
Dear friends,
Years ago, when I was working at a large tech company, I was responsible for the data warehouse. Every piece of data relating to individual users was supposed to come through the data warehouse, and it was an intellectually challenging undertaking to store the data reliably and make it available to other teams, subject to security and privacy guardrails, so they could use it to derive insights.
I wish that, back then, I (and my whole team) had had access to the Data Engineering Professional Certificate, a major new specialization we just launched on Coursera!
Data underlies all modern AI systems, and engineers who know how to build systems to store and serve it are in high demand. Today, far too many businesses struggle to build a robust data infrastructure, which leads to missed opportunities to create value with data analytics and AI. Additionally, AI’s rise is accelerating the demand for data engineers.
If you’re interested in learning these skills, please check out this four-course sequence, which is designed to make you job-ready as a data engineer.
The Data Engineering Professional Certificate is taught by Joe Reis, co-author of the best-selling book Fundamentals of Data Engineering, in collaboration with Amazon Web Services. (Disclosure: I serve on Amazon's board of directors.) When DeepLearning.AI decided to teach data engineering, I felt that Joe, who has helped many startups and big companies design their data architectures and thus has broad and deep experience in this field, would be the ideal instructor. He was the first person we reached out to, and I was thrilled that he agreed to work with us on this. I hope that you’ll be thrilled, too, taking this specialization!
While building AI systems and analyzing data are important skills, the data that we feed into these systems determines their performance. In this specialization, you’ll go through the whole data engineering lifecycle and learn how to generate, ingest, store, transform, and serve data. You’ll learn how to make necessary tradeoffs between speed, flexibility, security, scalability, and cost.
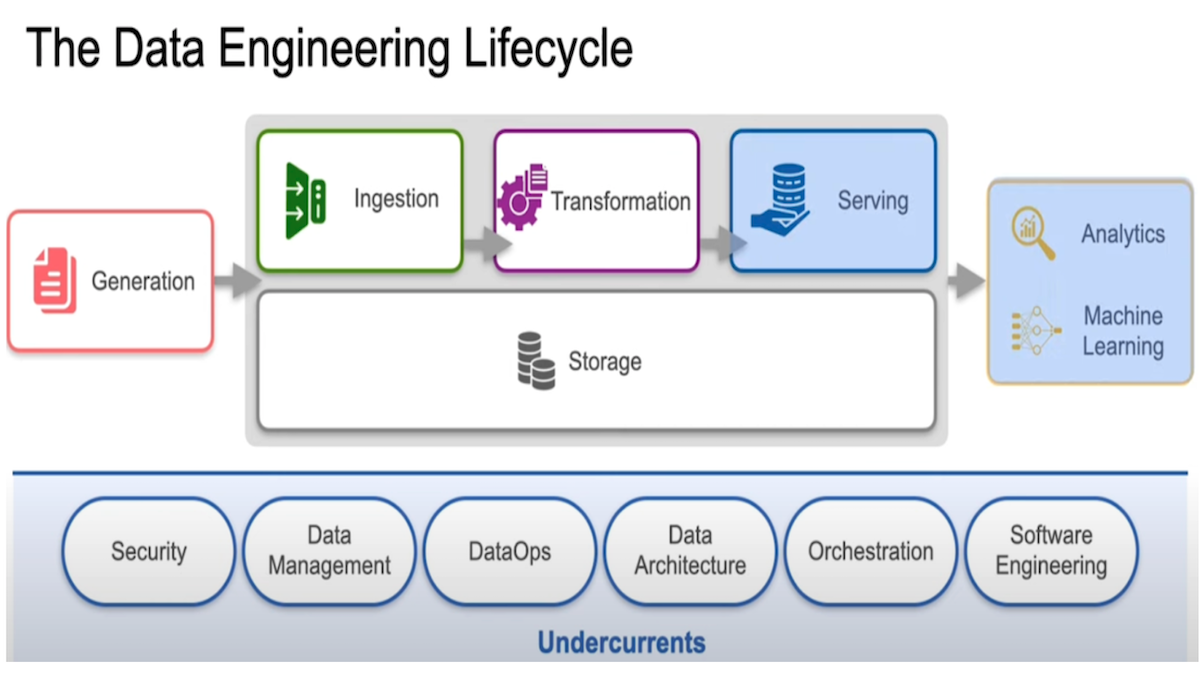
If you’re a software engineer, this will give you a deeper understanding of data engineering so that you can build data applications. If you’re an aspiring or practicing data scientist or AI/machine learning engineer, you’ll learn skills that expand your scope to manage data in a more sophisticated way. For example, you’ll learn about DataOps to automate and monitor your data pipelines, and how to build “infrastructure as code” to programmatically define, deploy, and maintain your data infrastructure, as well as best practices for data-centric AI.
