
Dear friends,
After a recent price reduction by OpenAI, GPT-4o tokens now cost $4 per million tokens (using a blended rate that assumes 80% input and 20% output tokens). GPT-4 cost $36 per million tokens at its initial release in March 2023. This price reduction over 17 months corresponds to about a 79% drop in price per year: 4/36 = (1 - p)17/12. (OpenAI charges a lower price, just $2 per million tokens, for using a new Batch API that takes up to 24 hours to respond to a batch of prompts. That’s an 87% drop in price per year.)
As you can see, token prices are falling rapidly! One force that’s driving prices down is the release of open weights models such as Llama 3.1. If API providers, including startups Anyscale, Fireworks, Together.ai, and some large cloud companies, do not have to worry about recouping the cost of developing a model, they can compete directly on price and a few other factors such as speed.
Further, hardware innovations by companies such as Groq (a leading player in fast token generation), Samba Nova (which serves Llama 3.1 405B tokens at an impressive 114 tokens per second), and wafer-scale computation startup Cerebras (which just announced a new offering), as well as the semiconductor giants NVIDIA, AMD, Intel, and Qualcomm, will drive further price cuts.
When building applications, I find it useful to design to where the technology is going rather than only where it has been. Based on the technology roadmaps of multiple software and hardware companies — which include improved semiconductors, smaller models, and algorithmic innovation in inference architectures — I’m confident that token prices will continue to fall rapidly.
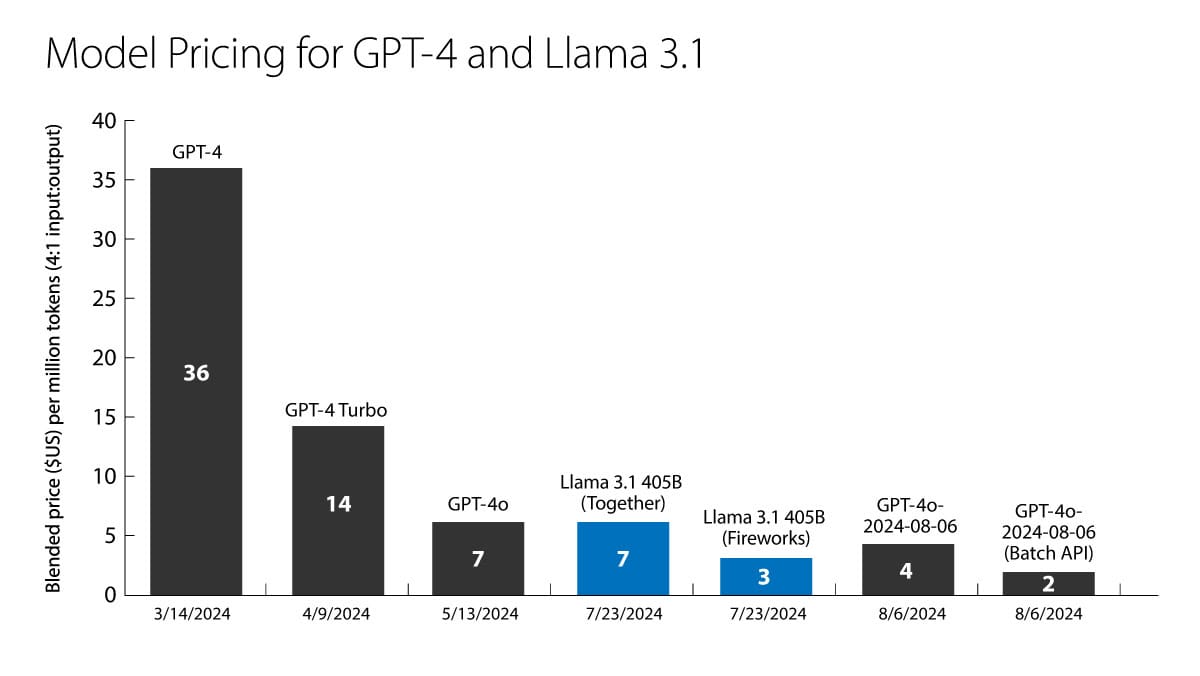
This means that even if you build an agentic workload that isn’t entirely economical, falling token prices might make it economical at some point. As I wrote previously, being able to process many tokens is particularly important for agentic workloads, which must call a model many times before generating a result. Further, even agentic workloads are already quite affordable for many applications. Let's say you build an application to assist a human worker, and it uses 100 tokens per second continuously: At $4/million tokens, you'd be spending only $1.44/hour – which is significantly lower than the minimum wage in the U.S. and many other countries.
