
Dear friends,
There’s a lingering misconception that building with generative AI is expensive. It is indeed expensive to train cutting-edge foundation models, and a number of companies have spent billions of dollars doing this (and even released some of their models as open weights). But as a result, it’s now very inexpensive to build a wide range of AI applications.
The AI stack has several layers, shown in the diagram below. Here are the lower layers, from the bottom up:
- Semiconductors. Nvidia has been a huge benefactor in this space. AMD’s MI300 and forthcoming MI350 are also strong alternatives to the Nvidia H100 and the delayed Blackwell chips.
- Cloud. AWS (disclosure: I serve on Amazon’s board of directors), Google Cloud, and Microsoft Azure make it easy for developers to build.
- Foundation models. This includes both proprietary models such as OpenAI’s and Anthropic’s, and open weights models such as Meta’s Llama.
The foundation model layer frequently appears in headlines because foundation models cost so much to build. Some companies have made massive investments in training these models, and a few of those have added to the hype by pointing out that paying lots for compute and data would lead (probably) to predictably better performance following scaling laws.
This layer is also currently hyper-competitive, and switching costs for application developers to move from one model to another are fairly low (for example, requiring changes to just a few lines of code). Sequoia Capital’s thoughtful article on “AI's $600B Question” points out that, to justify massive capital investments in AI infrastructure (particularly GPU purchases and data center buildouts), generative AI needs to get around $600B of revenue. This has made investing at the foundation model layer challenging. It’s expensive, and this sector still needs to figure out how to deliver returns. (I’m cautiously optimistic it will work out!)

On top of this layer is an emerging orchestration layer, which provides software that helps coordinate multiple calls to LLMs and perhaps to other APIs. This layer is becoming increasingly agentic. For example, Langchain has helped many developers build LLM applications, and its evolution into LangGraph for building agents has been a great development. Other platforms such as Autogen, MemGPT, and CrewAI (disclosure: I made a personal investment in CrewAI) are also making it easier to build agentic workflows. Switching costs for this layer are much higher than for the foundation model layer, since, if you’ve built an agent on one of these frameworks, it’s a lot of work to switch to a different one. Still, competition in the orchestration layer, as in the foundation model layer, seems intense.
Finally, there’s the application layer. Almost by definition, this layer has to do better financially than all the layers below. In fact, for investments at the lower layers to make financial sense, the applications had better generate even more revenue, so the application vendors can afford to pay providers of infrastructure, cloud computing, foundation models, and orchestration. (This is why my team AI Fund focuses primarily on AI application companies, as I discussed in a talk.)
Fortunately, because of the massive investments in foundation models, it’s now incredibly inexpensive to experiment and build prototypes in the applications layer! Over Thanksgiving holiday, I spent about one and a half days prototyping different generative AI applications, and my bill for OpenAI API calls came out to about $3. On my personal AWS account, which I use for prototyping and experimentation, my most recent monthly bill was $35.30. I find it amazing how much fun you can have on these platforms for a small number of dollars!
By building on widely available AI tools, AI Fund now budgets $55,000 to get to a working prototype. And while that is quite a lot of money, it’s far less than the billions companies are raising to develop foundation models. Individuals and businesses can experiment and test important ideas at reasonable cost.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Starting your career in AI has never been easier with Machine Learning Specialization, a foundational program for beginners in machine learning. Get started!
News
Agents Open the Wallet
One of the world’s biggest payment processors is enabling large language models to spend real money.
