
Dear friends,
I’m thrilled that former students and postdocs of mine won both of this year’s NeurIPS Test of Time Paper Awards. This award recognizes papers published 10 years ago that have significantly shaped the research field. The recipients included Ian Goodfellow (who, as an undergraduate, built my first GPU server for deep learning in his dorm room) and his collaborators for their work on generative adversarial networks, and my former postdoc Ilya Sutskever and PhD student Quoc Le (with Oriol Vinyals) for their work on sequence-to-sequence learning. Congratulations to all these winners!
By nature, I tend to focus on the future rather than the past. Steve Jobs famously declined to build a corporate museum, instead donating Apple's archives to Stanford University, because he wanted to keep the company forward-looking. Jeff Bezos encourages teams to approach every day as if it were “Day 1,” a mindset that emphasizes staying in the early, innovative stage of a company or industry. These philosophies resonate with me.
But taking a brief look at the past can help us reflect on lessons for the future. One takeaway from looking at what worked 10 to 15 years ago is that many of the teams I led bet heavily on scaling to drive AI progress — a bet that laid a foundation to build larger and larger AI systems. At the time, the idea of scaling up neural networks was controversial, and I was on the fringe. I recall distinctly that, around 2008, Yoshua Bengio advised me not to bet on scaling and to focus on inventing algorithms instead!
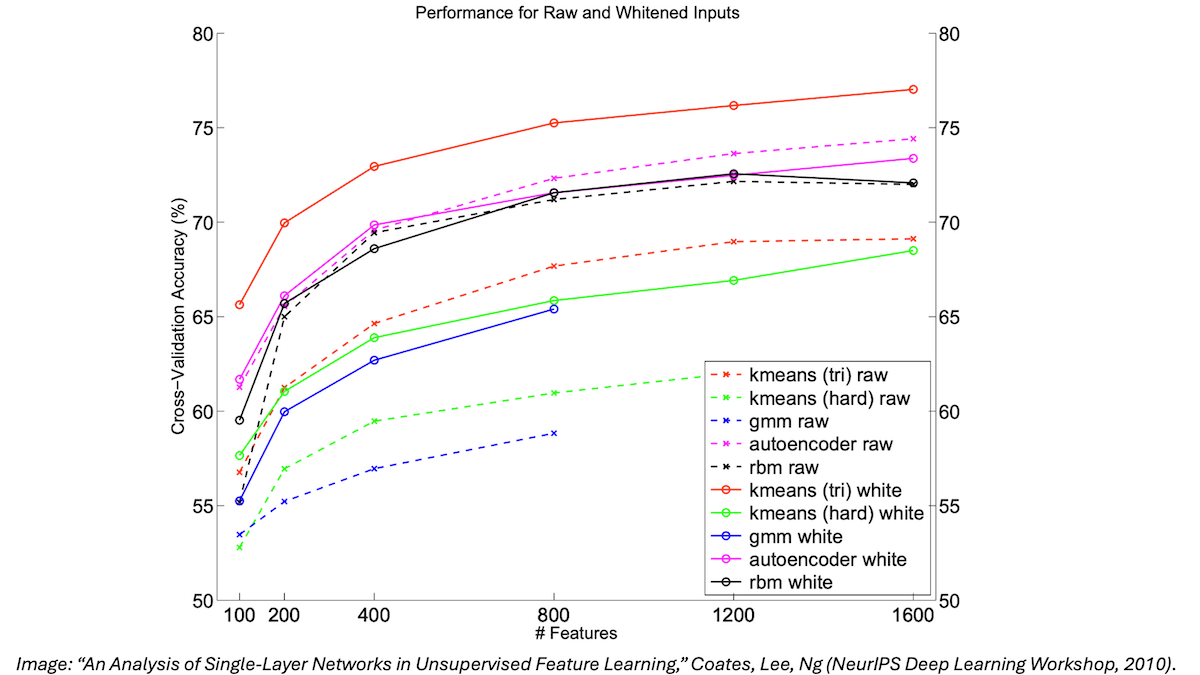
A lesson I carry from that time is to not worry about what others think, but follow your convictions, especially if you have data to support your beliefs. Small-scale experiments performed by my Stanford group convinced me that scaling up neural networks would drive significant progress, and that’s why I was willing to ignore the skeptics. The diagram below, generated by Adam Coates and Honglak Lee, is the one that most firmed up my beliefs at that time. It shows that, for a range of models, the larger we scaled them, the better they perform. I remember presenting it at CIFAR 2010, and if I had to pick a single reason why I pushed through to start Google Brain and set as the team’s #1 goal to scale up deep learning algorithms, it is this diagram!
