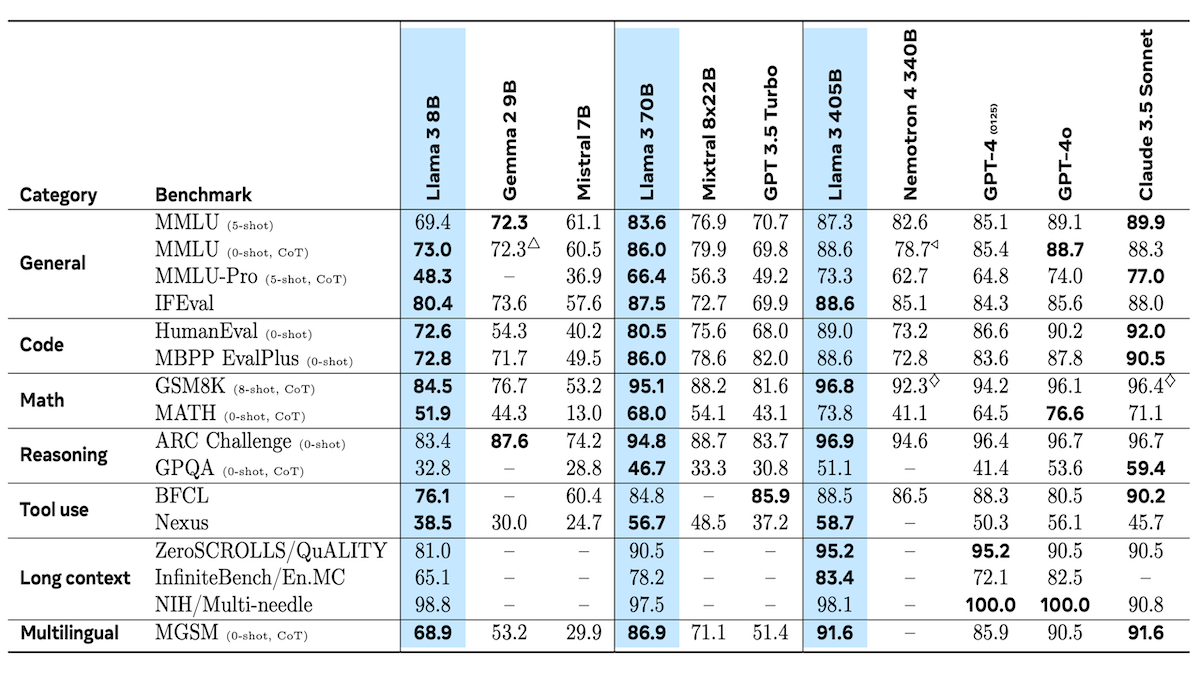
What's new: Llama 3.1 405B delivers state-of-the-art performance on a handful of public benchmarks and has a context window of 128,000 input tokens while allowing a range of commercial uses. In addition to the 405-billion parameter model, Meta released new versions of the earlier Llama 3 70B (70 billion parameters) and 8B (8 billion parameters). Model weights are available here.
Key insight: Fine-tuning on generated data can improve a model’s performance, but incorrect or lower-quality examples degrade it. The Llama team undertook an extensive effort to fix or remove bad examples using a variety of tools including the model itself, auxiliary models, and off-the-shelf tools.
How it works: Llama 3.1 models are transformers that have been pretrained to predict the next token in a sequence. Meta provided more information about the development of Llama 3.1 405B than the smaller versions. Its pretraining dataset comprised 16.4 trillion tokens of text, “much” of it scraped from the web. The pretrained model was fine-tuned to perform seven tasks, including coding and reasoning, via supervised learning and direct preference optimization (DPO). Most of the fine-tuning data was generated by the model itself and curated using a variety of methods including agentic workflows. For instance,
- To generate good code to learn from, the team: (1) Generated programming problems from random code snippets. (2) Generated a solution to each problem, prompting the model to follow good programming practices and explain its thought process in comments. (3) Ran the generated code through a parser and linter to check for issues like syntax errors, style issues, and uninitialized variables. (4) Generated unit tests. (5) Tested the code on the unit tests. (6) If there were any issues, regenerated the code, giving the model the original question, code, and feedback. (7) If the code passed all tests, added it to the dataset. (8) Fine-tuned the model. (9) Repeated this process several times.
