
Dear friends,
AI Product Management is evolving rapidly. The growth of generative AI and AI-based developer tools has created numerous opportunities to build AI applications. This is making it possible to build new kinds of things, which in turn is driving shifts in best practices in product management — the discipline of defining what to build to serve users — because what is possible to build has shifted. In this letter, I’ll share some best practices I have noticed.
Use concrete examples to specify AI products. Starting with a concrete idea helps teams gain speed. If a product manager (PM) proposes to build “a chatbot to answer banking inquiries that relate to user accounts,” this is a vague specification that leaves much to the imagination. For instance, should the chatbot answer questions only about account balances or also about interest rates, processes for initiating a wire transfer, and so on? But if the PM writes out a number (say, between 10 and 50) of concrete examples of conversations they’d like a chatbot to execute, the scope of their proposal becomes much clearer. Just as a machine learning algorithm needs training examples to learn from, an AI product development team needs concrete examples of what we want an AI system to do. In other words, the data is your PRD (product requirements document)!
In a similar vein, if someone requests “a vision system to detect pedestrians outside our store,” it’s hard for a developer to understand the boundary conditions. Is the system expected to work at night? What is the range of permissible camera angles? Is it expected to detect pedestrians who appear in the image even though they’re 100m away? But if the PM collects a handful of pictures and annotates them with the desired output, the meaning of “detect pedestrians” becomes concrete. An engineer can assess if the specification is technically feasible and if so, build toward it. Initially, the data might be obtained via a one-off, scrappy process, such as the PM walking around taking pictures and annotating them. Eventually, the data mix will shift to real-word data collected by a system running in production.
Using examples (such as inputs and desired outputs) to specify a product has been helpful for many years, but the explosion of possible AI applications is creating a need for more product managers to learn this practice.
Assess technical feasibility of LLM-based applications by prompting. When a PM scopes out a potential AI application, whether the application can actually be built — that is, its technical feasibility — is a key criterion in deciding what to do next. For many ideas for LLM-based applications, it’s increasingly possible for a PM, who might not be a software engineer, to try prompting — or write just small amounts of code — to get an initial sense of feasibility.

For example, a PM may envision a new internal tool for routing emails from customers to the right department (such as customer service, sales, etc.). They can prompt an LLM to see if they can get it to select the right department based on an input email, and see if they can achieve high accuracy. If so, this gives engineering a great starting point from which to implement the tool. If not, the PM can falsify the idea themselves and perhaps improve the product idea much faster than if they had to rely on an engineer to build a prototype.
Often, testing feasibility requires a little more than prompting. For example, perhaps the LLM-based email system needs basic RAG capability to help it make decisions. Fortunately, the barrier to writing small amounts of code is now quite low, since AI can help by acting as a coding companion, as I describe in the course, “AI Python for Beginners.” This means that PMs can do much more technical feasibility testing, at least at a basic level, than was possible before.
Prototype and test without engineers. User feedback to initial prototypes is also instrumental to shaping products. Fortunately, barriers to building prototypes rapidly are falling, and PMs themselves can move prototypes forward without needing software developers.
In addition to using LLMs to help write code for prototyping, tools like Replit, Vercel’s V0, Bolt, and Anthropic’s Artifacts (I’m a fan of all of these!) are making it easier for people without a coding background to build and experiment with simple prototypes. These tools are increasingly accessible to non-technical users, though I find that those who understand basic coding are able to use them much more effectively, so it’s still important to learn basic coding. (Interestingly, highly technical, experienced developers use them too!) Many members of my teams routinely use such tools to prototype, get user feedback, and iterate quickly.