I also remember presenting at NeurIPS in 2008 our work on using GPUs to scale up training neural networks. (By the way, one measure of success in academia is when your work becomes sufficiently widely accepted that no one cites it anymore. I’m quite pleased the idea that GPUs should be used for AI — which was controversial back then — is now such a widely accepted “fact” that no one bothers to cite early papers that pushed for it.😃)
When I started Google Brain, the thesis was simple: I wanted to use the company’s huge computing capability to scale up deep learning. Shortly afterward, I built Stanford’s first supercomputer for deep learning using GPUs, since I could move faster at Stanford than within a large company. A few years later, my team at Baidu showed that as you scale up a model, its performance improves linearly on a log-log scale, which was a precursor to OpenAI’s scaling laws.
As I look to the future, I’m sure there are ideas that many people are skeptical about today, but will prove to be accurate. Scaling up AI models turned out to be useful for many teams, and it continues to be exciting, but now I’m even more excited by upcoming ideas that will prove to be even more valuable in the future.
This past year, I spent a lot of time encouraging teams to build applications with agentic AI and worked to share best practices. I have a few hypotheses for additional technologies that will be important next year. I plan to spend the winter holiday playing with a few of them, and I will have more to share next year. But if you have an idea that you have conviction on, so long as you can do so responsibly, I encourage you to pursue it!
Keep learning,
Andrew
A MESSAGE FROM DEEPLEARNING.AI

In our latest short course, you’ll learn how to use OpenAI o1 for advanced reasoning in tasks like coding, planning, and image analysis. Explore tradeoffs between intelligence gains and cost as well as techniques, such as meta prompting, to optimize performance. Enroll now!
News
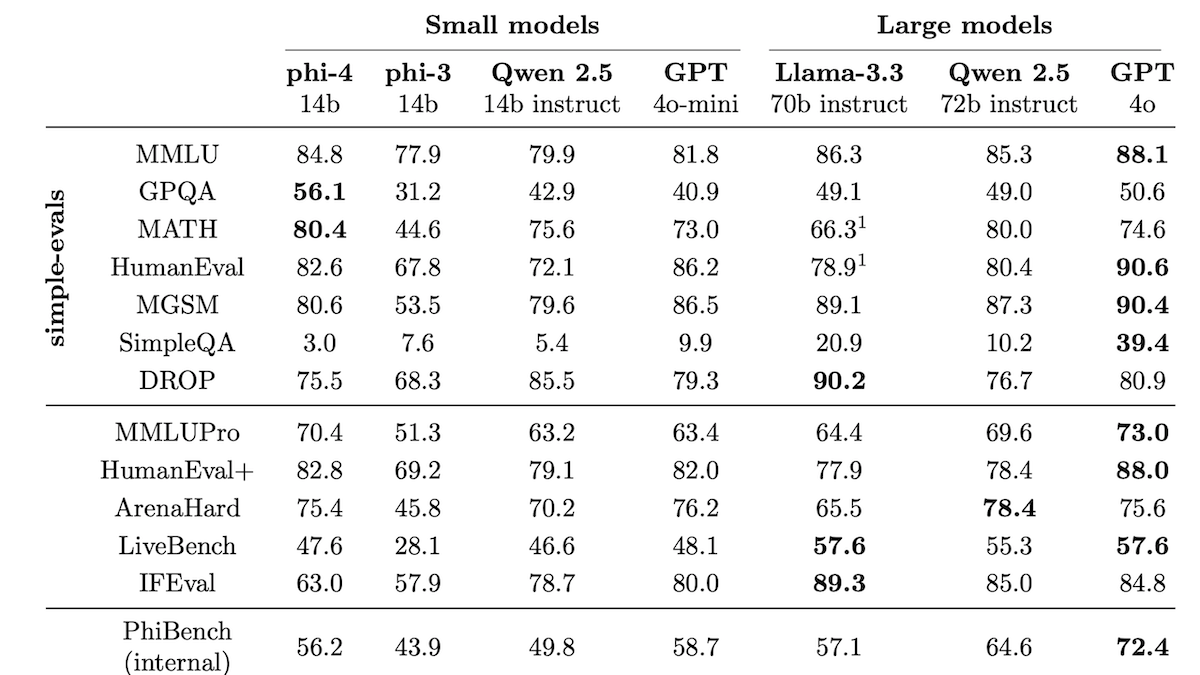
Phi-4 Beats Models Five Times Its Size
Microsoft updated its smallest model family with a single, surprisingly high-performance model.