- To generate fine-tuning data that represented good lines of reasoning, the team: (1) Generated math questions and answers from math problems. (2) Manually identified the types of problems the model struggled with. (3) Asked humans to write questions for those problems. (4) Generated step-by-step answers for those problems. (5) Removed examples that end with the wrong answer. (6) Asked the model to determine whether the reasoning was correct. (7) Removed examples that the model identified as having incorrect reasoning. (8) Trained separate models to determine if the reasoning was correct. (9) Used those models to filter out incorrect examples.
Results: The authors compared Llama 3.1 405B to Claude 3.5 Sonnet, GPT-4, GPT-4o, and Nemotron 4 340B on 16 public benchmarks. It either outperformed or tied the other models on seven of the 16 (although two, GSM8K and MMLU zero-shot chain-of-thought, are not directly comparable due to differences in prompting methods). For instance, Llama 3.1 405B set a new state of the art in IFEval (general knowledge), ARC Challenge (reasoning), and Nexus (tool use). The smaller versions outperformed other models in the same general size classes as well. Llama 3.1 70B set new states of the art in all benchmarks for general knowledge, coding, math, and reasoning. Llama 3.1 8B dominated general, coding, and math benchmarks.
License: Llama 3.1 models are licensed under a custom license that allows both commercial use (by companies with up to 700 million monthly active users in the month prior to Llama 3.1’s release) and training other models on generated data. This enables many companies to use it as they like while potentially requiring Meta’s largest competitors to negotiate a commercial license.
The French connection: Separately, Mistral announced its next-generation LLM Mistral Large 2, which allows noncommercial use but requires a special license for commercial use. The 123 billion-parameter model boasts performance similar to that of Llama 3.1 405B on a number of benchmarks despite being less than one-third the size.
Why it matters: The Llama 3.1 family continues Meta’s contributions in open models and extends them to some commercial uses. The upgraded 8B and 70B models perform better than their predecessors, while the 405B version rivals top proprietary models and enables researchers to generate high-quality synthetic data for training further models. The team provides extensive detail about how they generated fine-tuning data. For each task, they describe the pipeline used to create the data along with various notes about what worked and what didn’t work for them — helpful information for researchers who aim to build next-generation LLMs.
We're thinking: Data-centric AI, the discipline of systematically engineering data to build a successful AI system, is critical for machine learning. The Llama 3.1 paper makes clear that systematically engineering the training data was also a key to training what is, as far as we know, the first open weights model to achieve better performance than the best proprietary models on multiple benchmarks. The potential of open weights is looking better every day!
Search Gets Conversational
OpenAI is testing an AI-powered search engine in a bid to compete head-to-head with both Google and its close partner Microsoft Bing.
What’s new: OpenAI released SearchGPT, an integrated search engine and large language model that aims to be friendly to both users and publishers. Access is limited initially to selected trial users. OpenAI offers a wait list but no timeline for expanding access.
How it works: SearchGPT sorts results collected by web crawler, like Google and its competitors. It differs in providing direct answers to queries and offering a conversational user interface for follow-up questions. OpenAI has not disclosed the underlying model.