AI is enabling a lot of new applications to be built, creating massive growth in demand for AI product managers who know how to scope out and help drive progress in building these products. AI product management existed before the rise of generative AI, but the increasing ease of building applications is creating greater demand for AI applications, and thus a lot of PMs are learning AI and these emerging best practices for building AI products. I find this discipline fascinating, and will keep on sharing best practices as they grow and evolve.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Write and code more effectively with OpenAI Canvas, a user-friendly workspace for collaborating with AI. In this free course, explore use cases like building game apps and designing SQL databases from screenshots, and gain insights into how GPT-4o powers Canvas’ features. Join for free
News
Competitive Performance, Competitive Prices
Amazon introduced a range of models that confront competitors head-on.
What’s new: The Nova line from Amazon includes three vision-language models (Nova Premier, Nova Pro, and Nova Lite), one language model (Nova Micro), an image generator (Nova Canvas), and a video generator (Nova Reel). All but Nova Premier are available on Amazon’s Bedrock platform, and Nova Premier, which is the most capable, is expected in early 2025. In addition, Amazon plans to release a speech-to-speech model in early 2025 and a multimodal model that processes text, images, video, and audio by mid-year. (Disclosure: Andrew Ng serves on Amazon’s board of directors.)
How it works: Nova models deliver competitive performance at relatively low prices. Amazon hasn’t disclosed parameter counts or details about how the models were built except to say that Nova Pro, Lite, and Micro were trained on a combination of proprietary, licensed, public, and open-source text, images, and video in over 200 languages.