So how can AI companies prepare?
- First, I continue to hear from teams that are surprised to find out how cheap LLM usage is when they actually work through cost calculations. For many applications, it isn’t worth too much effort to optimize the cost. So first and foremost, I advise teams to focus on building a useful application rather than on optimizing LLM costs.
- Second, even if an application is marginally too expensive to run today, it may be worth deploying in anticipation of lower prices.
- Finally, as new models get released, it might be worthwhile to periodically examine an application to decide whether to switch to a new model either from the same provider (such as switching from GPT-4 to the latest GPT-4o-2024-08-06) or a different provider, to take advantage of falling prices and/or increased capabilities.
Because multiple providers now host Llama 3.1 and other open-weight models, if you use one of these models, it might be possible to switch between providers without too much testing (though implementation details — specifically quantization, does mean that different offerings of the model do differ in performance). When switching between models, unfortunately, a major barrier is still the difficulty of implementing evals, so carrying out regression testing to make sure your application will still perform after you swap in a new model can be challenging. However, as the science of carrying out evals improves, I’m optimistic that this will become easier.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

In our short course “Large Multimodal Model Prompting with Gemini,” you’ll learn how to build systems that reason across text, images, and video and how prompting multimodal models differs from text-only LLMs. You’ll also optimize LMM systems and output. Enroll today!
News
A Lost Voice Regained
A man who lost the ability to speak four years ago is sounding like his earlier self, thanks to a collection of brain implants and machine learning models.
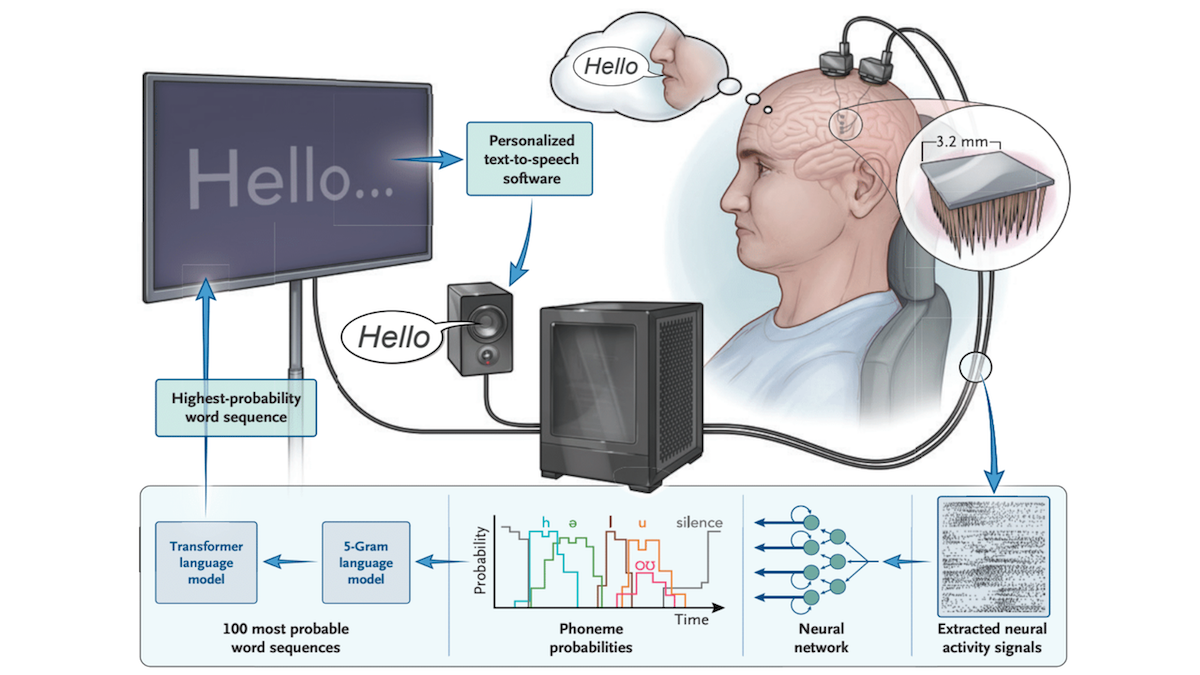
What’s new: Researchers built a system that decodes speech signals from the brain of a man who lost the ability to speak clearly due to amyotrophic lateral sclerosis, also known as ALS, and enables him to speak through a synthetic version of his former voice. At the start of the study, his efforts to speak were intelligible only to his personal caregiver. Now he converses regularly with family and friends, The New York Times reported. Nicholas Card built the system with colleagues University of California-Davis, Stanford University, Washington University, Brown University, VA Providence Healthcare, and Harvard Medical School.
