
Dear friends,
A “10x engineer” — a widely accepted concept in tech — purportedly has 10 times the impact of the average engineer. But we don’t seem to have 10x marketers, 10x recruiters, or 10x financial analysts. As more jobs become AI enabled, I think this will change, and there will be a lot more “10x professionals.”
There aren’t already more 10x professionals because, in many roles, the gap between the best and the average worker has a ceiling. No matter how athletic a supermarket checkout clerk is, they’re not likely to scan groceries so fast that customers get out of the store 10x faster. Similarly, even the best doctor is unlikely to make patients heal 10x faster than an average one (but to a sick patient, even a small difference is worth a lot). In many jobs, the laws of physics place a limit on what any human or AI can do (unless we completely reimagine that job).
But for many jobs that primarily involve applying knowledge or processing information, AI will be transformative. In a few roles, I’m starting to see tech-savvy individuals coordinate a suite of technology tools to do things differently and start to have, if not yet 10x impact, then easily 2x impact. I expect this gap to grow.
10x engineers don’t write code 10 times faster. Instead, they make technical architecture decisions that result in dramatically better downstream impact, they spot problems and prioritize tasks more effectively, and instead of rewriting 10,000 lines of code (or labeling 10,000 training examples) they might figure out how to write just 100 lines (or collect 100 examples) to get the job done.
I think 10x marketers, recruiters, and analysts will, similarly, do things differently. For example, perhaps traditional marketers repeatedly write social media posts. 10x marketers might use AI to help write, but the transformation will go deeper than that. If they are deeply sophisticated in how to apply AI — ideally able to write code themselves to test ideas, automate tasks, or analyze data — they might end up running a lot more experiments, get better insights about what customers want, and generate much more precise or personalized messages than a traditional marketer, and thereby end up making 10x impact.

Similarly, 10x recruiters won’t just use generative AI to help write emails to candidates or summarize interviews. (This level of use of prompting-based AI will soon become table stakes for many knowledge roles.) They might coordinate a suite of AI tools to efficiently identify and carry out research on a large set of candidates, enabling them to have dramatically greater impact than the average recruiter. And 10x analysts won’t just use generative AI to edit their reports. They might write code to orchestrate a suite of AI agents to do deep research into the products, markets, and companies, and thereby derive far more valuable conclusions than someone who does research the traditional way.
A 2023 Harvard/BCG study estimated that, provided with GPT-4, consultants could complete 12% more tasks, and completed tasks 25% more quickly. This was just the average, using 2023 technology. The maximum advantage to be gained by using AI in a sophisticated way will be much bigger, and will only grow as technology improves.
Here in Silicon Valley, I see more and more AI-native teams reinvent workflows and do things very differently. In software engineering, we've venerated the best engineers because they can have a really massive impact. This has motivated many generations of engineers to keep learning and working hard, because doing those things increases the odds of doing high-impact work. As AI becomes more helpful in many more job roles, I believe we will open up similar paths to a lot more people becoming a “10x professional.”
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Learn in detail how transformer-based large language models work in this new course by the authors of Hands-On Large Language Models. Explore the architecture introduced in the paper “Attention Is All You Need,” and learn through intuitive explanations and code examples. Join in for free
News
Reasoning in High Gear
OpenAI introduced a successor to its o1 models that’s faster, less expensive, and especially strong in coding, math, and science.
What’s new: o3-mini is a large language model that offers selectable low, medium, and high levels of reasoning “effort.” These levels consume progressively higher numbers of reasoning tokens (specific numbers and methods are undisclosed), and thus greater time and cost, to generate a chain of thought. It’s available to subscribers to ChatGPT Plus, Team, and Pro, as well as to higher-volume users of the API (tiers 3 through 5). Registered users can try it via the free ChatGPT service by selecting “reason” in the message composer or selecting o3-mini before regenerating a response.
How it works: o3-mini’s training set emphasized structured problem-solving in science and technology fields, and fine-tuning used reinforcement learning on chain-of-thought (CoT) data. Like the o1 family, it charges for tokens that are processed during reasoning operations and hides them from the user. (Competing reasoning models DeepSeek-R1, Gemini 2.0 Flash Thinking, and QwQ-32B-Preview make these tokens available to users.) o3-mini has a maximum input of 200,000 tokens and a maximum output of 100,000 tokens. Its knowledge cutoff is October 2023.
