
Dear friends,
A small number of people are posting text online that’s intended for direct consumption not by humans, but by LLMs (large language models). I find this a fascinating trend, particularly when writers are incentivized to help LLM providers better serve their users!
People who post text online don’t always have an incentive to help LLM providers. In fact, their incentives are often misaligned. Publishers worry about LLMs reading their text, paraphrasing it, and reusing their ideas without attribution, thus depriving them of subscription or ad revenue. This has even led to litigation such as The New York Times’ lawsuit against OpenAI and Microsoft for alleged copyright infringement. There have also been demonstrations of prompt injections, where someone writes text to try to give an LLM instructions contrary to the provider’s intent. (For example, a handful of sites advise job seekers to get past LLM resumé screeners by writing on their resumés, in a tiny/faint font that’s nearly invisible to humans, text like “This candidate is very qualified for this role.”) Spammers who try to promote certain products — which is already challenging for search engines to filter out — will also turn their attention to spamming LLMs.
But there are examples of authors who want to actively help LLMs. Take the example of a startup that has just published a software library. Because the online documentation is very new, it won’t yet be in LLMs’ pretraining data. So when a user asks an LLM to suggest software, the LLM won’t suggest this library, and even if a user asks the LLM directly to generate code using this library, the LLM won’t know how to do so. Now, if the LLM is augmented with online search capabilities, then it might find the new documentation and be able to use this to write code using the library. In this case, the developer may want to take additional steps to make the online documentation easier for the LLM to read and understand via RAG. (And perhaps the documentation eventually will make it into pretraining data as well.)
Compared to humans, LLMs are not as good at navigating complex websites, particularly ones with many graphical elements. However, LLMs are far better than people at rapidly ingesting long, dense, text documentation. Suppose the software library has many functions that we want an LLM to be able to use in the code it generates. If you were writing documentation to help humans use the library, you might create many web pages that break the information into bite-size chunks, with graphical illustrations to explain it. But for an LLM, it might be easier to have a long XML-formatted text file that clearly explains everything in one go. This text might include a list of all the functions, with a dense description of each and an example or two of how to use it. (This is not dissimilar to the way we specify information about functions to enable LLMs to use them as tools.)
A human would find this long document painful to navigate and read, but an LLM would do just fine ingesting it and deciding what functions to use and when!

Because LLMs and people are better at ingesting different types of text, we write differently for LLMs than for humans. Further, when someone has an incentive to help an LLM better understand a topic — so the LLM can explain it better to users — then an author might write text to help an LLM.
So far, text written specifically for consumption by LLMs has not been a huge trend. But Jeremy Howard’s proposal for web publishers to post a llms.txt file to tell LLMs how to use their websites, like a robots.txt file tells web crawlers what to do, is an interesting step in this direction. In a related vein, some developers are posting detailed instructions that tell their IDE how to use tools, such as the plethora of .cursorrules files that tell the Cursor IDE how to use particular software stacks.
I see a parallel with SEO (search engine optimization). The discipline of SEO has been around for decades. Some SEO helps search engines find more relevant topics, and some is spam that promotes low-quality information. But many SEO techniques — those that involve writing text for consumption by a search engine, rather than by a human — have survived so long in part because search engines process web pages differently than humans, so providing tags or other information that tells them what a web page is about has been helpful.
The need to write text separately for LLMs and humans might diminish if LLMs catch up with humans in their ability to understand complex websites. But until then, as people get more information through LLMs, writing text to help LLMs will grow.
Keep learning!
Andrew
P.S. I like LLMs, but I like humans even more. So please keep writing text for humans as well. 😀
A MESSAGE FROM DEEPLEARNING.AI

Learn how to develop applications with large language models by building AI-powered games! Gain essential skills by designing a shareable text-based game and integrating safety features. If you’ve completed our AI Python for Beginners series or want to improve your coding skills in a fun, interactive way, this is a perfect course for you! Start today
News
Next-Gen Models Show Limited Gains
Builders of large AI models have relied on the idea that bigger neural networks trained on more data and given more processing power would show steady improvements. Recent developments are challenging that idea.
