
Dear friends,
Happy Thanksgiving! In the United States, this is a week when many reflect on their blessings and give thanks. Even as I reflect on how lucky I am to have food, shelter, family, and friends, I think about those who have much less and what we can do to help them.
Last week, I spoke with a woman who had been severely physically abused by her husband. She showed me pictures of her face from a few years ago, which had a bloodied sequence of tears down the middle. She also showed me scars left by cigarette burns inflicted by her husband, who told her these burns made her ugly so no other man would ever want her. She is no longer with her husband but continues to struggle. Her phone is badly cracked and barely holds a charge. Without a high-school degree, she has struggled to find a job and is surviving by staying on the couch of a friend. As winter approaches, they keep their place chilly to save the cost of electricity.
Working in AI, I am fortunate to interact with many of the smartest and most capable technology and business leaders in the world. But both at home and when I travel, I try to meet with people of a broad range of backgrounds, because ultimately I want to do work that helps people broadly, and this requires that I understand people broadly. When you go to a grocery store and see someone put down a $5 carton of eggs because it is too expensive, and hear them think through how to explain to their kids why they’re skipping eggs that week, it gives you a deeper appreciation for why a $1.50/hour raise can be life-changing for many people.
While I can try to help out individuals here and there, technology is advancing rapidly, and this gives me a lot of optimism for the future. Technology remains the best way I know of to help people at scale through providing better education, career guidance, healthcare, personal safety, healthier food, or other things needed to support thriving.

I am optimistic about the future because I see so many ways life can be so much better for so many people. I feel blessed that, when my kids or I are cold, we have warm clothing, and when we are hungry, we have a working car to drive to the grocery and buy fresh food. I feel blessed that, rather than using a badly cracked cellphone, I have a modern laptop and a fast internet connection to do my work on.
As a child, my father taught me the aphorism “there but for the grace of God go I” to recognize that, in even slightly different circumstances, I might have ended up with much less. Having worked on many software products, I know that, to make good decisions, I have to understand the people I hope to serve. This is why I continue to routinely seek out, speak with, and try to understand people from all walks of life, and I hope many others in AI will do so, too.
I see so many people in the AI community building things to make the world better. I am thankful for what the AI community has already done, and I look forward to continuing to build and serve others together.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Get started coding in Python with AI Python for Beginners, a four-part course led by Andrew Ng. Build projects from the very first lesson with real-time support from an AI assistant. Complete the course and bring your ideas to life! Start today
News
Reasoning Revealed
An up-and-coming Hangzhou AI lab unveiled a model that implements run-time reasoning similar to OpenAI o1 and delivers competitive performance. Unlike o1, it displays its reasoning steps.
What’s new: DeepSeek announced DeepSeek-R1, a model family that processes prompts by breaking them down into steps. A free preview version is available on the web, limited to 50 messages daily; API pricing is not yet announced. R1-lite-preview performs comparably to o1-preview on several math and problem-solving benchmarks. DeepSeek said it would release R1 as open source but didn't announce licensing terms or a release date.
How it works: DeepSeek-R1-lite-preview uses a smaller base model than DeepSeek 2.5, which comprises 236 billion parameters. Like o1-preview, most of its performance gains come from an approach known as test-time compute, which trains an LLM to think at length in response to prompts, using more compute to generate deeper answers. Unlike o1-preview, which hides its reasoning, at inference, DeepSeek-R1-lite-preview’s reasoning steps are visible. This makes the model more transparent, but it may also make it more vulnerable to jailbreaks and other manipulation.