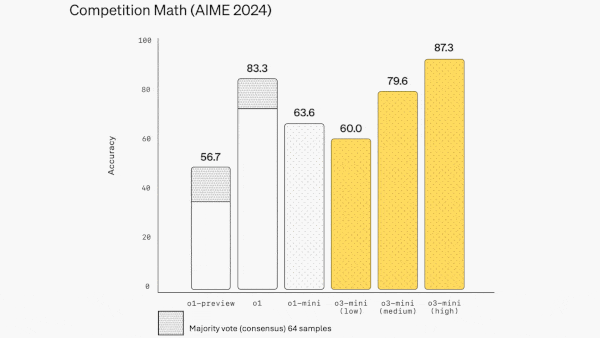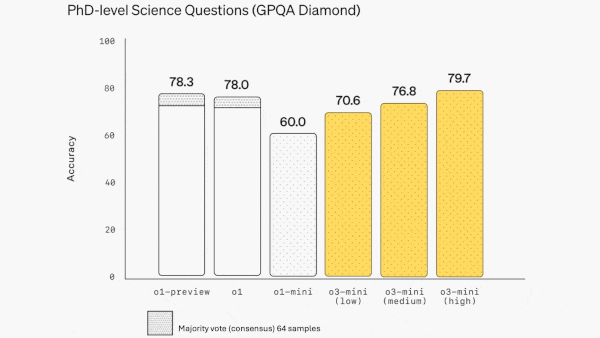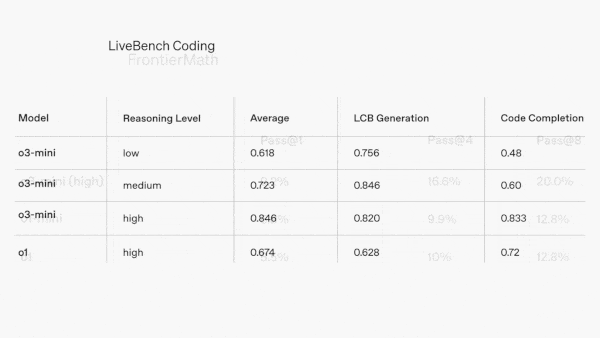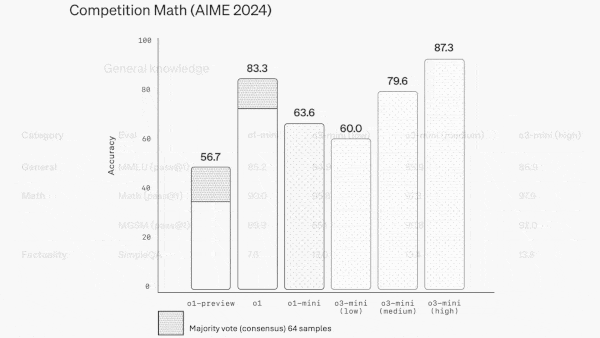
- In OpenAI’s tests, o3-mini beat o1 and o1-mini on multiple benchmarks including math (AIME 2024), science (GPQA Diamond), and coding (Codeforces and LiveBench). It outperformed o1 by 1 to 4 percentage points when set at high or medium effort, and it outperformed o1-mini when set at low effort. It did significantly less well on tests of general knowledge, even with high effort. On MMLU (multiple-choice questions in many fields) and SimpleQA (questions about basic facts), o3-mini with high effort (which achieved 86.9 percent and 13.8 percent respectively) underperformed o1 (92.3 percent and 47 percent) and GPT-4o (88.7 percent and 39 percent).
- Unlike o1-mini, o3-mini supports function calling, structured outputs (JSON format), developer messages (system prompts that specify the model’s context or persona separately from user input), and streaming (delivering responses token-by-token in real time).
- API access costs $1.10/$4.40 per million input/output tokens with a discounted rate of $0.55 per million cached input tokens. OpenAI’s Batch API, which processes high-volume requests asynchronously, costs half as much. In comparison, access to o1 costs $15/$60 per million input/output tokens and o1-mini costs $3/$12 per million input/output tokens. (OpenAI recently removed API pricing for o1-mini and, in the ChatGPT model picker, replaced it with o3-mini, which suggests that o1-mini is being phased out.)
- OpenAI limits the number API calls users can make per minute and per day depending on how frequently they use the API and how much money they’ve spent. Rate limits range from 5,000/4 million requests/tokens per per minute (Tier 3) to 30,000/150 million requests/tokens per minute (Tier 5), with higher limits for batch requests.
