
Dear friends,
Writing software, especially prototypes, is becoming cheaper. This will lead to increased demand for people who can decide what to build. AI Product Management has a bright future!
Software is often written by teams that comprise Product Managers (PMs), who decide what to build (such as what features to implement for what users) and Software Developers, who write the code to build the product. Economics shows that when two goods are complements — such as cars (with internal-combustion engines) and gasoline — falling prices in one leads to higher demand for the other. For example, as cars became cheaper, more people bought them, which led to increased demand for gas. Something similar will happen in software. Given a clear specification for what to build, AI is making the building itself much faster and cheaper. This will significantly increase demand for people who can come up with clear specs for valuable things to build.
This is why I’m excited about the future of Product Management, the discipline of developing and managing software products. I’m especially excited about the future of AI Product Management, the discipline of developing and managing AI software products.
Many companies have an Engineer:PM ratio of, say, 6:1. (The ratio varies widely by company and industry, and anywhere from 4:1 to 10:1 is typical.) As coding becomes more efficient, I think teams will need more product management work (as well as design work) as a fraction of the total workforce. Perhaps engineers will step in to do some of this work, but if it remains the purview of specialized Product Managers, then the demand for these roles will grow.
This change in the composition of software development teams is not yet moving forward at full speed. One major force slowing this shift, particularly in AI Product Management, is that Software Engineers, being technical, are understanding and embracing AI much faster than Product Managers. Even today, most companies have difficulty finding people who know how to develop products and also understand AI, and I expect this shortage to grow.

Further, AI Product Management requires a different set of skills than traditional software Product Management. It requires:
- Technical proficiency in AI. PMs need to understand what products might be technically feasible to build. They also need to understand the lifecycle of AI projects, such as data collection, building, then monitoring, and maintenance of AI models.
- Iterative development. Because AI development is much more iterative than traditional software and requires more course corrections along the way, PMs need to understand how to manage such a process.
- Data proficiency. AI products often learn from data, and they can be designed to generate richer forms of data than traditional software.
- Skill in managing ambiguity. Because AI’s performance is hard to predict in advance, PMs need to be comfortable with this and have tactics to manage it.
- Ongoing learning. AI technology is advancing rapidly. PMs, like everyone else who aims to make best use of the technology, need to keep up with the latest technology advances, product ideas, and how they fit into users’ lives.
Finally, AI Product Managers will need to know how to ensure that AI is implemented responsibly (for example, when we need to implement guardrails to prevent bad outcomes), and also be skilled at gathering feedback fast to keep projects moving. Increasingly, I also expect strong product managers to be able to build prototypes for themselves.
The demand for good AI Product Managers will be huge. In addition to growing AI Product Management as a discipline, perhaps some engineers will also end up doing more product management work.
The variety of valuable things we can build is nearly unlimited. What a great time to build!
Keep learning,
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Get up-close and personal with OpenAI’s groundbreaking o1 model! In our short course “Reasoning with o1,” you’ll learn how to get the best performance in coding, planning, and STEM tasks; perform complex, multi-step tasks; and optimize prompts with meta prompting. Enroll today
News
DeepSeek Ups the Open Weights Ante
A new model from Hangzhou upstart DeepSeek delivers outstanding performance and may change the equation for training costs.
What’s new: DeepSeek-V3 is an open large language model that outperforms Llama 3.1 405B and GPT-4o on key benchmarks and achieves exceptional scores in coding and math. The weights are open except for applications that involve military uses, harming minors, generating false information, and similar restrictions. You can download them here.
Mixture of experts (MoE) basics: The MoE architecture uses different subsets of its parameters to process different inputs. Each MoE layer contains a group of neural networks, or experts, preceded by a gating module that learns to choose which one(s) to use based on the input. In this way, different experts learn to specialize in different types of examples. Because not all parameters are used to produce any given output, the network uses less energy and runs faster than models of similar size that use all parameters to process every input.