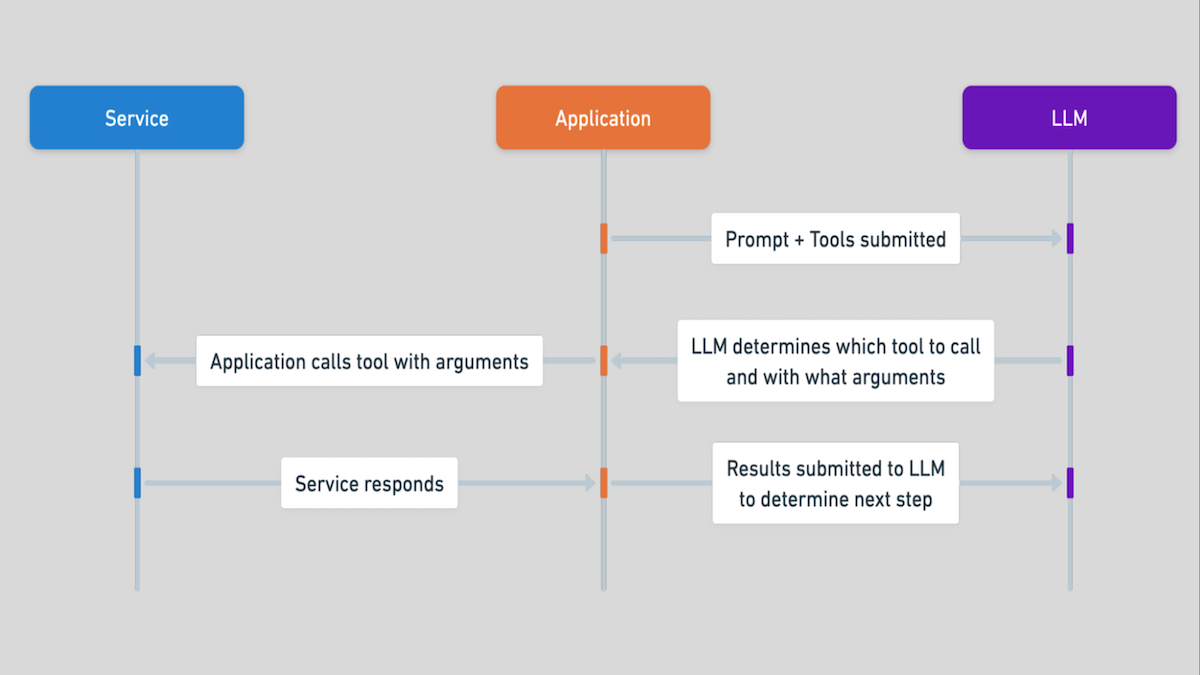
What’s new: Stripe announced Stripe Agent Toolkit, a library for Python and Typescript that supports agentic workflows that use API calls to execute monetary transactions. You can download it here.
How it works: An agentic purchasing workflow may look like this: A user asks the agent to find a flight to a certain destination, on a certain schedule, with a certain price limit; and an LLM queries a flight database, chooses a flight, obtains authorization from the user, and purchases the flight. Stripe Agent Toolkit supports agentic workflow frameworks from CrewAI, LangChain, and Vercel. It doesn’t yet implement all of Stripe’s API, but Stripe expects to extend it in the future.
- The library can issue virtual debit cards for one-time use, so applications based on LLMs can spend money only when you want them to.
- It also authorizes transactions in real time, so you can present intended purchases to an end user for approval before an agent executes them.
- It can track the LLM’s use of tokens per customer, so you can bill clients for costs they incur while using agents you’ve built.
- Stripe provides restricted API keys, so you can limit the range of API calls an LLM is allowed to request.
Why it matters: Agents that can spend money securely open a wide variety of applications. Stripe’s API previously made it possible to enable an LLM-based application to make purchases online, but doing so required trusting the LLM to generate the right API calls and not to make inappropriate ones. The new library makes it easier to enforce spending limits and API constraints, and thus to build agents that engage in ecommerce safely.
We’re thinking: Stripe’s offering helps developers build agents that are cents-ible!
Mistral’s Vision-Language Contender
Mistral AI unveiled Pixtral Large, which rivals top models at processing combinations of text and images.
What’s new: Pixtral Large outperforms a number of leading vision-language models on some tasks. The weights are free for academic and non-commercial use and can be licensed for business use. Access is available via Mistral AI’s website or API for $2/$6 per million tokens for input/output. In addition, Pixtal Large now underpins le Chat, Mistral AI’s chatbot, which also gained several new features.