You’ll also hear 17 other industry leaders share their wisdom about effective data engineering. Bill Inmon, the father of data warehousing, shares fascinating stories about the evolution of the data warehouse, including how he wrote his first program as a student in 1965. Wes McKinney, creator of the Python pandas package (as in “import pandas as pd”), talks about how he designed this wildly popular package and shares best practices for data manipulation. These instructors will give you a mental framework for developing and deploying data systems.
Getting your data infrastructure right is a valuable foundational skill that will serve you well in whatever you do with AI or data analytics. I hope you enjoy this specialization!
Keep learning,
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Learn the principles of data engineering with our four-course professional certificate taught by Joe Reis. Develop skills throughout the data engineering lifecycle and gain hands-on experience building systems on Amazon Web Services. Earn a certificate upon course completion! Enroll today
News
OpenAI o1 Forges Chains of Thought
Preliminary versions of OpenAI’s new model family were trained explicitly to think step-by-step, yielding outstanding marks in math, science, and coding — but users can’t see their reasoning steps.
What’s new: OpenAI launched beta versions of o1-preview and o1-mini, language models that were trained via reinforcement learning to use chains of thought. The models are available to paid ChatGPT users as well as API customers who have been onboard for more than 30 days and spent $1,000. o1-preview costs $15/$60 per million input/output tokens, significantly higher than GPT-4o’s price of $5/$15. o1-mini costs $3/$12 per million input/output tokens. OpenAI didn’t announce a release date for a finished o1 model.
How it works: o1-preview is a preliminary release, and o1-mini is a faster preliminary version that’s particularly effective at coding. OpenAI published an o1 system card but hasn’t disclosed details about the new models’ size, architecture, or training. Both models have an input context window of 128,000 tokens. They accept only text tokens, but OpenAI plans to support other media types in future versions.
- o1-preview and o1-mini were trained on data scraped from the web, open-source databases, and proprietary data supplied by partners and OpenAI. The reinforcement learning process rewarded the models for generating desired reasoning steps and for their alignment with human values, goals, and expectations.
- The beta models process “reasoning tokens” that the company charges for as though they were output tokens although they’re invisible to users. The use of reasoning tokens makes the models slower and costlier to produce output than GPT-4o, but they deliver superior performance in tasks that benefit from step-by-step reasoning. OpenAI provides an example in which o1-preview deciphered enciphered text in which each letter is replaced by two letters that, according to alphabetical order, are equidistant from the intended letter. In other examples, it calculates the pH of a solution of ammonium fluoride and suggests a medical diagnosis based on symptoms that are present and absent.