How it works: DeepSeek-V3 is a mixture-of-experts (MoE) transformer that comprises 671 billion parameters, of which 37 billion are active at any moment. The team trained the model in 2.79 million GPU hours — less than 1/10 the time required to train Llama 3.1 405B, which DeepSeek-V3 substantially outperforms — at an extraordinarily low cost of $5.6 million.
- The developers trained it on roughly 15 trillion tokens, including a larger percentage of coding and math data relative to DeepSeek-V2. They fine-tuned it on a wide variety of tasks using output generated by DeepSeek-R1 and DeepSeek-V2.5. They further sharpened its performance across diverse domains using the reinforcement learning algorithm known as group relative policy optimization.
- Earlier work showed that training to predict the next two tokens would improve performance over learning to predict just one. The authors implemented this procedure. The model learned to predict the first token as usual and used an additional set of layers to learn to predict the second token. The additional layers aren’t used at inference.
- Following DeepSeek-V2, DeepSeek-V3 uses multi-head latent attention, which saves memory during execution relative to other variants of attention.
- Also like DeepSeek-V2, the new model combines dedicated (routed) and shared experts. The model chooses eight of 256 experts for a particular input, but it also uses a shared expert that processes all inputs.
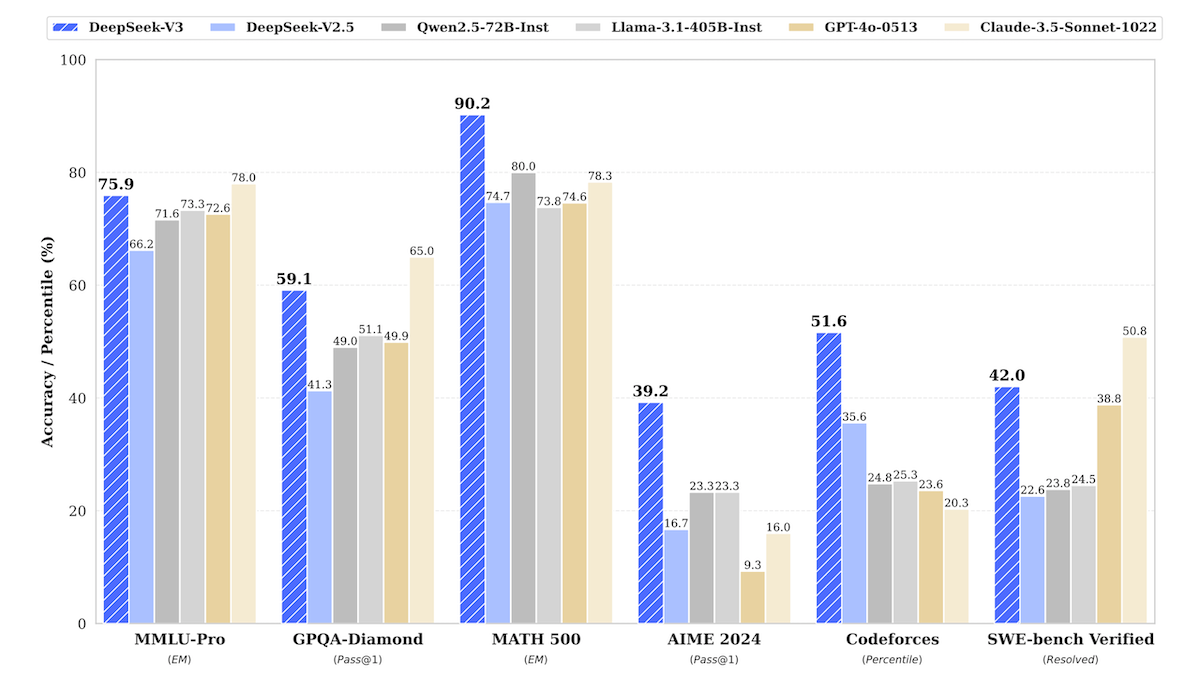
Results: In DeepSeek’s tests, DeepSeek-V3 outperformed Llama 3.1 405B and Qwen 2.5 72B across the board, and its performance compared favorably with that of GPT-4o.