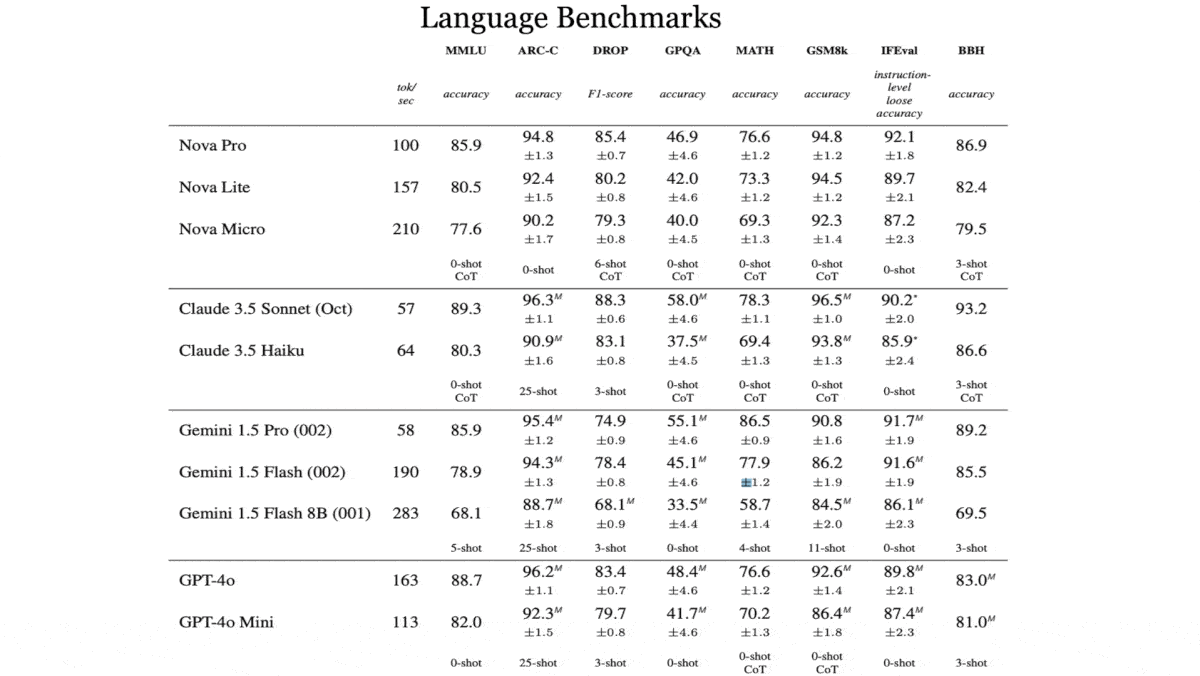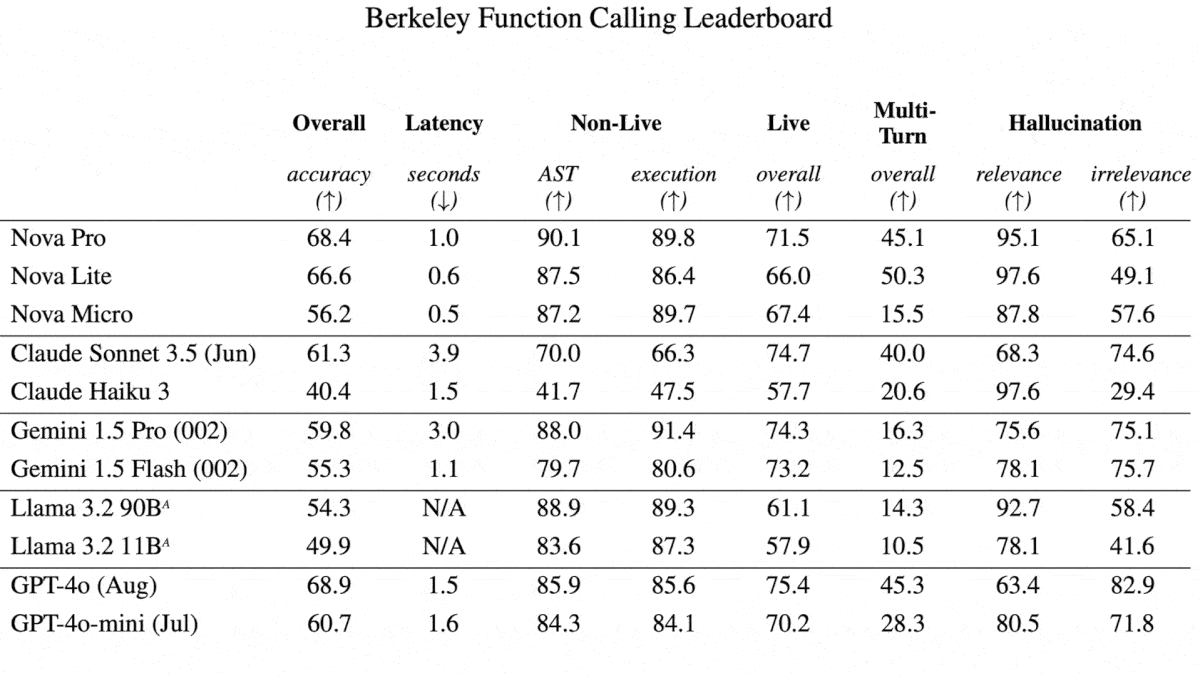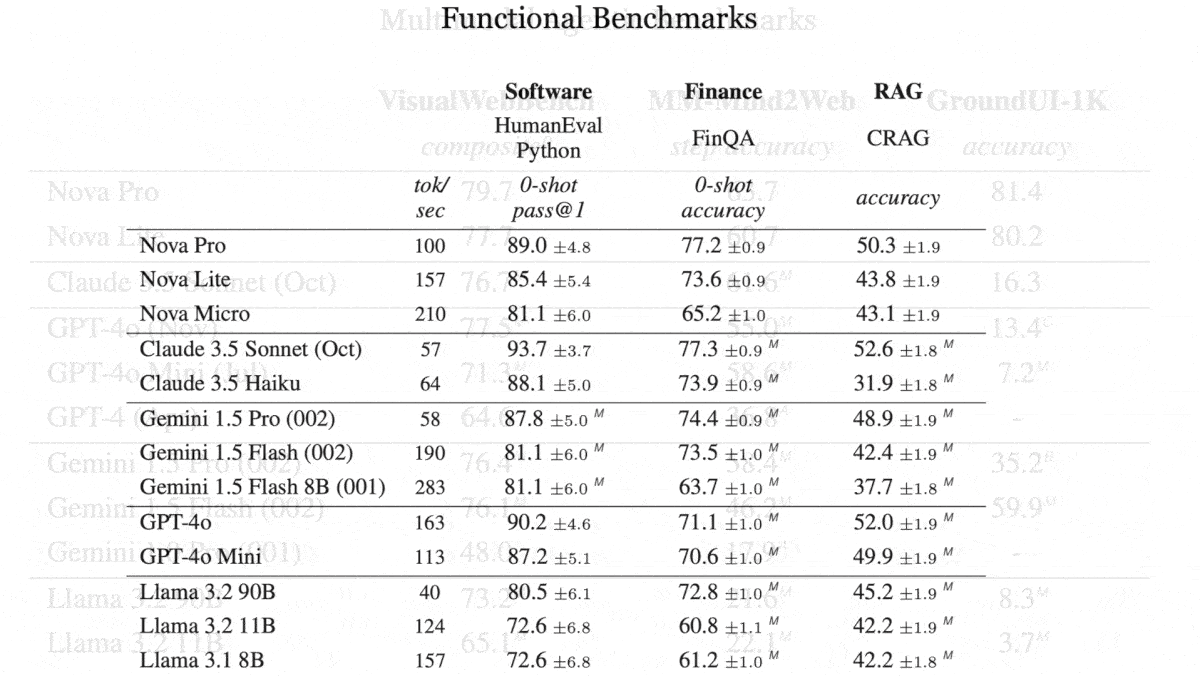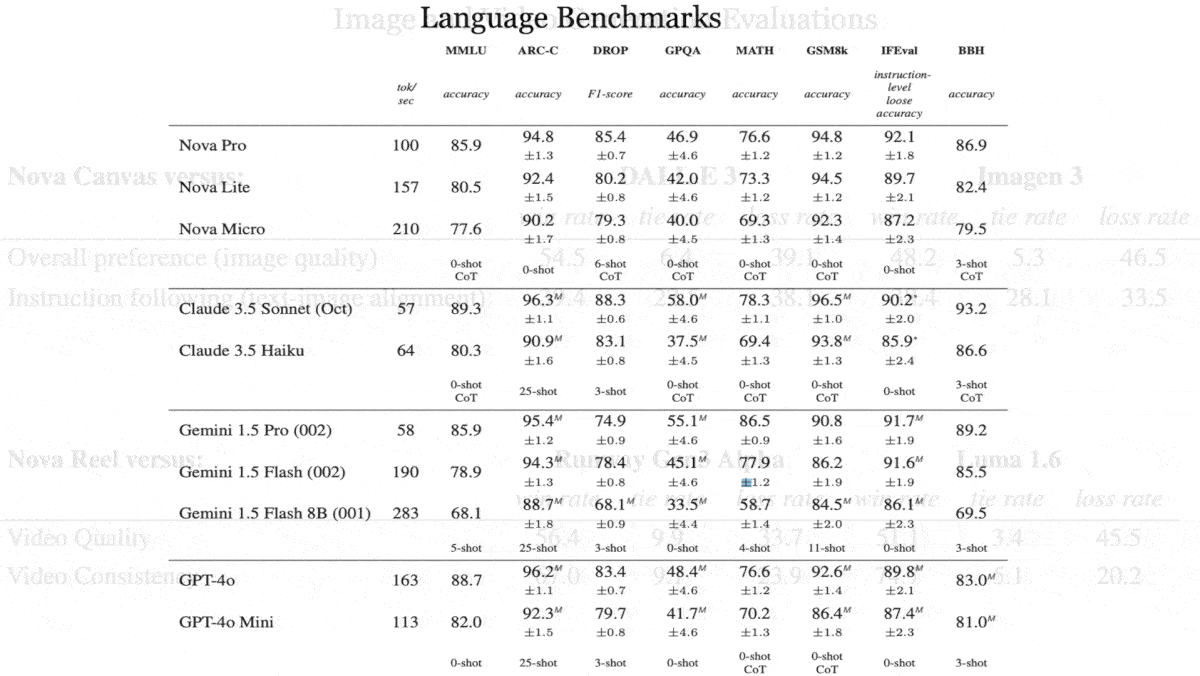
- Nova Pro is roughly comparable to that of Anthropic Claude 3.5 Sonnet, OpenAI GPT-4o, and Google Gemini Pro. It has a 300,000-token input context window, enabling it to process relatively large vision-language inputs. Nova Pro outperforms its primary competitors in tests of following complex instructions (IFEval), summarizing long texts (SQuALITY), understanding videos (LVBench), and reading and acting on websites (MM-Mind2Web). It processes 95 tokens per second. At $0.80/$3.20 per million tokens of input/output, it’s significantly less expensive than GPT-4o ($2.50/$10) and Claude 3.5 Sonnet ($3/$15) but slower than GPT-4o (115 tokens per second).
