
Dear friends,
Large language models (LLMs) are typically optimized to answer peoples’ questions. But there is a trend toward models also being optimized to fit into agentic workflows. This will give a huge boost to agentic performance!
Following ChatGPT’s breakaway success at answering questions, a lot of LLM development focused on providing a good consumer experience. So LLMs were tuned to answer questions (“Why did Shakespeare write Macbeth?”) or follow human-provided instructions (“Explain why Shakespeare wrote Macbeth”). A large fraction of the datasets for instruction tuning guide models to provide more helpful responses to human-written questions and instructions of the sort one might ask a consumer-facing LLM like those offered by the web interfaces of ChatGPT, Claude, or Gemini.
But agentic workloads call on different behaviors. Rather than directly generating responses for consumers, AI software may use a model in part of an iterative workflow to reflect on its own output, use tools, write plans, and collaborate in a multi-agent setting. Major model makers are increasingly optimizing models to be used in AI agents as well.
Take tool use (or function calling). If an LLM is asked about the current weather, it won’t be able to derive the information needed from its training data. Instead, it might generate a request for an API call to get that information. Even before GPT-4 natively supported function calls, application developers were already using LLMs to generate function calls, but by writing more complex prompts (such as variations of ReAct prompts) that tell the LLM what functions are available and then have the LLM generate a string that a separate software routine parses (perhaps with regular expressions) to figure out if it wants to call a function.
Generating such calls became much more reliable after GPT-4 and then many other models natively supported function calling. Today, LLMs can decide to call functions to search for information for retrieval-augmented generation (RAG), execute code, send emails, place orders online, and much more.

Recently, Anthropic released a version of its model that is capable of computer use, using mouse-clicks and keystrokes to operate a computer (usually a virtual machine). I’ve enjoyed playing with the demo. While other teams have been prompting LLMs to use computers to build a new generation of RPA (robotic process automation) applications, native support for computer use by a major LLM provider is a great step forward. This will help many developers!
As agentic workflows mature, here is what I am seeing:
- First, many developers are prompting LLMs to carry out the agentic behaviors they want. This allows for quick, rich exploration!
- In a much smaller number of cases, developers who are working on very valuable applications will fine-tune LLMs to carry out particular agentic functions more reliably. For example, even though many LLMs support function calling natively, they do so by taking as input a description of the functions available and then (hopefully) generating output tokens to request the right function call. For mission-critical applications where generating the right function call is important, fine-tuning a model for your application’s specific function calls significantly increases reliability. (But please avoid premature optimization! Today I still see too many teams fine-tuning when they should probably spend more time on prompting before they resort to this.)
- Finally, when a capability such as tool use or computer use appears valuable to many developers, major LLM providers are building these capabilities directly into their models. Even though OpenAI o1-preview’s advanced reasoning helps consumers, I expect that it will be even more useful for agentic reasoning and planning.
Most LLMs have been optimized for answering questions primarily to deliver a good consumer experience, and we’ve been able to “graft” them into complex agentic workflows to build valuable applications. The trend of LLMs built to support particular operations in agents natively will create a lot of lift for agentic performance. I’m confident that large agentic performance gains in this direction will be realized in the next few years.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Prevent common issues in applications based on large language models such as hallucinations, data leaks, and off-topic responses. Build guardrails that protect against incorrect or sensitive responses in our new short course, made in collaboration with GuardrailsAI. Sign up now!
News
Mixture of Experts Pulls Ahead
A new open source large language model outperforms competitors, including the open-weights Llama 3.1 405B, on a variety of benchmarks.
What’s new: Tencent released Hunyuan-Large, a mixture-of-experts model with open code and open weights. It comes in base and instruction-tuned versions, both of which can process a relatively large input context window of 256,000 tokens. It’s free for developers outside the European Union who have fewer than 100 million monthly users. You can experiment with it here.
Mixture of experts (MoE) basics: The MoE architecture uses different subsets of its parameters to process different inputs. Each MoE layer contains a group of neural networks, or experts, preceded by a gating module that learns to choose which one(s) to use based on the input. In this way, different experts learn to specialize in different types of examples. Because not all parameters are used to produce any given output, the network uses less energy and runs faster than models of similar size that use all parameters to process every input.
