
Dear friends,
Congratulations to Geoff Hinton and John Hopfield for winning the 2024 Physics Nobel Prize! It’s wonderful to see pioneering work in AI recognized, and this will be good for our whole field. Years ago, I was the first to call Geoff the “Godfather of Deep Learning,” which later became “Godfather of AI.” I’m thrilled at the recognition he’s receiving via this most prestigious of awards.
As Geoff relayed in the “Heroes of Deep Learning” interview I did with him years ago, his early work developing the foundations of neural networks has been instrumental to the rise of deep learning and AI. It has been years since I implemented a Hopfield network, but John’s work, too, has been influential. Their recognition is well deserved!
But the Nobel committee wasn’t done yet. One day after the physics prize was announced, Demis Hassabis, John Jumper, and David Baker won the Chemistry Nobel Prize for their work on AlphaFold and protein design. AlphaFold and AlphaFold 2, as well as the work of Baker’s lab, are compelling applications of AI that made significant steps forward in chemistry and biology, and this award, too, is well deserved!
It’s remarkable that the Nobel committees for physics and chemistry, which are made up of scientists in those fields, chose to honor AI researchers with this year’s awards. This is a sign of our field’s growing impact on society.

While it’s good that people from outside AI are recognizing AI researchers, I wonder if there’s room for the AI community to pick more award recipients ourselves. Best-known in computer science is the Turing Award, which is selected by a broad group of computer scientists, many of whom have deep AI knowledge. Many AI conferences give out best-paper awards. And applications of AI to other fields doubtless will continue to receive much-deserved recognition by leaders in those fields. I’m optimistic this will allow AI researchers to win more Nobel Prizes — someday also in economics, literature, medicine, and peace, too. Nonetheless, this seems like a good time to see how all of us in AI can do more to recognize the work of innovators in our field.
Geoff once thanked me for my role in getting him anointed “Godfather of AI,” which he said was good for his career. I didn’t realize before that I had the power to give out such titles 😉 but I would love for there to be numerous godfathers and godmothers — and many other awards — in AI!
At Geoff's retirement party last October (pictured in the photo above), I spoke with affection and gratitude for all the work he has done to grow AI. Even as we cheer the new Nobel wins for AI, let’s continue to think about how we in AI can do more to celebrate the next generation of innovators.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Try the new capabilities of Llama 3.2 in our latest course with Meta. Learn how to compose multimodal prompts, call custom tools, and use the Llama Stack API to build applications with Meta’s family of open weights models. Enroll for free!
News

Familiar Faces, Synthetic Soundtracks
Meta upped the ante for text-to-video generation with new systems that produce consistent characters and matching soundtracks.
What’s new: Meta presented Movie Gen, a series of four systems that generate videos, include consistent characters, alter generated imagery, and add matching sound effects and music. Movie Gen will be available on Instagram in 2025. Meanwhile, you can view and listen to examples here. The team explains how the model was built an extensive 92-page paper.
Generated videos: Movie Gen Video can output 256 frames (up to 16 seconds at 16 frames per second) at 1920x1080-pixel resolution. It includes a convolutional neural network autoencoder, transformer, and multiple embedding models.
- Movie Gen Video produces imagery by flow matching, a technique related to diffusion. It learned to remove noise from noisy versions of images and videos given matching text descriptions from 1 billion image-text pairs and 100 million video-text pairs. At inference, it starts with pure noise and generates detailed imagery according to a text prompt.
- The system concatenates multiple text embeddings to combine the strengths of different embedding models. UL2 was trained on text-only data, so its embeddings may provide “reasoning abilities,” according to the authors. Long-prompt MetaCLIP was trained to produce similar text and image representations, so its embeddings might be useful for “cross-modal generation.” ByT5 produces embeddings of individual text elements such as letters, numbers, and symbols; the system uses it when a prompt requests text within a clip.
