
Dear friends,
The buzz over DeepSeek this week crystallized, for many people, a few important trends that have been happening in plain sight: (i) China is catching up to the U.S. in generative AI, with implications for the AI supply chain. (ii) Open weight models are commoditizing the foundation-model layer, which creates opportunities for application builders. (iii) Scaling up isn’t the only path to AI progress. Despite the massive focus on and hype around processing power, algorithmic innovations are rapidly pushing down training costs.
About a week ago, DeepSeek, a company based in China, released DeepSeek-R1, a remarkable model whose performance on benchmarks is comparable to OpenAI’s o1. Further, it was released as an open weight model with a permissive MIT license. At Davos last week, I got a lot of questions about it from non-technical business leaders. And on Monday, the stock market saw a “DeepSeek selloff”: The share prices of Nvidia and a number of other U.S. tech companies plunged. (As of the time of writing, they have recovered somewhat.)
Here’s what I think DeepSeek has caused many people to realize:
China is catching up to the U.S. in generative AI. When ChatGPT was launched in November 2022, the U.S. was significantly ahead of China in generative AI. Impressions change slowly, and so even recently I heard friends in both the U.S. and China say they thought China was behind. But in reality, this gap has rapidly eroded over the past two years. With models from China such as Qwen (which my teams have used for months), Kimi, InternVL, and DeepSeek, China had clearly been closing the gap, and in areas such as video generation there were already moments where China seemed to be in the lead.
I’m thrilled that DeepSeek-R1 was released as an open weight model, with a technical report that shares many details. In contrast, a number of U.S. companies have pushed for regulation to stifle open source by hyping up hypothetical AI dangers such as human extinction. It is now clear that open source/open weight models are a key part of the AI supply chain: Many companies will use them. If the U.S. continues to stymie open source, China will come to dominate this part of the supply chain and many businesses will end up using models that reflect China’s values much more than America’s.
Open weight models are commoditizing the foundation-model layer. As I wrote previously, LLM token prices have been falling rapidly, and open weights have contributed to this trend and given developers more choice. OpenAI’s o1 costs $60 per million output tokens; DeepSeek R1 costs $2.19. This nearly 30x difference brought the trend of falling prices to the attention of many people.

The business of training foundation models and selling API access is tough. Many companies in this area are still looking for a path to recouping the massive cost of model training. The article “AI’s $600B Question” lays out the challenge well (but, to be clear, I think the foundation model companies are doing great work, and I hope they succeed). In contrast, building applications on top of foundation models presents many great business opportunities. Now that others have spent billions training such models, you can access these models for mere dollars to build customer service chatbots, email summarizers, AI doctors, legal document assistants, and much more.
Scaling up isn’t the only path to AI progress. There’s been a lot of hype around scaling up models as a way to drive progress. To be fair, I was an early proponent of scaling up models. A number of companies raised billions of dollars by generating buzz around the narrative that, with more capital, they could (i) scale up and (ii) predictably drive improvements. Consequently, there has been a huge focus on scaling up, as opposed to a more nuanced view that gives due attention to the many different ways we can make progress. Driven in part by the U.S. AI chip embargo, the DeepSeek team had to innovate on many optimizations to run on less-capable H800 GPUs rather than H100s, leading ultimately to a model trained (omitting research costs) for under $6M of compute.
It remains to be seen if this will actually reduce demand for compute. Sometimes making each unit of a good cheaper can result in more dollars in total going to buy that good. I think the demand for intelligence and compute has practically no ceiling over the long term, so I remain bullish that humanity will use more intelligence even as it gets cheaper.
I saw many different interpretations of DeepSeek’s progress on social media, as if it was a Rorschach test that allowed many people to project their own meaning onto it. I think DeepSeek-R1 has geopolitical implications that are yet to be worked out. And it’s also great for AI application builders. My team has already been brainstorming ideas that are newly possible only because we have easy access to an open advanced reasoning model. This continues to be a great time to build!
Keep learning,
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Discover Anthropic’s new capabilty - Computer Use - that allows LLM-based agents use a computer interface. In this free course, you’ll learn to apply image reasoning and function-calling to ‘use’ a computer as follows: a model processes an image of the screen, analyzes it to understand what's going on, and navigates the computer via mouse clicks and keystrokes. Start today!
