
Dear friends,
Recently I visited South Korea, where I spoke at length about AI with President Yoon Suk Yeol. Based on what I saw there in government, business, and academia, the nation is well positioned to become a strong AI hub. When he asked me if I would advise South Korea as a member of the Global AI Strategy Steering Group of the country’s National AI Committee, I agreed on the spot. I was delighted to learn this week that Yann LeCun has also joined. I’ve been consistently impressed by the thoughtful approach the Korean government has taken toward AI, with an emphasis on investment and innovation and a realistic understanding of risks without being distracted by science-fiction scenarios of harm.
I’ve advised many countries to build AI for the sectors where they’re strong. For example, I felt that by investing in sectors like tourism and certain industries, Thailand can do projects more efficiently than I can in Silicon Valley. South Korea’s tech ecosystem gives it a foundation to move even faster across multiple sectors. This emphasizes the long-term value for countries to become good at tech, because tech is now pervasive and affects all industries.
Korea has a very strong local software ecosystem. For example, the dominant search engine is not Google or Bing, but Naver (a Korean company). The dominant messaging system is not WhatsApp or WeChat, but KakaoTalk. With local tech giants Naver and Kakao offering email, mobile payment, cloud computing, ride sharing, and other services, the country has many sophisticated tech businesses. Additionally, SK hynix and Samsung are advanced semiconductor manufacturers. It also has a thriving entrepreneurship ecosystem, including Upstage, a language modeling startup, which taught a course with us on “Pretraining LLMs.” Finally, the Korean institutions Seoul National University, which I visited last year, and KAIST have global reputations.

Korea has a highly educated population, highly skilled software engineers, and a thriving set of software products. This gives it a fantastic foundation to embrace the next generation of AI. After meeting with businesses in retail, construction, insurance, cosmetics, telecoms, and other industries, I was delighted by the wide variety of opportunities many companies are pursuing across different industry sectors.
Lastly, Korea is known globally for its K-pop. Meeting Bang Si-Hyuk, the chairman of HYBE, which manages the superstar singing group BTS, and learning how the company operates was a real treat! (Another treat was eating at a Korean eel house, where the seafood was unforgettable.)
That’s why I’ve traveled to South Korea four times since last year. My venture studio AI Fund, which collaborates with many Korean companies, has benefited tremendously from the advice of many South Koreans, including Taizo Son, Changmook Kang, Hyungjun Kim, Sung Kim, JP Lee, Ian Park, and Alice Oh. I look forward to doing more in, and with, South Korea!
화이팅 (Let’s go)!
Andrew
P.S. We just released the final two courses of AI Python for Beginners! The complete set of four courses is now available and remains free for a limited time. If you know someone who is considering learning to code, please recommend these courses! They teach how to (a) write code using AI-assistance, which is where the field is going, and (b) take advantage of generative AI, which allows you to do valuable things quickly. Since releasing the first two courses, I’ve been inspired by many learner stories like this one. Julia K. started with AI Python for Beginners and shortly afterward wrote useful program after useful program. (She accomplished this before we had even finished releasing all four courses!) I hope many others will have similar stories to tell.
A MESSAGE FROM DEEPLEARNING.AI

The final courses of Andrew Ng’s AI Python for Beginners are live! Work on hands-on projects to analyze data, automate tasks, create reusable functions, and extend Python with third-party tools. Join for free today!
News
Long Context Gets Up to Speed
A new open weights model generates tokens faster than current transformers, especially when processing long inputs.
What’s new: AI21 Labs released Jamba 1.5, an update of its earlier Jamba. It comes in Mini and Large versions and boasts a relatively large (and validated) input context length of 256,000 tokens. The model weights are free to users who have annual recurring revenue under $50 million and available on several cloud platforms including Google Cloud Vertex AI, Hugging Face, and Microsoft Azure.