- o1-preview’s output is limited to around 32,768 tokens, including reasoning tokens, while o1-mini’s is capped at roughly 65,536. OpenAI recommends budgeting 25,000 tokens for reasoning.
- OpenAI keeps the chain of thought hidden to avoid exposing information that wasn’t requested. In addition, it doesn’t want users to try to control the model’s reasoning, and it doesn’t want competitors to see what’s going on behind the scenes. (Nonetheless, ChatGPT users can see a summary of steps that led to a given response)
- OpenAI and third parties conducted safety evaluations, including testing for inappropriate outputs, race, gender, and age biases, and harmful chains of thought. o1-preview and o1-mini returned fewer hallucinations and showed more resistance to jailbreaking attacks than GPT-4o and GPT-4o mini. Both models show a higher risk than previous OpenAI models of helping to produce biological threats, but the risk is within the bounds of its safety policy.
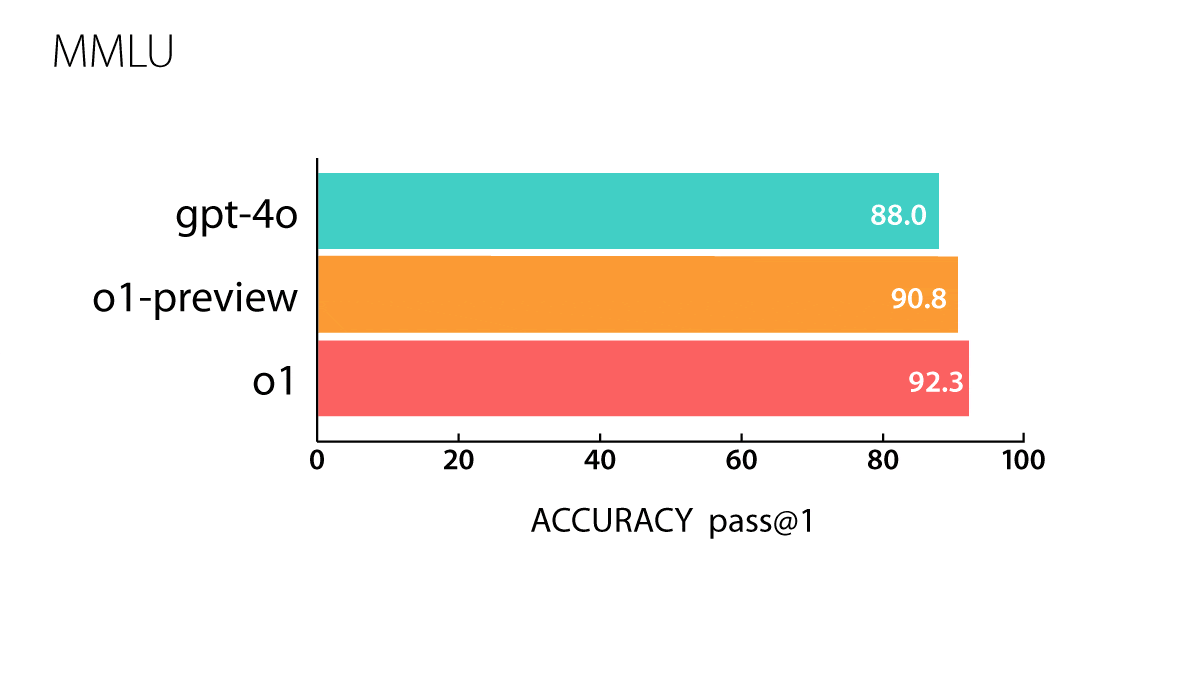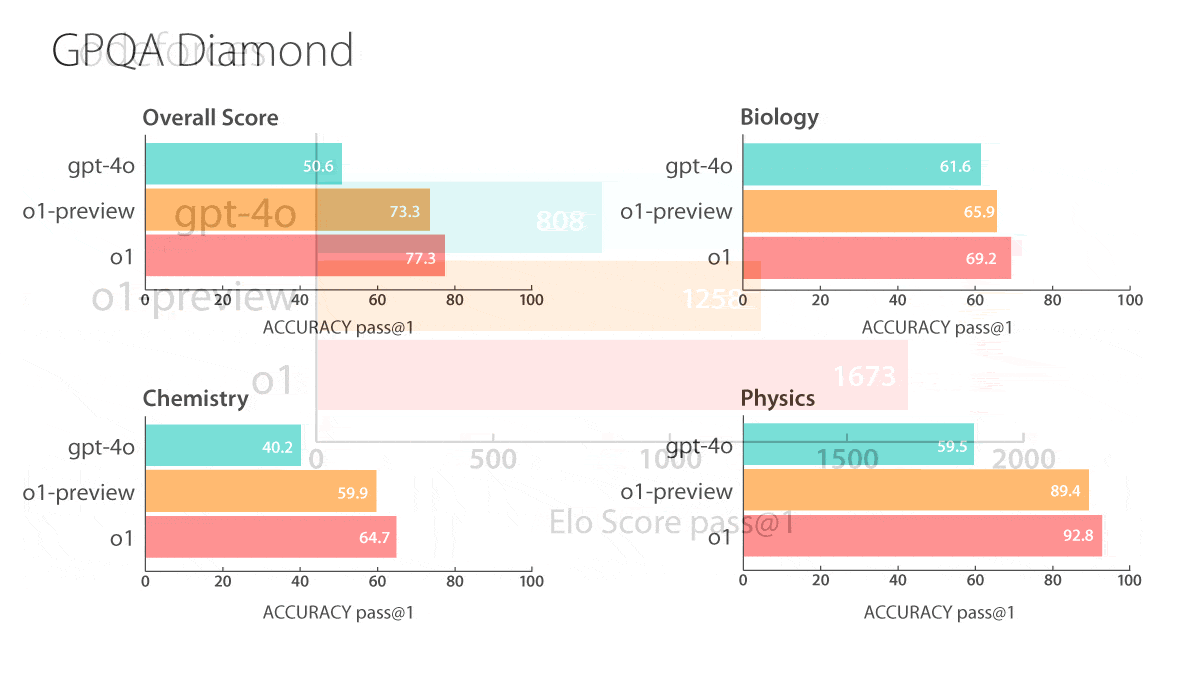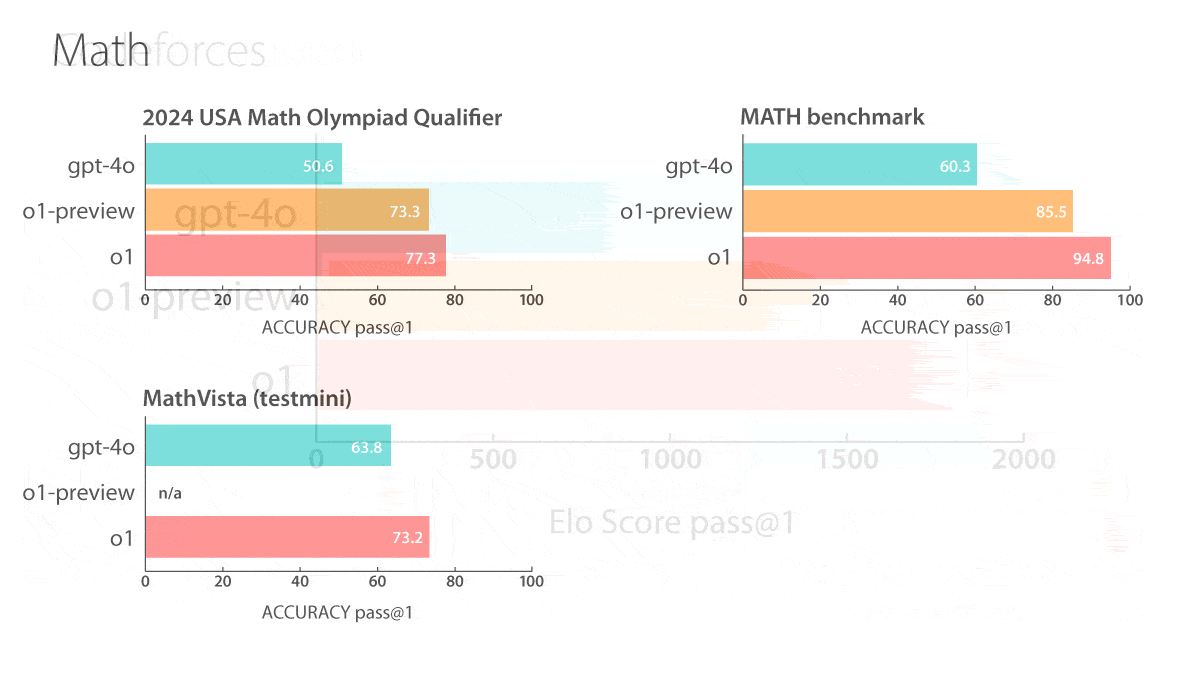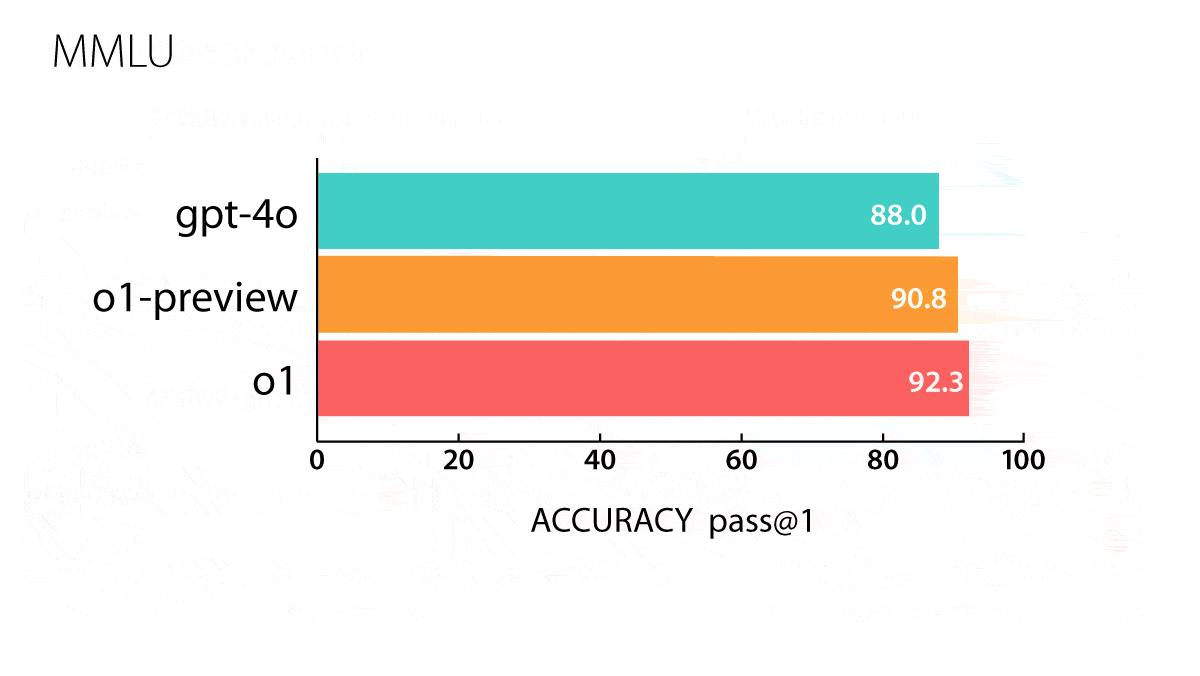
Results: The actual o1 model — which remains unavailable — generally outperforms o1-preview, while both vastly outperform GPT-4o on math, science, and coding benchmarks.