What’s new: Marah Abdin and a team at Microsoft released Phi-4, a large language model of 14 billion parameters that outperforms Llama 3.3 70B and Qwen 2.5 (72 billion parameters) on math and reasoning benchmarks. The model is available at Azure AI Foundry under a license that permits non-commercial uses, and the weights will be released via Hugging Face next week.
How it works: Phi-4 is a transformer that processes up to 16,000 tokens of input context. The ways the authors constructed the pretraining and fine-tuning datasets accounts for most of its performance advantage over other models.
- Much of the pretraining set was high-quality data from the web or existing datasets. The authors used known high-quality datasets and repositories of high-quality web data (like books and research papers). They also filtered websites using classifiers they trained to recognize high-quality text.
- The rest of the pretraining data was generated or rewritten by GPT-4o. Given snippets of text from web pages, code, scientific papers, and books, GPT-4o rewrote them as exercises, discussions, question-and-answer pairs, and structured reasoning tasks. GPT-4o then followed a feedback loop to improve its accuracy by critiquing its own outputs and generating new ones.
- The authors fine-tuned Phi-4 on existing and newly generated data they acquired in similar ways.
- They further fine-tuned it on two rounds of generated data using Direct Preference Optimization (DPO), which trains models to be more likely to generate a preferred example and less likely to generate a not-preferred example. In the first round, the authors generated preferred/not-preferred pairs by identifying important tokens in generated responses: They considered a token to be important if, after the model generated it (as part of a partial response), the probability that it ultimately would produce a correct output significantly improved (or declined). They measured this probability by generating multiple completions of a given prompt and determining the percentage of times the model produced the correct answer after generating a given token. The preferred/not-preferred pairs (in which one element of the pair is composed of an input, token(s) to generate, and preferred or not-preferred label) took tokens generated prior to the important token as the input, the important token as the preferred token, and the important token that decreased the probability as the not-preferred token.
- In the second round of generating preferred/not-preferred pairs and fine-tuning via DPO, the authors generated responses from GPT-4o, GPT-4 Turbo, and Phi-4, and then used GPT-4o to rate them. Highly rated responses were preferred, and lower-rated responses were not preferred.
Results: Of 13 benchmarks, Phi-4 outperforms Llama 3.3 70B (its most recent open weights competitor) on six and Qwen 2.5 on five.
- Phi-4 outperforms Llama 3.3 70B, Qwen 2.5, and GPT-4o on GPQA (graduate level questions and answers) and MATH (competition-level math problems).
- However, Llama 3.3 70B wins DROP (reading comprehension) and SimpleQA (answering questions about basic facts). Llama 3.3 70B also performs significantly better on IFEval (instruction-following).
Why it matters: Phi-4 shows that there’s still room to improve the performance of small models by curating training data, following the age-old adage that better data makes a better model.
We’re thinking: Some researchers found that earlier versions of Phi showed signs of overfitting to certain benchmarks. In their paper, the Microsoft team stressed that they had improved the data decontamination process for Phi-4 and added an appendix on their method. We trust that independent tests will show that Phi-4 is as impressive as its benchmark scores suggest.

Open Video Gen Closes the Gap
The gap is narrowing between closed and open models for video generation.
What’s new: Tencent released HunyuanVideo, a video generator that delivers performance competitive with commercial models. The model is available as open code and open weights for developers who have less than a 100 million monthly users and live outside the EU, UK, and South Korea.