How it works: The authors surgically implanted four electrode arrays into areas of the brain that are responsible for speech. The system learned to decode the patient’s brain signals, decide the most likely phonemes he intended to speak, determine the words those phonemes express, and display and speak the words aloud using a personalized speech synthesizer.
- After the patient recovered from the implantation surgery, the authors collected data for training and evaluating the system. They recorded his brain signals while he tried to speak during 84 sessions, each between 5 and 30 minutes, over 32 weeks. The sessions were split into two tasks: copying, in which the patient spoke sentences shown on a screen, and conversation, in which he spoke about whatever he wanted. Initial sessions focused on copying. Later, when the authors had accrued paired brain signals and known sentences, they focused on conversation.
- A gated recurrent unit (GRU) learned to translate brain signals into a sequence of phonemes. The authors trained the model after each session on all recordings made during that session. To adapt it to day-to-day changes in brain activity, they also fine-tuned it during later sessions: After they recorded a new sentence, they fine-tuned the GRU on a 60/40 mix of sentences from the current session and previous sessions.
- A weighted finite-state transducer (WFST), based on a pretrained 5-gram language model and described in the supplementary information here), translated sequences of phonemes into sentences. Given a sequence, it generated the 100 most likely sentences.
- Given the likely sentences, the authors ranked them according to the probability that the GRU, WFST, and OPT, a pretrained large language model, would generate them.
- A pretrained StyleTTS 2 text-to-speech model turned the highest-ranking sentence into speech. The authors fine-tuned the model on recordings of the patient’s voice from before the onset of his illness, such as podcasts.
Results: After two hours of recording the patient’s brain signals and training on that data, the system achieved 90.2 percent accuracy in the copying task. By the final session, the system achieved 97.5 percent accuracy and enabled the patient to speak on average 31.6 words per minute using a vocabulary of 125,000 words.
Behind the news: Previous work either had much lower accuracy or generated a limited vocabulary. The new work improved upon a 2023 study that enabled ALS patients to speak with 76.2 percent accuracy using a vocabulary of equal size.
Why it matters: Relative to the 2023 study on which this one was based, the authors changed the positions of the electrodes in the brain and continued to update the GRU throughout the recording/training sessions. It’s unclear which changes contributed most to the improved outcome. As language models improve, new models potentially could act as drop-in replacements for the models in the authors’ system, further improving accuracy. Likewise, improvements in speech-to-text systems could increase the similarity between the synthetic voice and the patient’s former voice.
We’re thinking: Enabling someone to speak again restores agency. Enabling someone to speak again in their own voice restores identity.
Agentic Coding Strides Forward
An agentic coding assistant boosted the state of the art in an important benchmark by more than 30 percent.
What’s new: Cosine, a startup based in London, unveiled Genie, a coding assistant that achieves top performance on SWE-bench, which tests a model’s ability to solve GitHub issues. The company has yet to announce pricing and availability, but a waitlist is available.
How it works: Genie is a fine-tuned version of GPT-4o with a larger context window of undisclosed size. It works similarly to agentic coding tools like Devin, Q, OpenDevin, and SWE-agent. Its agentic workflow loops through four processes: retrieving information, planning, writing code, and running it. It was trained on a proprietary training set that captures software engineers’ processes for reasoning, gathering information, and making decisions. It edits lines of code in place rather than rewriting entire sections or files from scratch.
- Cosine initially fine-tuned Genie roughly equally on six software engineering tasks: developing features, fixing bugs, refactoring, making minor changes, writing tests, and writing documentation. The fine-tuning set included 15 programming languages, mostly JavaScript and Python (21 percent each) followed by TypeScript and TSX (14 percent each).