News
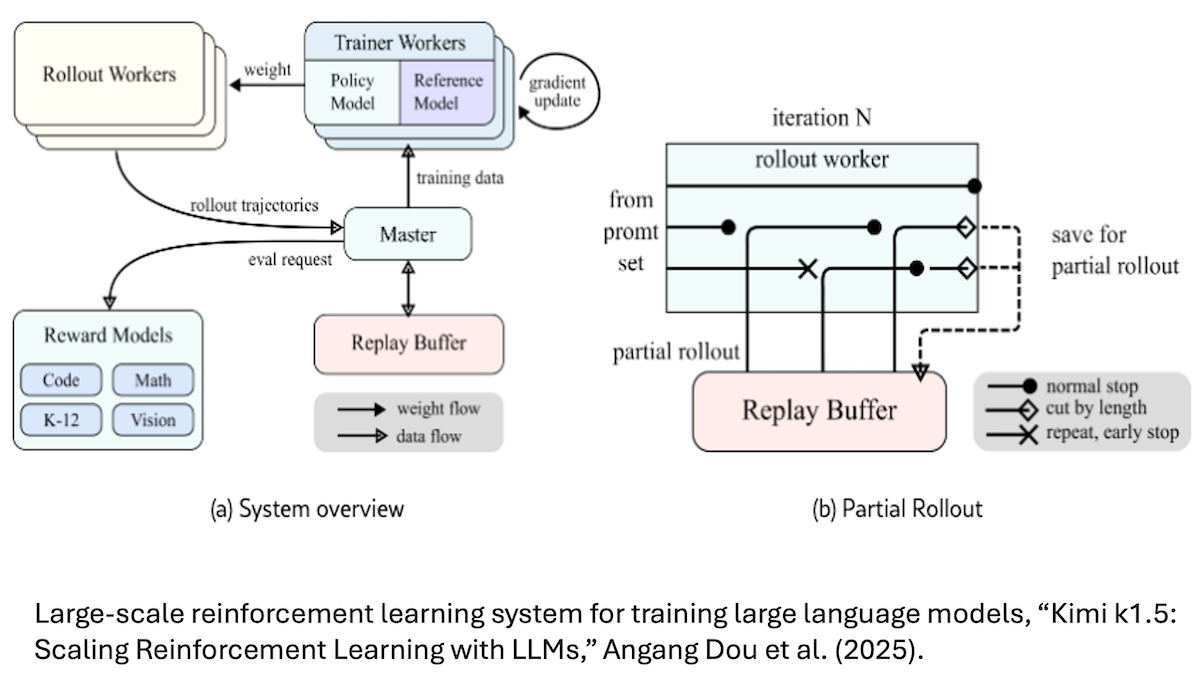
Reinforcement Learning Heats Up
Reinforcement learning is emerging as an avenue for building large language models with advanced reasoning capabilities.
What’s new: Two recent high-performance models, DeepSeek-R1 (and its variants including DeepSeek-R1-Zero) and Kimi k1.5, learned to improve their generated lines of reasoning via reinforcement learning. o1 pioneered this approach last year.
Reinforcement learning (RL) basics: RL rewards or punishes a model for performing particular actions or achieving certain objectives. Unlike supervised and unsupervised learning, which compare the model's output to a known ground truth, RL doesn’t explicitly tell a model what it should output. Instead, the model starts out behaving randomly and discovers desired behaviors by earning rewards for its actions. This makes RL especially popular for training machine learning models that play games or control robots.
How it works: To improve the chain of thought (CoT) generated by a large language model (LLM), reinforcement learning encourages the model to generate correct solutions to math, coding, science, and other problems that have known solutions. Unlike typical LLM training, in which the model simply generates the next token of its output and receives feedback token by token, this method rewards the model for generating a sequence of reasoning steps that lead to an accurate conclusion, even if doing so requires generating many intermediate tokens between the prompt and the response — to plan an outline, check the conclusion, or reflect on the approach — without explicit training on the reasoning steps to take.
- The DeepSeek team found that fine-tuning via reinforcement learning alone (after pretraining) was sufficient for DeepSeek-R1-Zero to learn problem-solving strategies like double checking its answer. However, the model also showed quirky behaviors such as mixing different languages in its output. The team overcame these issues in DeepSeek-R1 by supervised fine-tuning on a small number of long CoT examples prior to reinforcement learning.
