
Dear friends,
I’m encouraged at the progress of the U.S. government at moving to stem harmful AI applications. Two examples are the new Federal Trade Commission (FTC) ban on fake product reviews and the DEFIANCE Act, which imposes punishments for creating and disseminating non-consensual deepfake porn. Both rules take a sensible approach to regulating AI insofar as they target harmful applications rather than general-purpose AI technology.
As I described previously, the best way to ensure AI safety is to regulate it at the application level rather than the technology level. This is important because the technology is general-purpose and its builders (such as a developer who releases an open-weights foundation model) cannot control how someone else might use it. If, however, someone applies AI in a nefarious way, we should stop that application.
Even before generative AI, fake reviews were a problem on many websites, and many tech companies dedicate considerable resources to combating them. A telltale sign of old-school fake reviews is the use of similar wording in different reviews. AI’s ability to automatically paraphrase or rewrite is making fake reviews harder to detect.
Importantly, the FTC is not going after the makers of foundation models for fake reviews. The provider of an open weights AI model, after all, can’t control what someone else uses it for. Even if one were to try to train a model to put up guardrails against writing reviews, I don’t know how it could distinguish between a real user of a product asking for help writing a legitimate review and a spammer who wanted a fake review. The FTC appropriately aims to ban the application of fake reviews along with other deceptive practices such as buying positive reviews.

The DEFIANCE Act, which passed unanimously in the Senate (and still requires passage in the House of Representatives before the President can sign it into law) imposes civil penalties for the creating and distributing non-consensual, deepfake porn. This disgusting application is harming many people including underage girls. While many image generation models do have guardrails against generating porn, these guardrails often can be circumvented via jailbreak prompts or fine-tuning (for models with open weights).
Again, DEFIANCE regulates an application, not the underlying technology. It aims to punish people who engage in the application of creating and distributing non-consensual intimate images, regardless of how they are generated — whether the perpetrator uses a diffusion model, a generative adversarial network, or Microsoft Paint to create an image pixel by pixel.
I hope DEFIANCE passes in the House and gets signed into law. Both rules guard against harmful AI applications without stifling AI technology itself (unlike California’s poorly designed SB-1047), and they offer a good model for how the U.S. and other nations can protect citizens against other potentially harmful applications.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Build flexible, maintainable applications with our new course, “Building AI Applications with Haystack.” Guided by Tuana Çelik, you’ll build projects like a RAG app and a self-reflecting agent using the Haystack framework. Join for free
News
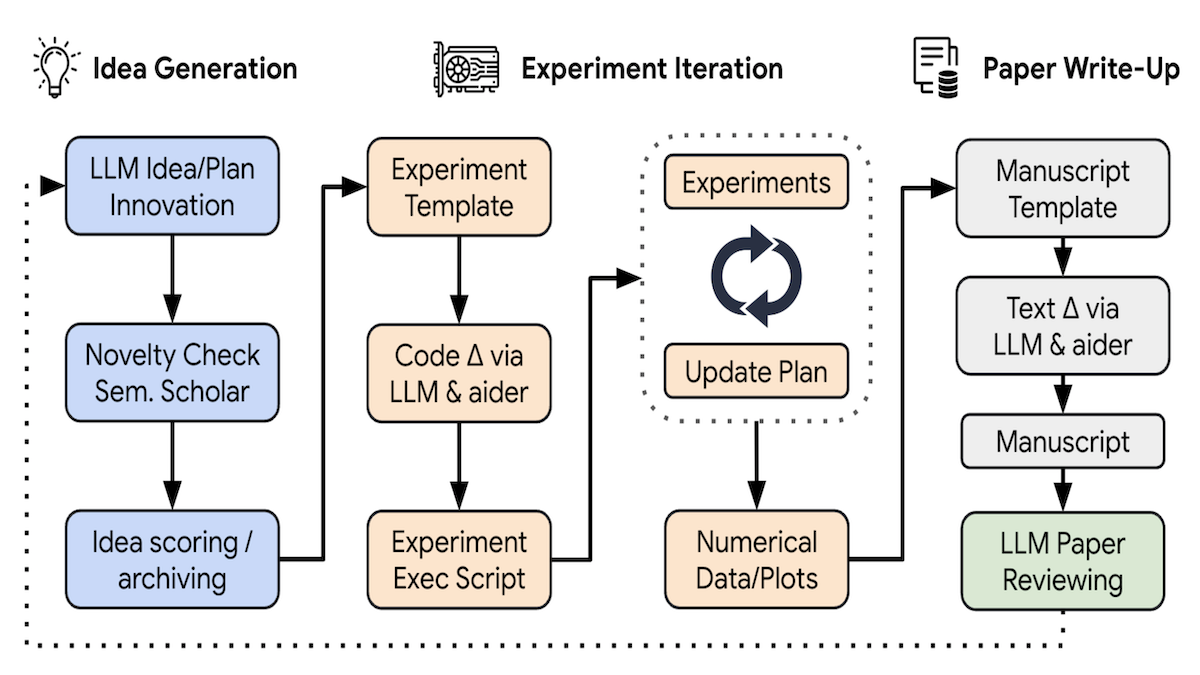
AI Agents for AI Research