How it works: Jamba 1.5 is a hybrid architecture made up of transformer, mamba, and mixture of experts (MoE) layers. Unlike transformer layers, in which processing power scales quadratically as input length increases, the mamba layers enable the required processing power to scale linearly as input length increases without requiring workarounds like sparse attention and sliding windows. The MoE layers are composed of many fully connected sublayers, of which only a small number are used to process a given input. Jamba 1.5 Mini has roughly 50 billion parameters but uses only 12 billion at a time, while Jamba 1.5 Large has around 400 billion parameters but uses only 94 billion at a time.
- The authors pretrained Jamba 1.5 on a proprietary dataset of web documents, code, books, and scientific articles. They further pretrained it on a higher proportion of longer documents to increase its ability to process long-text inputs.
- They fine-tuned Jamba 1.5 on generated data to handle specific types of input such as instructions, conversations, longer documents, question-answer pairs, and calls to external tools.
- Unlike transformer-based models, Jamba 1.5 showed no benefit from positional embeddings of input tokens, so it doesn’t use them.
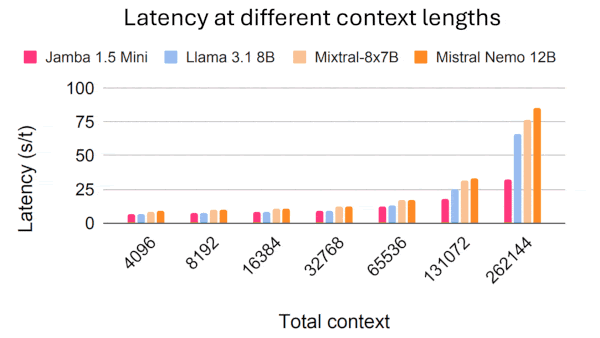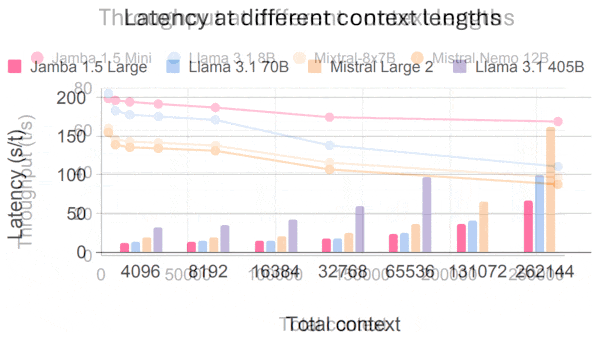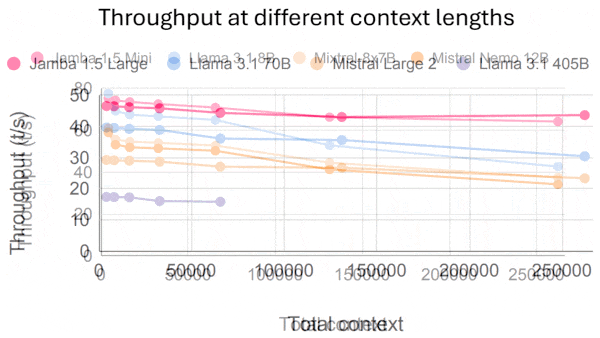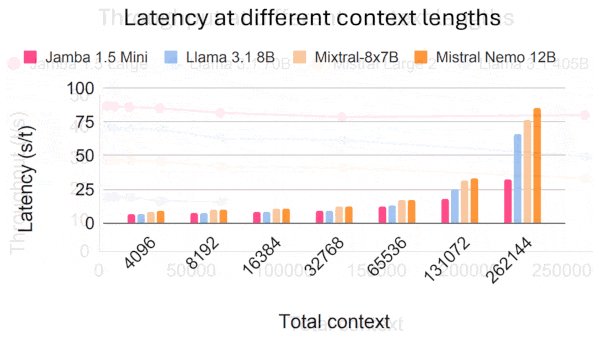
Results: Both versions of Jamba 1.5 produced output tokens faster than other models (running on identical hardware), especially given longer inputs. However, the larger version achieved lower performance on popular benchmarks than other open models.