Consistent characters: Given an image of a face, a fine-tuned version of Movie Gen Video generates a video that depicts a person with that face.
- To gather a training dataset for this capability, the team filtered Movie Gen Video’s pretraining dataset for clips that show a single face and consecutive frames are similar to one another. They built video-face examples by pairing each clip with a frame selected from the clip at random. To train the system, the team fed it text, the clip with added noise, and the single-frame face. It learned to remove the noise.
- Trained on this data alone, the system generated videos in which the person always faces the camera. To expand the variety of poses, they further trained it on examples that substituted the faces in the previous step with generated versions with alternate poses and facial expressions.
Altered clips: The team modified Movie Gen Video’s autoencoder to accept an embedding of an alteration — say, changing the background or adding an object. They trained the system to alter videos in three stages:
- First, they trained the system, given a starting image and an instruction to alter it, to produce an altered image.
- They further trained the system to produce altered clips. They generated two datasets of before-and-after clips based on instructions. (i) For instance, given a random frame and an instruction to, say, replace a person with a cat, the system altered the frame accordingly. Then the team subjected both frames to a series of augmentations selected at random, creating matching clips, one featuring a person, the other featuring a cat. Given the initial clip and the instruction, the system learned to generate the altered clip. (ii) The team used DINO and SAM 2 to segment clips. Given an unsegmented clip and an instruction such as “mark <object> with <color>,” the system learned to generate the segmented clip.
- Finally, they trained the system to restore altered clips to their original content. They built a dataset by taking a ground-truth clip and using their system to generate an altered version according to an instruction. Then Llama 3 rewrote the instruction to modify the altered clip to match the original. Given the altered clip and the instruction, the system learned to generate the original clip.
Synthetic soundtracks: Given a text description, a system called Movie Gen Audio generates sound effects and instrumental music for video clips up to 30 seconds long. It includes a DACVAE audio encoder (which encodes sounds that comes before and/or after the target audio), Long-prompt MetaCLIP video encoder, T5 text encoder, vanilla neural network that encodes the current time step, and transformer.
- Movie Gen Audio learned to remove noise from noisy versions of audio associated with 1 million videos with text captions. At inference, it starts with pure noise and generates up to 30 seconds of audio at once.
- At inference, it can extend audio. Given the last n seconds of audio, the associated portion of a video, and a text description, it can generate the next 30 - n seconds.
Results: Overall, Movie Gen achieved performance roughly equal to or better than competitors in qualitative evaluations of overall quality and a number of specific qualities (such as “realness”). Human evaluators rated their preferences for Movie Gen or a competitor. The team reported the results in terms of net win rate (win percentage minus loss percentage) between -100 percent and 100 percent, where a score above zero means that a system won more than it lost.
- For overall video quality, Movie Gen achieved a net win rate of 35.02 percent versus Runway Gen3, 8.23 percent versus Sora (based on the prompts and generated clips available on OpenAI’s website), and 3.87 percent versus Kling 1.5.
- Generating clips of specific characters, Movie Gen achieved a net win rate of 64.74 percent versus ID-Animator, the state of the art for this capability.
- Generating soundtracks for videos from the SReal SFX dataset, Movie Gen Audio achieved a net win rate between 32 percent and 85 percent compared to various video-to-audio models.
- Altering videos in the TGVE+ dataset, Movie Gen beat all competitors more than 70 percent of the time.
Why it matters: With Movie Gen, table stakes for video generation rises to include consistent characters, soundtracks, and various video-to-video alterations. The 92-page paper is a valuable resource for builders of video generation systems, explaining in detail how the team filtered data, structured models, and trained them to achieve good results.
We’re thinking: Meta has a great track record of publishing both model weights and papers that describe how the models were built. Kudos to the Movie Gen team for publishing the details of this work!

Voice-to-Voice and More for GPT-4o API
OpenAI launched a suite of new and updated tools to help AI developers build applications and reduce costs.