How it works: HunyuanVideo comprises a convolutional video encoder-decoder, two text encoders, a time-step encoder, and a transformer. The team trained the model in stages (first the encoder-decoder, then the system as a whole) using undisclosed datasets before fine-tuning the system.
- The team trained the encoder-decoder to reconstruct images and videos.
- They trained the system to remove noise from noisy embeddings of videos. They started with low-resolution images; then higher-resolution images; then low-resolution, shorter videos; and progressively increased to higher-resolution, longer videos.
- Given a video, the encoder embedded it. Given a text description of the video, a pretrained Hunyuan-Large produced a detailed embedding of the text and a pretrained CLIP produced a general embedding. A vanilla neural network embedded the current timestep. Given the video embedding with added noise, the two text embeddings, and the time-step embedding, the transformer learned to generate a noise-free embedding.
- The team fine-tuned the system to remove noise from roughly 1 million video examples that had been curated and annotated by humans to select those with the most aesthetically pleasing and compelling motions.
- At inference, given pure noise, a text description, and the current time step, the text encoders embed the text and the vanilla neural network embeds the time step. Given the noise, text embeddings, and the time-step embedding, the transformer generates a noise-free embedding, and the decoder turns it back into video.
Results: 60 people judged responses to 1,533 text prompts by HunyuanVideo, Gen-3 and Luma 1.6. The judges preferred HunyuanVideo’s output overall. Examining the systems’ output in more detail, they preferred HunyuanVideo’s quality of motion but Gen-3’s visual quality.
Behind the news: In February, OpenAI’s announcement of Sora (which was released as this article was in production) marked a new wave of video generators that quickly came to include Google Veo, Meta Movie Gen, Runway Gen-3 Alpha, and Stability AI Stable Video Diffusion. Open source alternatives like Mochi continue to fall short of publicly available commercial video generators.