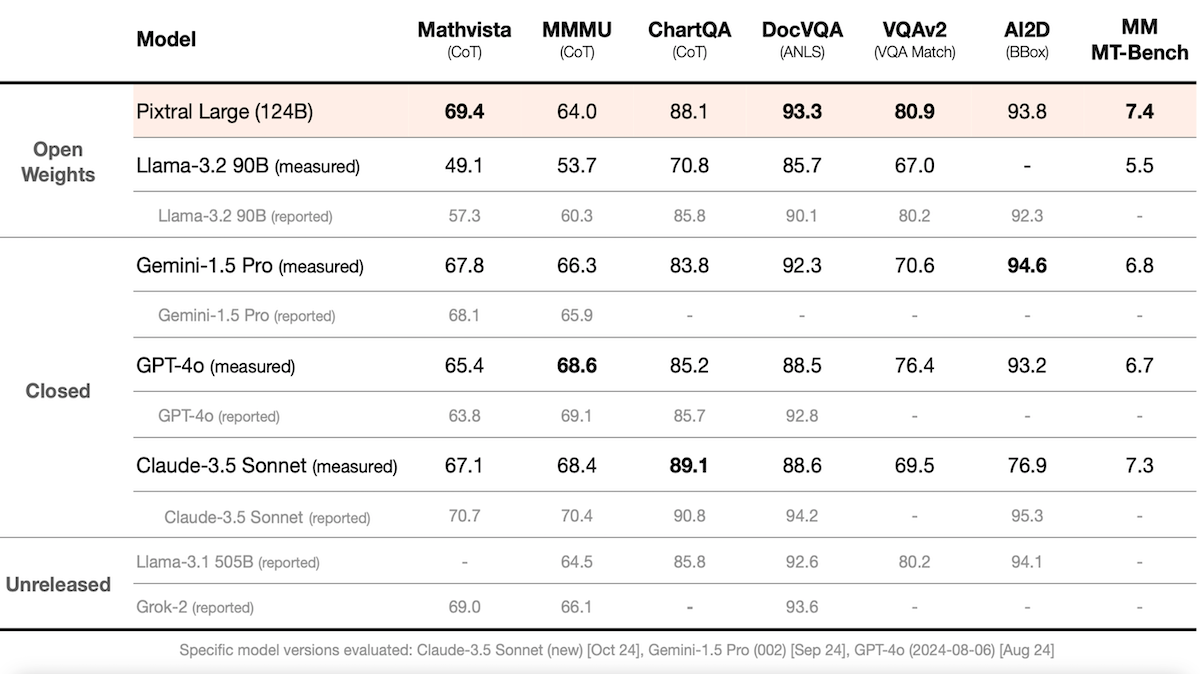
How it works: Pixtral Large generates text in response to text and images in dozens of languages. It processes 131,072 tokens of context, which is sufficient to track relationships among 30 high-resolution images at a time. Based on Mistral Large 2 (a 123 billion-parameter large language model) and a 1 billion-parameter vision encoder, it demonstrates strong performance across several benchmarks (as reported by Mistral).
- Mistral compared Pixtral Large to the open weights Llama 3.2 90B and the closed models Gemini-1.5 Pro, GPT-4o, and Claude-3.5 Sonnet. In Mistral’s tests (as opposed to the other model providers’ reported results, which differ in some cases), Pixtral Large achieved the best performance on four of eight benchmarks that involved analyzing text and accompanying visual elements.
- For instance, on MathVista (math problems that involve visual elements, using chain-of-thought prompting), it achieved 69.4 percent accuracy, while Gemini 1.5 Pro, the next-best model in Mistral AI’s report, achieved 67.8 percent accuracy. (Claude 3.5 Sonnet outperforms Pixtral-Large on this benchmark according to Anthropic’s results. So do OpenAI o1 and Claude-3.5 Sonnet, according to their developers’ results, which Mistral did not include in its presentation.)
- Pixtral Large powers new features of le Chat including PDF analysis for complex documents and a real-time interface for creating documents, presentations, and code, similar to Anthropic’s Artifacts and OpenAI’s Canvas. Le Chat also gained beta-test features including image generation (via Black Forest Labs’ Flux.1), web search with source citations (using Mistral’s proprietary search engine), and customizable agents that can perform tasks like scanning receipts, summarizing meetings, and processing invoices. These new features are available for free.
Behind the news: Pixtral Large arrives as competition intensifies among vision-language models. Meta recently entered the field with Llama 3.2 vision models in 11B and 90B variants. Both Pixtral Large and Llama 3.2 90B offer open weights, making them smaller and more widely available than Anthropic’s, Google’s, or OpenAI’s leading vision-language models. However, like those models, Pixtral Large falls short of the reported benchmark scores of the smaller, more permissively licensed Qwen2-VL 72B.
Why it matters: Pixtral Large and updates to le Chat signal that vision-language capabilities — combining text generation, image recognition, and visual reasoning — are essential to compete with the AI leaders. In addition, context windows of 129,000 tokens and above have become more widely available, making it possible to analyze lengthy (or multiple) documents that include text, images, and graphs as well as video clips.