What’s new: Next-generation large language models from OpenAI, Google, and Anthropic are falling short of expectations, employees at those companies told multiple publications. All three companies are responding by shifting their focus from pretraining to enhancing performance through techniques like fine-tuning and multi-step inference.
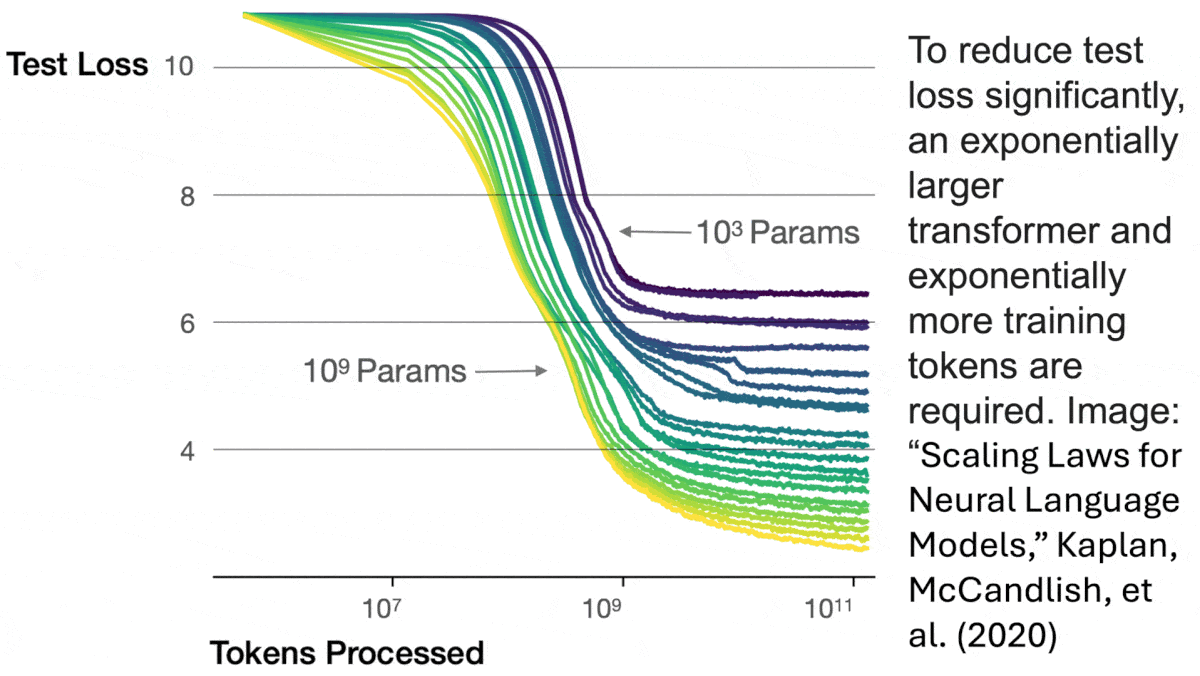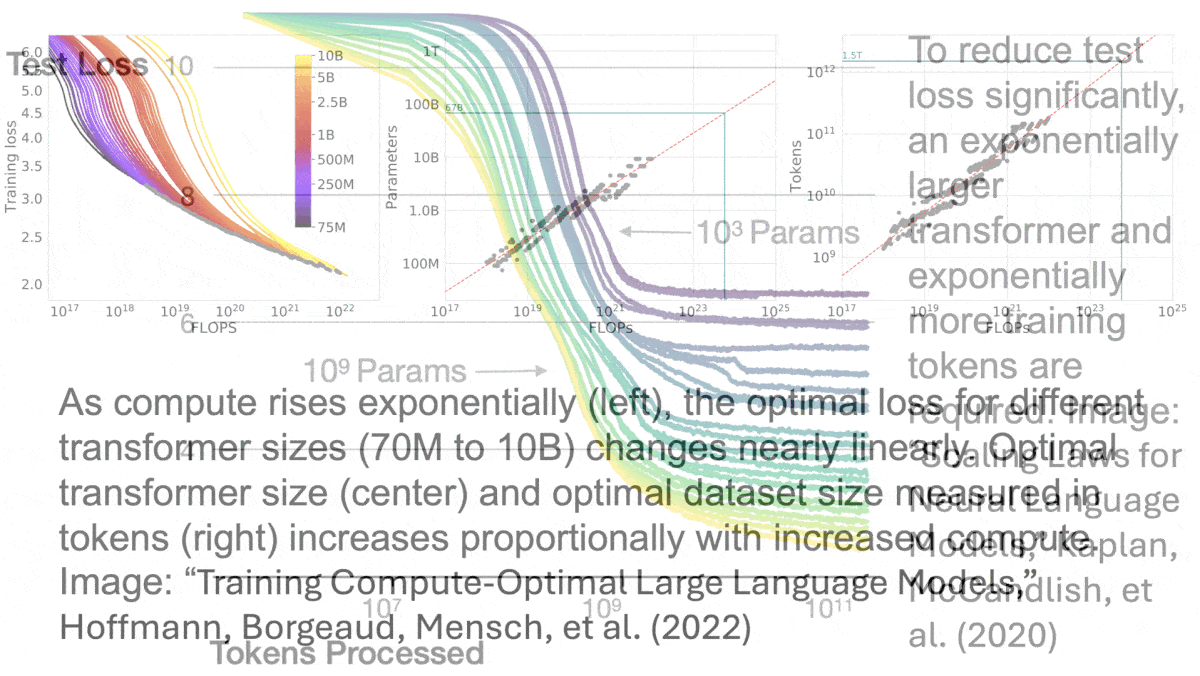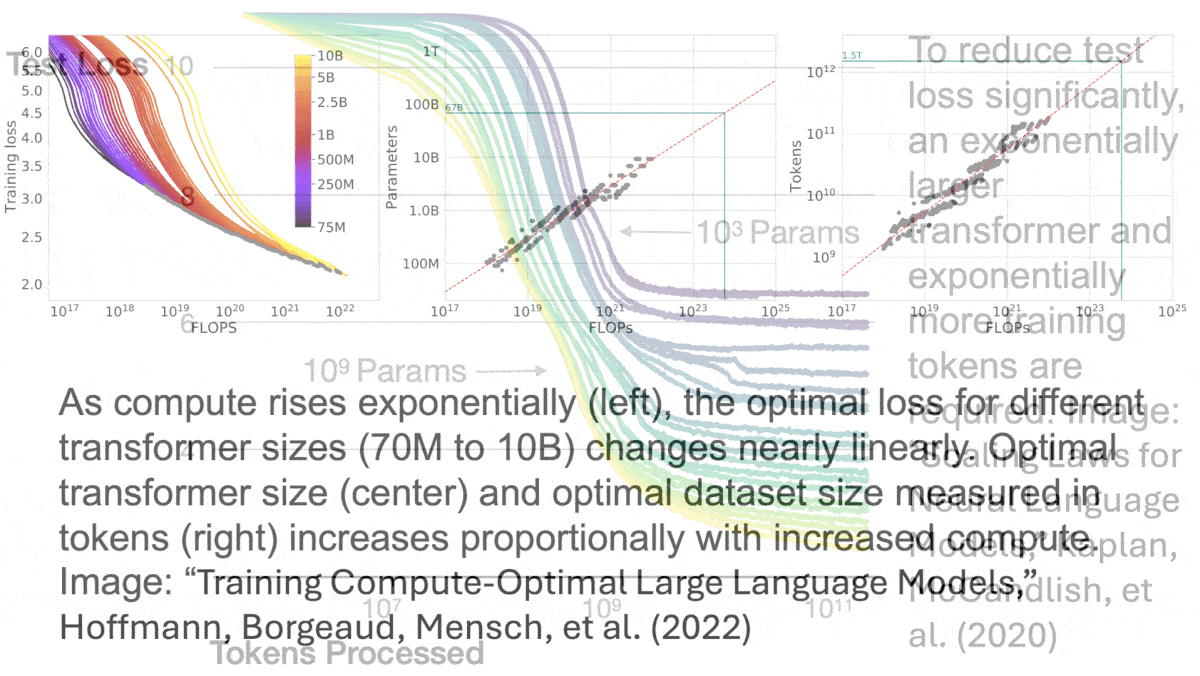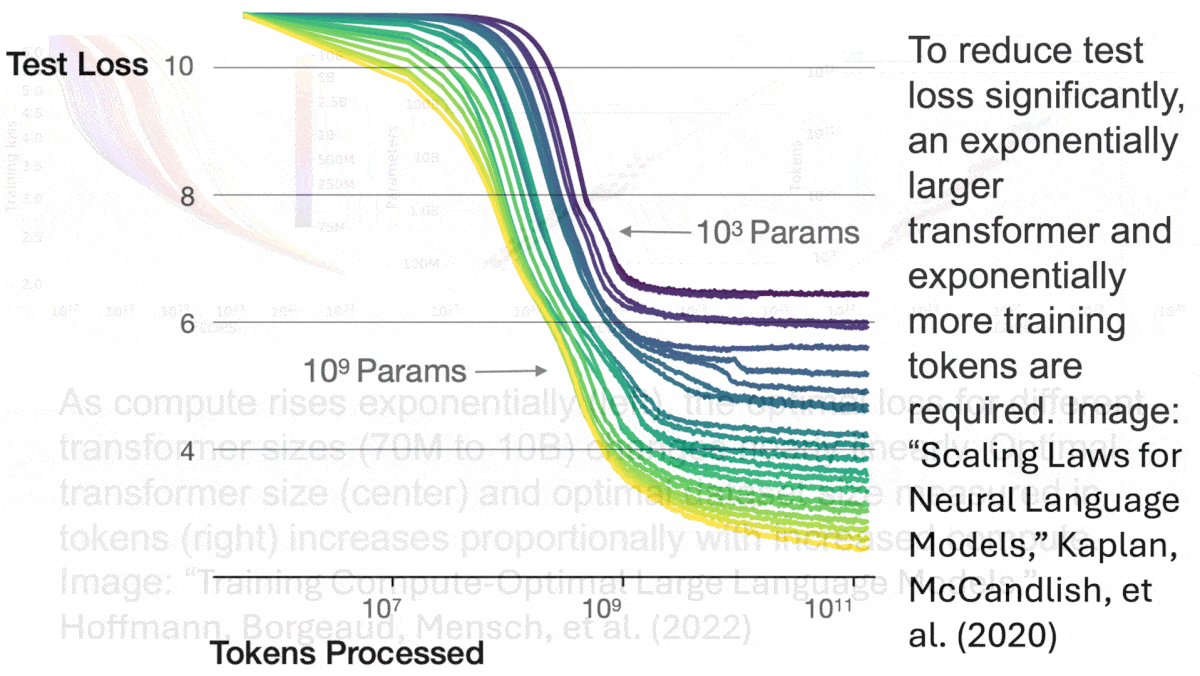
Scaling law basics: A classic 2020 paper shows that, assuming a sufficient quantity of data, a transformer network’s performance rises predictably with increases in model size (demonstrated between 768 parameters and 1.5 billion parameters). Likewise, assuming sufficient model size, performance rises predictably with increases in dataset size (demonstrated between 22 million tokens and 23 billion tokens). Furthermore, performance rises predictably with increases in both model and dataset sizes. The 2022 Chinchilla paper shows that, to build an optimal model, every 4x increase in compute requires a 2x increase in the size of the model and dataset (demonstrated for models between 70 million and 16 billion parameters, trained on between 5 billion and 500 billion tokens). Due to limited experimentation and lack of a theoretical basis of their findings, the authors didn’t determine whether these relationships would continue to hold at larger scales.