While some observers argue that large language models can’t produce truly original output, new work prompted them to generate novel scientific research.
What’s new: Researchers proposed AI Scientist, an agentic workflow that directs large language models to generate ideas for AI research, produce code to test them, and document the enquiry. You can see examples of its output and download the code to generate your own papers here. The team included Chris Lu, Cong Lu, Robert Tjarko Lange, and colleagues at Tokyo-based startup Sakana AI, University of Oxford, University of British Columbia, Vector Institute, and the Canadian Institute for Advanced Research.
How it works: The authors used Claude Sonnet 3.5, GPT-4o, DeepSeek Coder, and LLama 3.1 405B to generate papers in three categories: diffusion image modeling, transformer-based language modeling, and “grokking,” which the authors define as generalization and speed of learning in deep neural networks.
- The authors prompted a given large language model (LLM) to generate “the next creative and impactful idea for research” in one of the three categories. Then they provided an API to search papers and asked the LLM to either determine whether its idea was novel (in which case it moved to the next step) or, if it couldn’t determine an answer, generate a search query to find related works. Then the authors asked again in light of the search results. They repeated this process until the LLM made a decision.
- Once they had a novel idea, they prompted the LLM to generate a list of experiments and run them using the Aider Python library. Then they prompted it to generate notes about the results and generate figures by altering an existing Python script.
- They prompted the LLM to generate a paper, one section at a time, given the notes, figures, sections generated so far, and tips on how to write a paper based on an existing guide. Then they prompted it to search for related works and add relevant citations. Finally, they asked it to remove redundancy, reduce verbosity, and finalize the document’s format.
Results: The team used GPT-4o to evaluate the generated papers according to the guidelines for papers presented at the Neural Information Processing Systems (NeurIPS) conference. The guidelines include an overall score between 1 (very strongly reject) and 10 (award-quality: flawless and groundbreaking) and a decision to reject or accept the paper.
- Of the four LLMs, Claude Sonnet 3.5 performed best. Its highest-scoring papers achieved 6 (weak accept). With respect to one of Claude’s works, the authors wrote, “The AI Scientist correctly identifies an interesting and well-motivated direction in diffusion modeling research . . . It proposes a comprehensive experimental plan to investigate its idea, and successfully implements it all, achieving good results." The authors provide an archive of Claude’s output here.
- GPT-4o ranked second. Its highest-scoring paper achieved 5 (borderline accept).
- The generated papers achieved an average score of 4.05 or less (4 is borderline reject) across all models and categories of experiment. The experiments generally involved small networks that were trained and tested on generated data. The authors note that the system often failed to implement its ideas, sometimes fabricated results, and sometimes failed to cite the most relevant papers, among other issues.