We’re thinking: Mistral is helping to internationalize development of foundation models. We’re glad to see major developers emerging in Europe!

Garbage Out
Rapid progress in generative AI comes with a hidden environmental cost: mountains of obsolete hardware.
What’s new: A study projects that servers used to process generative AI could produce millions of metric tons of electronic waste by 2030. Extending server lifespans could reduce the burden substantially, according to author Peng Weng and colleagues at the Chinese Academy of Sciences and Reichman University.
How it works: The study extrapolated from publicly available data to model accumulation of electronic waste, or e-waste, between 2023 and 2030. The authors examined four scenarios: One scenario assumed linear growth in which hardware manufacturing expands at the current rate of 41 percent annually. The other three assumed exponential growth of demand for computing: conservative (85 percent annually), moderate (115 percent annually), and aggressive (136 percent annually). The study evaluated each scenario with and without measures taken to reduce waste.
- In the linear-growth scenario, e-waste could add up to 1.2 million metric tons between 2023 and 2030. In the aggressive scenario, the total could reach 5 million metric tons, or roughly 1 percent of total electronic waste during that period. (These figures don’t account for mitigations, which would improve the numbers, or ongoing manufacturing of earlier, less efficient technology, which would exacerbate them.)
- The study assumed that servers typically would be discarded after three years. Upgrading servers more frequently, when improved hardware becomes available, would reduce overall server numbers because fewer servers would deliver greater processing power. However, because servers would be discarded more quickly, it could add a cumulative 1.2 million metric tons in the linear scenario or 2.3 million metric tons in the aggressive scenario, assuming no mitigation measures are taken.
- U.S. trade restrictions on advanced chips are also likely to exacerbate the problem. They could push affected countries to rely on less-efficient hardware designs and thus require more new servers to reach a competitive processing capacity. This could increase total waste by up to 14 percent.
- The authors explored several approaches to reducing e-waste. Repurposing equipment for non-AI applications and reusing critical components like GPUs and CPUs could cut e-waste by 42 percent. Improving the power efficiency of chips and optimizing AI models could reduce e-waste by 16 percent.
- The most promising approach to reducing e-waste is to extend server lifespans. Adding one year to a server’s operational life could reduce e-waste by 62 percent.
Why it matters: E-waste is a problem not only due to its sheer quantity. Server hardware contains materials that are both hazardous and valuable. Discarded servers contain toxic substances like lead and chromium that can find their way into food water supplies. They also contain valuable metals, such as gold, silver, and platinum, that could save the environmental and financial costs of producing more of them. Proper recycling of these components could yield $14 billion to $28 billion, highlighting both the economic potential and the urgent need to develop and deploy advanced recycling technologies.
We’re thinking: Humanity dumps over 2 billion metric tons of waste annually, so even comprehensive recycling and repurposing of AI hardware and other electronic devices would make only a small dent in the overall volume. However, the high density of valuable materials in e-waste could make mining such waste profitable and help recycle waste into valuable products, making for a more sustainable tech economy.
Breaking Jailbreaks
Jailbreak prompts can prod a large language model (LLM) to overstep built-in boundaries, leading it to do things like respond to queries it was trained to refuse to answer. Researchers devised a way to further boost the probability that LLMs will respond in ways that respect such limits.
What’s new: Jingtong Su, Julia Kempe, and Karen Ullrich at New York University and MetaAI improved model behavior via E-DPO. Their method modifies Direct Preference Optimization (DPO), a popular way to align models with human preferences.
Key insight: DPO fine-tunes a model to encourage a developer’s notion of good behavior and suppress bad behavior, but it must also ensure that the model doesn’t forget knowledge it learned during pretraining. To this end, DPO’s loss function includes a regularization constraint that encourages the model to produce token probabilities similar to those it produced prior to fine-tuning. However, this causes the model to retain not only desired knowledge but also undesired knowledge that may lead it to produce an unwanted response. We can reduce the probability that it will draw on such undesired knowledge by changing the regularization constraint. The idea is to ensure similar token probabilities between (a) a model prior to fine-tuning, asked to behave harmlessly prior to receiving the harmful prompt and (b) the fine-tuned model, given a harmful prompt. This adjustment helps the fine-tuned model deliver outputs based on benign knowledge, along with the usual benefits of DPO.
