
Dear friends,
Over the weekend, my two kids colluded in a hilariously bad attempt to mislead me to look in the wrong place during a game of hide-and-seek. I was reminded that most capabilities — in humans or in AI — develop slowly.
Some people fear that AI someday will learn to deceive humans deliberately. If that ever happens, I’m sure we will see it coming from far away and have plenty of time to stop it.
While I was counting to 10 with my eyes closed, my daughter (age 5) recruited my son (age 3) to tell me she was hiding in the bathroom while she actually hid in the closet. But her stage whisper, interspersed with giggling, was so loud I heard her instructions clearly. And my son’s performance when he pointed to the bathroom was so hilariously overdramatic, I had to stifle a smile.
Perhaps they will learn to trick me someday, but not yet! (In his awful performance, I think my son takes after me. To this day, I have a terrible poker face — which is matched by my perfect lifetime record of losing every poker game I have ever played!)
Last year, the paper “Are Emergent Abilities of Large Language Models a Mirage?” by Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo, which won a NeurIPS outstanding paper award, considered “emergent” properties of LLMs, which refers to capabilities that seem to appear suddenly as model sizes increase. The authors point out that scaling laws imply that the per-token error rate decreases (improves) slowly with scale, and emergent properties might be an artifact of researchers studying nonlinear or discontinuous metrics that transform a gradually decreasing per-token error rate into something that looks more like a step function.

Consider a “combination lock” metric that requires getting many items right. Say we’re measuring the likelihood that an LLM will get 10 independent digits of an answer right. If the odds of it getting each digit right improve gradually from 0 to 1, then the odds of it getting all 10 digits right will appear to jump suddenly. But if we look at continuous metrics, such as the total number of correct digits, we will see that the underlying performance actually improves gradually. (Public perception of a technology can also shift in a discontinuous way because of social dynamics.)
This is why many of us saw GPT-3 as a promising step in transforming text processing long before ChatGPT appeared: BERT, GPT, GPT-2, and GPT-3 represented points on a continuous spectrum of progress. Or, looking back further in AI history, even though AlphaGo’s victory over Lee Sedol in the game of Go took the public by surprise, it actually represented many years of gradual improvements in AI’s ability to play Go.
While analogies between human and machine learning can be misleading, I think that just as a person’s ability to do math, to reason — or to deceive — grows gradually, so will AI’s. This means the capabilities of AI technology will grow gradually (although I wish we could achieve AGI overnight!), and the ability of AI to be used in harmful applications, too, will grow gradually. As long as we keep performing red-teaming exercises and monitoring our systems’ capabilities as they evolve, I’m confident that we will have plenty of time to spot issues in advance, and the science-fiction fears of AI-initiated doomsday will remain science fiction.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Learn to build AI systems that interact with video in “Multimodal RAG: Chat with Videos,” taught by Intel’s Vasudev Lal. Use multimodal embedding models to merge visual and text data, and build retrieval augmented generation (RAG) systems with LangChain and vector stores. Start today
News
Waymo Spotlights Safety Record
Waymo, the autonomous vehicle division of Alphabet, released an analysis of its own safety data. It suggests that the company’s self-driving cars are safer than human drivers on the same roads.
What’s new: Waymo’s analysis claims that its robotaxis, compared to human-driven vehicles, were involved in proportionally fewer accidents that involved police reports, passenger injuries, or airbag deployment. The company argues that these types of incidents are more relevant to assessing safety than minor collisions with no serious damage.