- With 262,144 tokens as input, Jamba 1.5 Mini generated about 62 tokens per second, LLaMA 3.1 8B generated about 41, and Mixtral generated about 39. The difference became narrower as input length decreased. With 4,096 tokens as input, Jamba 1.5 Mini generated around 78 tokens per second, LLaMA 3.1 8B generated about 79, and Mixtral 8x7B generated about 60.
- Both models performed extraordinarily well on RULER, a suite of 13 tasks that assess the ability of large language models to take advantage of input context at various lengths. Jamba 1.5 Mini and Large utilized their full context length, while many competing models utilized half or less.
- Across 11 popular benchmarks, Jamba 1.5 Mini performed similarly to LLaMA 3.1 8B and Gemma 2 9B. However, Jamba 1.5 Large achieved lower performance than LLaMA 3.1 70B and Mistral Large 2 123B on nearly every benchmark.
Behind the news: The mamba architecture, which is designed to enable processing to scale linearly with longer input lengths, has been a subject of much research since its release in late 2023. Notably, Mamba-2, Mamba-2-Hybrid, and Zamba combined mamba layers with attention layers with varying degrees of success.
Why it matters: The original Mamba model was much faster and equally accurate compared to transformers up to 2.8 billion parameters. But how the mamba architecture compared to transformers at larger scales was an open question. Jamba 1.5 shows that the combination of mamba and transformer layers can yield higher speed in larger models — although the results don’t yet exceed those of comparably sized transformers.