- DeepSeek-V3 showed exceptional performance in coding and math tasks. In coding, DeepSeek-V3 dominated in five of the seven benchmarks tested. However, DeepSeek-V3 lost to o1 on one of the five, according to a public leaderboard. Specifically, on Polyglot, which tests a model’s ability to generate code in response to difficult requests in multiple programming languages, DeepSeek-V3 (48.5 percent accuracy) beat Claude Sonnet 3.5 (45.3 percent accuracy), though it lost to o1 (61.7 percent accuracy).
- In language tasks, it performed neck-and-neck with Claude 3.5 Sonnet, achieving higher scores in some tasks and lower in others.
Behind the news: OpenAI’s o1 models excel thanks to agentic workflows in which they reflect on their own outputs, use tools, and so on. DeepSeek swims against the tide and achieves superior results without relying on agentic workflows.
Why it matters: Open models continue to challenge closed models, giving developers high-quality options that they can modify and deploy at will. But the larger story is DeepSeek-V3’s shockingly low training cost. The team doesn’t explain precisely how the model achieves outstanding performance with such a low processing budget. (The paper credits “meticulous engineering optimizations.”) But it’s likely that DeepSeek’s steady refinement of MoE is a key factor. DeepSeek-V2, also an MoE model, saved more than 40 percent in training versus the earlier DeepSeek 67B, which didn’t employ MoE. In 2022, Microsoft found that MoE cost five times less in training for equal performance compared to a dense model, and Google and Meta reported that MoE achieved better performance than dense models trained on the same numbers of tokens.
We’re thinking: If they can be replicated, DeepSeek’s results have significant implications for the economics of training foundation models. If indeed it now costs around $5 million to build a GPT-4o-level model, more teams will be able to train such models, and the cost of competing with the AI giants could fall dramatically.
U.S. Moves to Expand AI Export Restrictions
The United States proposed limits on exports of AI technology that would dramatically expand previous restrictions, creating a new international hierarchy for access to advanced chips and models.
What’s new: The Biden administration, which will transition to leadership under incoming President Trump next week, issued new rules that restrict exports of AI chips and models to most countries beyond a select group of close allies. The rules, which are not yet final, would create a three-tier system that limits exports to a number of close allies and blocks access entirely to China, Iran, North Korea, Russia, and others. They also would introduce the U.S.’ first-ever restrictions on exporting closed weights for large AI models.
How it works: The restrictions were announced shortly after a leak reached the press. A public comment period of 120 days will enable the incoming U.S. Presidential administration to consider input from the business and diplomatic communities and modify the rules before they take effect. The rules are scheduled to take effect in one year.
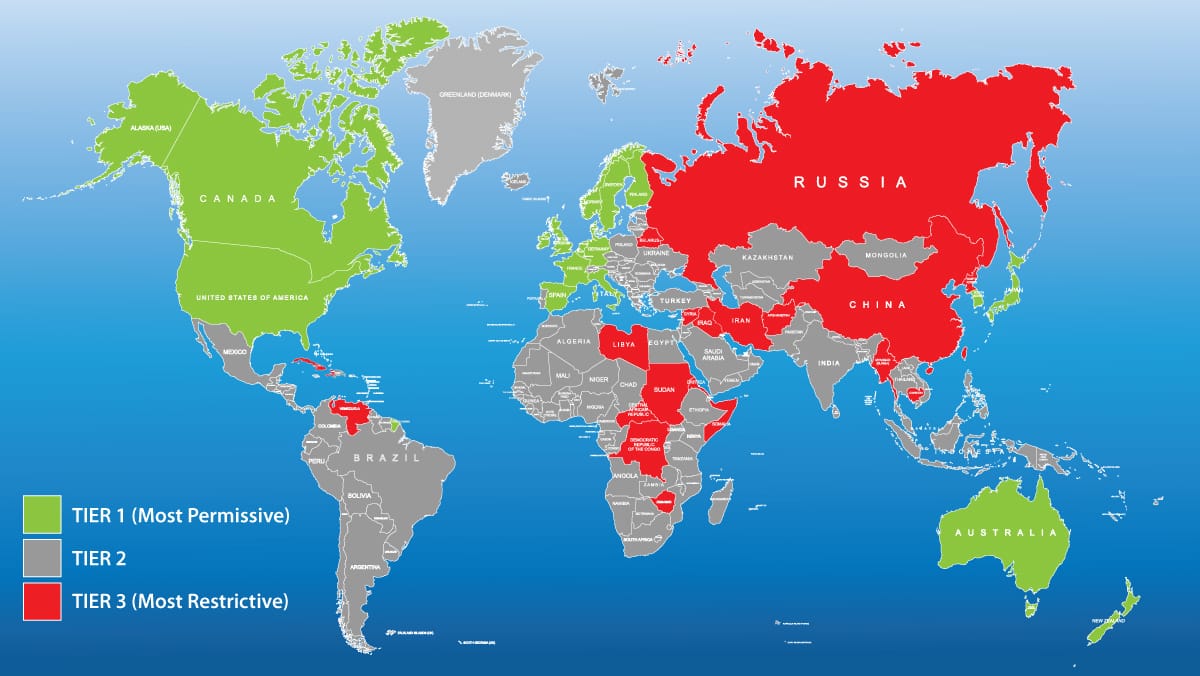
- A new hierarchy divides nations into three groups that would have different degrees of access to AI chips both designed in the U.S. and manufactured abroad using U.S. technology, as well as proprietary AI models.