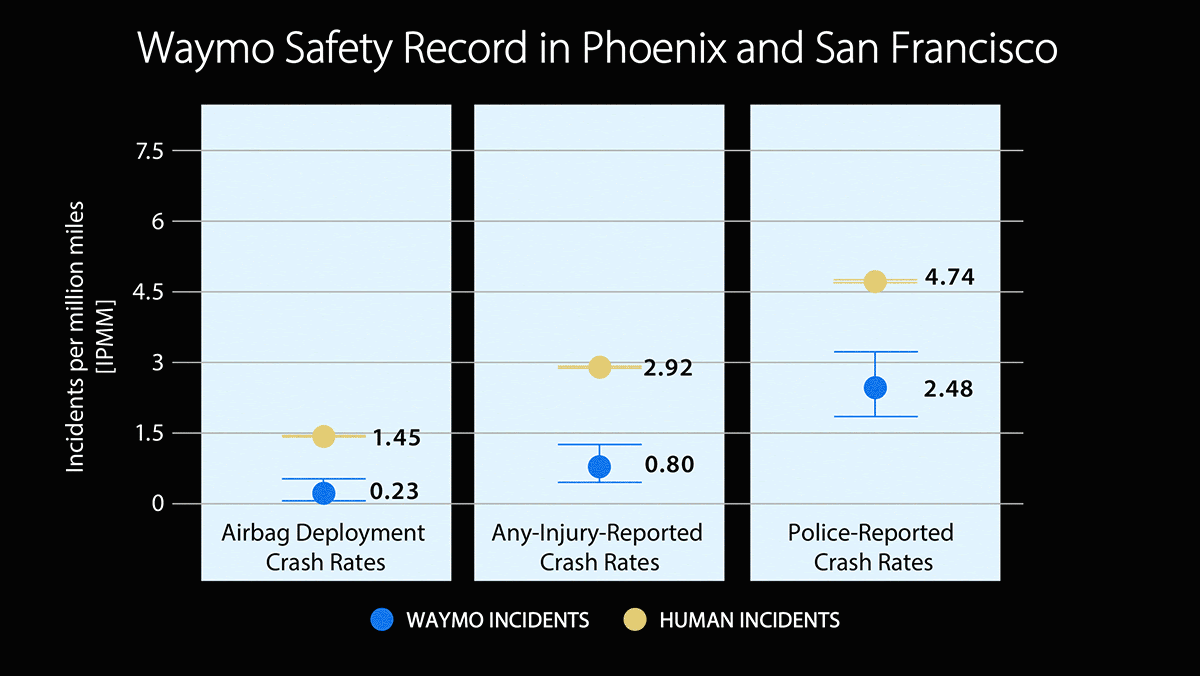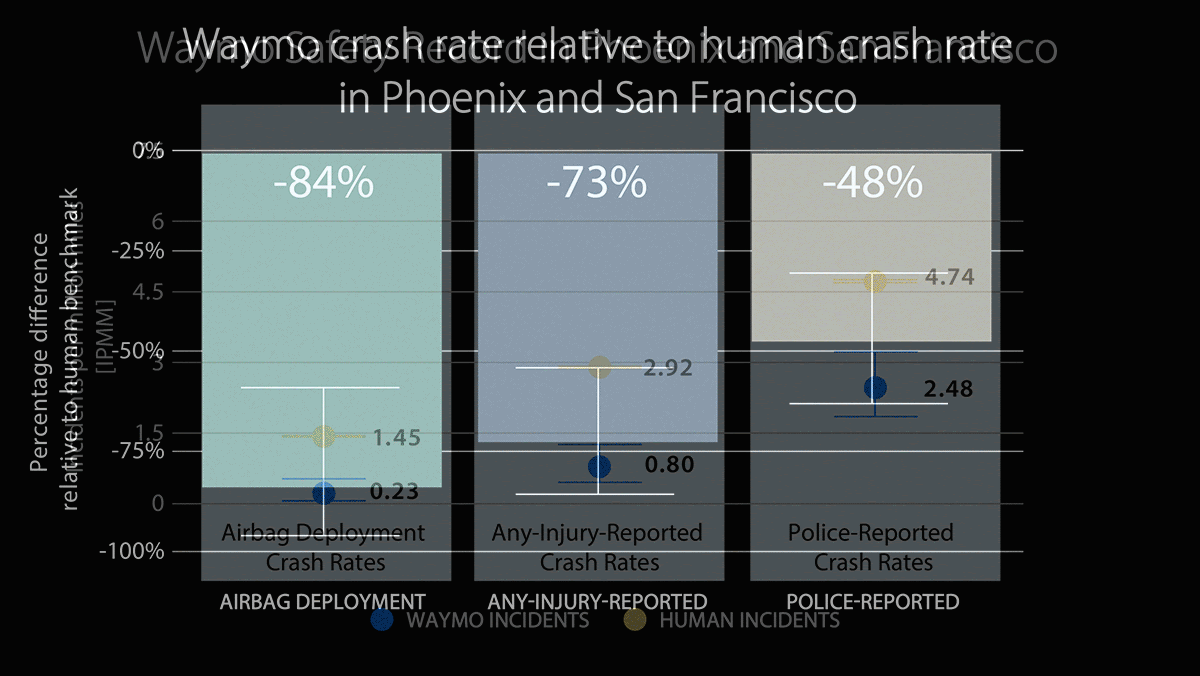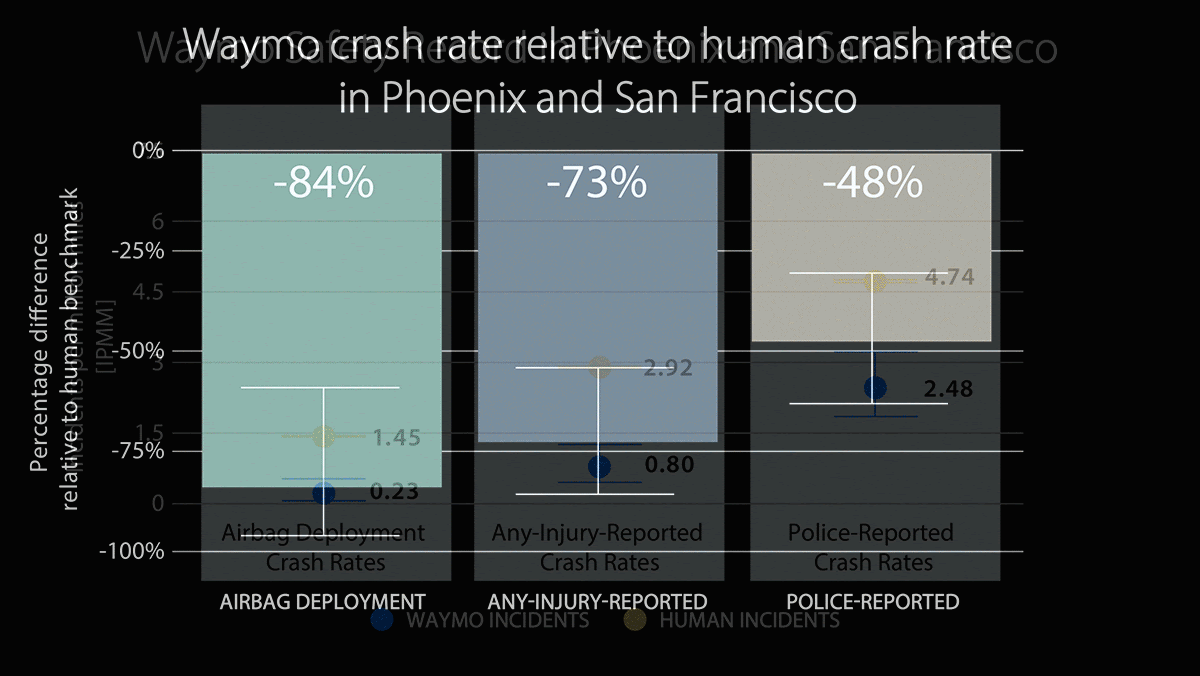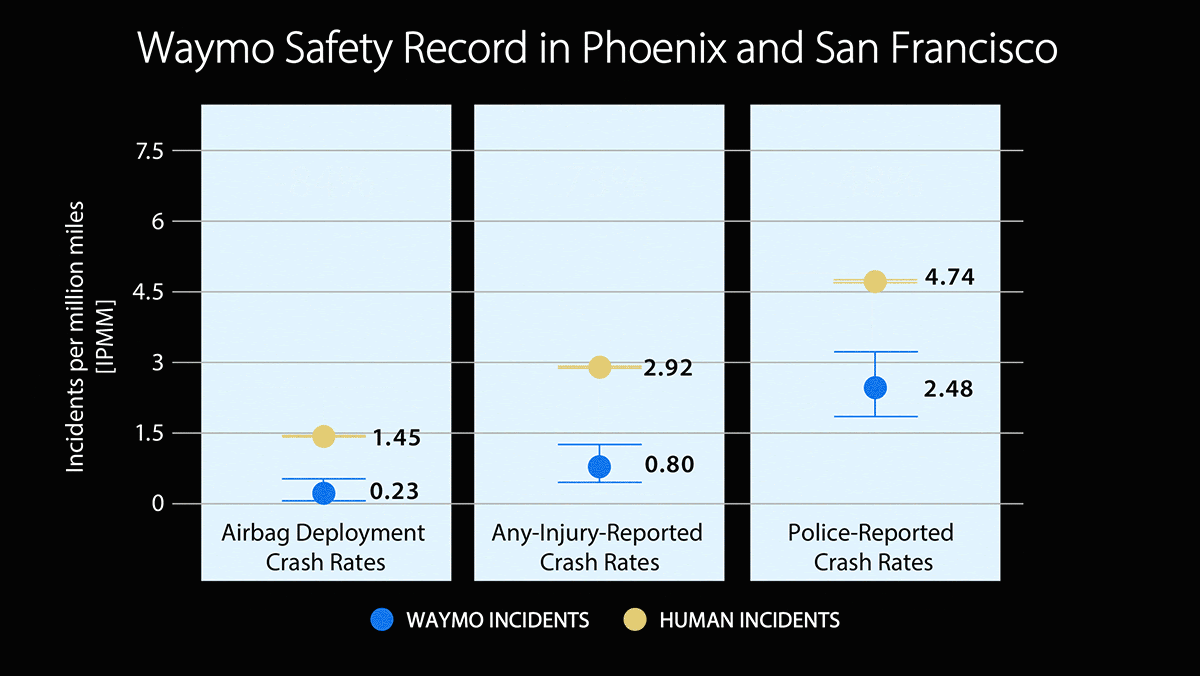
How it works: The study compares the number of incidents per mile experienced by Waymo vehicles and human drivers. It covers over 22 million miles driven along specific routes in Phoenix, Arizona, and San Francisco, California. The results were consistent in Phoenix and San Francisco.
- Waymo vehicles had 48 percent fewer incidents that were reported to the police than vehicles driven by humans.
- Waymo vehicles had 73 percent fewer incidents that caused injuries than vehicles driven by humans.
- Waymo vehicles deployed airbags 84 percent less frequently than vehicles driven by humans.
Behind the news: Waymo’s study arrives amid ongoing scrutiny of autonomous vehicle safety, particularly in San Francisco, where accidents and traffic disruptions caused by self-driving cars have raised public backlash and regulatory challenges. Earlier this year, the state