We’re thinking: While hardware companies like Groq and SambaNova are accelerating LLMs, software innovations like Jamba may enable further speed-ups.
Models Ranked for Hallucinations
How often do large language models make up information when they generate text based on a retrieved document? A study evaluated the tendency of popular models to hallucinate while performing retrieval-augmented generation (RAG).
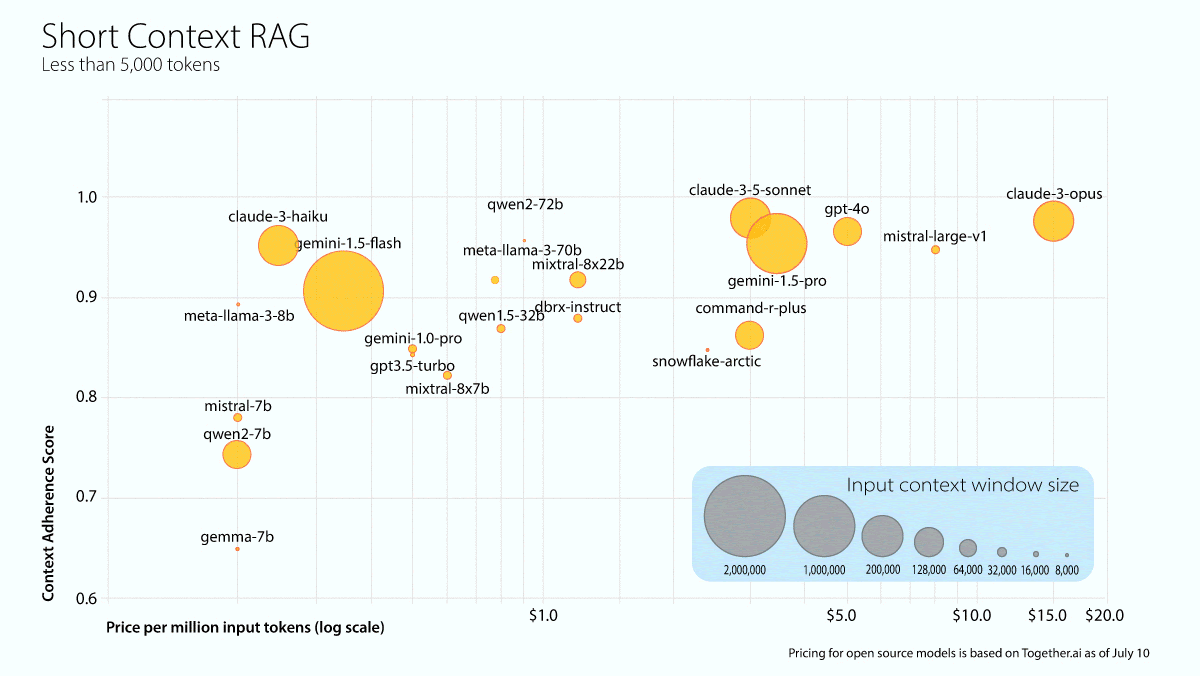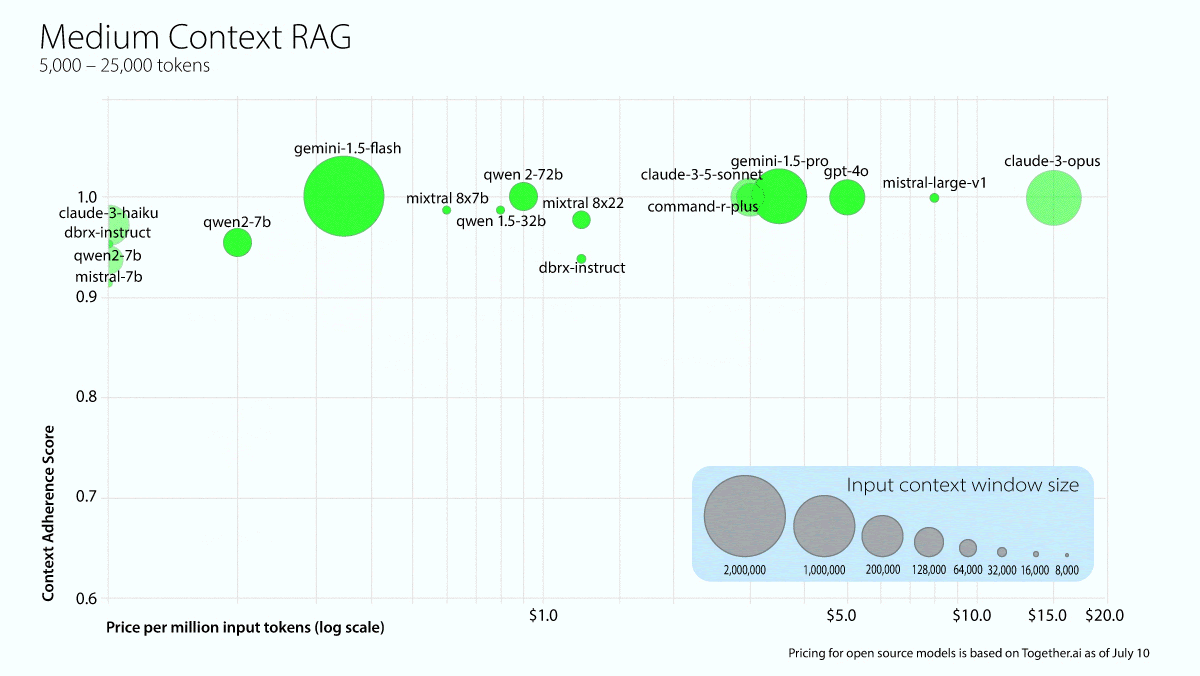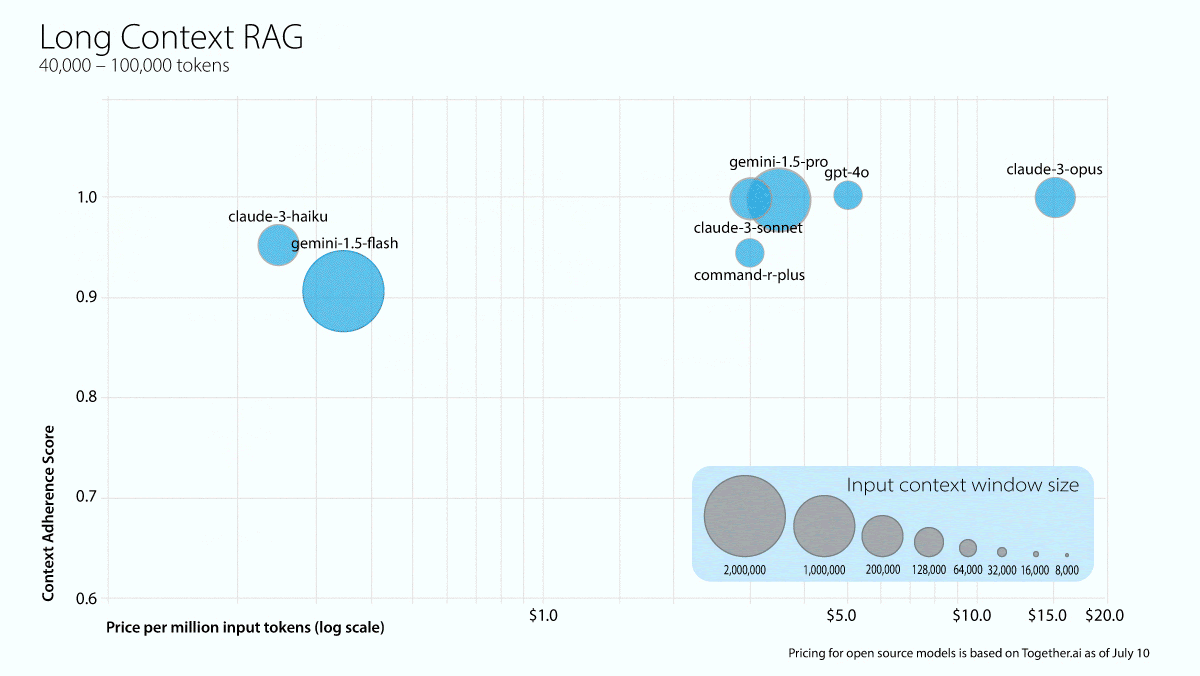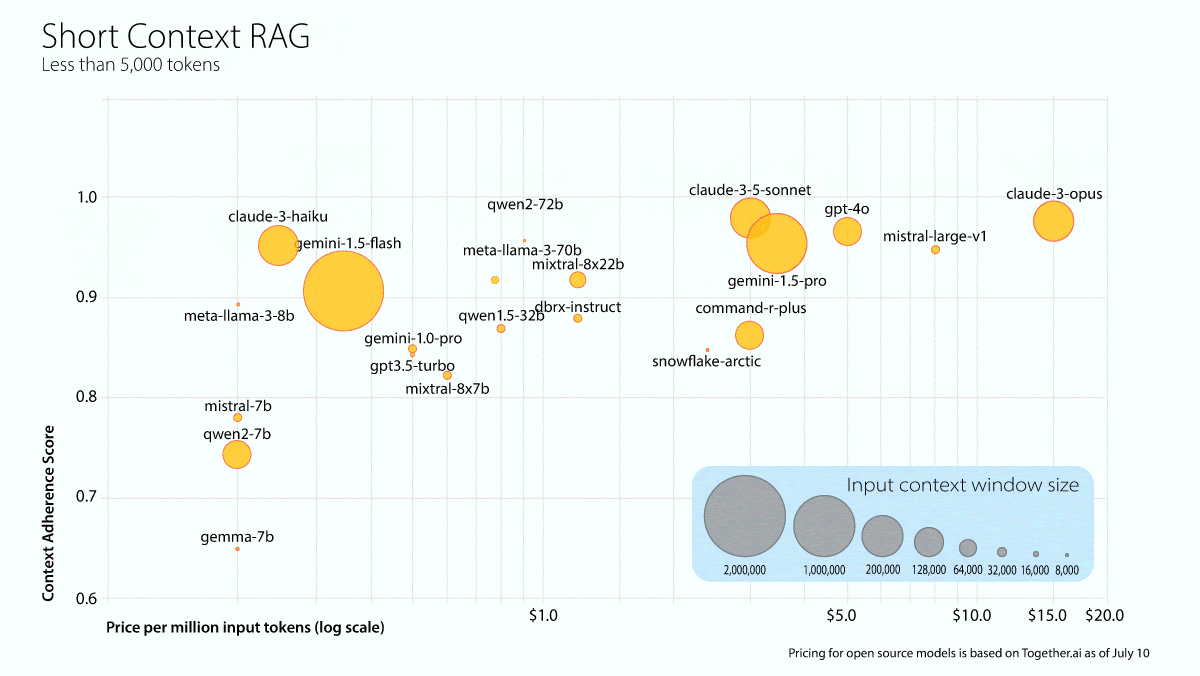
What’s new: Galileo, which offers a platform for evaluating AI models, tested 22 models to see whether they hallucinated after retrieving information from documents of various lengths. Claude 3.5 Sonnet was the overall winner, and most models performed best when retrieving information from medium-length documents.