- o3-mini’s system card highlights safety measures taken during the model’s training. OpenAI notes that o3-mini’s improved coding ability puts it at a medium risk for autonomous misuse, the first OpenAI model to be so flagged.
What they’re saying: Users praised o3-mini for its speed, reasoning, and coding abilities. They noted that it responds best to “chunkier” prompts with lots of context. However, due to its smaller size, it lacks extensive real-world knowledge and struggles to recall facts.
Behind the news: Days after releasing o3-mini, OpenAI launched deep research, a ChatGPT research agent based on o3. OpenAI had announced the o3 model family in December, positioning it as an evolution of its chain-of-thought approach. The release followed hard upon that of DeepSeek-R1, an open weights model that captivated the AI community with its high performance and low training cost, but OpenAI maintained that the debut took place on its original schedule.
Why it matters: o3-mini continues OpenAI’s leadership in language models and further refines the reasoning capabilities introduced with the o1 family. In focusing on coding, math, and science tasks, it takes advantage of the strengths of reasoning models and raises the bar for other model builders. In practical terms, it pushes AI toward applications in which it’s a reliable professional partner rather than a smart intern.
We’re thinking: We’re glad that o3-mini is available to users of ChatGPT’s free tier as well as paid subscribers and API users. The more users become familiar with how to prompt reasoning models, the more value they’ll deliver.
Training for Computer Use
As Anthropic, Google, OpenAI, and others roll out agents that are capable of computer use, new work shows how underlying models can be trained to do this.
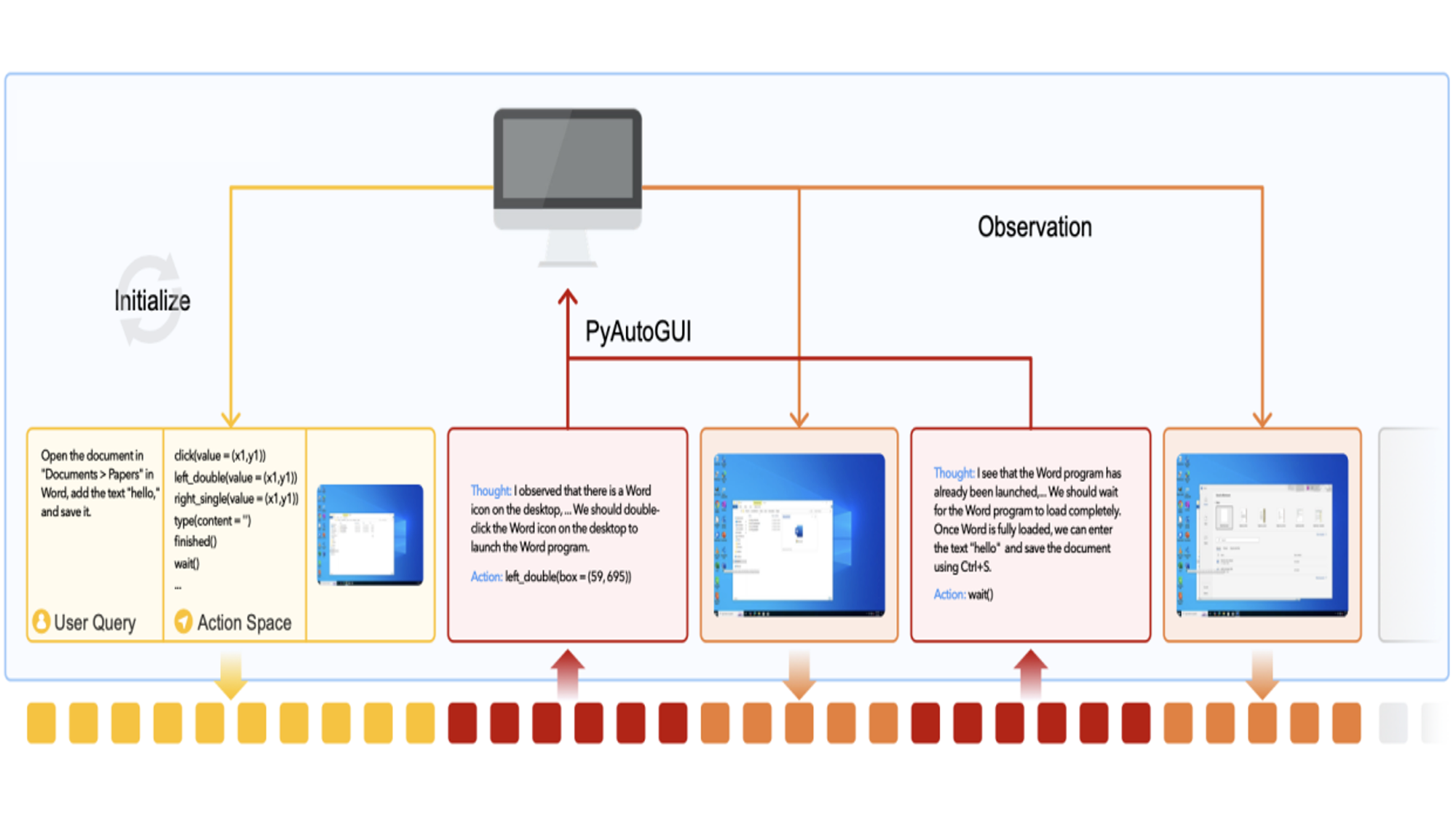
What’s new: Yujian Qin and colleagues at ByteDance and Tsinghua University introduced UI-TARS, a fine-tuned version of the vision-language model Qwen2-VL that uses lines of reasoning to decide which mouse clicks, keyboard presses, and other actions to take in desktop and mobile apps. The model’s weights are licensed freely for commercial and noncommercial uses via Apache 2.0. You can download them here.
- The authors added chains of thought (CoTs) to their training set of screenshots and actions by prompting an unspecified vision-language model to explain the current action given previous screenshots, actions, and generated CoTs. Sometimes that process led to bad explanations, so they also generated multiple CoTs and actions for a given screenshot and selected the CoT that led to the correct action.
- They fine-tuned UI-TARS to generate a CoT and action from an instruction (such as “Open the document and add the text ‘hello’”) plus the screenshots, CoTs, and actions so far.