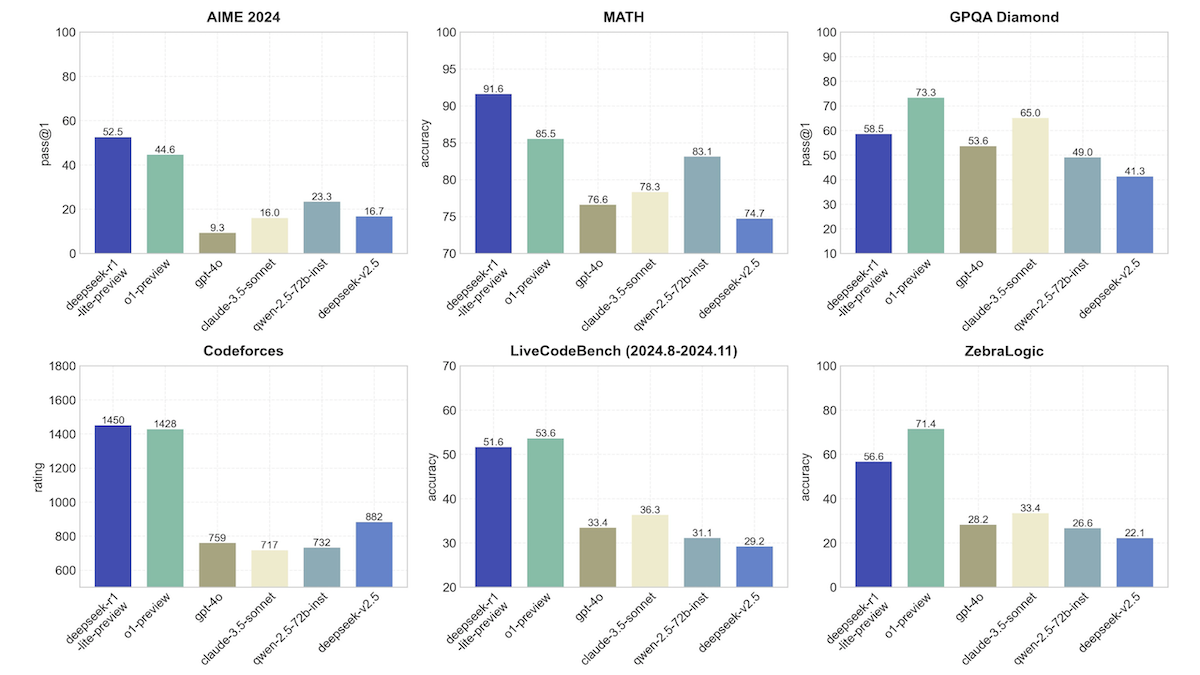
- According to DeepSeek, R1-lite-preview, using an unspecified number of reasoning tokens, outperforms OpenAI o1-preview, OpenAI GPT-4o, Anthropic Claude 3.5 Sonnet, Alibaba Qwen 2.5 72B, and DeepSeek-V2.5 on three out of six reasoning-intensive benchmarks.
- It substantially outperforms o1-preview on AIME (advanced high school math problems, 52.5 percent accuracy versus 44.6 percent accuracy), MATH (high school competition-level math, 91.6 percent accuracy versus 85.5 percent accuracy), and Codeforces (competitive programming challenges, 1,450 versus 1,428). It falls behind o1 on GPQA Diamond (graduate-level science problems), LiveCodeBench (real-world coding tasks), and ZebraLogic (logical reasoning problems).
- DeepSeek reports that the model’s accuracy improves dramatically when it uses more tokens at inference to reason about a prompt (though the web user interface doesn’t allow users to control this). On AIME math problems, performance rises from 21 percent accuracy when it uses less than 1,000 tokens to 66.7 percent accuracy when it uses more than 100,000, surpassing o1-preview’s performance. The additional performance comes at the cost of slower and more expensive output.
Behind the news: DeepSeek-R1 follows OpenAI in implementing this approach at a time when scaling laws that predict higher performance from bigger models and/or more training data are being questioned.
Why it matters: DeepSeek is challenging OpenAI with a competitive large language model. It’s part of an important movement, after years of scaling models by raising parameter counts and amassing larger datasets, toward achieving high performance by spending more energy on generating output.
We’re thinking: Models that do and don’t take advantage of additional test-time compute are complementary. Those that do increase test-time compute perform well on math and science problems, but they’re slow and costly. Those that don’t use additional test-time compute do well on language tasks at higher speed and lower cost. Applications that require facility in both math and language may benefit by switching between the two.

Household Help
A new generation of robots can handle some household chores with unusual skill.
What’s new: Physical Intelligence, a startup based in San Francisco, unveiled π0 (pronounced “pi-zero”), a machine learning system that enables robots to perform housekeeping tasks that require high coordination and dexterity, like folding clothes and cleaning tables. The company also announced $400 million in investments from OpenAI, Jeff Bezos, and several Silicon Valley venture capital firms.
How it works: π0 is a version of the pretrained PaliGemma vision-language model that has been modified for flow matching. (Flow matching is similar to diffusion, in which a model learns to remove noise from inputs to which noise has been added, and ultimately generates output by removing noise from an input of pure noise). A user supplies a text command, and the robot uses its sensor inputs to remove noise from a pure-noise action embedding to generate an appropriate action.
- PaliGemma comprises SigLIP, a vision transformer that turns images into embeddings; a linear layer that adapts the image embeddings to serve as input for the pretrained large language model Gemma; and Gemma, which estimates the noise to be removed from a robot action embedding to which noise has been added.