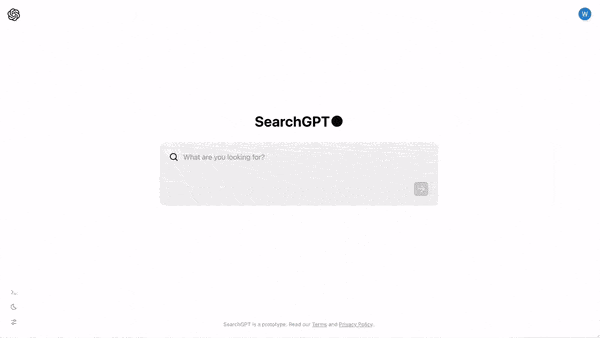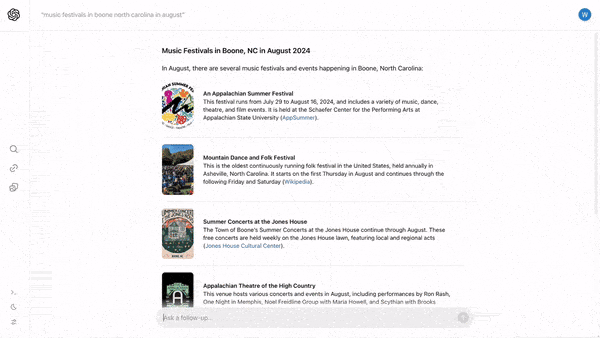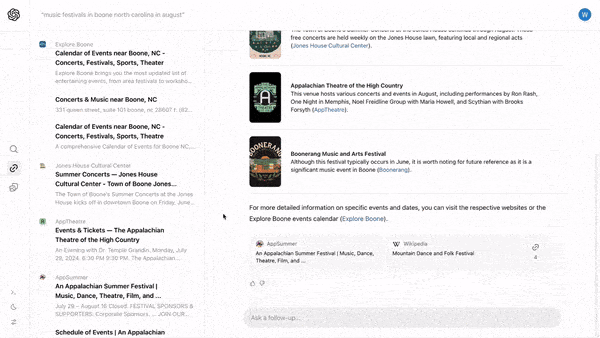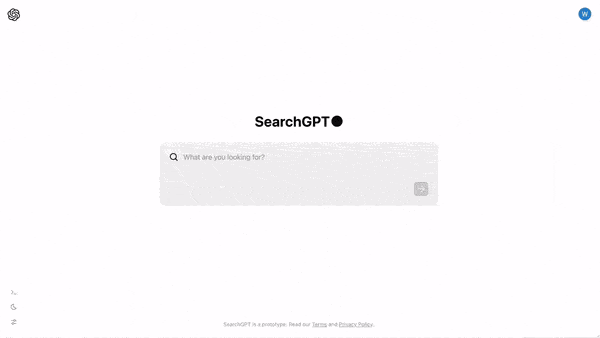
- Given a question or search string like “best tomatoes to grow in Minnesota,” SearchGPT returns an answer such as a list of tomato varieties. Typically it adds a source for the information (The Garden Magazine) and a link to the published site(s). Other relevant links appear in a sidebar.
- After receiving the initial response, users can refine the search by asking further questions like, “which of these can I plant now?” SearchGPT will generate new results based on context.
- The system draws on information from publishers from which OpenAI licensed copyrighted materials including Associated Press, The Atlantic, Financial Times, and News Corp. OpenAI also has struck licensing deals with online forums including Reddit and Stack Overflow. Whether these partners are favored in search results is not clear.
- The service also draws on web pages indexed by its crawler. Web publishers can opt out of being crawled for indexing, gathering training data, or both.
Behind the news: OpenAI’s move is part of a larger race to supercharge web search with AI.
- Google and Microsoft added AI-generated results and summaries to their search engines last year, and Google expanded its AI Overview program earlier this year. Search GPT amps up OpenAI’s competition with Google, which uses its own Gemini models, but also with its partner Microsoft, whose AI-driven Bing Search and Copilot products rely on OpenAI.
- The startups You.com and Perplexity offer AI-driven search services. Publishers have criticized Perplexity for breaching paywalls, ignoring publishers’ efforts to opt out, and publishing AI-generated summaries of articles produced by other companies on its own websites.
Why it matters: Search stands to be disrupted by advances in AI, and agents that browse multiple articles to synthesize a result are becoming more capable. OpenAI’s approach looks like a step forward (and smart business insofar as it leads users into deeper relationship with its models), and its strategy of licensing content from trusted sources could prove to be an advantage.