- o1: The forthcoming model outperformed GPT-4o on 54 out of 57 MMLU subcategories that test knowledge in fields like elementary mathematics, U.S. history, and law. It achieved an Elo score of 1,673 on coding contests drawn from the website Codeforces (in which it was allowed 10 submissions for any given problem), putting it in the 89th percentile (human expert level). On the GPQA Diamond tests of graduate-level knowledge in biology, chemistry, and physics, it scored higher than PhD-level experts recruited by OpenAI. It correctly answered 74 percent of questions from the 2024 USA Math Olympiad qualifier.
- o1-preview: The preview version ranked in the 62nd percentile on Codeforces. Human evaluators preferred its output to that of GPT-4o in response to prompts that tested coding, data analysis, and math. (They preferred GPT-4o’s responses to prompts that requested “personal writing.”)
Behind the news: In recent months, Anthropic has been using the tag <antThinking> to generate thinking tokens that are hidden from users. However, OpenAI’s implementation in the o1 models takes this capability much further.
Why it matters: The o1 models show that the combination of reinforcement learning and chain-of-thought reasoning can solve problems that large language models generally find challenging. They’re substantially more accurate in domains such as coding, math, and science that have low tolerance for error. However, the fact that the models hide their reasoning from users makes them less transparent and explainable than their predecessors and may make their outstanding performance less valuable in some applications.