- Nova Lite compares favorably with Anthropic Claude Haiku, Google Gemini 1.5 Flash, and OpenAI GPT-4o Mini. Optimized for processing speed and efficiency, it too has a 300,000 token input context window. Nova Lite bests Claude 3.5 Sonnet and GPT-4o on VisualWebBench, which tests visual understanding of web pages. It also beats Claude 3.5 Haiku, GPT-4o Mini, and Gemini 1.5 Flash in multimodal agentic tasks that include MM-Mind2Web and the Berkeley Function-Calling Leaderboard. It processes 157 tokens per second and costs $0.06/$0.24 per million tokens of input/output, making it less expensive than GPT-4o mini ($0.15/$0.60), Claude 3.5 Haiku ($0.80/$4), or Gemini 1.5 Flash ($0.075/$0.30), but slower than Gemini 1.5 Flash (189 tokens per second).
- Nova Micro is a text-only model with a 128,000-token context window. It exceeds Llama 3.1 8B and Gemini Flash 8B on all 12 tests reported by Amazon, including generating code (HumanEval) and reading financial documents (FinQA). It also beats the smaller Claude, Gemini, and Llama models on retrieval-augmented generation tasks (CRAG). It processes 210 tokens per second (the lowest latency among Nova models) and costs $0.035/$0.14 per million input/output tokens. That’s cheaper than Gemini Flash 8B ($0.0375/$0.15) and Llama 3.1 8B ($0.10/$0.10), but slower than Gemini Flash 8B (284.2 tokens per second).
- Nova Canvas accepts English-language text prompts up to 1,024 characters and produces images up to 4.2 megapixels in any aspect ratio. It also performs inpainting, outpainting, and background removal. It excels on ImageReward, a measure of human preference for generated images, surpassing OpenAI DALL·E 3 and Stability AI Stable Diffusion 3.5. Nova Canvas costs between $0.04 per image up to 1024x1024 pixels and $0.08 per image up to 2,048x2,048 pixels. Prices are hard to compare because many competitors charge by the month or year, but this is less expensive and higher-resolution than DALL·E 3 ($0.04 to $0.12 per image).
- Nova Reel accepts English-language prompts up to 512 characters and image prompts up to 720x1,280 pixels. It generates video clips of 720x1280 pixels up to six seconds long. It demonstrates superior ability to maintain consistent imagery from frame to frame, winning 67 percent of head-to-head comparisons with the next highest-scoring model, Runway Gen-3 Alpha. Nova Reel costs $0.08 per second of output, which is less expensive than Runway Gen-3 Alpha ($0.096 per second) and Kling 1.5 ($0.12 per second) in their standard monthly plans.
Behind the news: The company launched Bedrock in April 2023 with Stability AI’s Stable Diffusion for image generation, Anthropic’s Claude and AI21’s Jurassic-2 for text generation, and its own Titan models for text generation and embeddings. Not long afterward, it added language models from Cohere as well as services for agentic applications and medical applications. It plans to continue to provide models from other companies (including Anthropic), offering a range of choices.