- Tier 1: Australia, Japan, Taiwan, the United Kingdom, and most of Europe would retain nearly unrestricted access. However, these nations must keep 75 percent of their AI computing power within allied countries. No more than 10 percent can be transferred to any single country outside this group to ensure that advanced AI development remains concentrated among close U.S. allies.
- Tier 2: Traditional U.S. allies and trade partners like Israel, Saudi Arabia, and Singapore face an initial cap of 507 million units of total processing power (TPP) — roughly the computational capacity of 32,000 Nvidia H100 chips — through the first quarter of 2025. The cap would increase to 1.02 billion TPP by 2027. U.S. companies that operate in these countries can apply for higher limits: 633 million TPP in Q1 2025, rising to 5.064 billion TPP by Q1 2027.
- Tier 3: China, Russia, and around two dozen other countries are blocked from receiving advanced AI chips, model weights, and specialized knowledge related to these systems.
- The U.S. Commerce Department’s export control agency must approve the export of models or transfer of weights of closed models that were trained using more than 1026 computational operations. These rules target future systems, as no known models today used this amount of computation during training.
- Companies based in the U.S. must maintain at least 50 percent of their total AI computing power within U.S. borders. They also must track distribution of their models, implement security measures, and submit to regular audits.
Behind the news: The proposed rules build on 2022’s CHIPS and Science Act, which was designed to strengthen domestic semiconductor production and restrict technologies abroad that could bear on U.S. security. An initial round of restrictions in late 2022 barred semiconductor suppliers AMD and Nvidia from selling advanced chips to Chinese firms. In November 2024, the U.S. tightened restrictions further, ordering Taiwan Semiconductor Manufacturing Company, which fabricates those chips, to halt production of advanced chips destined for China.
Plus green AI infrastructure: In addition, President Biden issued an executive order to encourage the rapid build-out of computing infrastructure for AI. The federal government will hold competitions among private companies to lease sites it owns for the building of data centers at private expense. The selection of sites will take into account availability of sources of clean energy, including support for nuclear energy. The government will expedite permitting on these sites and support development of energy transmission lines around them. It will also encourage international allies to invest in AI infrastructure powered by clean energy.
Why it matters: Protecting the United States’ advantages in high tech has been a rising priority for the White House over the past decade. The earlier export restrictions forced many Chinese AI developers to rely on less-powerful hardware. The new limits are likely to have a far broader impact. They could force developers in the Tier 2 and Tier 3 countries to build less resource-intensive models and lead them to collaborate more closely with each other, reducing the value of U.S.-made technology worldwide. They could hurt U.S. chip vendors, which have warned that the rules could weaken U.S. competitiveness in the global economy. They could also force companies that are building huge data centers to process AI calculations to reconsider their plans.