How it works: The researchers tested 10 closed and 12 open models based on their sizes and popularity. They ran each model 20 times using short, medium, and long context lengths (a total of 60 tests) using GPT-4o to evaluate how closely the output text adhered to the context.
- The researchers selected text from four public and two proprietary datasets for short-context tests (less than 5,000 tokens each). They chose longer documents from private companies for medium- and long-context tests. They split these documents into passages of 5,000, 10,000, 15,000, 20,000, and 25,000 tokens for medium-context tests, and 40,000, 60,000, 80,000, and 100,000 tokens for long-context tests.
- For each test, they fed a prompt and a related document to a model. The prompt asked the model to retrieve particular information from the document.
- They fed the prompt and response to Galileo’s ChainPoll hallucination detection tool. ChainPoll queries a model (in this case, GPT-4o) multiple times using chain-of-thought prompting to return a score of either 1 (the response is directly supported by the context document) or 0 (the response is not supported by the context document). They tallied each model’s average scores for each context length and averaged those to produce a final score.
Results: Anthropic’s Claude 3.5 Sonnet ranked highest overall, achieving 0.97 in short context lengths and 1.0 in medium and long context lengths.
- Among models with open weights, Qwen2-72b Instruct scored highest for short (0.95) and medium (1.0) context lengths. The researchers singled out Gemini 1.5 Flash for high performance (0.94, 1.0, and 0.92 for short, medium, and long context lengths respectively) at low cost.
- Most models performed best in medium context lengths, which the report calls the “sweet spot for most LLMs.”
Behind the news: Galileo performed similar tests last year, when it compared performance in both RAG and non-RAG settings (without differentiating among context lengths). GPT-4 and GPT-3.5 held the top three spots in both settings despite strong showings by Llama 2 and Zephyr 7B. However, the top scores were lower (between 0.70 and 0.77).
Why it matters: Model builders have reduced hallucinations, but the difference between rare falsehoods and none at all may be critical in some applications.
We’re thinking: It’s curious that medium-length RAG contexts generally yielded fewer hallucinations than short or long. Maybe we should give models more context than we think they need.
AI-Powered Policing Goes National
Argentina created a national law-enforcement department that will use AI to detect crimes as they’re committed, investigate them afterward, and predict them before they occur.
What’s new: President Javier Milei of Argentina established the Artificial Intelligence Unit Applied to Security (UIAAS), The Register reported. The unit aims to detect, investigate, and predict criminal activity by using machine learning algorithms to monitor the internet, wireless communications, security cameras, drone surveillance, financial transactions, and other data in real time.
How it works: Milei established the UIAAS in a late-July resolution. Milei created it under the Ministry of Security shortly after he reorganized the national intelligence agency to give himself more direct control. In December, his security minister quashed public protests against his austerity policies; he promised to identify protesters via “video, digital, or manual means” and bill them for the cost of policing the demonstrations.
- The UIAAS is empowered to “use machine learning algorithms to analyze historical crime data to predict future crimes and help prevent them.” This approach “will significantly improve the efficiency of the different areas of the ministry and of the federal police and security forces, allowing for faster and more precise responses to threats and emergencies,” the resolution states.
- The resolution notes that Argentina is not alone among nations in using AI for law enforcement. It cites China, France, India, Israel, Singapore, the United Kingdom, and the United States as “pioneers in the use of Artificial Intelligence in their areas of government and Security Forces.”