Why it matters: While other AI giants raced to outdo one another in models for text and multimodal processing, Amazon was relatively quiet. With Nova, it has staked out a strong position in those areas, as well as the startup-dominated domains of image and video generation. Moreover, it’s strengthening its cloud AI offerings with competitive performance, pricing, and speed. Nova’s pricing continues the rapid drop in AI prices over the last year. Falling per-token prices help make AI agents or applications that process large inputs more practical. For example, Simon Willison, developer of the Django Python framework for web applications, found that Nova Lite generated descriptions for his photo library (tens of thousands of images) for less than $10.
We’re thinking: The Nova suite is available via APIs as well as two web playgrounds (one in the Bedrock console, the other a new interface for building AI apps called PartyRock). This accords with Amazon Web Services’ focus on developers. For consumers, Amazon offers the earlier Rufus shopping bot; for enterprises, the Q assistant.
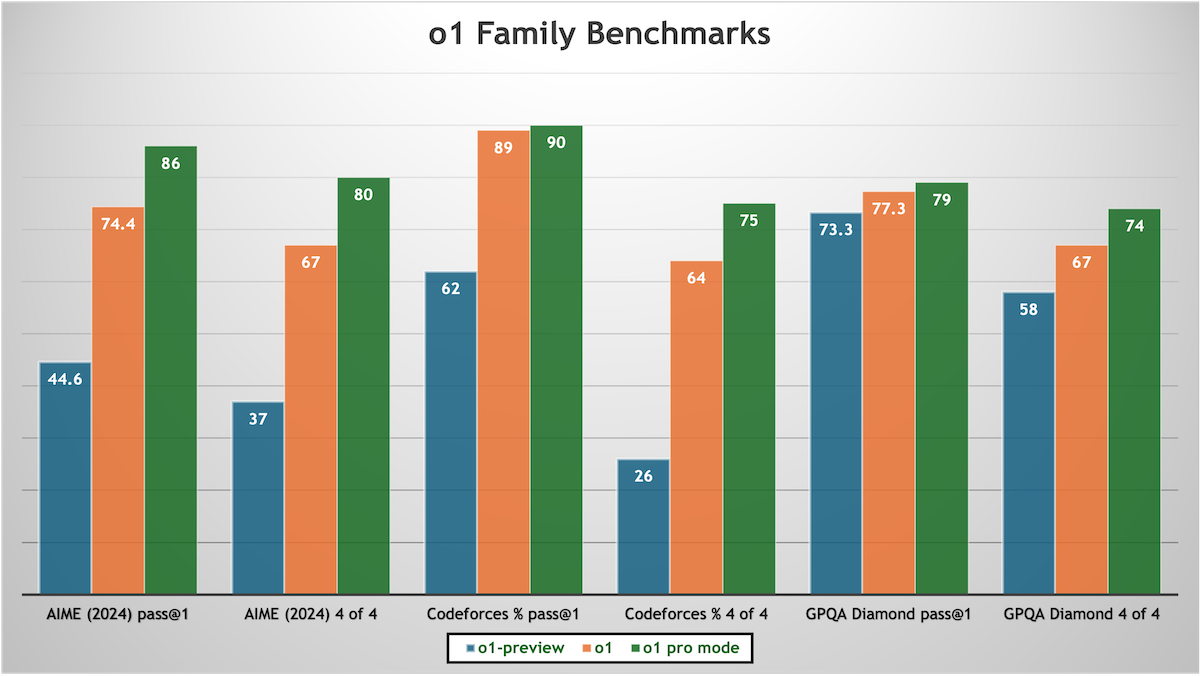
Higher Reasoning
OpenAI launched not only its highly anticipated o1 model but also an operating mode that enables the model to deliver higher performance — at a hefty price.
What’s new: Kicking off a 12-day holiday blitz, OpenAI launched o1 (previously available in preview and mini versions) and introduced o1 pro mode, which processes more tokens at inference to produce more accurate output. Both options accept text and image inputs to generate text outputs. They’re available exclusively through a new ChatGPT Pro subscription for $200 monthly. API access is not yet available.