- They ran UI-TARS within a virtual PC, generating a large number of screenshots, CoTs, and actions so far. They filtered out erroneous CoTs and actions using rules (such as removing those that included redundant actions), scoring outputs automatically and removing those with low scores, and reviewing them manually. They fine-tuned the model on the remaining outputs and repeatedly generated, filtered, and fine-tuned.
- They also fine-tuned the model on corrected examples of erroneous CoTs and actions. Human annotators corrected the CoT and action to (a) avoid the error and (b) fix the error after it occurred.
- Finally, they fine-tuned the model using Direct Preference Optimization (DPO) to prefer generating the corrected examples over the erroneous examples from the previous step.
- At inference, given a screenshot, an instruction, and potential actions (as is typical with open computer use models; the authors provide a handy list in a sample prompt), UI-TARS generated a CoT and an action to take. After taking that action (via PyAutoGUI, a Python module that controls computers), the model received a new screenshot and generated another chain of thought and action, and so on. At each step, the model produced a new chain of thought and action, taking into account the instruction and all CoTs, actions, and screenshots so far.
Behind the news: Adept touted computer use in early 2022, and OmniParser Aguvis soon followed with practical implementations. In October 2024, Anthropic set off the current wave of model/app interaction with its announcement of computer use for Claude 3.5 Sonnet. OpenAI recently responded with Operator, its own foray into using vision and language models to control computers.
Results: UI-TARS matched or outperformed Claude 3.5 Sonnet with computer use, GPT-4o with various computer use frameworks, and the Aguvis framework with its native model on 11 benchmarks. On OSWorld, which asks models to perform tasks using a variety of real-world applications and operating systems, UI-TARS successfully completed 22.7 percent of the tasks in 15 steps, whereas Claude 3.5 Sonnet with computer use completed 14.9 percent, GPT-4o with Aguvis 17 percent, and Aguvis with its native model 10.3 percent.
Why it matters: Training a model to take good actions enables it to perform well. Training it to correct its mistakes after making them enables it to recover from unexpected issues that may occur in the real world.
We’re thinking: Since computer use can be simulated in a virtual machine, it’s possible to generate massive amounts of training data automatically. This is bound to spur rapid progress in computer use by large language models.
Gemini Thinks Faster
Google updated the December-vintage reasoning model Gemini 2.0 Flash Thinking and other Flash models, gaining ground on OpenAI o1 and DeepSeek-R1.