Why it matters: Agentic workflows are a rising theme in AI research from simpler design patterns like reflection to complex workflows for translating literature. These workflows make it possible to break down complex problems into more manageable subtasks. By breaking the task of conducting AI research into various stages of generating ideas, testing them, and writing a paper, an LLM that has access to the right tools can generate novel research papers with actual experimental results.
We’re thinking: Rather than merely synthesizing existing knowledge, this work points a fascinating direction for using AI to generate new knowledge! Right now, an LLM can suggest starting points for human researchers along with experiments that back up its suggestions.

Google Imagen 3 Raises the Bar
Image generation continued its rapid march forward with a new version of Google’s flagship text-to-image model.
What’s new: Google introduced Imagen 3, a proprietary model that improves upon the previous version’s image quality and prompt adherence, with features like inpainting and outpainting to be added in the future. Imagen 3 is available via Google’s ImageFX web user interface and Vertex AI Platform. It follows closely upon the releases of Black Forest Labs’ Flux.1 family (open to varying degrees), Midjourney v6.1, and Stability AI Stable Diffusion XL 1 (open weights) — all in the last month.
How it works: The accompanying paper does not describe the model’s architecture and training procedures in detail. The authors trained a diffusion model on an unspecified “large” dataset of images, text, and associated annotations that was filtered to remove unsafe, violent, low-quality, generated, and duplicate images as well as personally identifying information. Google’s Gemini large language model generated some image captions used in training to make their language more diverse.
Results: Imagen 3 mostly outperformed competing models in head-to-head comparisons based on prompts from datasets including GenAI-Bench, DrawBench, and DALL-E 3 Eval. The team compared Imagen 3 to Midjourney v6.0, OpenAI DALL-E 3, Stable Diffusion 3 Large, and Stable Diffusion XL 1.0. More than 3,000 evaluators from 71 countries rated the models’ responses in side-by-side comparisons. The raters evaluated image quality, preference regardless of the prompt, adherence to the prompt, adherence to a highly detailed prompt, and ability to generate the correct numbers of objects specified in a prompt. Their ratings (between 1 and 5) were used to compute Elo ratings.
- Imagen 3 swept the overall preference tests. On GenAI-Bench and DrawBench, Imagen 3 (1,099 Elo and 1,068 Elo respectively) beat the next-best Stable Diffusion 3 (1,047 Elo and 1,053 Elo respectively). On DALL-E 3 Eval, Imagen 3 (1,079 Elo) beat the next-best MidJourney v6.0 (1,068 Elo).
- Likewise, Imagen 3 swept the prompt-image alignment benchmarks. On GenAI-Bench and DrawBench, Imagen 3 (1,083 Elo and 1,064 Elo respectively) outperformed the next-best Stable Diffusion 3 (1,047 Elo for both datasets). On DALL-E 3 Eval, Imagen 3 (1,078) narrowly edged out DALL-E 3 (1,077 Elo) and Stable Diffusion 3 (1,069 Elo).
- Imagen 3 showed exceptional strength in following detailed prompts in the DOCCI dataset (photographs with detailed descriptions that averaged 136 words). In that category, Imagen 3 (1,193 Elo) outperformed next-best Midjourney v6.0 (1,079 Elo).
- Although none of the models tested did very well at generating specified numbers of objects from the GeckoNum dataset, Imagen 3 (58.6 Elo) outperformed the next-best DALL-E 3 (46.0 Elo).
- Imagen 3 lost to Midjourney v6.0 across the board in tests of visual appeal regardless of the prompt. It was slightly behind on GenAI-Bench (1,095 Elo versus 1,101 Elo), farther behind on DrawBench (1,063 Elo versus 1,075 Elo), and well behind on DALL-E 3 Eval (1,047 Elo versus 1,095 Elo).
Why it matters: Each wave of advances makes image generators more useful for a wider variety of purposes. Google’s emphasis on filtering the training data for safety may limit Imagen 3’s utility in some situations (indeed, some users complained that Imagen 3 is more restrictive than Imagen 2, while the Grok2 large language model’s use of an unguardrailed version of Flux.1 for image generation has garnered headlines). Nonetheless, precautions are an important ingredient in the evolving text-to-image recipe.