How it works: Hunyuan-Large comprises 389 billion parameters but uses 52 billion parameters to process any given input. The team pretrained the model on 7 trillion tokens primarily of English and Chinese text, of which 5.5 trillion tokens came from unspecified sources and 1.5 trillion synthetic tokens were generated by unspecified large language models. The models used to generate training data were “specialized” to provide expert-level responses in various domains. The team fine-tuned Hunyuan-Large on unspecified datasets of instructions and human feedback.
- MoE models typically select which expert(s) to use based on the input. Hunyuan-Large chooses one of 16 experts, but it also uses a shared expert — an expert that processes every input.
- Recent research showed that there is a formula for the optimal learning rate based on the batch size (the number of examples a model sees during one training step). The shared expert and the chosen expert see a different amount of data in each training step, so the team modified the learning rate for the chosen expert based on that formula.
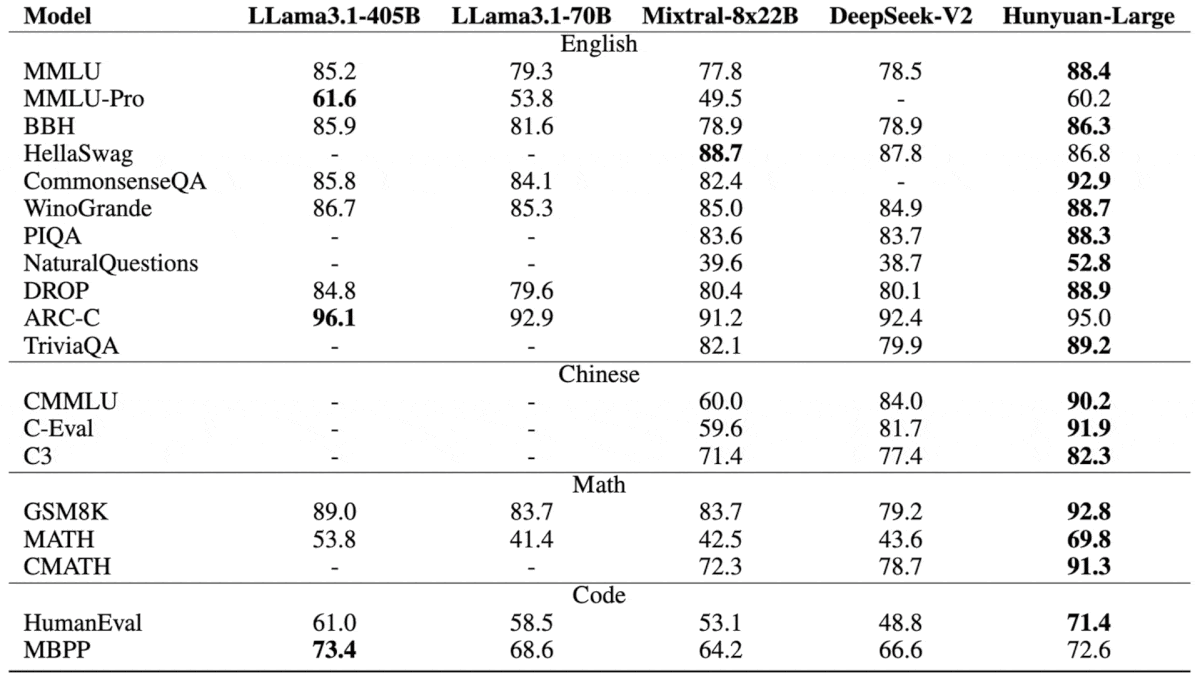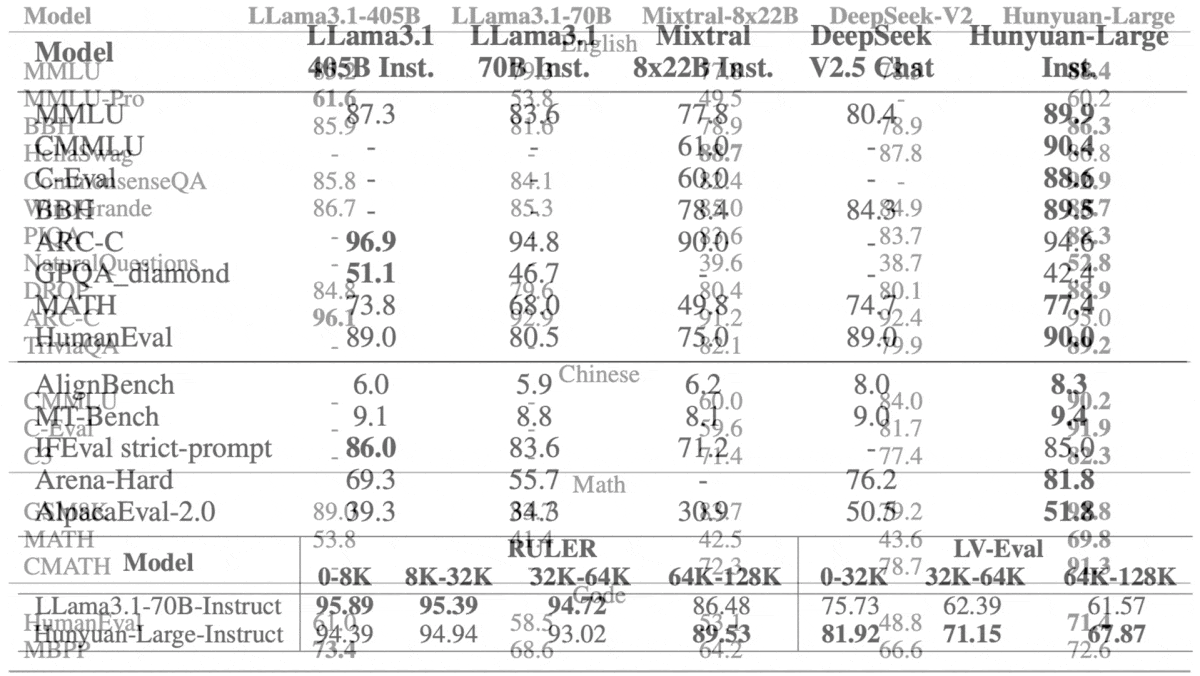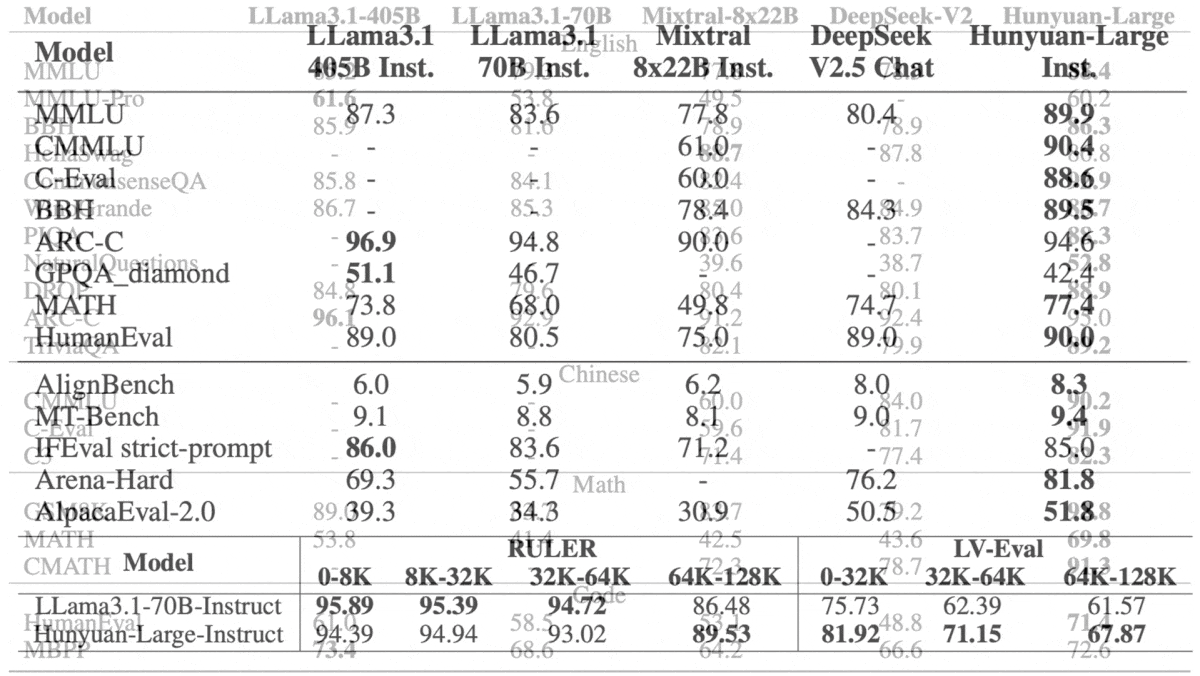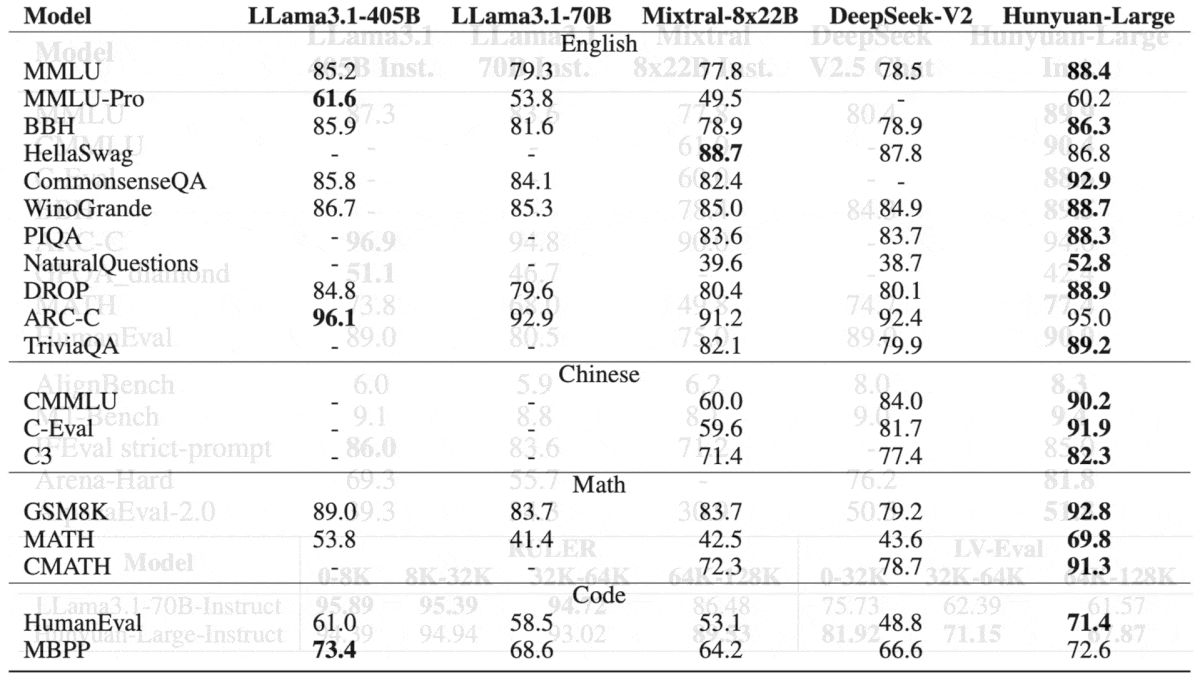
Results: The team compared the Hunyuan-Large models to four open source models and their instruction-tuned versions: Llama 3.1 70B, Llama 3.1 405B, and the MoE models Mixtral-8x22B and DeepSeek-V2.
- Hunyuan-Large achieved the best performance on 15 of 19 benchmarks that test English, Chinese, math, and coding proficiency. For example, on MMLU (answering multiple choice questions in topics including elementary mathematics, history, computer science, and law), Hunyuan-Large achieved 88.4 percent accuracy. The next-best competitor, Llama 3.1 405B, achieved 85.2 percent.
- The instruction-tuned version achieved the best performance on 10 of 13 benchmarks including measures of instruction-following ability and alignment with certain human preferences. For instance, Hunyuan-Large-Instruct maintained its dominance on MMLU (89.9 percent accuracy to Llama 3.1 405B Instruct’s 87.3 percent accuracy). On AlpacaEval 2, an instruction-following benchmark, Hunyuan-Large-Instruct achieved 51.8 percent, while the next-best competitor, DeepSeek 2.5 Chat, achieved 50.5 percent.