- The authors modified PaliGemma as follows: (i) They adapted it to accept embeddings that represent the robots’ state and previous actions, and to generate embeddings that represent the noise to be removed from noisy robot actions. (ii) They added a vanilla neural network to the input to turn the current timestep into an embedding. (iii) They modified Gemma to be a mixture-of-experts model: One expert, or subset of weights, is the pretrained weights, which process image and text embeddings. The other is a new set of weights that process robot action embeddings.
- They pretrained π0 to remove noise from action embeddings. (Since π0 produces embeddings of the noise to be removed, removing that noise is as simple as adding the two embeddings.)
- Training data included the Open X-Embodiment Dataset and a proprietary dataset of 10,000 hours of robotic states (for instance, current positions of a robot’s joints), actions (for instance, motions of the robot’s joints), and an associated language command. The proprietary dataset included data collected from seven different robots (such as a single stationary robot arm to two robot arms mounted on a mobile base) and 68 tasks (for example, folding laundry, making coffee, or bussing a table).
- After pretraining, the authors fine-tuned π0 to remove noise from action tokens in 15 further tasks, some of which were not represented in the pretraining set. These tasks improved the model’s ability to follow more detailed instructions and perform multi-stage tasks such as packing food into a to-go box.
- At inference, given the robot’s camera view of the surrounding scene, SigLip embeds the images. A linear layer projects the resulting embeddings to fit Gemma’s expected input size and data distribution. Given the images, text command, robot’s state, current timestep, and 50 noisy action tokens (starting with pure noise), Gemma iteratively removes noise. To complete longer tasks, the process repeats: The robot takes more images of the surrounding scene and retrieves the robot’s state, which π0 uses to generate further actions.
Results: π0 outperformed the open robotics models OpenVLA, Octo, ACT, and Diffusion Policy, all of which were fine-tuned on the same data, on all tasks tested, as measured by a robot’s success rate in completing each task. For example, using a single robotic arm to stack a set of bowls of four sizes, π0 completed about 100 percent on average. Diffusion Policy completed about 55 percent, ACT about 45 percent, and OpenVLA and Octo below 10 percent. Across all tasks, π0 completed about 80 percent on average, while Diffusion Policy completed about 35 percent on average.
Yes, but: The robot occasionally makes mistakes. In one video, it puts too many eggs into a carton and tries to force it shut. In another, it throws a container off a table instead of filling it with items.
Behind the news: Commercial robotics appears to be undergoing a renaissance. Skild raised $300 million to develop a “general-purpose brain for robots.” Figure AI secured $675 million to build humanoid robots powered by multimodal models. Covariant, which specializes in industrial robotics, licensed its technology to Amazon. (Disclosure: Andrew Ng is a member of Amazon's board of directors). OpenAI renewed its robotics effort after dismantling its robotics department in 2020.
Why it matters: Robots have been slow to benefit from machine learning, but the generative AI revolution is driving rapid innovations that make them much more useful. Large language models have made it possible to command robots using plain English. Meanwhile, the team at Physical Intelligence collected a dataset of sufficient size and variety to train the model to generate highly articulated and practical actions. Household robots may not be right around the corner, but π0 shows that they can perform tasks that people need done.
We’re thinking: One of the team members compared π0 to GPT-1 for robotics — an inkling of things to come. Although there are significant differences between text data (which is available in large quantities) and robot data (which is hard to get and varies per robot), it looks like a new era of large robotics foundation models is dawning.
AI Power Couple Recommits
Amazon and Anthropic expanded their partnership, potentially strengthening Amazon Web Services’ AI infrastructure and lengthening the high-flying startup’s runway.
What’s new: Amazon, already a significant investor in Anthropic, put another $4 billion into the AI company. In exchange, Anthropic will train and run its AI models on Amazon’s custom-designed chips. (Disclosure: Andrew Ng serves on Amazon’s board of directors.)
How it works: The new round brings Amazon’s investment in Anthropic to $8 billion (though it remains a minority stake without a seat on the startup’s board). The deal extended the partnership in several ways:
- AWS becomes Anthropic’s primary partner for training AI models. Anthropic will train its models using Amazon’s Trainium chips, which are designed for training neural networks of 100 billion parameters and up. Amazon executives previously claimed that these chips could cut training costs by as much as 50 percent compared to Nvidia graphics processing units (GPUs).
- Previously Anthropic ran its Claude models on Nvidia hardware; going forward, Anthropic will run them on Amazon’s Inferentia chips, according to The Information. Customers of Amazon Web Services will be able to fine-tune Claude on Bedrock, Amazon Web Services’ AI model platform.