Why it matters: Research in image generation has advanced at a rapid pace, while progress in video generation has been slower. One reason may be the cost of processing, which is especially intensive when it comes to video. The growing availability of pretrained, open source video generators could accelerate the pace by relieving researchers of the need to pretrain models and enabling them to experiment with fine-tuning and other post-training for specific tasks and applications.
We’re thinking: Tencent’s open source models are great contributions to research and development in video generation. It’s exciting to see labs in China contributing high-performance models to the open source community!
Multimodal Modeling on the Double
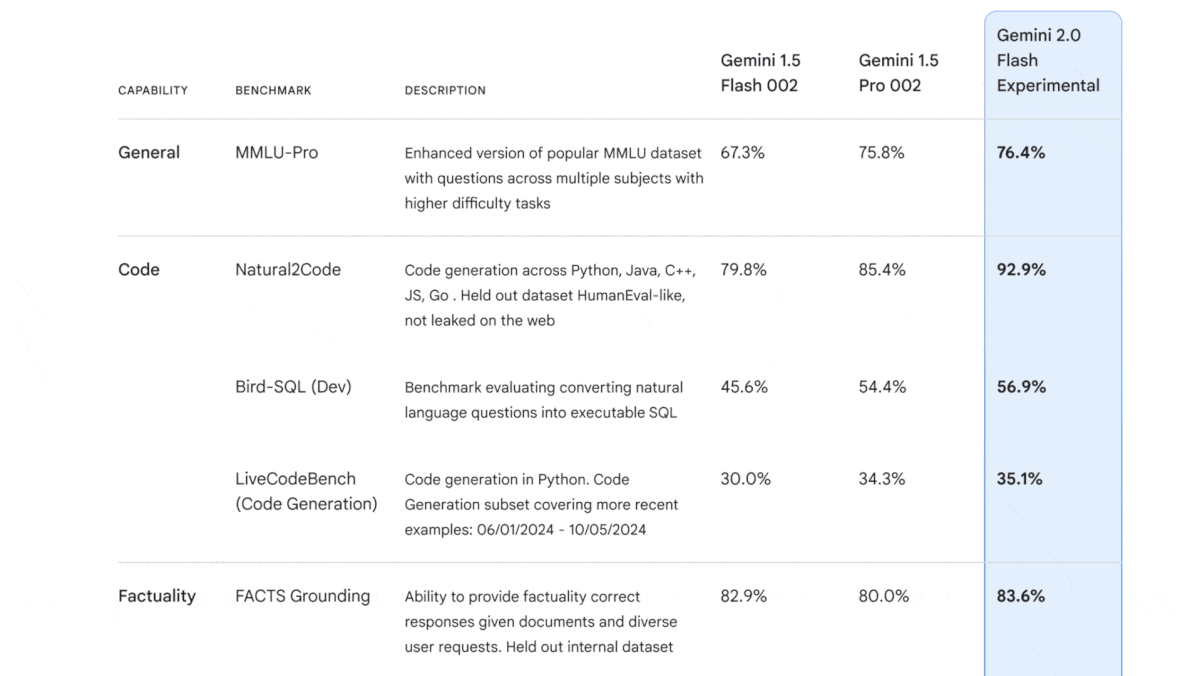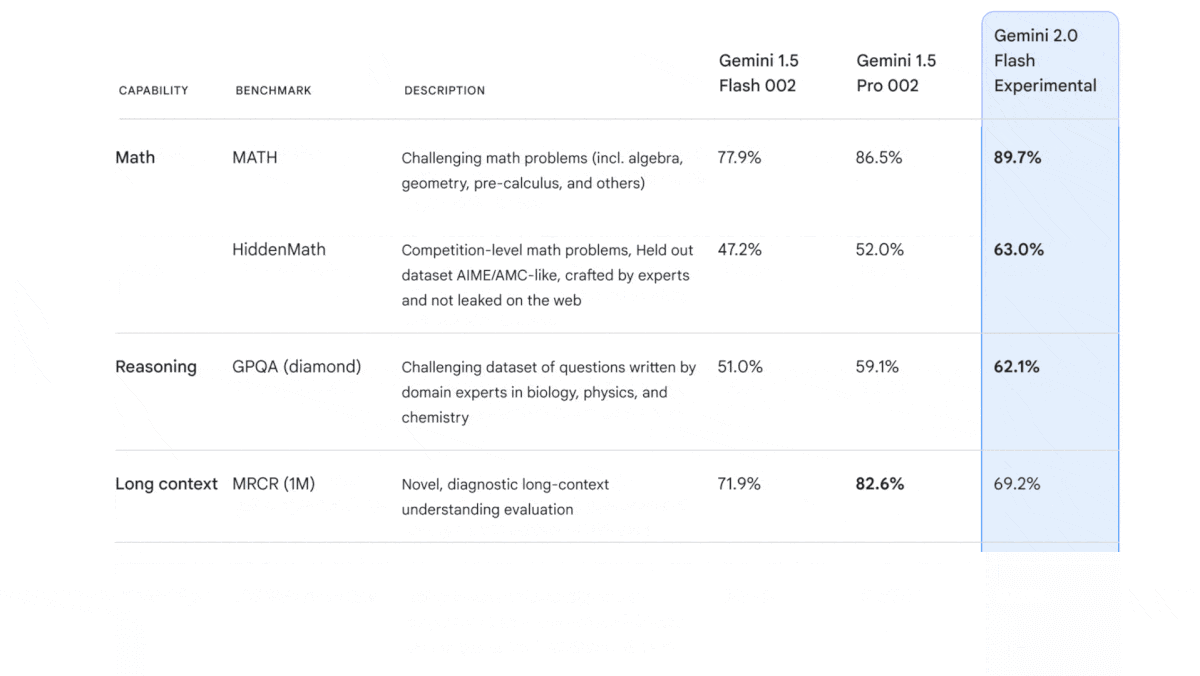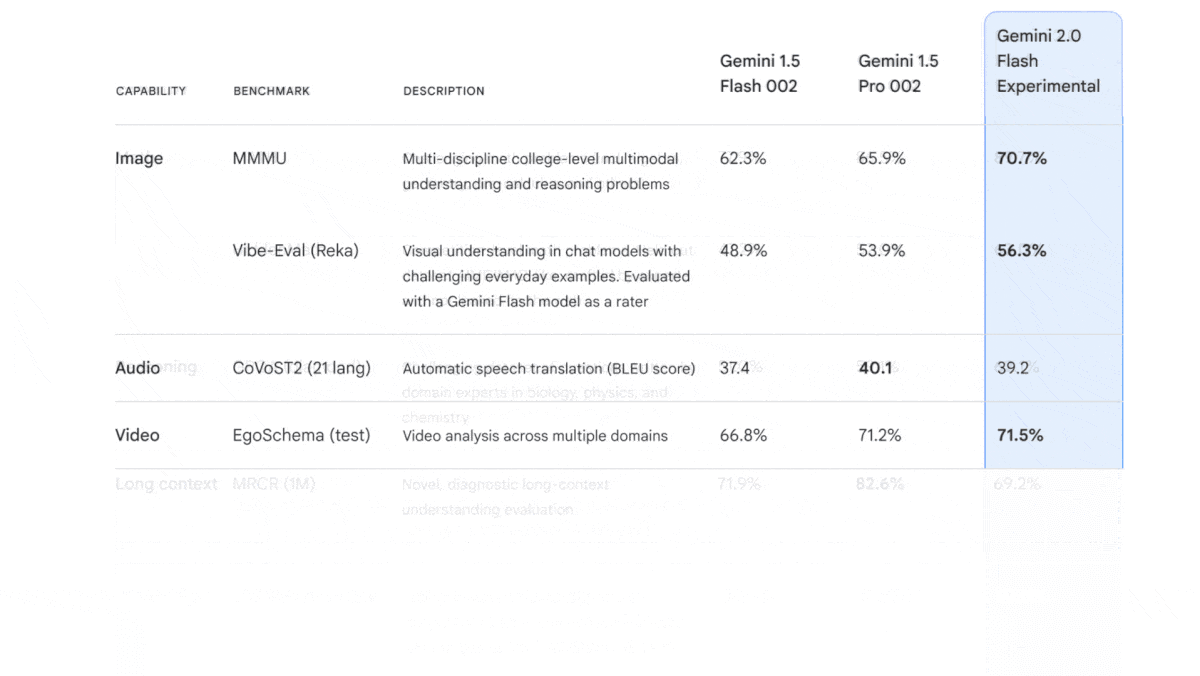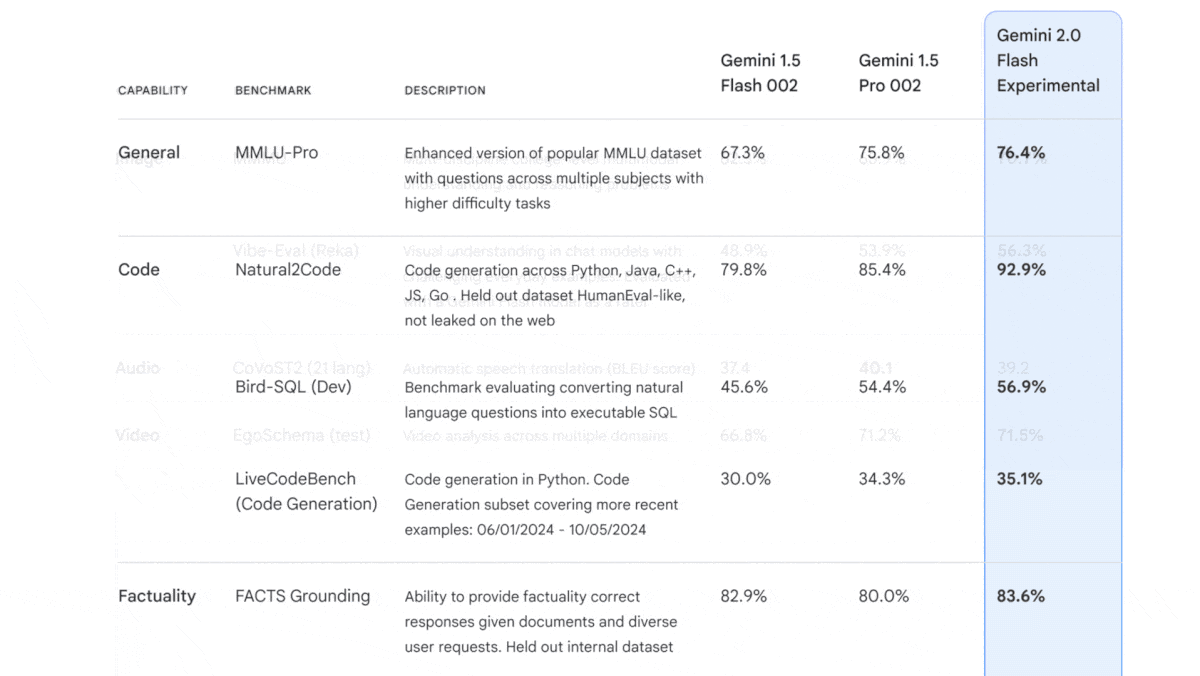
Google’s Gemini 2.0 Flash, the first member of its updated Gemini family of large multimodal models, combines speed with performance that exceeds that of its earlier flagship model, Gemini 1.5 Pro, on several measures.