We’re thinking: Agentic workflows can significantly improve a system’s ability to reflect, reason, and iterate on its output. Training a model to take such steps directly in response to even general-purpose questions opens an exciting alternative path to better reasoning beyond simply scaling up model size.
High Gear for Llama 3.1 405B
SambaNova raised the speed limit for access to the largest model in the Llama 3.1 family — and it’s free.
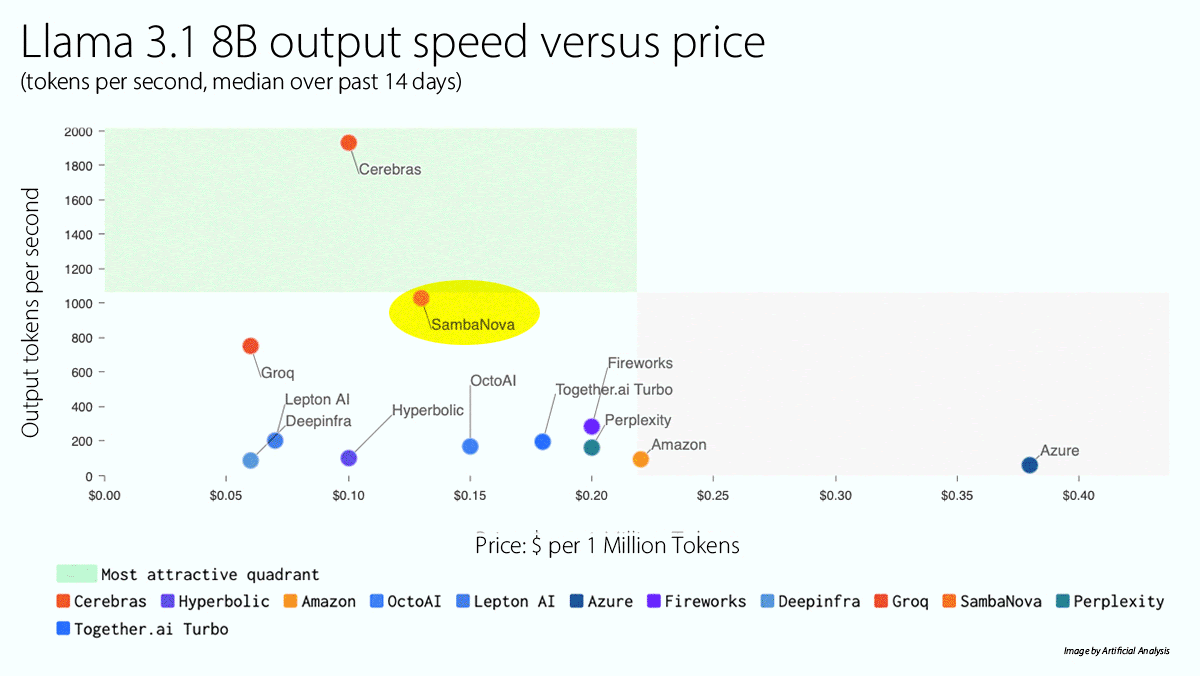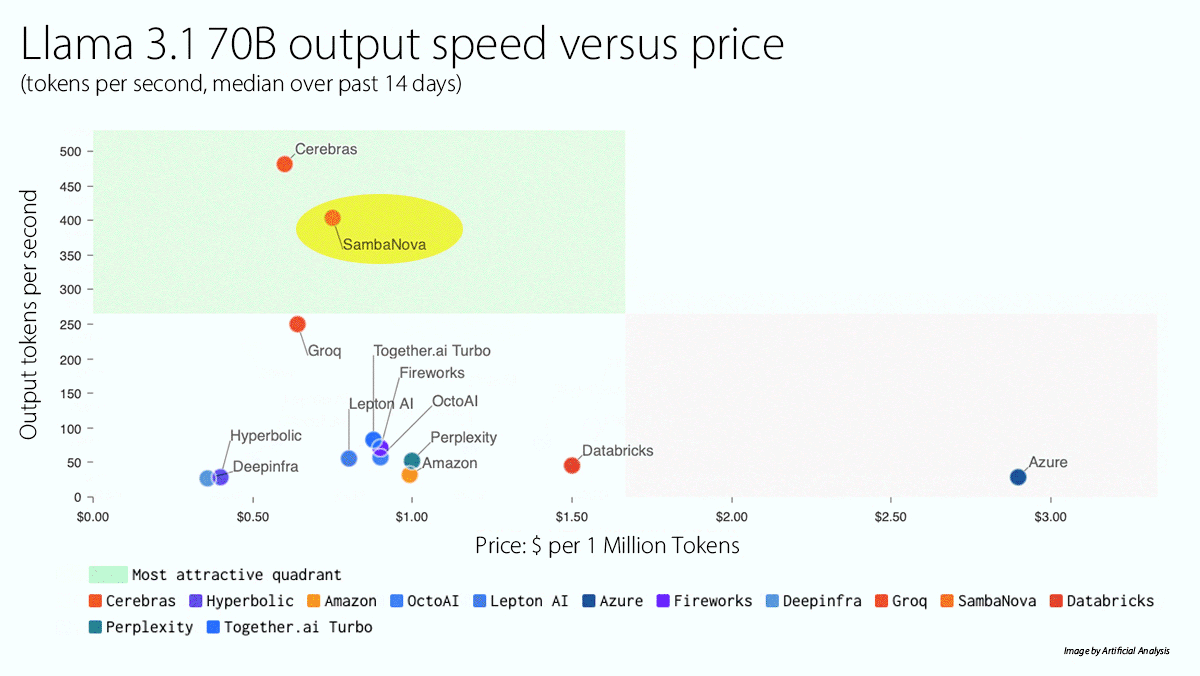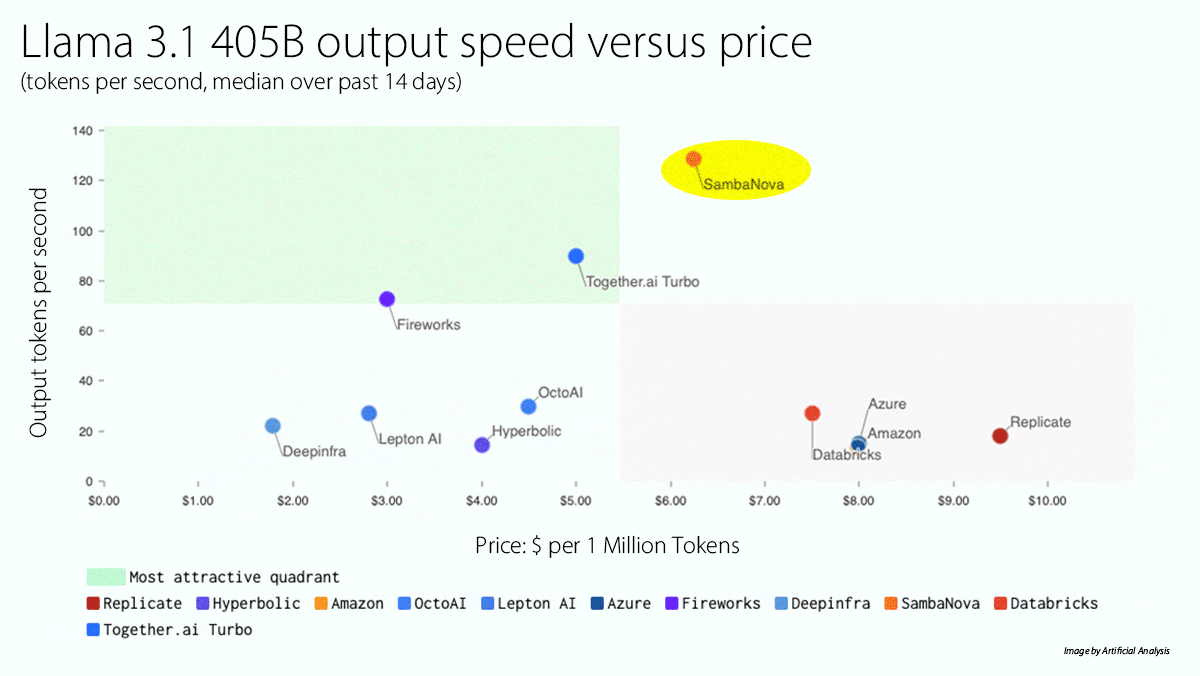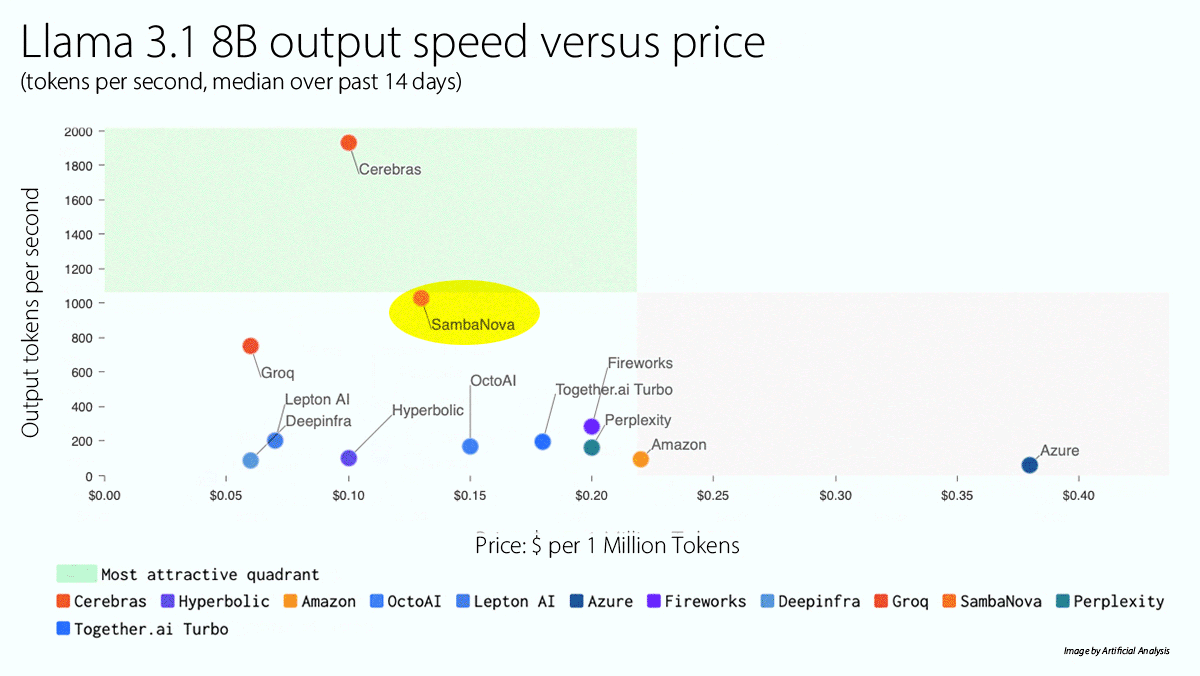
What’s new: SambaNova launched a cloud service that runs Llama 3.1 405B significantly faster than competitors. A free tier is available, to be followed later this year by paid tiers that offer higher rate limits.
How it works: SambaNova uses proprietary chips and software to accelerate model inference.
- The platform enables Llama 3.1 405B to generate 129 tokens per second (the fastest on the market) for $5/$10 per million input/output tokens. It enables Llama 3.1 70B to generate 411 tokens per second (behind Cerebras, which costs somewhat less) for $0.60/$1.20 per million input/output tokens, and Llama 3.1 8B to generate 998 tokens per second (also behind Cerebras, which offers a slightly lower price) for $0.10/$0.20 per million input/output tokens, according to Artificial Analysis. SambaNova’s own testing shows 132 tokens per second for Llama 3.1 405B and 461 tokens per second for Llama 3.1 70B.