What’s new: Gemini 2.0 Flash Thinking Experimental 1-21 is a vision-language model (images and text in, text out) that’s trained to generate a structured reasoning process or chain of thought. The new version improves on its predecessor’s reasoning capability and extends its context window. It's free to access via API while it remains designated “experimental” and available to paid users of the Gemini app, along with Gemini 2.0 Flash (fresh out of experimental mode) and the newly released Gemini 2.0 Pro Experimental. The company also launched a preview of Gemini 2.0 Flash Lite, a vision-language model (images and text in, text out) that outperforms Gemini 1.5 Flash at the same price.
How it works: Gemini 2.0 Flash Thinking Experimental 1-21 is based on Gemini 2.0 Flash Experimental (parameter count undisclosed). It processes up to 1 million tokens of input context, compared to its predecessor’s 32,000 and o1’s 128,000.
- Unlike o1, which hides its chain of thought, but like DeepSeek-R1 and Qwen QwQ, Gemini 2.0 Flash Thinking Experimental 1-21 includes its reasoning in its output.
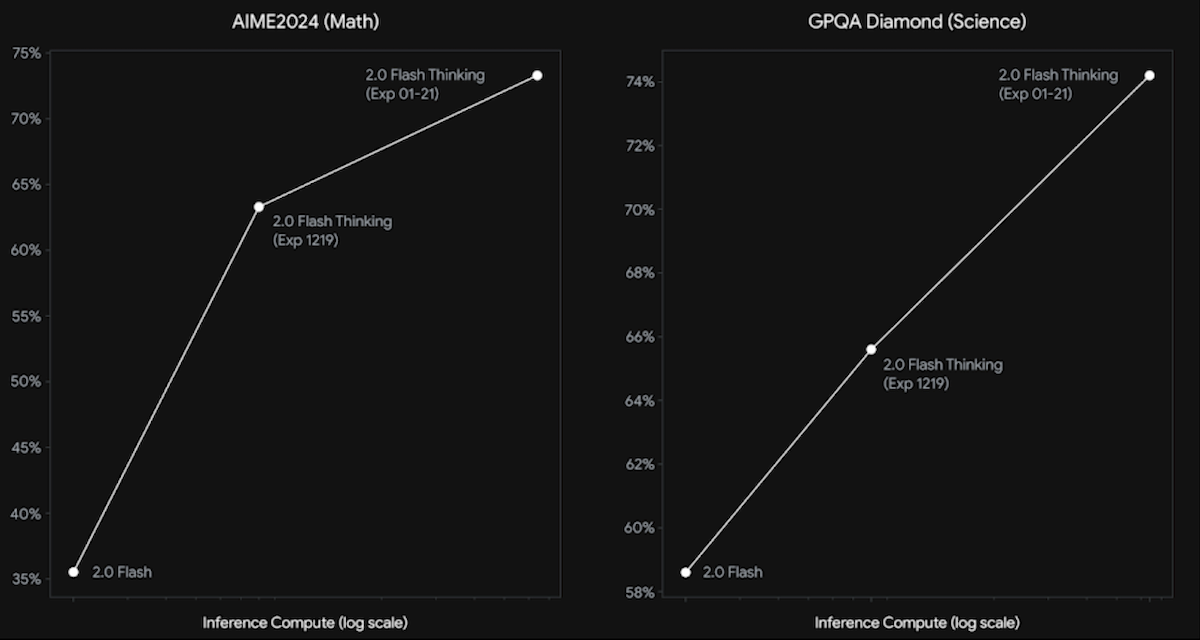
- On the graduate-level science exam GPQA-Diamond, it achieved 74.2 percent compared to the earlier version’s 58.6 percent, surpassing DeepSeek-R1 (71.5 percent) but behind o1 (77.3 percent).
- On the advanced math benchmark AIME 2024, it achieved 73.3 percent compared to the previous version’s 35.5 percent, but it trails behind DeepSeek-R1 (79.8 percent) and o1 (74.4 percent).
- On the visual and multimedia understanding test MMMU, it achieved 75.4 percent to outperform the previous version (70.7 percent) but fell short of o1 (78.2 percent).
- Developers can integrate Python code execution via the API, with support for data analysis and visualization through pre-installed libraries.