What’s new: At its annual DevDay conference, OpenAI introduced an API for speech processing using GPT-4o, distillation tools, vision fine-tuning capabilities, and the ability to cache prompts for later re-use. These tools are designed to make it easier to build fast applications using audio inputs and outputs, customize models, and cut costs for common tasks.
Development simplified: The new offerings aim to make it easier to build applications using OpenAI models, with an emphasis on voice input/output and image input, customizing models, and resolving common pain points.
- The Realtime API enables speech-to-speech interactions with GPT-4o using six preset voices, like ChatGPT's Advanced Voice Mode but with lower latency. The API costs $100/$200 per 1 million input/output tokens (about $0.06/$0.24 per minute of input/output). (The API processes text at $5/$20 per million input/output tokens.
- The Chat Completions API now accepts voice input and generates voice outputs for GPT-4o’s usual price ($3.75/$15 per million input/output tokens). However, it generates outputs less quickly than the Realtime API. (OpenAI didn’t disclose specific latency measurements.)
- The distillation tools simplify the process of using larger models like o1-preview as teachers whose output is used to fine-tune smaller, more cost-efficient students like GPT-4o mini. Developers can generate datasets, fine-tune models, and evaluate performance within OpenAI's platform. For example, you can use GPT-4o to create responses to customer-service questions, then use the resulting dataset to fine-tune GPT-4o mini.
- Vision fine-tuning allows developers to enhance GPT-4o's image understanding by fine-tuning the model on a custom image dataset. For instance, developers can improve visual search, object detection, or image analysis for a particular application by fine-tuning the model on domain-specific images. Vision fine-tuning costs $25 per million training tokens for GPT-4o, but OpenAI will give developers 1 million free training tokens per day through October 31.
- Prompt caching automatically reuses input tokens that were entered in recent interactions with GPT-4o, GPT-4o mini, and their fine-tuned variants. Repeated prompts cost half as much and get processed faster. The discount and speed especially benefit applications like chatbots and code editors, which frequently reuse input context.
Behind the news: OpenAI is undertaking a major corporate transformation. A recent funding round values OpenAI at $157 billion, making it among the world’s most valuable private companies, and the company is transferring more control from its nonprofit board to its for-profit subsidiary. Meanwhile, it has seen an exodus of executives that include CTO Mira Murati, Sora co-lead Tim Brooks, chief research officer Bob McGrew, research VP Barret Zoph, and other key researchers.
Why it matters: The Realtime API enables speech input and output without converting speech to text, allowing for more natural voice interactions. Such interactions open a wide range of applications, and they’re crucial for real-time systems like customer service bots and virtual assistants. Although Amazon Web Service and Labelbox provide services to distill knowledge from OpenAI models into open architectures, OpenAI’s tools ease the process of distilling from OpenAI models into other OpenAI models. Image fine-tuning and prompt caching, like similar capabilities for Anthropic Claude and Google Gemini, are welcome additions.
We’re thinking: OpenAI’s offerings have come a long way since DevDay 2023, when speech recognition was “coming soon.” We’re eager to see what developers do with voice-driven applications!

German Court: LAION Didn’t Violate Copyrights
A German court dismissed a copyright lawsuit against LAION, the nonprofit responsible for large-scale image datasets used to train Midjourney, Stable Diffusion, and other image generators.
What’s new: The court rejected a lawsuit claiming that cataloging images on the web to train machine learning models violates the image owners’ copyrights. It ruled that LAION’s activities fall under protections for scientific research.
How it works: LAION doesn’t distribute images. Instead, it compiles links to images and related text that are published on publicly available websites. Model builders who wish to use the images and/or text must download them from those sources. In 2023, photographer Robert Kneschke sued LAION for including his photos. The court’s decision emphasized several key points.
- LAION, while compiling links to images, had indeed made unauthorized copies of images protected by copyright, as defined by German law. However, Germany’s Copyright Act allows unauthorized use of copyrighted works for scientific research. The court ruled that LAION had collected the material for this purpose, so it did not violate copyrights.