What’s new: Gemini 2.0 Flash processes an immense 2 million tokens of input context including text, images, video, and speech, and generates text, images, and speech. Text input/output is available in English, Spanish, Japanese, Chinese, and Hindi, while speech input/output is available in English only for now. It can use tools, generate function calls, and respond to a real-time API — capabilities that underpin a set of pre-built agents that perform tasks like research and coding. Gemini 2.0 Flash is available for free in an experimental preview version via Google AI Studio, Google Developer API, and Gemini Chat.
How it works: Gemini 2.0 Flash (parameter count undisclosed) matches or outperforms several competing models on key benchmarks, according to Google’s report.
- Gemini 2.0 Flash is faster than Gemini 1.5 Flash. It offers relatively low average latency (0.53 seconds to receive the first token, just ahead of Mistral Large 2 and GPT-4o mini) and relatively high output speed (169.5 tokens per second, just ahead of AWS Nova Lite and OpenAI o1 Preview but behind Llama), according to Artificial Analysis.
- It beats Gemini 1.5 Pro on multiple key benchmarks, including measures of language understanding (MMLU-Pro) and visual and multimedia understanding (MMMU). It also excels at competition-level math problems, achieving state-of-the-art results on MATH and HiddenMath. It outperforms Gemini 1.5 Pro when generating Python, Java, and SQL code (Natural2Code) and (LiveCodeBench).
- Compared to competing models, Gemini 2.0 Flash does well on language and multimedia understanding. On MMLU-Pro, Gemini 2.0 Flash outperforms GPT-4o and is just behind Claude 3.5 Sonnet, according to TIGER-Lab. Google reports a score of 70.7 percent on MMMU, which would put it ahead of GPT-4o and Claude 3.5 Sonnet, but behind o1’s, on the MMMU leaderboard as of this publication date. It does less well on tests of coding ability, in which it underperforms Claude 3.5 Sonnet, GPT-4o, o1-preview, and o1-mini.
- The Multimodal Live API feeds live-streamed inputs from cameras or screens to Gemini 2.0 Flash, enabling real-time applications like live translation and video recognition.
- The model’s multimodal input/output capabilities enable it to identify and locate objects in images and reason about them. For instance, it can locate a spilled drink and suggest ways to clean it up. It can alter images according to natural-language commands, such as turning a picture of a car into a convertible, and explain the changes step by step.
Agents at your service: Google also introduced four agents that take advantage of Gemini 2.0 Flash’s ability to use tools, call functions, and respond to the API in real time. Most are available via a waitlist.
- Astra, which was previewed in May, is an AI assistant for smartphones (and for prototype alternative-reality glasses that are in beta test with US and UK users). Astra recognizes video, text, images, and audio in real time and integrates with Google services to help manage calendars, send emails, and answer search queries.
- Mariner automatically compares product prices, buys tickets, and organizes schedules on a user’s behalf using a Chrome browser extension.
- Deep Research is a multimodal research assistant that analyzes datasets, summarized text, and compiles reports. It’s designed for academic and professional research and is available to Gemini Advanced subscribers.