- Similarly, the Kimi k1.5 team found that fine-tuning the model on long CoTs prior to reinforcement learning enabled it to devise its own problem-solving strategies. The resulting long responses proved to be more accurate but also more expensive to generate, so the team added a second round of reinforcement learning that encouraged the model to produce shorter responses. On the AIME 2024 benchmark of advanced math problems, this process reduced the average number of tokens in the response by around 20 percent, and on MATH-500, it cut the average number of output tokens by roughly 10 percent.
- OpenAI has disclosed limited information about how it trained o1, but team members have said they used reinforcement learning to improve the model’s chain of thought.
Behind the news: While RL has been a staple technique for training models to play games and control robots, its role in developing LLMs has been confined to alignment with human preferences. Reinforcement learning to match judgements of humans (reinforcement learning from human feedback, or RLHF) or AI (Constitutional AI, which uses reinforcement learning from AI feedback or RLAIF) were the primary methods for encouraging LLMs to align with human preferences prior to the development of direct preference optimization.
Why it matters: Reinforcement learning has surprising utility in training large language models to reason. As researchers press models into service in more complex tasks — math, coding, animated graphics, and beyond — reinforcement learning is emerging as an important path to progress.
We’re thinking: Less than three years ago, reinforcement learning looked too finicky to be worth the trouble. Now it’s a key direction in language modeling. Machine learning continues to be full of surprising twists!

Computer Use Gains Momentum
OpenAI introduced an AI agent that performs simple web tasks on a user’s behalf.
What’s new: Operator automates online actions like buying goods, booking tickets and completing forms by navigating websites in a browser-like environment within ChatGPT. It’s available on desktops as a research preview for subscribers to ChatGPT Pro ($200 per month). OpenAI promises broader availability to come as well as API access to the underlying model and improved ability to coordinate multi-step tasks like scheduling meetings across calendars from different vendors.
How it works: Operator uses a new model called Computer-Using Agent (CUA) that accepts text input and responds with web actions.
- Users type commands into ChatGPT. CUA translates these inputs into structured instructions executes them by interacting directly with web elements like buttons, menus, and text fields. OpenAI didn’t disclose CUA’s architecture or training methods but said it was trained on simulated and real-world browser scenarios via reinforcement learning.
- CUA earns high marks on some measures in tests performed by OpenAI. On WebVoyager, which evaluates web tasks, CUA succeeded 87 percent of the time. On OSWorld, a benchmark that evaluates the ability of multimodal agents to perform complex tasks that involve real-world web and desktop apps, CUA achieved a success rate of 38.1 percent. In separate tests performed by Kura and Anthropic, on WebVoyager, Kura achieved 87 percent while DeepMind’s Mariner achieved 83.5 percent, and on OSWorld, Claude Sonnet 3.5 with Computer Use achieved 22 percent.
- Operator is restricted from interacting with unverified websites and sharing sensitive data without the user’s consent. It offers content filters, and a separate model monitors Operator in real time and pauses the agent in case of suspicious behavior.
Behind the news: Operator rides a wave of agents designed to automate everyday tasks. Last week, OpenAI introduced ChatGPT Tasks, which lets users schedule reminders and alerts but doesn’t support web interaction. (Early users complained that Tasks was buggy and required overly precise instructions.) Anthropic’s Computer Use focuses on basic desktop automation, while DeepMind’s Project Mariner is a web-browsing assistant built on Gemini 2.0. Perplexity Assistant automates mobile apps such as booking Uber rides on Android phones.
Why it matters: In early reports, users said Operator sometimes was less efficient than a human performing the same tasks. Nevertheless, agentic AI is entering the consumer market, and Operator is poised to give many people their first taste. It’s geared to provide AI assistance for an endless variety of personal and business uses, and — like ChatGPT was for other developers of LLMs — and it’s bound to serve as a template for next-generation products.
We’re thinking: Computer use is maturing, and the momentum behind it is palpable. AI developers should have in their toolbox.

White House Orders Muscular AI Policy
Under a new president, the United States reversed its approach to AI regulation, seeking global dominance by reducing restrictions.
What’s new: President Trump, who took office last week, signed an executive order that set a 180-day deadline to draft an AI Action Plan. The order aims to boost national security, economic competitiveness, and U.S. leadership in artificial intelligence.