We’re thinking: The Biden administration’s embargo on AI chips has been leaky. So far, it has slowed down adversaries only slightly while spurring significant investment in potential suppliers that aren’t connected to the U.S. While the public comment period invites lobbying and industry feedback, ultimately geopolitical priorities may hold sway. Whatever the outcome, reducing the world’s dependence on U.S. chips and models would result in a very different global AI ecosystem.
AI Supercomputer on Your Desk
Nvidia’s new desktop computer is built specifically to run large AI models.
What’s new: Project Digits is a personal supercomputer intended to help developers fine-tune and run large models locally. Project Digits, which is small enough to hold in one hand, will be available in May, starting at $3000.
How it works: Project Digits is designed to run models of up to 200 billion parameters — roughly five times the size that fits comfortably on typical consumer hardware — provided they’re quantized to 4 bits of precision. Two units can be connected to run models such as Meta’s Llama 3.1 405B. Complete specifications are not yet available.
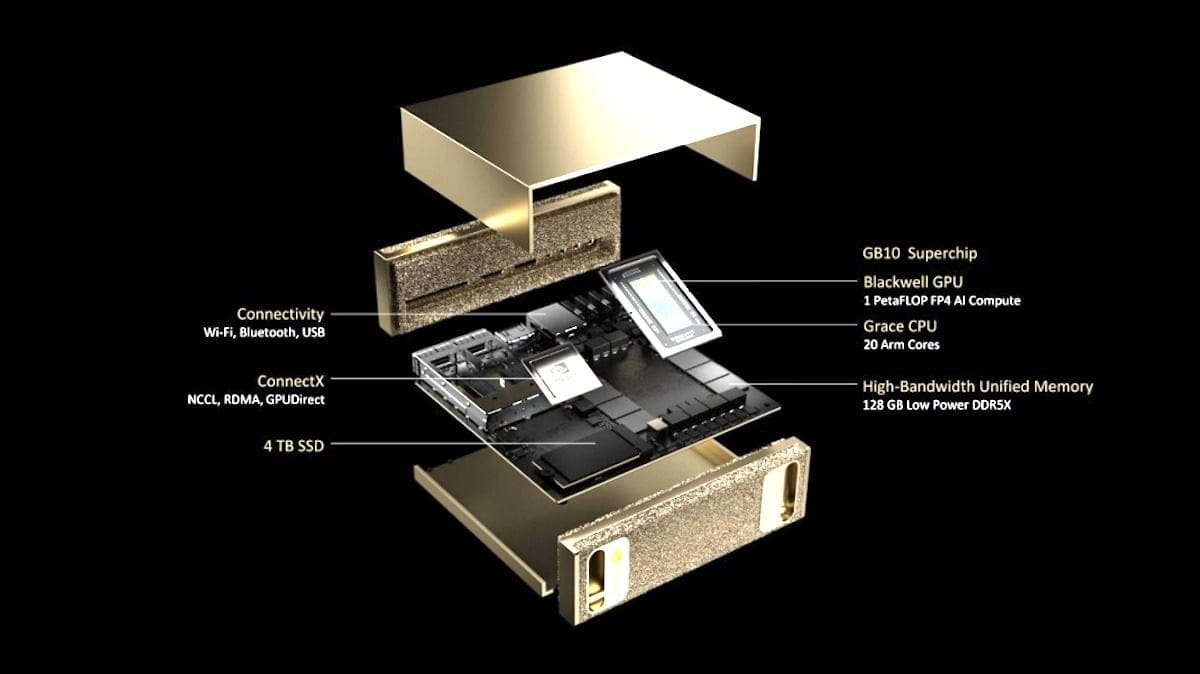
- Project Digits runs Nvidia’s DGX operating system, a flavor of Ubuntu Linux.
- The system is based on a GB10 system-on-a-chip that combines the Nvidia Blackwell GPU architecture (which serves as the basis for its latest B100 GPUs) and Grace CPU architecture (designed to manage AI workloads in data centers), connected via high-bandwidth NVLink interconnect.