of California banned Cruise, a Waymo competitor, after one of its self-driving cars drove over a pedestrian and dragged her about 20 feet before coming to a stop.
Why it matters: Waymo’s analysis implies that autonomous vehicles could significantly reduce road accidents and injuries. The data could help urban planners to craft policies that would integrate autonomous vehicles into existing transportation systems.
Yes, but: Waymo’s analysis is based on methods and benchmarks introduced in two research papers that have not yet been peer reviewed. Validating them through peer review would help to establish the safety record of self-driving cars.
We’re thinking: This report makes a compelling case for autonomous vehicles. But the question remains whether these findings will be sufficient to increase public trust. We encourage other self-driving companies to release comprehensive safety data.

2D-to-3D Goes Mainstream
Traditionally, building 3D meshes for gaming, animation, product design, architecture, and the like has been labor-intensive. Now the ability to generate 3D meshes from a single image is widely available.
What’s new: Two companies launched systems that produce a 3D mesh from one image. Stability AI released SF3D. Its weights and code are freely available to users with annual revenue under $1 million. Meanwhile, Shutterstock launched a service that provides a similar capability.
How it works: Stability AI’s SF3D generates output in a half-second, while Shutterstock’s service takes around 10 seconds.
- SF3D has five components: (1) a transformer that produces an initial 3D representation of an input image; (2) a model based on CLIP that uses the image to estimate how metallic and rough the object’s surface texture is; (3) a convolutional neural network that, given the transformer’s output, estimates how light reflects off the surface; (4) a model based on Deep Marching Tetrahedra (DMTet) that smooths the transformer’s output; and (5) an author-built algorithm that separates the 3D mesh from the surface texture map.