- Moreover, the court found that downloading images and text in order to correlate them likely fell under a further exemption to copyright for data mining. This finding wasn’t definitive because the exemption for research made it irrelevant, but the court mentioned it to help guide future rulings.
- The dataset’s noncommercial status was a key factor in the ruling. LAION distributed the dataset for free, and no commercial entity controlled its operations. Although a LAION dataset may be used to train a machine learning model that’s intended to be sold commercially, this is not sufficient to classify creating such datasets as commercial activity. The plaintiff contended that, because some LAION members have paid roles in commercial companies, LAION could be considered a commercial entity. However, the court rejected that argument.
Behind the news: Several other artists have sued LAION, which stands for Large-scale AI Open Network, claiming that the organization used their works without their consent. They have also sued AI companies, including a class action suit against Stability AI, Midjourney, and DeviantArt for using materials under copyright, including images in LAION’s datasets, to train their models. Similar cases have been brought against makers of music generators and coding assistants. All these lawsuits, which are in progress, rest on the plaintiff’s claim that assembling a training dataset of copyrighted works infringes copyrights.
Why it matters: The German ruling is the first AI-related decision in Europe since the adoption of the AI Act, and the court took that law’s intent into account when making its decision. It affirms that creating text-image pairs of publicly available material for the purpose of training machine learning models does not violate copyrights, even if commercial organizations later use the data. However, the court did not address whether training AI models on such datasets, or using the trained models in a commercial setting, violates copyrights.
We’re thinking: This decision is encouraging news for AI researchers. We hope jurisdictions worldwide establish that training models on media that’s available on the open web is fair and legal.
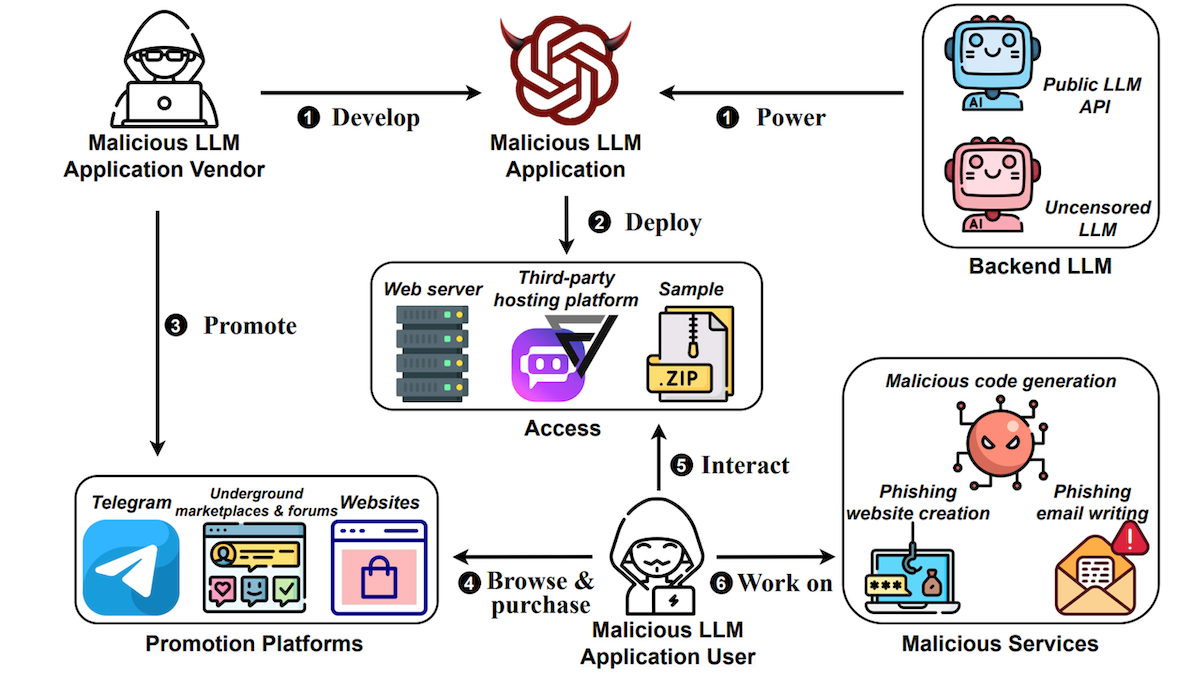
AI’s Criminal Underground Revealed
Researchers probed the black market for AI services that are designed to facilitate cybercrime.