We’re thinking: It’s difficult to compare the benchmarks reported for Imagen 3 and the recently released Flux.1, which claims similar improvements over earlier models. In any case, Google has yet to publish a benchmark for generating text, a valuable capability for commercial applications. The Flux.1 models, two of which are open to some degree, may prove to be formidable rivals in this area.
Open Models for Math and Audio
Alibaba followed up its open-weights Qwen2 large language models with specialized variations.
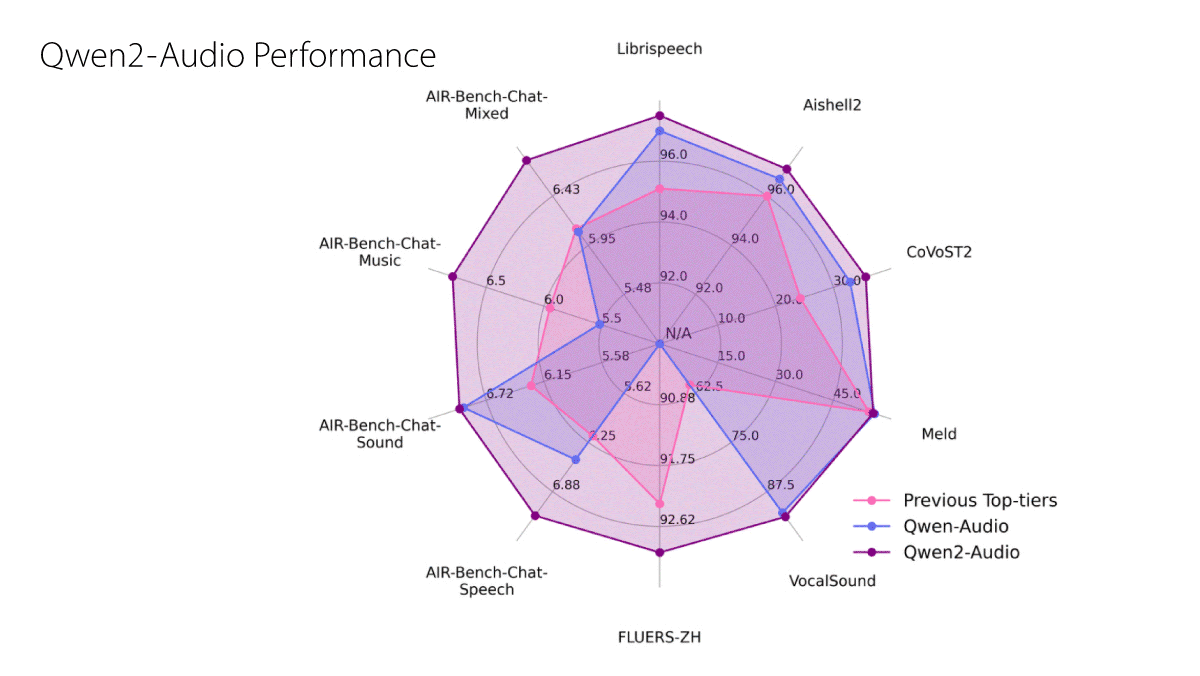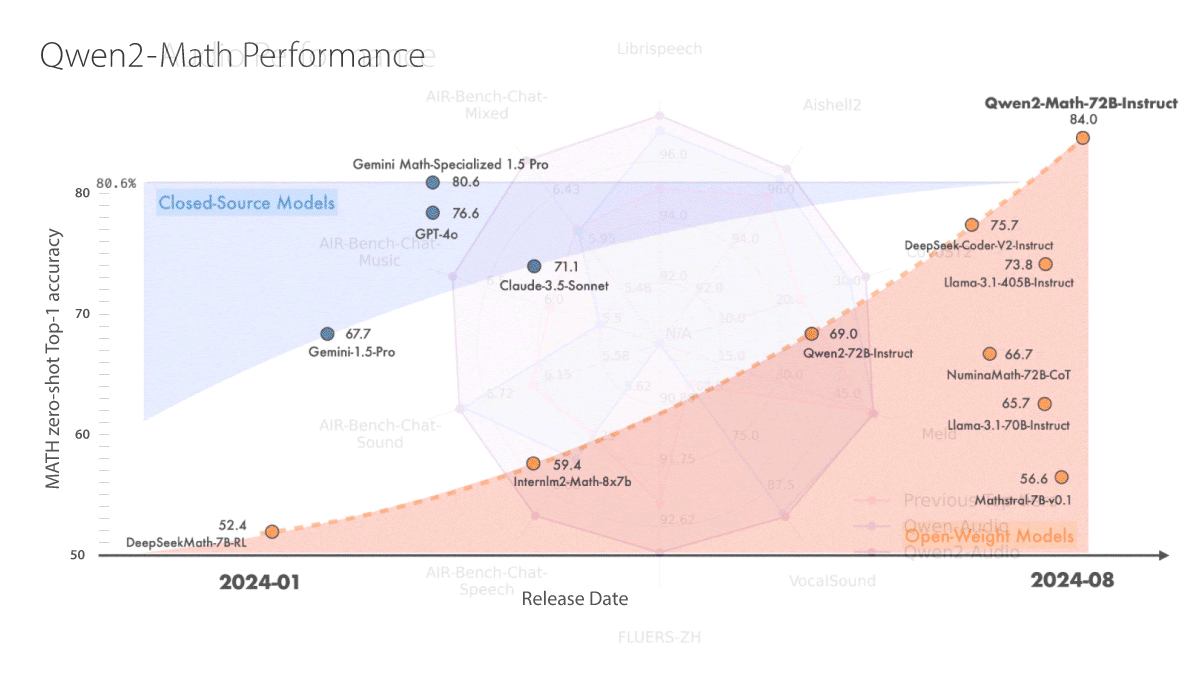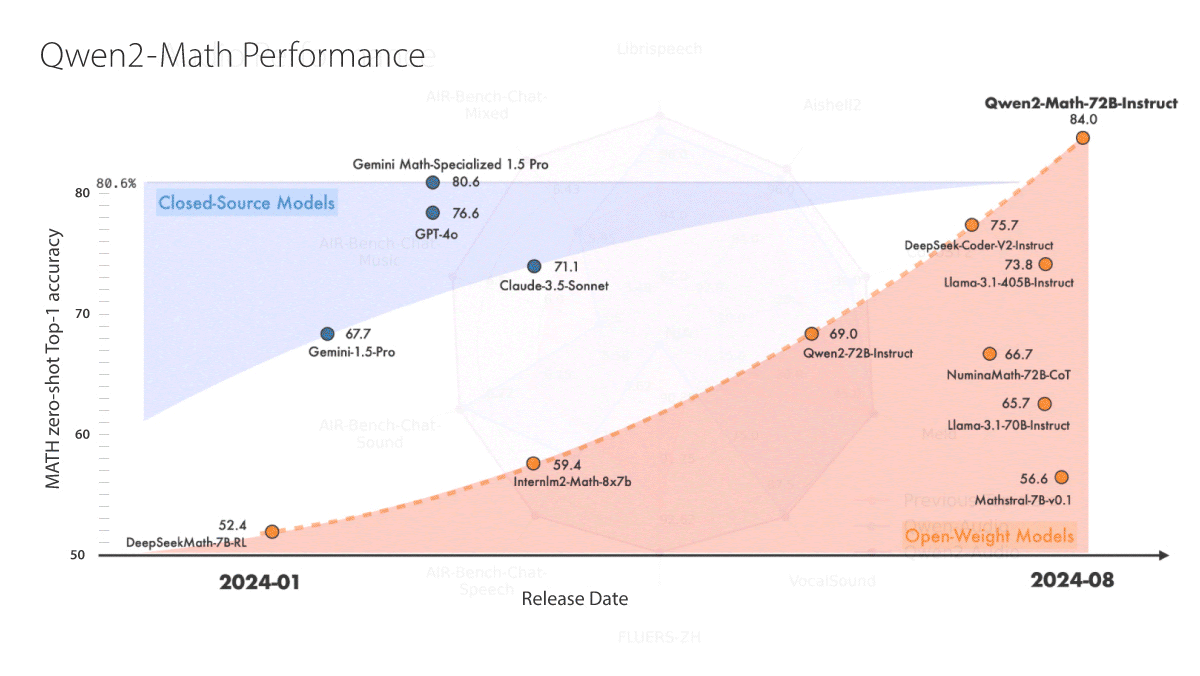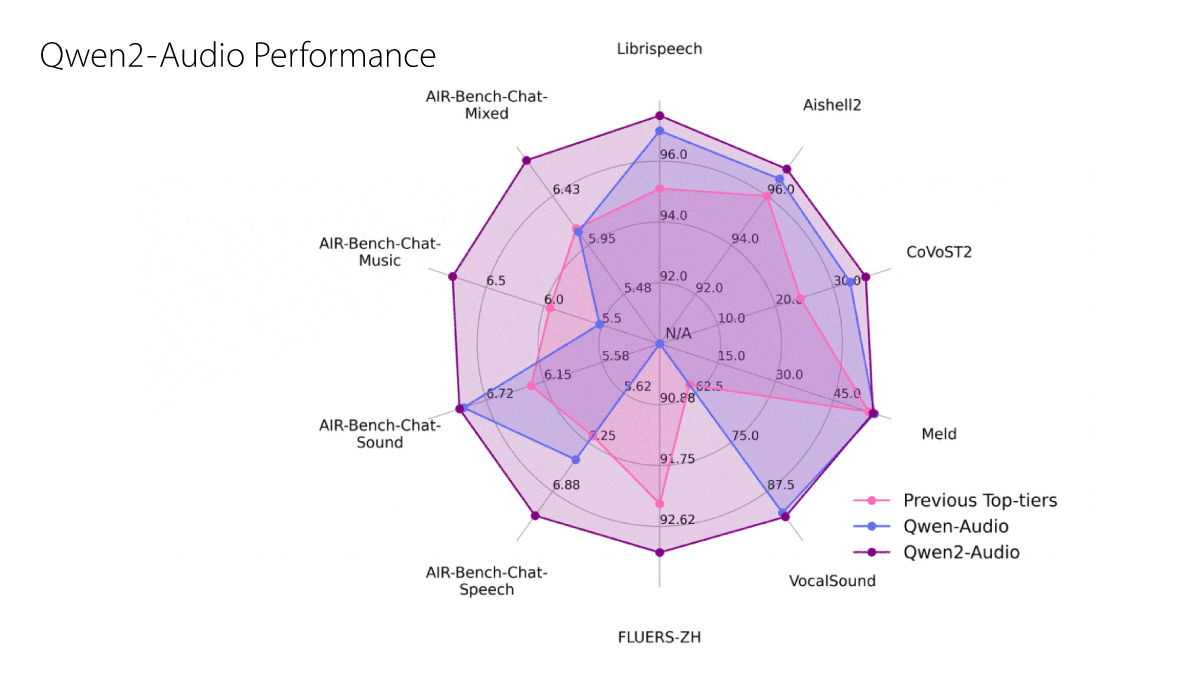
What’s new: Qwen2-Math and Qwen2-Audio are model families devoted to, respectively, solving math problems and generating text directly from audio. Both set new states of the art in a variety of English and Chinese benchmarks, and some versions offer open weights. Notably Qwen2-Math-Instruct-72B, whose 72 billion parameters are fine-tuned according to human preferences, outperformed top models including Claude 3.5 Sonnet, Gemini 1.5-Pro, GPT-4o, and Llama-3.1-405B on some math benchmarks.
Math mavens: Qwen2-Math models include pretrained and instruction-tuned variations that comprise 1.5 billion, 7 billion, and 72 billion parameters. The license for the largest version is free for noncommerical development and commercial developers who have less than 100 million monthly active users.