Why it matters: Hunyuan-Large generally outperforms Llama 405B, achieving the performance of a 405 billion parameter model while computing only 52 billion parameters. That’s a significantly lower processing requirement, and the model is free for many purposes.
We’re thinking: Setting aside Switch Transformer — a 1.6 trillion parameter behemoth that was built to test the limits of size rather than performance — Hunyuan-Large is among the largest MoE models we’ve come across. It’s an impressive demonstration of what larger MoE models can accomplish.

Big AI Pursues Military Contracts
Two top AI companies changed their stances on military and intelligence applications.
What’s new: Meta made its Llama family of large language models available to the U.S. government for national security purposes — a major change in its policy on military applications. Similarly, Anthropic will offer its Claude models to U.S. intelligence and defense agencies.
How it works: Meta and Anthropic are relying on partnerships with government contractors to navigate the security and procurement requirements for military and intelligence work.
- Meta’s partners in the defense and intelligence markets include Accenture, Amazon, Anduril, Booz Allen, Databricks, Deloitte, IBM, Leidos, Lockheed Martin, Microsoft, Oracle, Palantir, Scale AI, and Snowflake. These companies will integrate Llama models into U.S. government applications in areas like logistics, cybersecurity, intelligence analysis, and tracking terrorists’ financial activities.
- Some Meta partners have built specialized versions of Llama. For example, Scale AI fine-tuned Llama 3 for national security applications. Called Defense Llama, the fine-tuned model can assist with tasks such as planning military operations and analyzing an adversary’s vulnerabilities.
- Anthropic will make its Claude 3 and 3.5 model families available to U.S. defense and intelligence agencies via a platform built by Palantir, which provides big-data analytics to governments, and hosted by Amazon Web Services. The government will use Claude to review documents, find patterns in large amounts of data, and help officials make decisions.
Behind the news: In 2018, Google faced backlash when it won a contract with the U.S. government to build Project Maven, an AI-assisted intelligence platform. Employees protested, resigned, and called on the company to eschew military AI work. Google withdrew from the project and Palantir took it over. Subsequently, many AI developers, including Meta and Anthropic, have forbidden use of their models for military applications. Llama’s new availability to U.S. military and intelligence agencies is a notable exception. In July, Anthropic, too, began to accommodate use of its models for intelligence work. Anthropic still prohibits using Claude to develop weapons or mount cyberattacks.
Why it matters: The shift in Meta’s and Anthropic’s policies toward military uses of AI is momentous. Lately AI has become a battlefield staple in the form of weaponized drones, and AI companies must take care that their new policies are consistent with upholding human rights. Military uses for AI include not only weapons development and targeting but also potentially life-saving search and rescue, logistics, intelligence, and communications. Moreover, defense contracts represent major opportunities for AI companies that can fund widely beneficial research and applications.
We’re thinking: Peace-loving nations face difficult security challenges, and AI can be helpful in meeting them. At the same time, the militarization of AI brings challenges to maintaining peace and stability, upholding human rights, and retaining human control over autonomous systems. We call on developers of military AI to observe the guidelines, proposed by Responsible Artificial Intelligence in the Military, which are endorsed by more than 60 countries and call for robust governance, oversight, accountability, and respect for human rights.
Voter’s Helper
Some voters navigated last week’s United States elections with help from a large language model that generated output based on verified, nonpartisan information.
What’s new: Perplexity, an AI-powered search engine founded in 2022 by former OpenAI and Meta researchers, launched its Election Information Hub, an AI-enhanced website that combines AI-generated analysis with real-time data. The model provided live updates, summaries, and explanations of key issues in the recent national, state, and local elections in the U.S. (The hub remains live, but it no longer displays information about local contests or delivers detailed results for election-related searches.)
How it works: Perplexity partnered with Associated Press for election news and Democracy Works, a nonprofit that develops technology and data related to democracy. Democracy Works provided an API for information about elections, issues, and polling locations.
- Users could search by candidate, issue, state, district, or postal code. For example, searching a postal code returned AI-generated summaries of local races, measures, or other ballot issues drawn from vetted sources such as Ballotpedia, a nonpartisan clearinghouse for election information. A chatbot window enabled users to ask questions and drill down on citations of information sources.