How it works: The executive order assigns responsibility for crafting the AI Action Plan to three key figures in the administration: Michael Kratsios, assistant to the president for science and technology (and former managing director of Scale AI); venture capitalist David Sacks, the new special advisor for AI and cryptocurrency; and national security advisor Michael Waltz.
- The AI Action Plan must “sustain and enhance America’s global AI dominance in order to promote human flourishing, economic competitiveness, and national security.”
- The order directs agency heads to suspend or eliminate policies created under President Biden’s 2023 executive order, which President Trump revoked, that may conflict with advancing U.S. AI dominance and national security.
- U.S. companies are to develop AI systems “free from ideological bias or engineered social agendas,” reflecting the administration’s belief that AI systems encode liberal political biases.
- The order directs the federal Office of Management and Budget to award government contracts to AI companies that align with the administration’s emphasis on advancing U.S. competitiveness and national security.
- Most provisions leave significant discretion to the team that will draft the action plan, making their interpretation and implementation open-ended.
AI infrastructure build-out: Along with the executive order, President Trump announced Stargate, a joint venture that involves OpenAI, Oracle, and SoftBank. The three companies outlined a plan to invest $100 billion in computing infrastructure for AI, such as next-generation data centers, and $500 billion over four years. In addition, the administration declared a national energy emergency with respect to U.S. supplies of energy and issued an order to ramp up domestic energy production. These measures aim to support energy-intensive AI initiatives like Stargate by removing regulatory barriers to building oil, gas, and renewable energy projects on federal lands.
Why it matters: The Trump administration says that Biden’s 2023 regulations were “onerous and unnecessary,” stifled innovation, and jeopardized U.S. leadership in AI. The new order reduces bureaucratic oversight of AI development, creating a more permissive regulatory environment (except when it comes to ideological bias).
We’re thinking: The Biden administration’s 2023 executive order aimed to guard against hypothetical, rather than actual, AI risks. It introduced thresholds of processing used to train models as a measure of their risk — a poorly thought-out proxy. To be fair, the AI Safety Institute under the U.S. National Institute of Standards and Technology didn’t hamper AI progress as much as some had feared, but overall the order was not helpful to AI innovation or safety. We’re pleased that the new administration is focusing on AI progress rather than hypothetical risks.
Fine-Tuning Fine Points
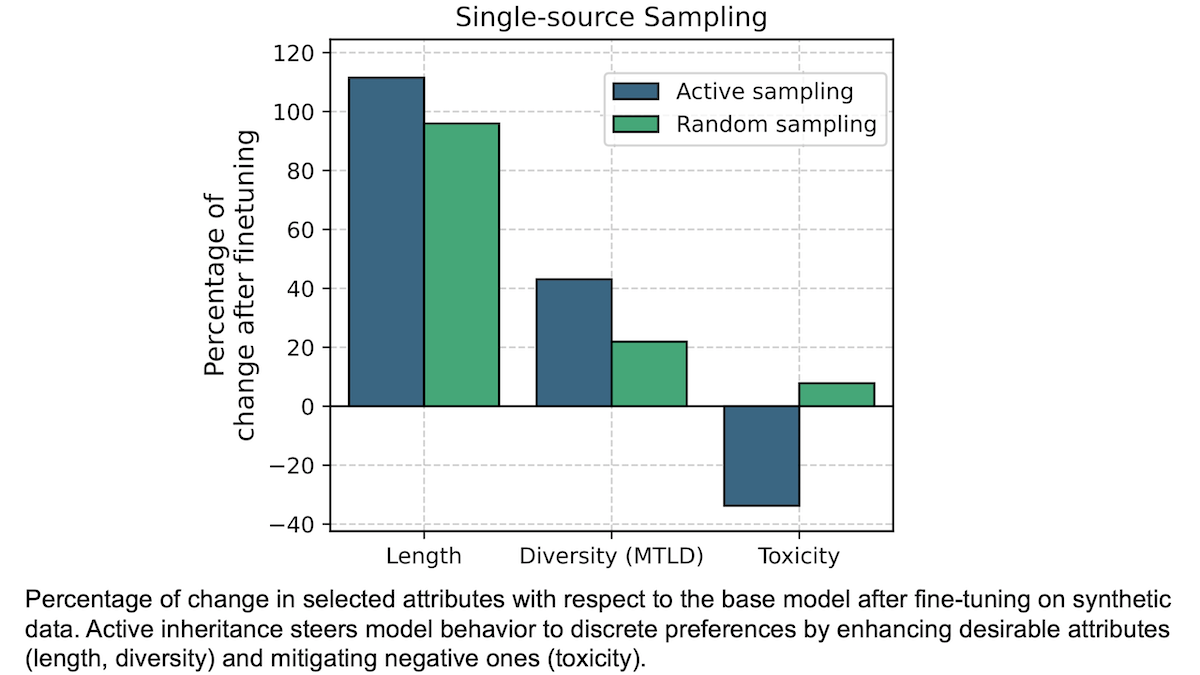
The practice of fine-tuning models on synthetic data is becoming well established. But synthetic training data, even if it represents the training task well, may include characteristics like toxicity that impart unwelcome properties in the trained model’s output, and it may inconsistently represent desired traits such as the target output length. Researchers developed a method that reduces aspects of generated data and retains desired ones.