How it works: According to an updated system card, o1 models were trained on a mix of public, licensed, and proprietary text, code, and images, with a focus on technical, academic, and structured datasets. They respond to prompts by breaking them down into intermediate steps, each of which consumes a number of hidden “reasoning tokens.” The models don’t reveal these steps, but ChatGPT presents a natural-language summary of the reasoning process. The new o1 and o1 pro mode perform better than o1-preview and o1-mini, but their additional reasoning requires more processing, which translates into higher costs and slower responses.
- o1 consistently outperforms o1-preview in one-shot benchmarks that measure accuracy in advanced math problems (AIME 2024), coding challenges (Codeforces), and graduate-level science questions (GPQA Diamond).
- o1 pro mode performs only slightly better than o1 on one-shot tests, but its higher accuracy is more evident when it’s asked to respond to the same input four times in a row. For example, given a problem from the American International Mathematics Examination, o1 solves it correctly 78 percent of the time, o1 pro mode 86 percent of the time. Given the same problem four times, o1 solves it correctly in all four tries 67 percent of the time, while o1 pro mode solves it correctly in all four tries 80 percent of the time.
- o1 and o1 pro mode are less prone to generating false or irrelevant information than o1-preview, as measured by OpenAI’s SimpleQA, which tests the ability to recall facts about science, geography, history, and the like, and PersonQA, which tests the ability to recall facts about people.
- ChatGPT Pro provides chatbot access to o1, o1 pro mode, and other OpenAI models. Subscribers get unlimited use of o1. OpenAI has not clarified whether o1 pro mode is subject to usage limits or other constraints.
Behind the news: Since September, when OpenAI introduced o1-preview and o1-mini, other model providers have implemented similar reasoning capabilities. DeepSeek’s R1 displays reasoning steps that o1 models keep hidden. Alibaba’s QwQ 32B excels at visual reasoning but is slower and has a smaller context window. Amazon’s Nova Premier, which is billed as a model for “complex reasoning tasks,” is expected in early 2025, but Amazon has not yet described its performance, architecture, or other details.
Why it matters: o1 and o1 pro mode highlight a dramatic shift in model development and pricing. Giving models more processing power at inference enables them to provide more accurate output, and it’s a key part of agentic workflows. It also continues to boost performance even as scaling laws that predict better performance with more training data and compute may be reaching their limits. However, it also raises OpenAI’s costs, and at $200 a month, the price of access to o1 and o1 pro is steep. It’s a premium choice for developers who require exceptional accuracy or extensive reasoning.
We’re thinking: Discovering scaling laws for using more processing at inference, or test-time compute, is an unsolved problem. Although OpenAI hasn’t disclosed the algorithm behind o1 pro mode, recent work at Google allocated tokens dynamically at inference based on a prompt’s difficulty. This approach boosted the compute efficiency by four times and enabled a model that had shown “nontrivial success rates” to outperform one that was 14 times larger.

Game Worlds on Tap
A new model improves on recent progress in generating interactive virtual worlds from still images.
What’s new: Jack Parker-Holder and colleagues from Google introduced Genie 2, which generates three-dimensional video game worlds that respond to keyboard inputs in real time. The model’s output remains consistent (that is, elements don’t morph or disappear) for up to a minute, and it includes first-person shooters, walking simulators, and driving games from viewpoints that include first person, third person, and isometric. Genie 2 follows up on Genie, which generates two-dimensional games.
How it works: Genie 2 is a latent diffusion model that generates video frames made up of an encoder, transformer, and decoder. The developers didn’t reveal how they built it or how they improved on earlier efforts.
- Given video frames, the encoder embeds them. Using those embeddings and keyboard input, the transformer generates the embedding of the next video frame. The decoder takes the new embedding and generates an image.