- Initial testing by The Verge revealed problems with accuracy in AI-generated summaries. These included outdated information (for example, summaries failed to consistently note Robert F. Kennedy Jr.’s withdrawal from the presidential election), mistakes in candidate profiles, and mishandling of write-in candidates. Perplexity eventually fixed many of the errors.
Behind the news: While Perplexity courted demand for AI-generated information about the U.S. elections, other search-engine providers took more cautious approaches. You.com offered an election chatbot that focused on vote tallies provided by Decision Desk HQ, an election information broker, rather than information about issues or polling locations. Google and Microsoft Bing emphasized information from vetted sources. Microsoft Copilot and OpenAI (which had launched its SearchGPT service the week before the election) simply declined to answer election-related questions, referring users to other sources of information.
Why it matters: Chatbots are maturing to the point where they can provide fairly trustworthy information in high-stakes decisions like elections. The combination of web search and retrieval-augmented generation contributes to decision support systems that are both personalized and accurate.
We’re thinking: Perfect information is hard to come by in any election. Traditional media, social media, and your uncle’s strongly held opinions all have limitations. Chatbots aren’t perfect either, but when they’re properly designed to avoid biased output and outfitted with high-quality information sources, they can help strengthen users’ choices and voices.

Free Agents
An open source package inspired by the commercial agentic code generator Devin aims to automate computer programming and more.
What’s new: OpenHands, previously known as OpenDevin, implements a variety of agents for coding and other tasks. It was built by Xingyao Wang and a team at University of Illinois Urbana-Champaign, Carnegie Mellon, Yale, University of California Berkeley, Contextual AI, King Abdullah University of Science and Technology, Australian National University, Ho Chi Minh City University of Technology, Alibaba, and All Hands AI. The code is free to download, use, and modify.
How it works: OpenHands provides a set of agents, or workflows for the user’s choice of large language models. Users can command various agents to generate, edit, and run code; interact with the web; and perform auxiliary tasks related to coding and other work. The agents run in a secure Docker container with access to a server to execute code, a web browser, and tools that, say, copy text from pdfs or transcribe audio files.
- The CodeAct agent follows the CodeAct framework, which specifies an agentic workflow for code generation. Given a prompt or results of a code execution, it can ask for clarification, write code and execute it, and deliver the result. It can also retrieve relevant information from the web.
- The browsing agent controls a web browser. At every time step, it receives the user’s prompt and a text description of each element it sees on the resulting webpage. The description includes a numerical identifier, words like “paragraph” or “button” (and associated text), a list of possible actions (such as scroll, click, wait, drag and drop, and send a message to the user), an example chain of thought for selecting an action, and a list of previous actions taken. It executes actions iteratively until it has sent a message to the user.
- A set of “micro agents” perform auxiliary tasks such as writing commit messages, writing Postgres databases, summarizing codebases, solving math problems, delegating actions to other agents, and the like. Users can write their own prompts to define micro agents.
Results: Overall, OpenHands agents achieve similar performance to previous agents on software engineering problems, web browsing, and miscellaneous tasks like answering questions. For example, fixing issues in Github in SWE-Bench, the CodeAct agent using Claude 3.5 Sonnet solved 26 percent while Moatless Tools using the same model solved 26.7 percent. On GPQA Diamond, a set of graduate-level questions about physics, chemistry, and biology, the CodeAct agent using GPT-4-turbo with search wrote code to perform the necessary calculations and found relevant information to answer the questions, achieving 51.8 percent accuracy. GPT-4 with search achieved 38.8 percent accuracy.
Why it matters: Agentic workflows are rapidly expanding the scope and capabilities of large language models. As open source software, this system gives developers an extensible toolkit for designing agentic systems. Although it’s oriented toward coding, it accommodates a variety of information-gathering, -processing, and -publishing tasks.
We’re thinking: This system lets users tailor custom agents simply by rewriting prompts. We look forward to seeing what non-programmers do with it!
A MESSAGE FROM DEEPLEARNING.AI

Build AI applications that have long-term agentic memory! Our short course “LLMs as Operating Systems: Agent Memory” is based on insights from the MemGPT paper and taught by two of its coauthors. Learn how to implement persistent, efficient memory management for applications based on large language models. Enroll for free