- Anthropic will contribute to developing Amazon’s Neuron toolkit, software that accelerates deep learning workloads on Trainium and Inferentia chips.
Behind the news: In November, Anthropic agreed to use Google’s cloud-computing infrastructure in return for a $2 billion investment. The previous month, Amazon had committed to invest as much as $4 billion in Anthropic, and Anthropic had made Amazon Web Services the primary provider of its models.
Yes, but: The UK’s Competition and Markets Authority recently cleared both Amazon’s and Google’s investments in Anthropic, but regulators continue to monitor such arrangements for violations of antitrust laws. Microsoft and OpenAI face a similar investigation by the European Commission and U.S. Federal Trade Commission.
Why it matters: The speed and skill required to build state-of-the-art AI models is driving tech giants to collaborate with startups, while the high cost is driving startups to partner with tech giants. If the partnership between Amazon and Anthropic lives up to its promise, Claude users and developers could see gains in performance and efficiency. This could validate Amazon's hardware as a competitor with Nvidia and strengthen Amazon Web Services’ position in the cloud market. On the other hand, if Claude faces any challenges in scaling while using Trainium and Inferentia, that could affect both companies' ambitions.
We’re thinking: Does the agreement between Amazon and Anthropic give the tech giant special access to the startup’s models for distillation, research, or integration, as the partnership between Microsoft and OpenAI does? The companies’ announcements don’t say.

Object Detection for Small Devices
An open source model is designed to perform sophisticated object detection on edge devices like phones, cars, medical equipment, and smart doorbells.
What’s new: Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, and colleagues at the International Digital Economy Academy introduced Grounding DINO 1.5, a system that enables devices with limited processing power to detect arbitrary objects in images based on a text list of objects (also known as open-vocabulary object detection). You can download the code and weights here.
Key insight: The original Grounding DINO follows many of its predecessors by using image embeddings of different levels (from lower-level embeddings produced by an image encoder’s earlier layers, which are larger and represent simple patterns such as edges, to higher-level embeddings produced by later layers, which are smaller and represent complex patterns such as objects). This enables it to better detect objects at different scales. However, it takes a lot of computation. To enable the system to run on devices that have less processing power, Grounding DINO 1.5 uses only the smallest (highest-level) image embeddings for a crucial part of the process.
How it works: Grounding DINO 1.5 is made up of components that produce text and image embeddings, fuse them, and classify them. It follows the system architecture and training of Grounding DINO with the following exceptions: (i) It uses a different image encoder, (ii) a different model combines text and image embeddings, and (iii) it was trained on a newer dataset of 20 million publicly available text-image examples.
- Given an image, a pretrained EfficientViT-L1 image encoder produced three levels of image embeddings.
- Given the corresponding text, BERT produced a text embedding composed of tokens.
- Given the highest-level image embedding and the text embedding, a cross-attention model updated each one to incorporate information from the other (fusing text and image modalities, in effect). After the update, a CNN-based model combined the updated highest-level image embedding with the lower-level image embeddings to create a single image embedding.
- Grounding DINO 1.5 calculated which 900 tokens in the image embedding were most similar to the tokens in the text embedding.
- A cross-attention model detected objects using both the image and text embeddings. For each token in the updated image embedding, it determined: (i) which text token(s), if any, matched the image token, thereby giving each image token a classification including “not an object” and (ii) a bounding box that enclosed the corresponding object (except for tokens that were labeled “not an object”).
- The system learned to (i) maximize the similarity between matching tokens from the text and image embeddings and minimize the similarity between tokens that didn’t match and (ii) minimize the difference between its own bounding boxes and those in the training dataset.
Results: Grounding DINO 1.5 performed significantly faster than the original Grounding DINO: 10.7 frames per second versus 1.1 frames per second running on an Nvidia Jetson Orin NX computer. Tested on a dataset of images of common objects annotated with labels and bounding boxes, Grounding DINO 1.5 achieved better average precision (a measure of how many objects it identified correctly in their correct location, higher is better) than both Grounding DINO and YOLO-Worldv2-L (a CNN-based object detector). Grounding DINO 1.5 scored 33.5 percent, Grounding DINO 27.4 percent, and YOLO-Worldv2-L 33 percent.
Why it matters: The authors achieved 10 times the speed with just a couple of small changes (a more efficient image encoder and a smaller image embedding when performing cross-attention between embeddings of images and texts). Small changes can yield big results.
We’re thinking: Lately model builders have been building better, smaller, faster large language models for edge devices. We’re glad to see object detection get similar treatment.