- Jules is a coding agent for Python and JavaScript. Given text instructions, Jules creates plans, identifies bugs, writes and completes code, issues GitHub pull requests, and otherwise streamlines development. Jules is slated for general availability in early 2025.
Behind the news: OpenAI showed off GPT-4o’s capability for real-time video understanding in May, but Gemini 2.0 Flash beat it to the punch: Google launched the new model and its multimodal API one day ahead of ChatGPT’s Advanced Voice with Vision.
Why it matters: Speed and multimodal input/output are valuable characteristics for any AI model, and they’re especially useful in agentic applications. Google CEO Sundar Pichai said he wants Gemini to be a “universal assistant.” The new Gemini-based applications for coding, research, and video analysis are steps in that direction.
We’re thinking: While other large language models can take advantage of search, Gemini 2.0 Flash generates calls to Google Search and uses that capability in agentic tools — a demonstration of how Google’s dominance in search strengthens its efforts in AI.

When LLMs Propose Research Ideas
How do agents based on large language models compare to human experts when it comes to proposing machine learning research? Pretty well, according to one study.
What’s new: Chenglei Si, Diyi Yang, and Tatsunori Hashimoto at Stanford produced ideas for research in machine learning using Anthropic’s Claude 3.5 Sonnet and human researchers, and also evaluated them using both manual and automated methods. Claude 3.5 Sonnet generated competitive proposals, but its evaluations of proposals were less compelling.
How it works: Each proposal included a problem statement, motivation, step-by-step plan, backup plan, and examples of baseline outcomes versus expected experimental outcomes.
- Automated proposal generation: Given one of seven topics (bias, coding, safety, multilinguality, factuality, math, or uncertainty) and 10 related papers found by the Semantic Scholar search engine, Claude 3.5 Sonnet generated 4,000 research ideas. The authors embedded the ideas using all-MiniLM-L6-v2 and removed duplicate ideas based on the cosine similarity of their embeddings. This left roughly 200 AI-generated ideas for each topic. For each remaining idea, the model generated a proposal.
- Automated ranking: Claude Sonnet 3.5 ranked the proposals in a five-round tournament that awarded points for superior quality and pitted highest-scoring proposals against one another. In addition, one of the authors manually ranked the generated proposals.
- Human proposal generation: The authors paid 49 machine learning engineers to propose their own ideas. They obscured authorship by prompting an unidentified large language model to edit them according to a style guide. Then they manually checked the rewritten proposals to ensure that the model’s editing didn’t change their content significantly.
- Human ranking: A group of 79 machine learning engineers reviewed the 49 human-written proposals, the top 49 AI-generated proposals ranked by humans, and the top 49 AI-generated proposals ranked by AI (resulting in two to four reviews per proposal). They scored the proposals between 1 and 10 on five factors: novelty, feasibility, expected effectiveness, how exciting they were, and overall quality.
Results: Human judges deemed proposals generated by Claude 3.5 Sonnet as good as or better than those produced by humans. However, large language models proved less effective at judging the proposals’ quality.
- On average, humans scored the AI-generated and human-written proposals roughly equally in feasibility, expected effectiveness, how exciting they were, and overall quality. They deemed the AI-generated proposals significantly more novel. The top AI-generated proposals as ranked by humans achieved an average 5.78 novelty. The top AI-generated proposal as ranked by AI achieved an average 5.62 novelty. Human-written proposals achieved an average 4.86 novelty.
- The authors found that LLMs don’t yet match human performance when it comes to judging scientific papers. They compared the rates of agreement among five LLMs that evaluated proposals in their experiment, human judgements of the proposals, and human reviews of papers submitted to the NeurIPS and ICLR conferences. The most consistent LLM, Claude 3.5 Sonnet, was 53.3 percent consistent with average human judgment. The human judges were 56.1 percent consistent. Reviewers for NeurIPS and ICLR were 66 and 71.9 percent consistent respectively. Random chance was 50 percent.
Why it matters: AI models play a growing role in scientific discovery. This work shows they can set directions for research — in machine learning, at least — that rival those set by humans. However, human evaluation remains the gold standard for comparing performance on complex problems like generating text.
We’re thinking: Coming up with good research ideas is hard! That a large language model can do it with some competency has exciting implications for the future of both AI and science.