We’re thinking: In less than two years, OpenAI has revolutionized expectations of one of the web’s bedrock applications, search. Its progress shows how AI can make applications smarter, more efficient, and more responsive.
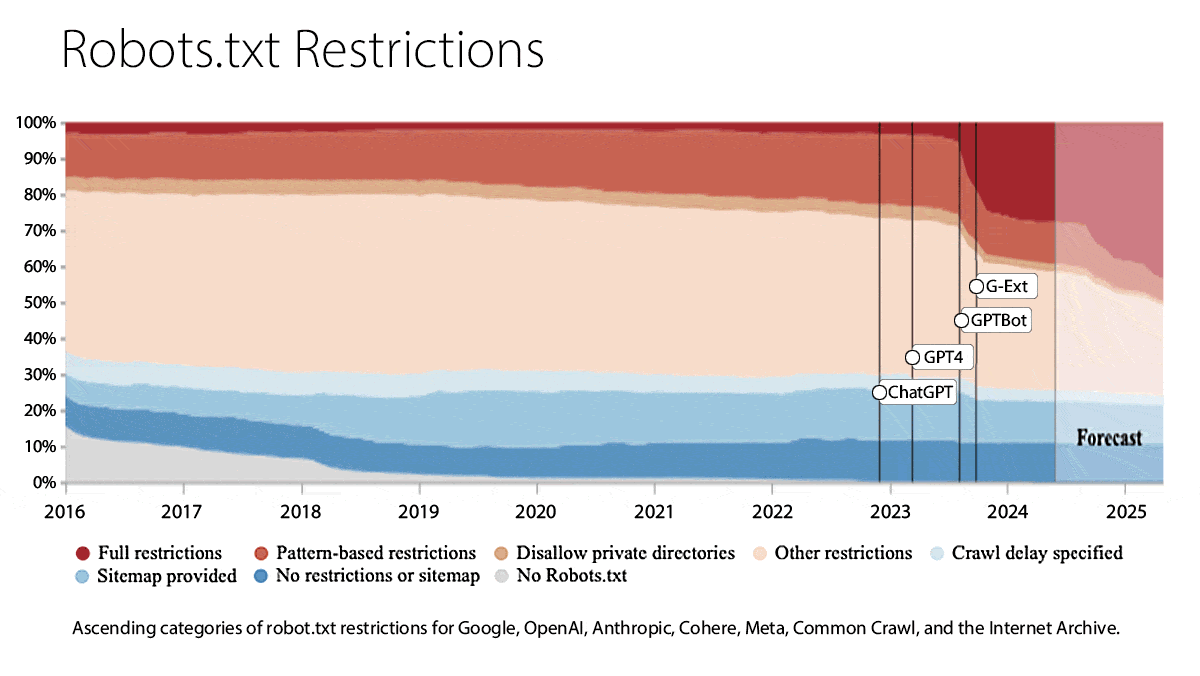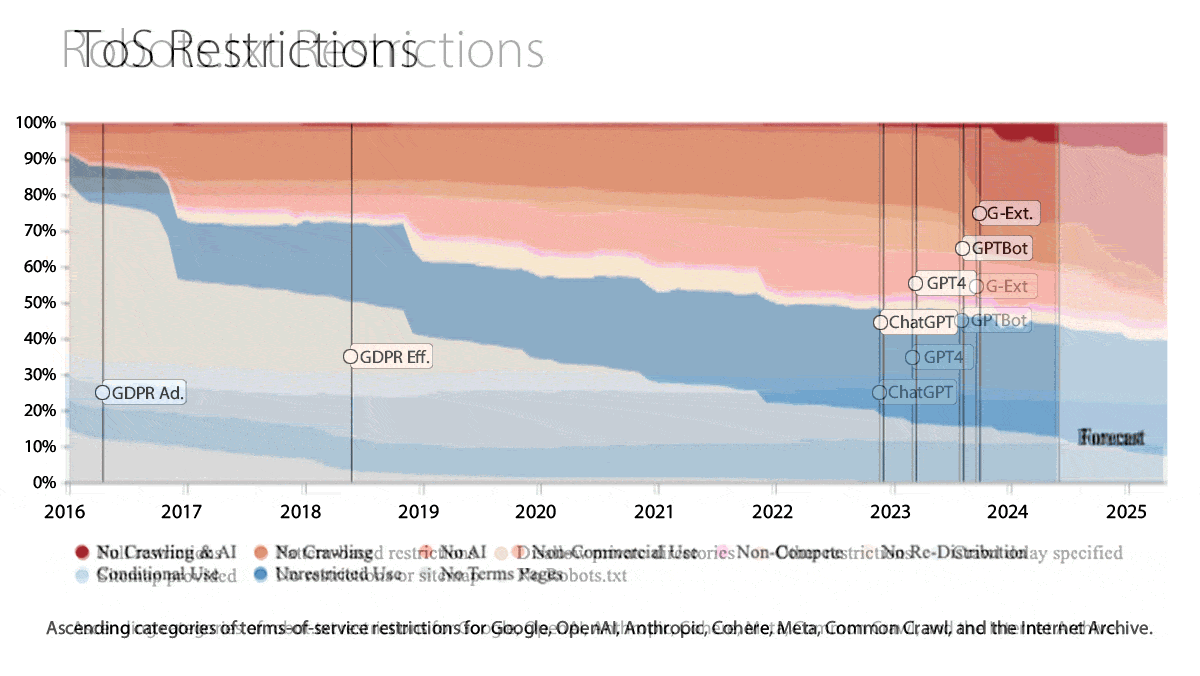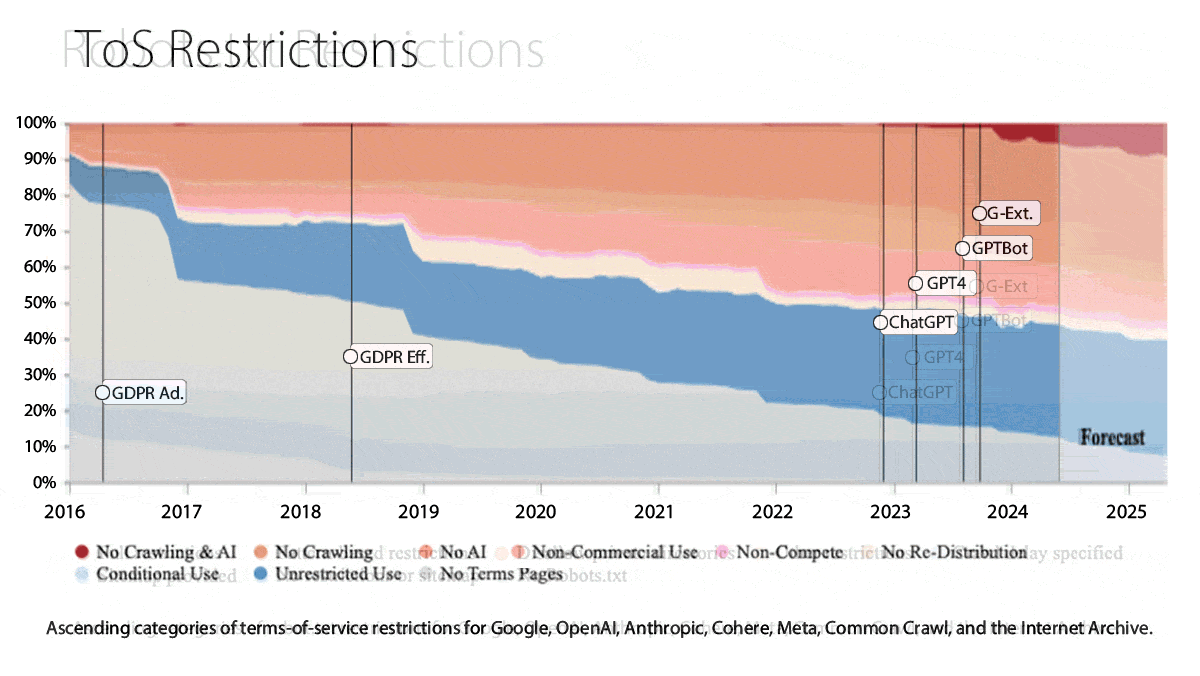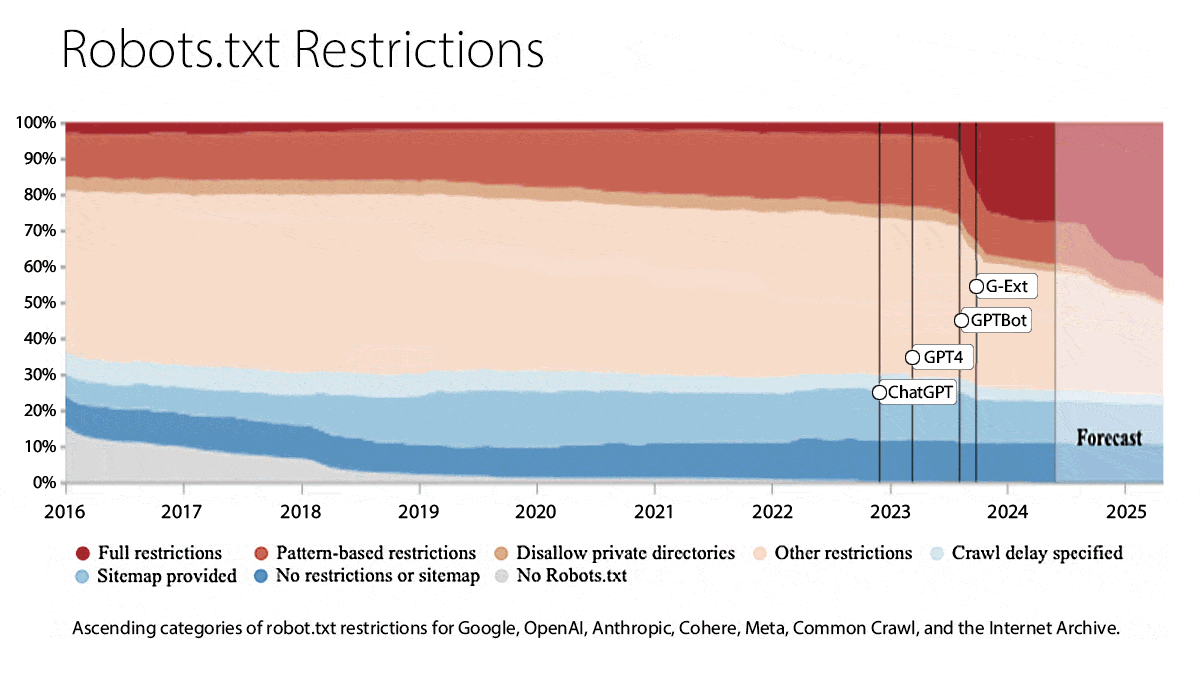
Web Data Increasingly Off Limits
Online publishers are moving to stop AI developers from training models on their content.
What’s new: Researchers at MIT analyzed websites whose contents appear in widely used training datasets. Between 2023 and 2024, many of these websites changed their terms of service to ban web crawlers, restricted the pages they permit web crawlers to access, or both.
How it works: MIT’s Data Provenance Initiative examined 14,000 websites whose contents are included in three large datasets, each of which contains data from between 16 and 45 million websites: C4 (1.4 trillion text tokens from Common Crawl), RefinedWeb (3 trillion to 6 trillion text tokens plus image links), and Dolma (3 trillion text tokens).