- At inference, given an image as the starting frame, the encoder embeds it. Given the embedding and keyboard input, the transformer generates the embedding of the next frame, which the decoder uses to generate an image. After the initial frame, the transformer uses embeddings it generated previously plus keyboard input to generate the next embedding.
Behind the news: Genie 2 arrives on the heels of Oasis, which generates a Minecraft-like game in real time. Unlike Oasis, Genie 2 worlds are more consistent and not limited to one type of game. It also comes at the same time as another videogame generator, World Labs. However, where Genie 2 generates the next frame given previous frames and keyboard input (acting, in terms of game development, as both graphics and physics engines), World Labs generates a 3D mesh of a game world from a single 2D image. This leaves the implementation of physics, graphics rendering, the player’s character, and other game mechanics to external software.
Why it matters: Genie 2 extends models that visualize 3D scenes based on 2D images to encompass interactive worlds, a capability that could prove valuable in design, gaming, virtual reality, and other 3D applications. It generates imagery that, the authors suggest, could serve as training data for agents to learn how to navigate and respond to commands in 3D environments.
We’re thinking: Generating gameplay directly in the manner of Genie 2 is a quick approach to developing a game, but the current technology comes with caveats. Developers can’t yet control a game’s physics or mechanics and they must manage any flaws in the model (such as a tendency to generate inconsistent worlds). In contrast, generating a 3D mesh, as World Labs does, is a more cumbersome approach, but it gives developers more control.

Getting the Facts Right
Large language models that remember more hallucinate less.
What’s new: Johnny Li and colleagues at Lamini introduced Mixture of Memory Experts (MoME), a method that enables large language models (LLMs) to memorize many facts with relatively modest computational requirements. (Disclosure: Andrew Ng invested in Lamini.)
Key insight: The key to getting factual answers from LLMs is to keep training it until it chooses the correct answer every time. In technical terms, train past the point where tokens relevant to the answer have a similar probability distribution, and continue until a single token has 100 percent probability. But this amount of training takes a lot of computation and, since the model may overfit the training set, it also may degrade performance on the test set. Fine-tuning is one solution, and fine-tuning a LoRA adapter to memorize facts reduces the computational burden. But a single LoRA adapter isn’t enough to store all of the knowledge in a large dataset. Training multiple adapters that are selected by cross-attention enables the LLM to memorize a variety of facts.
How it works: The authors extended a pretrained Llama-3-8B with a large number (on the order of 1 million) of LoRA adapters and a cross-attention layer. They froze Llama-3-8B and trained the LoRA adapters to predict the next token in a custom dataset of over 1 million questions and answers.
- For any given question, the model learned to select 32 LoRA adapters, each of which was associated with an embedding. The model selected adapters by performing cross-attention between an embedding of the input query and all adapter embeddings.
- The authors trained the LoRA adapters until they memorized all the answers as measured by the loss function (100 epochs).
- At inference, given a query, the model used cross-attention to select a subset of LoRA adapters and responded accordingly.
Results: The authors tested their LoRA-enhanced model’s ability to answer questions about a database via SQL queries. The model, which was outfitted for retrieval-augmented generation (RAG), achieved 94.7 percent accuracy. An unnamed model with RAG achieved 50 percent accuracy.
Yes, but: It stands to reason that the authors’ approach saves processing, but it’s unclear how much. The authors didn’t mention the cost of fine-tuning Llama-3-8B in the usual way on their training dataset for the same number of epochs.
Why it matters: The authors argue that eliminating hallucinations is possible in typical training, it’s just computationally very expensive (not to mention the risk of overfitting). An architecture designed to store and retrieve facts, via LoRA adapters in this case, makes the process more feasible.
We’re thinking: While some researchers want large language models to memorize facts, others want them to avoid memorizing their training data. These aims address very different problems. Preventing LLMs from memorizing training data would make them less likely to regurgitate it verbatim and thus violate copyrights. On the other hand, this work memorizes facts so the model can deliver consistent, truthful responses that might be stated in a variety of ways.