What’s new: Luísa Shimabucoro and colleagues at Cohere introduced active inheritance, a fine-tuning method that automatically selects synthetic training examples that have desirable characteristics.
Key insight: A naive way to generate synthetic fine-tuning data is to feed prompts to a model, collect its output, and use that as the fine-tuning set. But synthetic data is cheap, so we can afford to be more choosy. By generating several responses to each prompt, we can select the one that best suits our purposes.
How it works: The authors used Llama 2 7B and Mixtral 8x7B as both teachers and students in all combinations. They prompted the models with 52,000 prompts from the Alpaca dataset and used automated methods to evaluate their outputs in terms of characteristics including social bias, toxicity, word count, lexical diversity, and calibration (how well a model’s estimated probabilities match its accuracy).
- The authors generated 10 responses to each prompt.
- For each response, they measured social bias according to StereoSet, CrowS-Pairs, and Bias Benchmark for Question-Answering. They measured toxicity according to Perspective API and their own code. They measured calibration according to HELM. They used TextDescriptives to calculate metrics related to text.
- They fine-tuned separate models on (i) the initial responses, (ii) one response to each prompt selected at random, and (iii) the response to each prompt that best maximized each desired characteristic.
Results: Fine-tuning on the best response for each characteristic improved performance with respect to that characteristic beyond using the initial outputs or selecting outputs randomly.
- The authors’ method helped Mixtral 8x7B to generate less-toxic responses. For example, before fine-tuning, the model’s expected maximum toxicity measured 65.2 (lower is better). After fine-tuning on the lowest-toxicity responses generated by Llama 2 7B, Mixtral 8x7B’s expected maximum toxicity fell to 43.2. Conversely, after fine-tuning on random responses generated by Llama 2 7B, its expected maximum toxicity rose to 70.3.
- It also helped Llama 2 7B to cut its toxicity. Before fine-tuning, the model’s expected maximum toxicity was 71.7. After fine-tuning on its own least-toxic responses, expected maximum toxicity dropped to 50.7. Fine-tuning on random responses made its expected maximum toxicity fall less sharply to 68.1.
- Examining the impact of the authors’ method on more typical measures of performance, fine-tuning on the least-toxic responses and fine-tuning on random responses had about the same effect across seven benchmarks. Fine-tuning Llama 2 7B on its own least-toxic responses increased performance on average from 59.97 percent accuracy to 60.22 percent accuracy, while fine-tuning on random responses increased performance on average from 59.97 percent accuracy to 61.05 percent accuracy.
- However, the process degraded performance in some cases. Fine-tuning Mixtral-8x7B on the least-toxic Llama 2 7B responses decreased its average performance across seven benchmarks for question answering and common-sense reasoning from 70.24 percent accuracy to 67.48 percent accuracy. Fine-tuning it on random Llama 2 7B responses cut its average performance from 70.24 percent accuracy to 65.64 percent accuracy.
Why it matters: Training on synthetic data is becoming increasingly common. While it shows great promise, best practices for data generation are still being formulated. The authors’ method helps by automatically steering models toward generating more desirable responses, reducing negative traits and reinforcing positive traits.
We’re thinking: Knowledge distillation lately has led to more capable and compact models. This approach adds levers of fine control to that technique.