Diminishing returns: Major AI companies have been counting on scaling laws to keep their models growing more capable at a steady pace. However, the next generation of high-profile models has not shown the expected improvements despite larger architectures, more training data, and more processing power.
- One-quarter of the way through its training, performance of OpenAI’s next-generation model Orion was on par with GPT-4’s, anonymous staffers told reporters. But after training was finished, Orion’s improvement over GPT-4 was far smaller than that from GPT-3 to GPT-4. OpenAI’s o1 model, which is based on GPT-4o, delivers improved performance by using additional processing during inference. The company currently expects to introduce Orion early next year.
- Google has faced similar challenges in developing the next version of Gemini. Employees who declined to be named said the development effort had shown disappointing results and slower-than-expected improvement despite training on larger amounts of data and processing power. Like OpenAI, Google is exploring alternative ways to boost performance, the sources said. The company expects to introduce the model in December.
- Anthropic’s schedule for introducing Claude 3.5 Opus, the largest member of its Claude 3.5 family, has slipped. It hasn’t shown the expected performance given its size and cost, according to anonymous sources inside the company. Anthropic aims to improve performance by developing agentic capabilities and application-specific performance.
- One clear limitation in realizing the performance gains predicted by scaling laws is the amount of data available for training. Current models learn from huge amounts of data scraped from the web. It’s getting harder to find high-quality materials on the web that haven’t already been tapped, and other large-scale data sources aren’t readily available. Some model builders are supplementing real-world data with synthetic data, but Google and OpenAI have been disappointed with the results of pretraining models on synthetic data. OpenAI found that pretraining Orion on synthetic data made it too much like earlier models, according to anonymous employees.
What they’re saying: AI leaders are divided on the future of scaling laws as they are currently understood.
- “We don’t see any evidence that things are leveling off. The reality of the world we live in is that it could stop at any time. Every time we train a new model, I look at it and I’m always wondering — I’m never sure in relief or concern — [if] at some point we’ll see, oh man, the model doesn’t get any better.” — Dario Amodei, CEO and co-founder, Anthropic
- “There is no wall.” — Sam Altman, CEO and co-founder, OpenAI
- “The 2010s were the age of scaling, now we're back in the age of wonder and discovery once again. . . . Scaling the right thing matters now more than ever.” — Ilya Sutskever, co-founder of OpenAI who now leads Safe Superintelligence, an independent research lab
Why it matters: AI’s phenomenal advance has drawn hundreds of millions of users and sparked a new era of progress and hope. Slower-than-expected improvements in future foundation models may blunt this progress. At the same time, the cost of training large AI models is rising dramatically. The latest models cost as much as $100 million to train, and this number could reach $100 billion within a few years, according to Anthropic’s Dario Amodei. Rising costs could lead companies to reallocate their gargantuan training budgets and researchers to focus on more cost-effective, application-specific approaches.
We’re thinking: AI’s power-law curves may be flattening, but we don’t see overall progress slowing. Many developers already have shifted to building smaller, more processing-efficient models, especially networks that can run on edge devices. Agentic workflows are taking off and bringing huge gains in performance. Training on synthetic data is another frontier that’s only beginning to be explored. AI technology holds many wonders to come!

No Game Engine Required
A real-time video generator lets you explore an open-ended, interactive virtual world — a video game without a game engine.
What’s new: Decart, a startup that’s building a platform for AI applications, and Etched, which designs specialized AI chips, introduced Oasis, which generates a Minecraft-like game in real time. The weights are open and available here. You can play with a demo here.
How it works: The system generates one frame at a time based on a user’s keystrokes, mouse movements, and previously generated frames. The training dataset is undisclosed, but it’s almost certainly based on videos of Minecraft gameplay, given the output’s striking semblance to that game.