- Unlike some competitors, SambaNova runs Llama 3.1 at 16-bit precision (technically bf16/fp32 mixed precision). Models that process at lower precision can achieve higher speeds or run on less powerful hardware but lose accuracy.
Yes, but: SambaNova currently limits Llama 3.1’s context window to around 8,000 tokens, much less than the model’s native 128,000 tokens.
Behind the news: The new service arrives amid a broader competition to deliver fast inference among cloud providers that have developed their own specialized chips. Competitors like Cerebras and Groq have introduced their own high-speed inference services.
Why it matters: Throughput, cost, performance, and latency are critical factors in practical applications of AI models. Fast inference allows for more frequent API calls without bogging down time to output, which is essential for agentic workflows and real-time decision making.
We’re thinking: Models with open weights are now served faster than proprietary models and are nearly as capable. This may spur further adoption of open models as well as prompting strategies, such as agentic workflows, that require large numbers of output tokens.

Amazon Boosted by Covariant
Amazon took on talent and technology from robotics startup Covariant to enhance its warehouse automation, an area critical to its core ecommerce business.
What’s new: Amazon announced an agreement to hire Covariant’s cofounders and other key personnel and license its models. Financial terms were not disclosed. (Disclosure: Andrew Ng is a member of Amazon’s board of directors.)