- Shutterstock’s service, developed by TurboSquid (which Shutterstock acquired in 2021) and Nvidia, is due to launch this month. The company hasn’t disclosed pricing or how the system works. Users can specify an object and surroundings including light sources via an image or text description.
Behind the news: These releases arrived amid a flurry of recent works that aim to tackle similar problems. Most are based on Large Reconstruction Model (LRM), proposed by Adobe in late 2023, which produces a 3D mesh and surface texture from a single image in less than 5 seconds. Follow-up work trained LRM on real-world images in addition to the images of synthetic 3D meshes used in the original work and then reproduced LRM’s capabilities in an open source model. Further research extended the model to learn from generated videos. Stability AI’s new system addresses issues in its own previous work that was based on LRM.
Why it matters: SF3D replaces NeRF, a 2D-to-3D approach proposed in 2020 that serves as the basis for LRM and several other methods, with DMTet, which incorporates surface properties to achieve smoother meshes and better account for light reflecting off object surfaces.
We’re thinking: 3D generation is advancing rapidly. To ignore this technology would be a mesh-take!

Western Powers Sign AI Treaty
The European Union, United Kingdom, United States, and other countries signed a legally binding treaty that regulates artificial intelligence.
What’s new: The treaty, officially known as the Framework Convention on Artificial Intelligence and Human Rights, Democracy, and the Rule of Law, provides a legal framework for states to preserve democratic values while promoting AI innovation. It was negotiated by member nations of the Council of Europe (a transnational organization that promotes democracy and human rights and includes nearly twice as many countries as the EU) as well as observer states including Australia, Canada, and Mexico, which have not yet signed it. Countries that did not participate include China, India, Japan, and Russia.
How it works: The treaty will take effect later this year. It applies to any use of AI by signatories, private actors working on behalf of signatories, or actors in those jurisdictions. AI is broadly defined as any “machine-based system . . . [that generates] predictions, content, recommendations, or decisions that may influence physical or virtual environments.” The signatories agreed to do the following:
- Ensure that all AI systems are consistent with human-rights obligations and democratic processes, including individual rights to participate in fair debate
- Prohibit any use of AI that would discriminate against individuals on the basis of gender or other characteristics protected by international or domestic law
- Protect individual privacy rights and personal data against uses by AI
- Assess AI systems for risk and impact before making them widely available
- Promote digital literacy and skills to ensure public understanding of AI
- Notify individuals when they are interacting with an AI system
- Shut down or otherwise mitigate AI systems when they risk violating human rights
- Establish oversight mechanisms to ensure compliance with the treaty and provide remedies for violations
Exceptions: The treaty allows exceptions for national security and doesn’t cover military applications and national defense. It also doesn’t apply to research and development of AI systems that are not yet available for general use, unless testing such systems can interfere with human rights, democracy, or the rule of law.
Behind the news: The Council of Europe oversees the European Convention on Human Rights and its Court of Human Rights in Strasbourg, France. Its AI treaty builds on previous initiatives including the European Union's AI Act, which aims to regulate AI based on risk categories, and other national and international efforts like the United States’ AI Bill of Rights and the global AI Safety Summit.
Why it matters: As the first binding international agreement on AI, the treaty can be enforced by signatories’ own laws and regulations or by the European Court of Human Rights. Since so many AI companies are based in the U.S. and Europe, the treaty may influence corporate practices worldwide. Its provisions could shape the design of deployed AI systems.
Yes, but: Like any regulation, the treaty’s effectiveness depends on the interpretation of its high-level concepts. Its core terms (such as accountability measures, democratic processes, oversight, privacy rights, and transparency) represent a broad framework, but their precise meaning is vague and interpretation is left to the signatories. Also, the nonparticipation of major AI powers like China and large countries like Russia and India raises questions about whether its standards can be applied globally.
We’re thinking: The EU and U.S. have very different approaches to AI regulation; the EU has taken a much heavier hand. Yet both agreed to the treaty. This could indicate that these regions are finding common ground, which could lead to more uniform regulations internationally.