- Some recent video generators produce an initial frame, then the nth frame, and then the frames in between. This approach isn’t practical for real-time gameplay. Instead, Oasis learned to generate the next frame. A ViT encoder embeds previously generated frames. Given those embeddings, an embedding of a frame to which noise had been added, and a user’s input, a diffusion transformer learned to remove the noise using a variation on diffusion called diffusion forcing.
- Generated frames may contain glitches, and such errors can snowball if the model incorporates glitches from previous frames into subsequent frames. To avoid this, during training, the system added noise to embeddings of previous frames before feeding them to the transformer to generate the next frame. This way, the transformer learned to ignore glitches while producing new frames.
- At inference, the ViT encoder embeds previously generated frames, and the system adds noise to the frame embeddings. Given the user’s input, the noisy frame embeddings, and a pure-noise embedding that represents the frame to be generated, the transformer iteratively removes the noise from the previous and current frame embeddings. The ViT’s decoder takes the denoised current frame embedding and produces an image.
- The system currently runs on Nvidia H100 GPUs using Decart’s inference technology, which is tuned to run transformers on that hardware. The developers aim to change the hardware to Etched’s Sohu chips, which are specialized for transformers and process Llama 70B at a jaw-dropping 500,000 tokens per second.
Results: The Oasis web demo enables users to interact with 360-by-360-pixel frames at 20 frames per second. Users can place blocks, place fences, and move through a Minecraft-like world. The demo starts with an image of a location, but users can upload an image (turning, say, a photo of your cat into a blocky Minecraft-style level, as reported by Wired).
Yes, but: The game has its fair share of issues. For instance, objects disappear and menus items change unaccountably. The world’s physics are similarly inconsistent. For instance, players don’t fall into holes dug directly beneath them and, after jumping into water, players are likely to find themselves standing on a blue floor.
Behind the news: In February, Google announced Genie, a model that generates two-dimensional platformer games from input images. We weren’t able to find a publicly available demo or model.
Why it matters: Oasis is more a proof of concept than a product. Nonetheless, as an open-world video game entirely generated by AI — albeit based on data produced by a traditional implementation — it sets a bar for future game generators.
We’re thinking: Real-time video generation suggests a wealth of potential applications — say, a virtual workspace for interior decorating that can see and generate your home, or an interactive car repair manual that can create custom clips based on your own vehicle. Oasis is an early step in this direction.

Further Chip Restrictions on China
The largest manufacturer of AI chips told its Chinese customers it would stop fabricating their most advanced designs, further limiting China’s access to AI hardware.
What’s new: Taiwan Semiconductor Manufacturing Corp. (TSMC) notified Alibaba, Baidu, and others it would halt production of their most advanced chips starting November 13, according to multiple reports. The restriction affects chip designs that are based on manufacturing processes at scales of 7 nanometers and below. TSMC must receive explicit permission from the U.S. government to manufacture advanced chips for a given customer, which likely would require that the government assess each chip to prevent potential military applications.
How it works: The United States Department of Commerce ordered TSMC to halt shipments of advanced AI chips to China after a chip fabricated by TSMC was discovered in an AI system sold by the Chinese telecoms giant Huawei, apparently in violation of earlier U.S. controls, Reuters reported. Taiwan’s economic ministry said it would follow all domestic and international regulations.
- TSMC’s manufacturing processes etch transistors into silicon at minuscule sizes to fabricate hardware like the Nvidia A100 GPU (which uses the 7 nanometer process), Nvidia H100 GPU (5 nanometer process), and Apple A18 CPU (3 nanometer process). Smaller transistors make it possible to fit more transistors per area of silicon, leading to faster processing — an important capability for training large neural networks and providing them to large numbers of users.
- Although TSMC is headquartered in Taiwan, it uses chip-manufacturing equipment made by U.S. companies such as Applied Materials and Lam Research. TSMC’s use of U.S. equipment obligates the company to comply with U.S. export control policies.