- Subsequent fine-tuning focused on finishing incomplete code and fixing imperfect code, which was underrepresented in the initial dataset. This round of training used incorrect examples generated by Genie itself. By comparing Genie’s initial incorrect output with correct examples, the model improved its ability to recognize and fix mistakes.
- At inference — given a prompt in natural language, a ticket that outlines a programming task, or a GitHub issue — the model retrieves relevant files and documentation, makes a plan for fixing the issue, and writes new code. After writing new code, it runs verification tests. If the tests fail, it loops between planning and coding until the tests succeed.
- Genie can also create and monitor pull requests on GitHub. It responds to human comments on its own pull requests just like it acts upon GitHub issues.
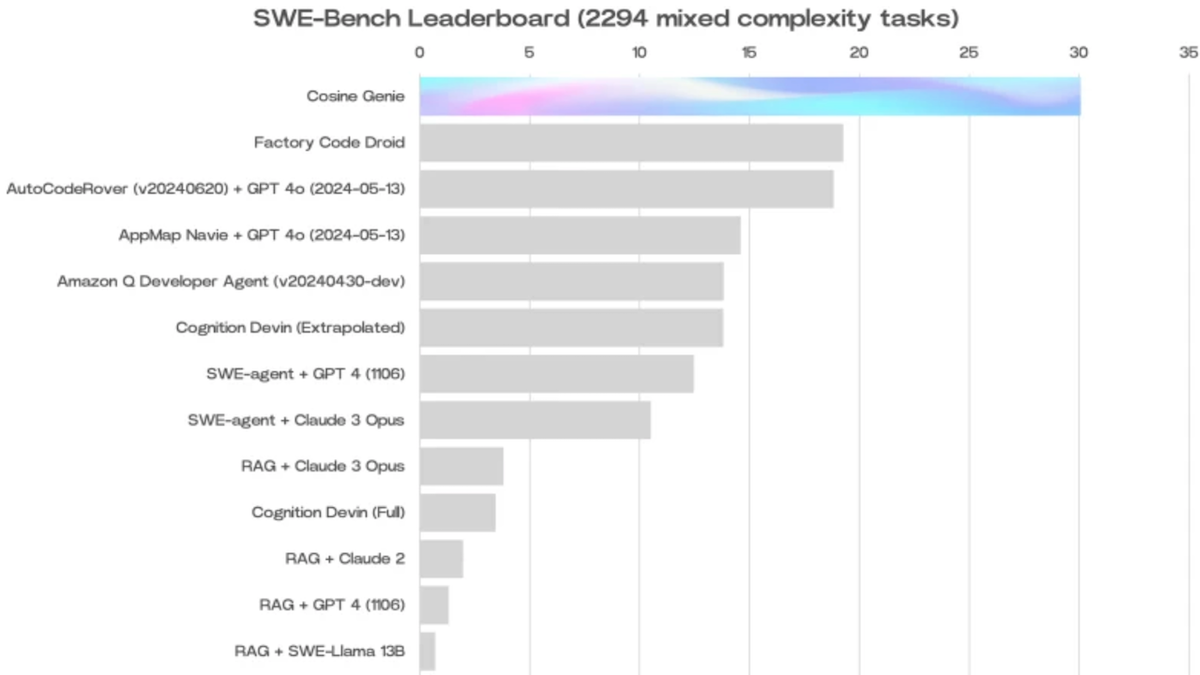
Results: Tested on SWE-bench Full (2,294 issue-commit pairs across 12 Python repositories), Genie solved 30.1 percent of problems, far ahead of the next closest competitor, Amazon Q, at 19.75 percent. Genie achieved 50.7 percent of the SWE-bench Lite (winnowed to 300 issue-commit pairs to save computation), beating CodeStory Aide plus other models at 43 percent. (Genie’s results don’t appear on the official SWE-bench leaderboard. The leaderboard requires that models document their workings, which Cosine declined to avoid revealing proprietary information. Cosine released Genie’s solution sets to verify its performance.)
Behind the news: SWE-bench’s creators recently collaborated with OpenAI to produce a new version, SWE-bench Verified. They eliminated extremely difficult and poorly configured problems, leaving 500 human-verified issue-commit pairs. Cosine has yet to publish Genie’s performance on SWE-bench Verified. As of this writing, Amazon Q ranks in first place with 38.8 percent.