- How it works: Qwen2-Math base models were initialized to Qwen2 weights and further pretrained on a corpus of math articles, books, exams, and data generated by Qwen2. The instruction-tuned versions were fine-tuned on more model-generated data using supervised learning followed by a reinforcement learning algorithm called group relative policy optimization. The team removed examples that significantly overlapped benchmark test sets and prominent math competitions.
- Results: Using few-shot, chain-of-thought prompting, Qwen2-Math-Instruct-72B achieved state-of-the-art performance in English math benchmarks including MATH and Chinese math benchmarks including CMATH, GaoKao Math Cloze, and GaoKao Math QA. (The 72 billion-parameter Qwen2-Math achieved state-of-the-art scores in GSM8k and MMLU STEM.) Qwen2-Math-Instruct-72B also outperformed Claude 3 Opus, GPT-4 Turbo, Gemini 1.5 Pro and Gemini Math-Specialized 1.5 Pro in the AIME 2024 math competition in some settings. The smaller, instruction-tuned versions outperformed other models of the same size by some measures.
Audio/text to text: A revision of the earlier Qwen-Audio, Qwen2-Audio takes text and audio inputs and generates text outputs. It’s designed to (i) provide text chat in response to voice input including voice transcription and translation between eight languages and (ii) discuss audio input including voice, music, and natural sounds. Weights (8.2 billion parameters) are available for base and instruction-tuned versions. You can try it here.
- How it works: Given a text prompt and audio, a Whisperlarge-v3 audio encoder embeds the audio, and a pretrained Qwen-7B language model uses the text prompt and audio embedding to generate text. The team further pretrained the system to predict the next text token based on a text-audio dataset that included 370,000 hours of recorded speech, 140,000 hours of music, and 10,000 hours of other sounds. They fine-tuned the system for chat in a supervised fashion and for factuality and prompt adherence using DPO. You can read the technical report here.
- Results: Qwen2-Audio outperformed previous state-of-the-art models in benchmarks that evaluate speech recognition (Librispeech, AISHELL-2, FLEURS-ZH), speech-to-text translation (CoVoST2), and audio classification (Vocalsound) as well as AIR-Bench tests for evaluating interpretation of speech, music, sound, and mixed-audio soundscapes.
Why it matters: Qwen2 delivered extraordinary performance with open weights, putting Alibaba on the map of large language models (LLMs). These specialized additions to the family push forward math performance and audio integration in AI while delivering state-of-the-art models into the hands of more developers.
We’re thinking: It’s thrilling to see models with open weights that outperform proprietary models. The white-hot competition between open and closed technology is good for everyone!
Scaling Laws for Data Quality
When training vision-language models, developers often remove lower-quality examples from the training set. But keeping only the highest-quality examples may not be ideal, researchers found.
What's new: Sachin Goyal, Pratyush Maini, and colleagues at Carnegie Mellon University derived scaling laws for filtering data that describe how the utility of examples — in terms of how much they increase performance (or decrease loss) — falls when they are used over and over again in training.
Key insight: When computational resources are limited relative to the amount of data available, some AI developers try to select the highest-quality examples and train on them for multiple iterations. However, the utility of examples declines a little bit every time they’re used. As computational resources rise, it’s better to introduce new examples even if they’re of slightly lower quality.
How it works: The authors used 128 million text-image pairs from DataComp to train various CLIP models, varying the data quality and number of times a model saw each example during training.
- The authors divided the dataset into subsets, each containing 10 percent of the examples, of graduated quality. They evaluated quality according to Text Masking and Re-Scoring (T-MARS) scores from a pretrained CLIP, measuring the similarity between CLIP embeddings of an image and corresponding text.
- They trained a model on each subset, repeating it up to 10 times. Each time the model was trained on a particular subset, they evaluated the model’s error rate on ImageNet classification and fit a scaling curve to the error rates.
- They calculated scaling curves for combinations of subsets (for example, the highest-quality 30 percent of examples) by taking a weighted average of the scaling curves of the individual subsets.