- The authors segmented each dataset into a head (2,000 websites that contributed the most tokens to each dataset) and a tail. Uniting the three heads yielded approximately 4,000 high-contribution sites (since content from some of these sites appears in more than one dataset). To represent the tail, they randomly sampled 10,000 other websites that appear in at least one dataset.
- They examined each website’s terms of service and robots.txt, a text file that tells web crawlers which pages they can access, for restrictions on using the website’s content. (Robots.txt is an honor system; no mechanism exists to enforce it.)
Results: In the past year, websites responsible for half of all tokens (text scraped and encoded for use as training data) in the study changed their terms of service to forbid either crawlers in general or use of their content to train AI systems. Robots.txt files showed the same shift.
- In April 2023, robots.txt files restricted less than 3 percent of tokens in the head and 1 percent of all tokens in the study. One year later, they restricted around 28 percent of tokens in the head and 5 percent of all tokens.
- Some types of websites are growing more restrictive than others. In April 2023, news websites in the head used robots.txt to restrict 3 percent of their tokens. In April 2024, that number rose to 45 percent.
- Websites are restricting some crawlers significantly more than others. Websites that represent more than 25 percent of tokens included in C4’s head restricted OpenAI’s crawler, but less than 5 percent of them restricted Cohere’s and Meta’s. By contrast, 1 percent restricted Google’s search crawler.
Behind the news: Data that once was freely available is becoming harder to obtain on multiple fronts. Software developers, authors, newspapers, and music labels have filed lawsuits that allege that AI developers trained systems on their data in violation of the law. OpenAI and others recently agreed to pay licensing fees to publishers for access to their material. Last year, Reddit and Stack Overflow started charging AI developers for use of their APIs.
Yes, but: The instructions in robots.txt files are not considered mandatory, and web crawlers can disregard them. Moreover, most websites have little ability to enforce their terms of use, which opens loopholes. For instance, if a site disallows one company’s crawler, the company may hire an intermediary to scrape the site.
Why it matters: AI systems rely on ample, high-quality training data to attain high performance. Restrictions on training data give developers less scope to build valuable models. In addition to affecting commercial AI developers, they may also limit research in academia and the nonprofit sector.
We’re thinking: We would prefer that AI developers be allowed to train on data that’s available on the open web. We hope that future court decisions and legislation will affirm this.
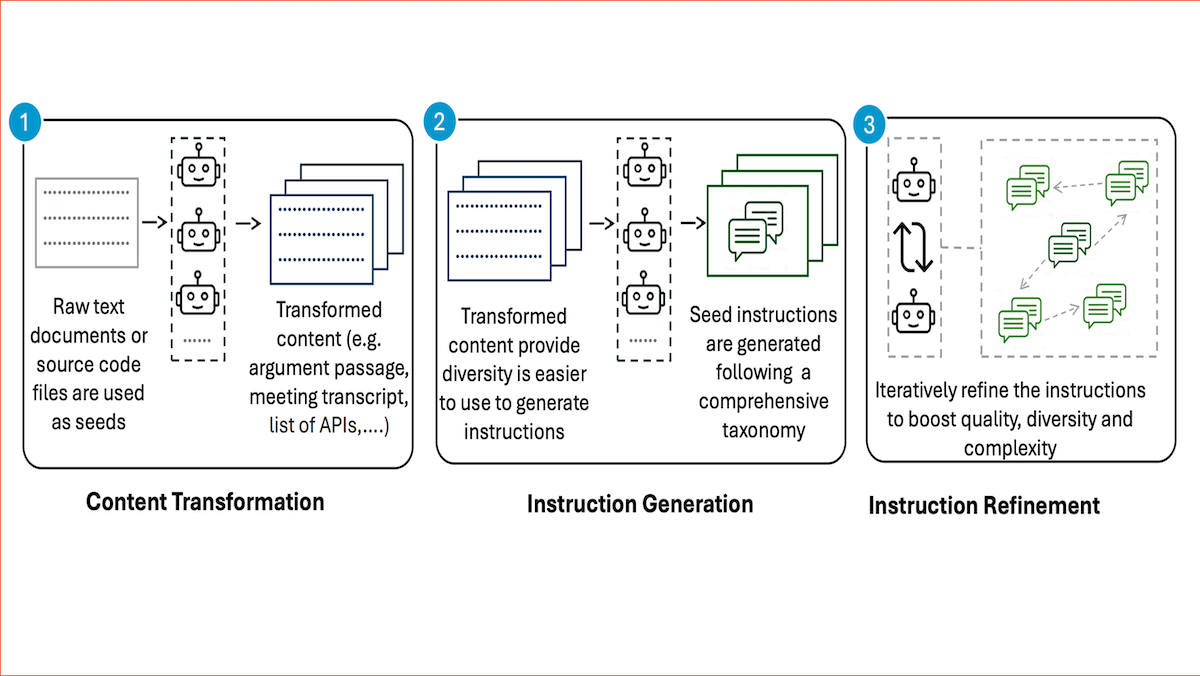
Synthetic Data Factory
Researchers increasingly fine-tune models on synthetic data, but generated datasets may not be sufficiently diverse. New work used agentic workflows to produce diverse synthetic datasets.