- The new unit is part of a broader cost-cutting effort that aims to replace government workers and organizations with AI systems, according to El Pais, a news outlet based in Madrid.
Behind the news: Argentina’s government is a presidential representative democratic republic. The country was ruled by a military dictatorship between 1976 and 1983.
- A report by the Pulitzer Center, which sponsors independent reporting on global issues, found that, between 2019 and 2020, a face recognition network in the Argentine capital city of Buenos Aires overreached its mission to track only fugitives and led to at least 140 errors that culminated in mistaken arrests or police checks. In 2022, a judge ruled the system unconstitutional and shut it down. City officials are trying to overturn the decision.
- However, Buenos Aires has used AI successfully in its criminal justice system. A rule-based system designed to prepare court opinions shortened the process of presenting evidence for consideration in a trial from 90 minutes to 1 minute and the time to process injunctions from 190 days to 42 days, according to the Inter-American Development Bank.
Why it matters: AI has valuable uses in law enforcement and security. At the same time, it needs to be applied responsibly and implemented in a way that’s fair and respectful of legal rights such as presumption of innocence.
We’re thinking: Surveillance is easy to abuse, and the notion of predictive policing warrants extreme caution to avoid bias against certain groups, violating civil rights, and other pitfalls. Ensuring that it’s used well requires robust technology, rigid controls, clear oversight, and public transparency. We hope that Argentina — no less than the countries that inspired it establish a national AI police agency — will put strong safeguards in place.
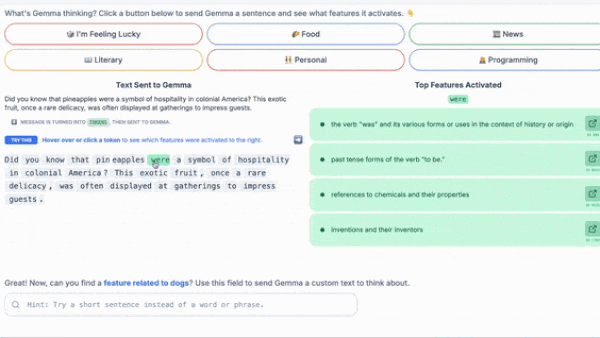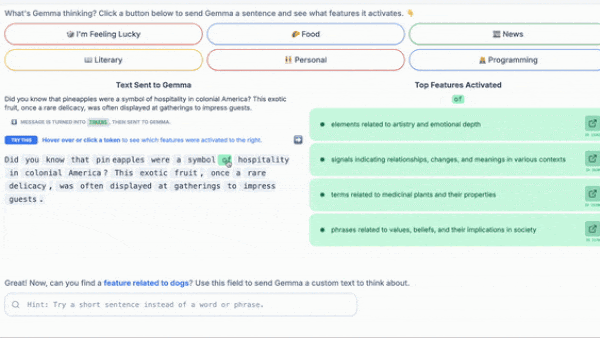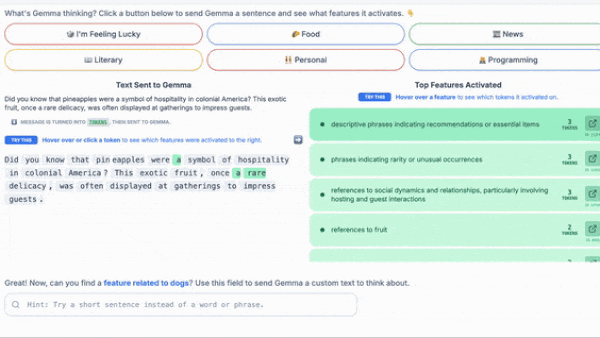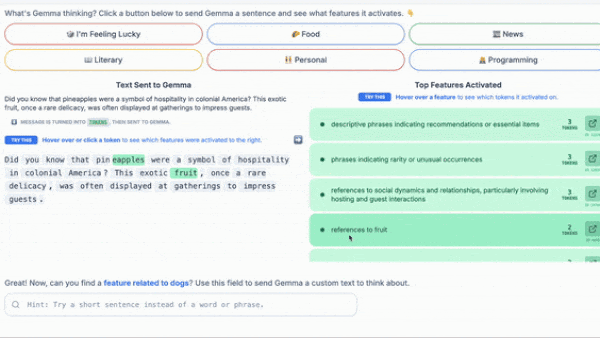
Making LLMs Explainable
Researchers have probed the inner workings of individual layers of large language models. A new tool applies this approach to all layers.