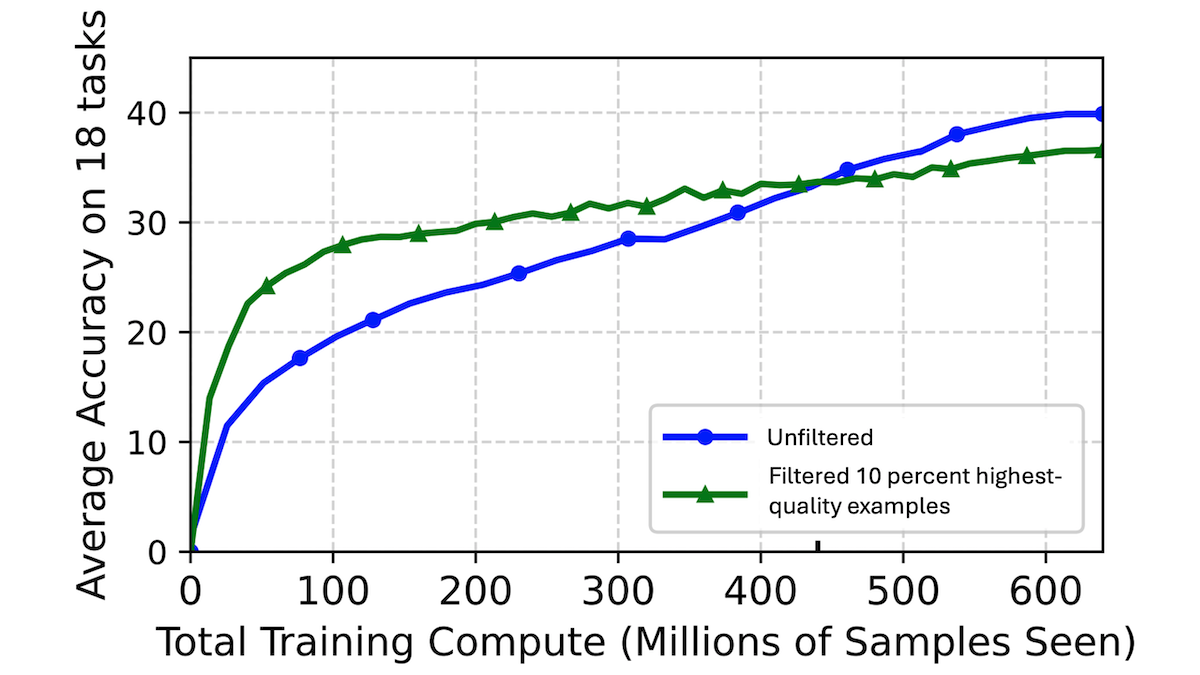
- To verify the scaling curves, the authors trained nine instances of CLIP using the highest-quality 10 percent, 30 percent, or 40 percent examples while presenting 32 million, 128 million, or 640 million examples (including repeats).
Results: The authors rated each model’s performance according to the average across 18 visual tasks, mostly involving classification accuracy (including ImageNet). The more examples a model saw, the more its performance benefited from training on lower-quality examples in addition to the highest-quality examples. Of the models that saw 32 million examples, the one trained on the highest-quality 10 percent of examples did best. Of the models that saw 128 million examples, the one trained on the highest-quality 30 percent of examples did the best. Of the models that saw 640 million examples, the one trained on the highest-quality 40 percent of examples did the best. These results confirmed theoretical predictions based on the scaling curves.
Why it matters: The practice of pretraining vision-language models on a certain percentage of only the highest-quality examples is not ideal. A better approach is to perform experiments to determine the best percentage given the available compute budget: Train first on a small amount of data and filter for quality according to the scaling curves.
We're thinking: This work affirms the fundamental principle of Data-centric AI: Systematically engineering training data is essential for getting optimal performance from a given architecture. However, it shows that using only the highest-quality data works best with smaller compute budgets. With more compute, lower-quality data can improve performance more than repeating the highest-quality examples too many times.