What’s new: Arindam Mitra, Luciano Del Corro, Guoqing Zheng, and colleagues at Microsoft introduced AgentInstruct, a framework for producing synthetic data for fine-tuning large language models (LLMs).
Key insight: To generate synthetic data for fine-tuning, researchers typically prompt an LLM to generate responses (and possibly further prompts) using a selection of existing prompts. While training on the resulting dataset can improve model performance, the synthetic data’s distribution may not match that of real-world data, yielding inconsistent performance. A more methodical approach can generate data closer to the real-world distribution: First generate prompts from each example in a large, diverse dataset, then generate responses.
How it works: The authors generated a synthetic text dataset based on three unlabeled datasets (including code) scraped from the web. They generated new examples for 17 tasks, including natural language tasks like reading comprehension and word puzzles as well as coding, tool use, and estimating measurements.
- Using an unspecified LLM, they generated prompts (text plus an instruction) using three agentic workflows they called content transformation (which created variations on the text that offer wider latitude for generating instructions), instruction generation, and instruction refinement (which made the instructions more complicated or unsolvable).
- For each task, they manually defined a team of agents to perform each workflow. For example, for the reading comprehension task, content transformation agents transformed raw text into a poem, satire, or other stylistic or formal variation. Instruction generation agents generated questions to ask about the transformed text based on an author-defined list of 43 types of questions. Instruction refinement agents received each (text, question) pair and produced more pairs by either (i) modifying the passage to make the question unanswerable, (ii) modifying the passage so the correct answer became the opposite of the original answer, or (iii) modifying the questions to be more complicated or unanswerable.
- The authors combined the resulting 22 million (text, instruction) prompts with prompts used to train Orca-1, Orca-2, and Orca-Math, for a total of 25.8 million prompts. Then they generated responses and fine-tuned Mistral-7B on the resulting dataset. They called the resulting model Orca-3.
Results: The authors compared Orca 3’s performance against that of competitors on 14 benchmarks. Orca 3 outperformed Mistral-7B (fine-tuned on prompts from previous versions of Orca) and Mistral-7B-Instruct (fine-tuned to respond to instructions) on 13 benchmarks. In some cases, it did so by large margins; for instance 40 percent on AGIEVAL, 54 percent on GSM8K, and 19 percent on MMLU. Orca 3 fell short of GPT-4 on 12 benchmarks.
Why it matters: The authors defined agentic workflows that turn text into diverse data for fine-tuning models. Their framework offers a pattern for AI engineers who want to build synthetic datasets for other tasks.
We’re thinking: We’re excited to see agentic workflows find applications that a wide variety of AI developers might put to use!
A MESSAGE FROM RAPIDFIRE AI

Tell us about your deep learning use cases and issues that need to be addressed and get a chance to win a $200 Amazon gift card! Take 10 minutes to fill out this quick survey now