Balancing Web Data Distributions
Datasets that were scraped from the web tend to be unbalanced, meaning examples of some classes (say, cats) are plentiful while examples of others (say, caterpillars) are scarce. A model that’s trained on an unbalanced dataset will perform unevenly across classes, but the labor required to balance the data manually can be prohibitive. An automated method addresses such imbalances.
What’s new: Huy V. Vo and colleagues at Meta, France’s National Institute for Research in Digital Science and Technology, Université Paris Saclay, and Google proposed a method that automatically selects a balanced subset of text or image datasets.
Key insight: A naive way to balance a dataset automatically is to cluster it using k-means to define implicit categories and then draw an equal number of points randomly from the resulting clusters. But this approach tends to form many clusters in areas of the distribution that have more examples, leading to over-representation of certain categories. For instance, when the authors applied k-means to web images and associated the clusters with their nearest neighbors in ImageNet, around 300 clusters (out of 10,000) corresponded to the ImageNet class “website.” However, after clustering, the distribution of the centroids is a bit more uniform than that of the entire dataset. Applying k-means repeatedly distributes the centroids (and thus the clusters) more uniformly. After a number of iterations, each cluster is more likely to represent a distinct category, and selecting equal numbers of examples from each cluster makes a balanced dataset.
How it works: The authors balanced image and text datasets using several iterations of k-means clustering. Their image dataset started with 743 million examples from a “publicly available repository of crawled web data.” For text, they started with CCNet, a version of Common Crawl that was filtered to match the distribution of language and topics found in Wikipedia. The following approach ensured balanced sampling from all levels, maintaining a balance among high-level classes (such as animal, vehicle, and sport) and lower-level subclasses (such as dog, airplane, and football):
- The authors embedded the data. They built an image-embedding model by training a ViT-L (307 million parameters) on ImageNet1k according to the DINOv2 self-supervised training method. To embed text, they used a pretrained SBERT.
- They clustered the data via k-means to produce 10 million clusters.
- They selected a small number of points closest to the centroid of each cluster. Then they applied k-means to the selected points to find new centroids. They repeated this process four times, each time decreasing the number of clusters, so the new clusters represented higher-level categories. With each iteration, the distribution of centroids became more uniform.
- Using the resulting hierarchy of clusters, the authors randomly selected balanced datasets of 100 million images and 210 billion text tokens. Specifically, starting with the highest-level clusters, they computed the number of samples to be drawn from each cluster. Then they looked up which clusters in the previous level were contained within each of the clusters in the current level and determined the number of samples to be drawn from each of these subclusters. They repeated this process at each level. In this way, when they reached the lowest level, they knew how many points to draw randomly from each of the lowest-level clusters. The points they drew made up a balanced dataset.
Results: Both vision and language models that were pretrained on the balanced data outperformed models that were pretrained on the corresponding unbalanced datasets.
- To test their balancing method on image classifiers, the authors pretrained ViT-g models on their balanced dataset and the unbalanced raw data. They froze the trained models and fine-tuned a linear layer on top of them to classify ImageNet. Pretrained on their balanced dataset, ViT-g achieved 85.7 percent accuracy on the ImageNet 1k validation set. Pretrained on the unbalanced dataset, it achieved 85.0 percent accuracy.
- To test their method on language models, they compared performance on various tasks of LLaMA-7B models that were pretrained on their balanced version of 210 billion tokens in CCNet and the unbalanced CCNet. For instance, on the HellaSwag question-answering dataset (zero-shot), the model pretrained on balanced data achieved 52.7 percent accuracy, while the model pretrained on unbalanced data achieved 51.9 percent accuracy. Similarly, on Arc-C (questions about common-sense physics such as the buoyancy of wood, zero-shot), the model pretrained on balanced data achieved 40.1 percent accuracy, while the model pretrained on unbalanced data achieved 35.5 percent accuracy.
Why it matters: The old-school machine learning algorithm k-means can organize quantities of pretraining data that are too large for manual inspection yet crucial to data-hungry models. Breaking down data into clusters also makes it possible to manually inspect cluster elements, which might help identify unwanted data.
We’re thinking: Even in the era of foundation models, data-centric AI — that is, systematically engineering the data used to train such models — remains a critical, often under-appreciated step. This paper offers a promising way to create more balanced datasets. The encouraging results suggest fruitful avenues for further study.