How it works: The new deal echoes Amazon’s previous not-quite acquisition of Adept as well as similar arrangements between other tech giants and startups.
- Amazon received a non-exclusive license to Covariant’s RFM-1, a model that enables robots to follow commands given as text or images, answer questions, and request further instructions. The deal will scale up Covariant’s installed base by several orders of magnitude: Covariant maintains hundreds of robots, while Amazon has over 750,000.
- Covariant CEO Peter Chen, CTO Rocky Duan, Chief Scientist Pieter Abbeel — all of whom are co-founders of the company — joined Amazon. Roughly a quarter of Covariant’s current staff moved to Amazon as well. The new hires will implement Covariant’s models in Amazon’s robots and work on fundamental AI research and human-robot interaction.
- Ted Stinson, previously Covariant’s COO, will lead the company as the new CEO alongside remaining co-founder Tianhao Zhang. Covariant will continue to serve existing customers in industries beyond ecommerce, including fulfillment and distribution, apparel, grocery, health and beauty, and pharmaceuticals, the company said.
Behind the news: Amazon has been working to acquire technical talent and technology for some time. In 2022, it announced that it would acquire iRobot, but the companies abandoned that plan earlier this year after EU regulators blocked the deal citing antitrust concerns. In October, it committed to invest as much as $4 billion in Anthropic in return for access to the startup’s technology. (UK regulatory authorities subsequently announced an antitrust probe into Amazon’s relationship with Anthropic.) In July, it signed a hire-and-license deal — similar to its agreement with Covariant — with agentic AI startup Adept.
Why it matters: Competition among AI giants continues to heat up. Amazon’s agreement with Covariant mirrors other deals in which a tech giant gained top talent and technology without formally acquiring a startup, including Microsoft’s arrangement with Inflection and Google’s deal with Character.AI. These developments highlight top tech companies’ race to secure their AI positions — and the fact that outright acquisitions invite regulatory scrutiny.
We’re thinking: Robotic foundation models that are trained on large amounts of unlabeled robotics data offer a promising way to quickly fine-tune robots to perform new tasks — potentially a major upgrade in warehouse logistics.

Reducing Memorization in LLMs
Studies have established that large language models can memorize the text passages they’ve been trained on repeatedly and regurgitate them when prompted in adversarial and, though rarely, in benign ways. Researchers proposed a way to reduce this tendency and attendant risks to intellectual property and privacy.
What’s new: Abhimanyu Hans and colleagues from University of Maryland introduced the goldfish loss, a modification of the next-token-prediction loss function typically used in large language models. The goldfish loss avoids memorization of long passages by masking some tokens during the loss computation.
Key insight: Certain passages may appear many times during training, either because the model takes multiple passes over data or because they’re duplicated in the training corpus. Randomly masking individual tokens from the loss computation doesn’t prevent a model from memorizing repeated passages because the model, over many repetitions, still sees every word and its place in the order. But masking a long passage the same way with every repetition ensures the model can’t memorize the passage regardless of the number of repetitions.
How it works: The goldfish loss masks the current token from the loss computation based on previous tokens. A deterministic hashing function decides which tokens to mask effectively at random the first time it encounters a particular 13-token sequence, but identically if it encounters the same sequence again. At a high level, it masks a certain percentage of tokens, typically one in three or four. The authors compared the goldfish loss to the next-token-prediction loss function in two settings: one that mimicked a typical training process and one that made memorization more likely.
- For the typical training process, the authors trained TinyLLaMa-1.1B for one epoch on a subset of RedPajama, a de-duplicated dataset of text scraped from the web. To provide duplicate text, they added 2,000 sequences from Wikipedia, each repeated 50 times.
- To promote memorization, they fine-tuned a pretrained Llama 2 7B for 100 epochs on 100 Wikipedia articles.
Results: The authors assessed the results using two metrics: (i) ROUGE-L, which falls between 0 and 100 percent and reflects the longest subsequence in common between ground-truth and generated data, and (ii) the percentage of tokens that exactly matched the original text in proper order. Both measure memorization, so lower scores are better.
- In the typical setting, the model trained using the next-token-prediction loss memorized heavily, while the model trained with the goldfish loss memorized just a little bit.
- In the setting that promoted memorization, the model trained using the next-token-prediction loss exactly matched 85 percent of the tokens in the Wikipedia articles and achieved 96 percent ROUGE-L. The model using the goldfish loss exactly matched 0 percent of the Wikipedia tokens and achieved 51 percent ROUGE-L.
- Both models achieved similar performance on six common-sense reasoning and question answering tasks, indicating that the goldfish loss didn’t hinder the accuracy on those tasks.
Why it matters: Businesses are worried about whether using LLMs poses risks to intellectual property rights and privacy. Techniques that address this concern without significantly impacting performance are welcome.
We’re thinking: Memorization also happens in models generating images. We look forward to research into using similar techniques in that domain.