What’s new: Tom Lieberum and colleagues at Google released Gemma Scope, a system designed to illuminate how each layer in Gemma 2-family large language models responds to a given input token. Gemma Scope is available for the 9 billion-parameter and newly released 2 billion-parameter versions of Gemma 2. You can play with an interactive demo or download the weights.
Key insight: A sparse autoencoder (SAE) is a sparse neural network that learns to reconstruct its input. The authors drew on earlier research into using SAEs to interpret neural networks.
- To see what a neural network layer knows about a given input token, you can feed it the token and study the embedding it generates. The difficulty with this approach is that the value at each index of the embedding may represent a tangle of concepts that are associated with many other values — too many other values to track.
- Instead, an SAE can transform the embedding into one in which each index corresponds to a distinct concept. The SAE can learn to represent the embedding by the weighted sum of a much larger number of vectors than the number of values in the embedding. However, each weighted sum has only a small number of non-zero weights — in other words, each embedding is expressed as only a small-number, or sparse, subset of the SAE vectors. Since the number of learned SAE vectors is far greater than the number of values in the original embedding, any given vector is more likely to represent a distinct concept than any value in the original embedding.
- The weights of this sum are interpretable: Each weight represents how strongly the corresponding concept is represented in the input. Given a token, the SAE’s first layer produces these weights.
How it works: The authors built over 400 SAEs, one for each layer of Gemma 2 2B and Gemma 2 9B. They fed Gemma 2 examples from its pretraining set and extracted the resulting embeddings at each layer. Given the resulting embeddings from a specific layer, an SAE learned to reconstruct each of them. An additional loss term minimized the number of non-zero outputs from the SAE’s first layer to help ensure that the SAE used only concepts related to the embedding. To interpret an embedding produced by the first layer of the SAE, the team labeled the embedding’s indices with their corresponding concepts. They used two main methods: manual and automatic.
- Manual labeling: (1) Insert the SAE in the appropriate location in Gemma 2. (2) Prompt Gemma 2. (3) Select an index in the embedding from the SAE’s first layer. (4) Note which token(s) cause the value at that index to be high. (5) Label the index manually based on commonalities between the noted tokens.
- Automatic labeling: This was similar to manual labeling, but GPT4o-mini labeled the indices based on commonalities between the noted tokens.
- In addition to testing how Gemma 2 responds to particular input tokens, Gemma Scope can be used to steer the model; that is, to see how the model responds when it’s forced to generate text related (or unrelated) to a particular concept: (1) Search the index labels to determine which index corresponds to the concept in question. (2) Insert the corresponding SAE into Gemma 2 at the appropriate layer. (3) Prompt the modified Gemma 2 to generate text, adjusting the output of the SAE’s first layer at the index. Gemma 2’s text should reflect the changed value.
Behind the news: Earlier research into using SAEs to interpret neural networks was limited to interpreting a single layer or a small network. Earlier this year, Anthropic used an SAE to interpret Claude 3 Sonnet’s middle layer, building on an earlier report in which they interpreted a single-layer transformer.
Why it matters: Many questions about how LLMs work have yet to be answered: How does fine-tuning change the way a model represents an input? What happens inside a model during chain-of-thought prompting versus unstructured prompting? Training an SAE for each layer is a step toward developing ways to answer these questions.
We’re thinking: In 2017, researchers visualized the layers of a convolutional neural network to show that the deeper the layer, the more complex the concepts it learned. We’re excited by the prospect that SAEs can deliver similar insights with respect to transformers.