- It comes with 128 GB of unified memory and 4 terabytes of solid-state storage.
- The system connects to Nvidia’s DGX Cloud service to enable developers to deploy models from a local machine to cloud infrastructure.
Behind the news: In a blitz of announcements at the Consumer Electronics Show (CES), Nvidia also launched a platform for developing robotics, autonomous vehicles, and other physical AI systems. Cosmos includes pretrained language and vision models that range from 4 billion to 14 billion parameters for generating synthetic training data for robots or building policy models that translate a robot’s state into its next action. Nvidia also released Cosmos Nemotron, a 34 billion-parameter, vision-language model designed for use by AI agents, plus a video tokenizer and other tools for robotics developers.
Why it matters: It’s common to train models on Nvidia A100 or H100 GPUs, which come with a price tag of at least $8,000 or $20,000 respectively, along with 40 gigabytes to 80 gigabytes of memory. These hefty requirements push many developers to buy access to computing infrastructure from a cloud provider. Coming in at $3,000 with 128 gigabytes of memory, Project Digits is designed to empower machine learning engineers to train and run larger models on their own machines.
We’re thinking: We look forward to seeing cost/throughput comparisons between running a model on Project Digits, A100, and H100.

Calibrating Contrast
Contrastive loss functions make it possible to produce good embeddings without labeled data. A twist on this idea makes even more useful embeddings.
What’s new: Vlad Sobal and colleagues at Meta, New York University, Brown University, Genentech, and Canadian Institute for Advanced Research introduced X-Sample contrastive loss (X-CLR), a self-supervised loss function that enables vision models to learn embeddings that capture similarities and differences among examples with greater subtlety.
Key insight: Contrastive loss functions like SimCLR equally encourage a model to produce dissimilar embeddings of images of, say, a cat, a dog, and a dump truck. But, of course, cats and dogs are more similar to each other than either are to dump trucks. Instead of marking examples as similar or dissimilar, X-CLR assigns similarity scores, so a model can learn to produce embeddings that match those scores.
How it works: The authors used X-CLR to train an embedding model on Conceptual Captions datasets of image-text pairs scraped from the web: CC-3M (3 million text-image pairs) and CC-12M (12 million text-image pairs). The model was similar to CLIP, except the text encoder was a sentence transformer pretrained on sentence pairs, and the vision encoder was a ResNet-50 pretrained on ImageNet.
- The sentence transformer embedded text captions for all examples. The system computed similarity scores according to cosine similarity between the text embeddings.
- Similarly, a ResNet-50 computed image embeddings, and the system computed similarity scores between them.
- The authors froze the sentence transformer and used the text similarity scores as labels in the loss function. The loss function minimized the difference between the similarity scores of the text embeddings and the corresponding similarity scores of the image embeddings.
Results: Systems trained using X-CLR outperformed competitors in ImageNet classification, especially when less training data was available. (The authors followed CLIP’s method of classification: They computed the similarity between an image embedding and text embeddings of all classes. The image’s classification was the class that corresponds to the text embedding with the highest similarity to the image embedding.)
- The authors compared a system trained using X-CLR, one trained using SimCLR, and CLIP. After training on the CC-3M dataset, the X-CLR system achieved 58.2 percent accuracy on ImageNet, while the SimCLR model achieved 57.0 percent and CLIP achieved 41.0 percent.
- Training on CC-12M resulted in smaller differences: X-CLR achieved 59.4 percent accuracy, SimCLR achieved 58.9 percent, and CLIP achieved 58.8 percent.
Why it matters: Contrastive loss functions are very useful, but the similar/dissimilar dichotomy leaves important nuances unaccounted for. Like CLIP, X-CLR takes advantage of both images and their captions for self-supervised learning. However, CLIP learns to recognize image-text pairs as similar or dissimilar, while X-CLR matches image-image pairs using captions as a similarity signal that’s continuous rather than discrete.
We’re thinking: Reality is not black and white. Allowing for shades of gray makes for better modeling.