How it works: The authors used E-DPO to further fine-tune Mistral-7b-sft-constitutional-ai (which is aligned using the technique known as constitutional AI) on two datasets in which each example consists of a prompt, a preferred response, and an objectionable response.
- The authors prompted GPT-3.5 Turbo to classify harmful prompts in the datasets.
- They fine-tuned the model according to DPO but, when the input was classified as harmful, they computed the regularization constraint differently. The updated regularization constraint encouraged the fine-tuned model’s token probabilities to be similar to those assigned by the original model after prompting it to “adhere to community guidelines and ethical standards.”
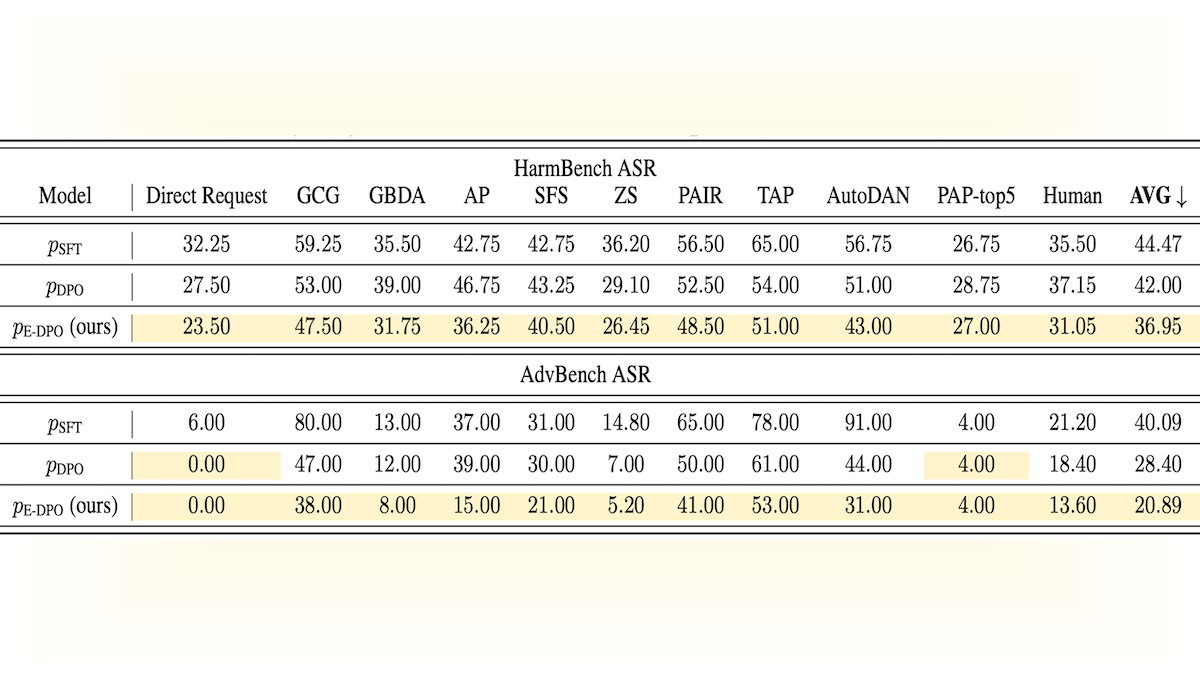
Results: E-DPO reduced Mistral-7b-SFT-constitutional-ai’s average attack success rate (ASR, the percentage of times a jailbreak prompt successfully elicited an objectionable responses) across 11 jailbreak datasets and methods (two sets of human-proposed jailbreak prompts and a variety of automatic jailbreak prompt-finding methods) from the HarmBench benchmark. The fine-tuned model achieved 36.95 ASR, while prior to fine-tuning it achieved 44.47 ASR. Typical DPO reduced the average ASR to 42.00.
Why it matters: We can’t train a model to respond in a desirable way to all jailbreaks, no matter how big the training dataset. The space of potential jailbreaks is practically unlimited. Instead, it’s necessary to alter training methods, as this work does.
We’re thinking: Humans, like learning algorithms, can circumvent social norms when they encounter a harmful request (attack your neighbors) cloaked in a manipulative scenario (to uphold religious or nationalistic values). While we work on aligning models with human preferences, let’s make sure we ourselves are aligned, too.