Why it matters: Some developers of AI coding assistants train models to follow human-style procedures while others are building AI-native methods. Genie takes a distinct step forward by mimicking software engineers. Competition between the two approaches, along with longer context windows, faster inference, and increasingly sophisticated agentic workflows, is driving improvement of coding assistants at a rapid pace.
We’re thinking: We’re glad this Genie escaped the bottle!
AI Lobby Expands
AI is a red-hot topic for lobbyists who aim to influence government policies in the United States.
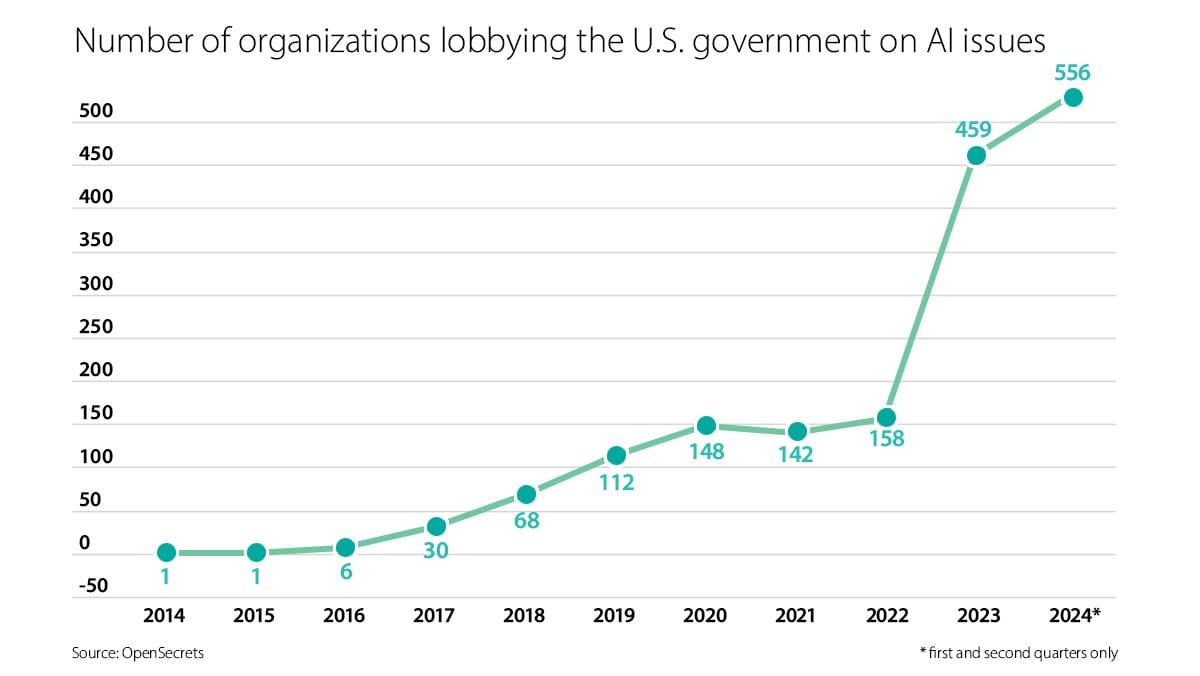
What’s new: The number of organizations lobbying to influence U.S. laws and regulations that affect AI jumped more than 20 percent in the first half of 2024, TechCrunch reported. Data collected by OpenSecrets, which tracks political contributions, shows increased lobbying by startups including OpenAI and Anthropic.
How it works: OpenSecrets searched for the words “AI” and “artificial intelligence” in lobbying disclosure forms. Organizations must file such forms quarterly if they discuss specific laws and regulations with decision makers or their staffs.
- More than 550 organizations lobbied the federal government about AI policy in the first half of 2024, up from 460 in 2023. These included tech giants and startups; venture capital firms; think tanks; companies and trade groups in various industries including insurance, health care, and education; and universities.
- OpenAI spent $800,000 on lobbying in the first half of the year, compared to $260,000 the previous year. OpenAI’s team of contract lobbyists grew to 15, including former U.S. Senator Norm Coleman. That’s up from three in 2023, when it hired its first internal lobbyist. In addition, the company’s global affairs department expanded to 35 people; it’s expected to balloon to 50 by the end of the year. OpenAI publicly supports legislation currently under consideration by the U.S. Senate that would appoint a National AI Research Resource program manager and authorize an AI Safety Institute to set national standards and create public datasets.