What’s new: Zilong Lin and colleagues at Indiana University Bloomington studied how large language models (LLMs) are used to provide harmful services, specifically generating malicious code, phishing emails, and phishing websites. They weren’t very effective, by and large (though a high success rate may not be necessary to support a thriving market in automated criminal activity).
Risky business: Providers base such services on either uncensored LLMs — that is, those that weren’t fine-tuned to reflect human preferences or don’t employ input/output filters — or publicly available models that they prompt using jailbreak techniques that circumvent built-in guardrails. They sell their services in hacker’s marketplaces and forums, charging far less than typical traditional malware vendors, but services based on models that have been fine-tuned to deliver malicious output command a premium. The authors found that one service generated revenue of more than $28,000 in two months.
Sprawling market: The authors identified 212 harmful services. Of those, 125 were hosted on the Poe AI platform, 73 were on FlowGPT, and the remaining 14 resided on unique servers. Of those, the authors were unable to access five because either the provider blocked them, or the service was fraudulent. They identified 11 LLMs used by these services including Claude-2-100k, GPT-4, and Pygmalion-13B (a variant of LLaMA-13B).
Testing output quality: The authors prompted more than 200 services using over 30 prompts to generate malicious code, phishing emails, or phishing websites. They evaluated the responses according to:
- Format: How often they followed the expected format (as defined by regular expressions)
- Compilability: How often generated Python, C, or C++ code was able to compile
- Validity: How often generated HTML and CSS ran successfully in both Chrome and Firefox
- Readability: How often generated phishing emails were fluent and coherent according to the Gunning fog Index of reading difficulty
- Evasiveness, or how often generated text both succeeded in all previous checks and evaded detection by VirusTotal (for malicious code and phishing sites) or OOPSpam (for phishing emails).
In all three tasks, at least one service achieved evasiveness of 67 percent or higher, while the majority of services achieved an evasiveness of less than 30 percent.
Testing real-world effectiveness: In addition, the authors ran practical tests to see how well the output worked in real-world situations. They prompted nine services to generate code that would target three specific vulnerabilities that relate to buffer overflow and SQL injection. In these tests, the models were markedly less successful.
- The authors tested generated code for two vulnerabilities on VICIdial, a call-center system known to be vulnerable to such issues. Of 22 generated programs that were able to compile, none changed VICIdial’s databases or disclosed system data.
- They tested generated code further on OWASP WebGoat 7.1, a website that provides code with known security flaws. Of 39 generated programs that were able to compile, seven launched successful attacks. However, these attacks did not target the specific vulnerabilities requested by the authors.
Why it matters: Previous work showed that LLMs-based services could generate misinformation and other malicious output, but little research has probed their actual use in cybercrime. This work evaluates their quality and effectiveness. In addition, the authors released the prompts they used to circumvent guardrails and generate malicious output — a resource for further research that aims to fix such issues in future models.
We’re thinking: It’s encouraging to see that harmful services didn’t get far in real-world tests, and the authors' findings should put a damper on alarmist scenarios of AI-enabled cybercrime. That doesn’t mean we don’t need to worry about harmful applications of AI technology. The AI community has a responsibility to design its products to be beneficial and evaluate them thoroughly for safety.