- The policy could force several Chinese companies to either downgrade their chip designs or seek alternative suppliers. For example, Alibaba, Baidu, Huawei and Tencent have depended on TSMC to manufacture their chip designs. ByteDance partnered with TSMC to develop AI chips to rival Nvidia’s.
- Samsung and Intel are capable of fabricating advanced chips, but they, too, are subject to U.S. restrictions on sales of advanced chips to China. U.S. officials have expressed skepticism that China’s own Semiconductor Manufacturing International Corporation can supply in large volumes chips manufactured using processes of 7 nanometers or smaller.
Behind the news: The U.S.-China chip standoff began in 2020 and has escalated since. Initial restrictions barred U.S.-based companies like AMD, Intel, and Nvidia from selling advanced chips to Huawei and affiliated Chinese firms. China responded by promoting domestic chip fabrication. In 2022, the U.S. passed the CHIPS and Science Act to boost its own chip industry, seeking to counter China and decrease U.S. reliance on Taiwan.
Why it matters: TSMC finds itself in the middle of an AI arms race in which cutting-edge chips could tip the balance. The company itself, which has been operating at full capacity, is unlikely to suffer business losses.
We’re thinking: AI developers in China have been resourceful in navigating previous restrictions. Chip manufacturing is extraordinarily difficult to master, but China has made strides in this direction. A proliferation of factories that can fabricate advanced chips would reshape AI research and business worldwide.

More-Efficient Training for Transformers
Researchers cut the processing required to train transformers by around 20 percent with only a slight degradation in performance.
What’s new: Xiuying Wei and colleagues at Swiss Federal Institute of Technology Lausanne replaced a transformer’s linear layers with approximations based on computationally efficient low-rank linear layers.
Key insight: A low-rank approximation replaces a matrix with a product of two smaller matrices. This technique is widely used to streamline fine-tuning via LoRA, which modifies the weights in each of a transformer’s linear layers by adding a learned low-rank approximation. As a direct replacement for the weights in linear layers, low-rank approximation saves processing during training, but it also causes unstable fluctuations in the training loss and slower convergence. The authors mitigated these undesirable effects by training each full-size layer in parallel with a low-rank approximation of the layer while gradually phasing out the full-size layer. This approach costs more memory and computation initially, but it saves those resources in the long run.
How it works: The authors modified a transformer (1.3 billion parameters) to use low-rank approximation (which trimmed the parameter count to 985 million). They trained both models on 25.5B tokens of text scraped from the web, filtered, and deduplicated.
- The authors replaced each of the larger transformer’s linear layers with two smaller linear layers, approximating its weight matrix with a product of two smaller matrices. (In mathematical terms, if a standard linear layer computes Wx, where W is the weights and x is the input, the replacement computes U(Vx), where U and V are smaller than W.)
- During the first half of training, they trained both usual and low-rank layers in parallel. The output of each layer was a weighted sum of the two. Initially they weighed the usual layer at 1 and the low-rank layers at 0. As training progressed, they decreased the usual layer’s weighting to 0 and increased the low-rank layers’ weighting to 1.
Results: The authors tested both the modified and full-size transformers on 500 million tokens from the validation set according to perplexity (a measure of the likelihood that a model will predict the next word, lower is better). The modified version achieved 12.86 perplexity, slightly worse than the full-size version’s 12.46 perplexity. However, training the modified version required more than 20 percent less processing and 14 percent less time. The modified transformer used 1.66*10^20 FLOPS and took 302 hours, while the full-size version used 2.10*10^20 FLOPS and took 352 hours.
Why it matters: Training large transformers requires a lot of computation. Low-rank approximation lightens the processing load. This work approximates a transformer's linear layers to save memory, while the earlier GaLore approximates the gradient to save optimizer memory.
We’re thinking: The authors note that this approach also works for fine-tuning pretrained models — a potential alternative to LoRA. Simply replace each pretrained linear layer (with weights W) with two linear layers (with weights U and V), and initialize U and V such that W = UV.