- Anthropic expanded its team of external lobbyists from three to five this year and hired an in-house lobbyist. It expects to spend $500,000 on lobbying as the election season heats up.
- Cohere budgeted $120,000 for lobbying this year after spending $70,000 last year.
- Amazon, Alphabet, Meta, and Microsoft each spent more than $10 million on lobbying in 2023, Time reported.
Yes, but: The lobbying disclosure forms show who is spending money to influence policy, but they provide only a limited view. For instance, they reveal only that an organization aimed to influence AI policy, not the directions in which they aimed to influence it. Similarly, the disclosures shed no light on other efforts to influence laws and regulations such as advertising or campaign contributions. They also don’t reveal how much an organization discussed AI relative to other topics and concerns. For instance, last year the American Medical Association spent $21.2 million on lobbying including AI but, given the wide range of policy issues involved in medicine, AI likely accounted for a small amount of the total.
Behind the news: The ramp-up in AI lobbying comes as the U.S. Congress is considering a growing number of laws that would regulate the technology. Since 2023, more than 115 bills have been proposed that seek to restrict AI systems, require developers to disclose or evaluate them, or protect consumers against potential harms like AI bias, infringement of privacy or other rights, or spreading inaccurate information according to the nonprofit, nonpartisan Brennan Center for Justice. Nearly 400 state laws are also under consideration, according to BSA, a software lobbying group, including California SB-1047, which would regulate AI models whose training exceeds a particular threshold of computation. Moreover, the U.S. will hold national elections in November, and lobbying of all kinds typically intensifies as organizations seek to influence candidates for office.
Why it matters: Given the large amount of AI development that takes place in the U.S., laws that govern AI in this country have an outsized influence over AI development worldwide. So it’s helpful to know which companies and institutions seek to influence those laws and in what directions. That the army of AI lobbyists includes companies large and small as well as far-flung institutions, with varying degrees of direct involvement in building or using AI, reflects both the technology’s power and the importance of this moment in charting its path forward.
We’re thinking: We favor thoughtful regulation of AI applications that reinforces their tremendous potential to do good and limits potential harms that may result from flaws like bias or privacy violations. However, it’s critical to regulate applications, which put technology to specific uses, not the underlying technology, whose valuable uses are wide-ranging and subject to human creativity. It’s also critical to encourage, and not stifle, open models that multiply the potential good that AI can do. We hope the AI community can come together on these issues.
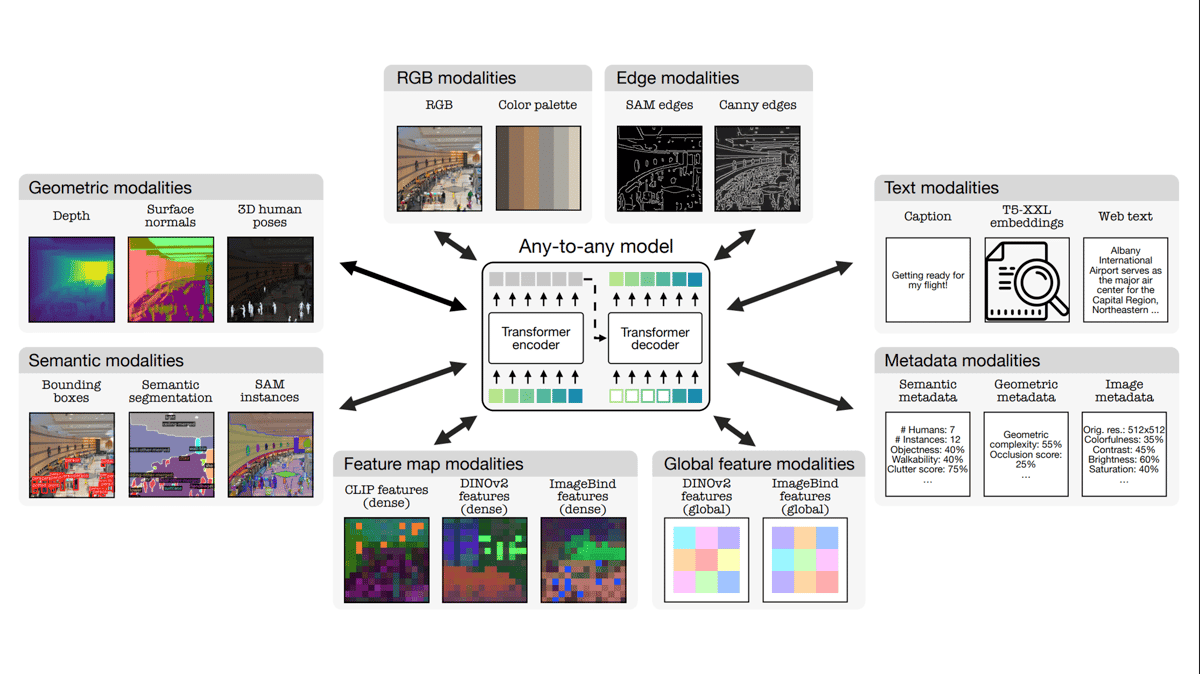
Multimodal to the Max
Researchers introduced a model that handles an unprecedented number of input and output types, including many related to performing computer vision tasks.
What’s new: Roman Bachmann, Oguzhan Fatih Kar, David Mizrahi and colleagues at EPFL and Apple built 4M-21, a system that works with 21 input and output types. These include modalities related to images, geometry, and text along with metadata and embeddings produced by other models.
Key insight: The authors followed and extended their insight from the earlier 4M, which handles seven input and output types, as well as work such as Unified-IO 2, which handles 11. The key to training a model to handle multiple types of data input is to ensure that the training data takes the same format with the same-sized embedding across all input types. Using the transformer architecture, tokens suffice.
How it works: 4M-21 comprises a large transformer and several encoder-decoders that convert different data types into tokens and back. The authors repeated their training strategy for 4M, but they increased the transformer’s size from 303 million parameters to 3 billion parameters, boosted the training dataset size from 400 million examples to 500 million examples, and incorporated new input types.
- The authors started with RGB images and captions from CC12M and COYO700M plus text from C4.
- Using a variety of tools, they extracted depth images, surface-normal images, semantically segmented images, images of edges, graphics metadata, bounding boxes, color palettes, web text, image embeddings (feature maps and global embeddings), and text embeddings. For instance, they performed semantic segmentation using Mask2Former and SAM, and extracted edges using OpenCV and SAM, counting each output as a separate data type.
- They converted all input types into tokens. For image-like data types and image embeddings, they trained VQ-VAE to reconstruct images and, in doing so, represent images as tokens. For human poses and the embeddings from DINOv2 and ImageBind, they trained Bottleneck MLP to reconstruct them and thus learn to represent them as tokens. They produced tokens of sequence data including text and metadata using WordPiece.
- Given a random sample of tokens of all modalities, 4M-21 learned to predict a different random sample of tokens. The random samples were sometimes biased toward one modality and other times biased toward a more balanced sampling. To determine which tokens to produce, 4M-21 received mask tokens that specified the desired modalities and token positions in the output.
Results: 4M-21 demonstrated strong zero-shot performance in a variety of vision tasks. For instance, in estimating surface normals for each point in an image, 4M-21 achieved a 20.8 L1 score (average absolute difference between predicted and true values, lower is better), while the multimodal model UnifiedIO 2-XL achieved a 34.8 L1. In estimating an image’s depth map, 4M-21 achieved 0.68 L1, while UnifiedIO 2-XL achieved 0.86 L1. In semantic segmentation, 4M-21 reached 48.1 percent mean intersection over union (overlap between predicted and ground-truth segments divided by their union, higher is better), while UnifiedIO 2-XL achieved 39.7 percent mean intersection over union.
Why it matters: Since 4M-21 learned to predict tokens of several modalities using tokens from other modalities, it isn’t limited to a single modalities as input. The authors demonstrate that it can generate new images conditioned by the combination of a caption and 3D human poses, edges, or metadata.
We’re thinking: The authors say 4M-21 can take as input any combination of the modalities it’s trained to handle and output any of them. The limits of this capability aren’t clear, but it opens the door to fine control over the model’s output. The authors explain how they extracted the various modalities; presumably users can do the same to prompt the model for the output they desire. For instance, a user could request an image by entering not only a prompt but also a color palette, edges, depth map extracted from another image, and receive output that integrates those elements.