Speed bumps: Large language models that are trained to generate a chain of thought (CoT) are boosting accuracy even as the additional processing increases inference costs and latency. Reliable measures of Gemini 2.0 Flash Thinking Experimental 1-21’s speed are not yet available, but its base model runs faster (168.8 tokens per second with 0.46 seconds of latency to the first token, according to Artificial Analysis) than all models in its class except o1-mini (which outputs 200 tokens per second with 10.59 seconds of latency to the first token).
Why it matters: The combination of CoT reasoning and long context — assuming the new model can take advantage of its 1 million-token context window, as measured by a benchmark such as RULER — could open up valuable applications. Imagine a reasoning model that can take an entire codebase as input and analyze it without breaking it into smaller chunks.
We’re thinking: Regardless of benchmark performance, this model topped the Chatbot Arena leaderboard at the time of writing. This suggests that users preferred it over o1 and DeepSeek-R1 — at least for common, everyday prompts.

Okay, But Please Don’t Stop Talking
Even cutting-edge, end-to-end, speech-to-speech systems like ChatGPT’s Advanced Voice Mode tend to get interrupted by interjections like “I see” and “uh-huh” that keep human conversations going. Researchers built an open alternative that’s designed to go with the flow of overlapping speech.
What’s new: Alexandre Défossez, Laurent Mazaré, and colleagues at Kyutai, a nonprofit research lab in Paris, released Moshi, an end-to-end, speech-to-speech system that’s always listening and always responding. The weights and code are free for noncommercial and commercial uses under CC-BY 4.0, Apache 2.0, and MIT licenses. You can try a web demo here.
Key insight: Up to 20 percent of spoken conversation consists of overlapping speech, including interjections like “okay” and “I see.”
- To respond appropriately despite such overlaps, a system must both listen and generate sound continuously — although much of what it will generate is silence.
- To respond without delay, it must keep latency to a minimum. This goal requires an end-to-end design rather than a pipeline of stand-alone models to perform voice detection, speech-to-text, text processing, and text-to-speech in turn.
How it works: The authors combined an encoder-decoder called Mimi and an RQ-Transformer, which is made up of the Helium transformer-based large language model (LLM) plus another transformer.
- Mimi’s encoder embedded spoken input using 8 audio tokens per timestep (80 milliseconds). The authors trained Mimi on 7 million hours of mostly English speech from undisclosed sources. The training involved two loss terms. (i) The first loss term encouraged Mimi, given one audio timestep, to produce audio that fooled a pretrained MS-STFT discriminator into thinking it was human speech. The second loss term distilled knowledge from a pretrained WavLM, an audio embedding model. It encouraged Mimi’s encoder, when Mimi and WavLM received the same audio timestep, to produce one audio token (of its 8 audio tokens per timestep) whose embedding was similar to the corresponding embedding produced by WavLM.
- Given the audio tokens, the Helium LLM produced text tokens that were used internally to help the additional transformer predict the next audio token (the idea being that the LLM’s skill with words would inform which audio token to generate next). The authors trained Helium to predict the next text token in 2.1 trillion tokens of English text (12.5 percent from Wikipedia and Stack Exchange, and the remaining 87.5 percent from Common Crawl).
- RQ-Transformer received many sets of 17 tokens per time step: 8 audio tokens encoded by Mimi from the audio input, 8 audio tokens from Moshi’s previously generated audio output, and 1 text token produced by Helium. RQ-Transformer learned to predict the next set of 17 tokens in 7 million hours of audio and transcribed text.
- To train the system specifically on conversational interaction, the authors further trained it to predict the next token in 2,000 hours of recorded phone conversations between randomly paired participants.
- At inference, given a user's speech, Mimi turned it into audio tokens. Given the audio tokens and RQ-Transformer’s previously generated audio and text tokens, RQ-Transformer generated new audio and text tokens. From the generated audio tokens, Mimi produced synthetic speech.
Results: In tests, Moshi proved fast and relatively accurate.
- Moshi (7 billion parameters) took around 200 milliseconds to respond to user input. In comparison, GPT-4o, which also produces speech output directly from speech input, took 232 milliseconds minimum (320 milliseconds average). Prior to GPT-4o, ChatGPT Voice Mode (a pipeline of speech-to-text, text-to-text, and text-to-speech models) took an average of 5.4 seconds.
- Moshi achieved 26.6 percent accuracy on Web Questions, higher than the speech-to-text-to-speech models tested by the authors: Spectron (1 billion parameters) achieved 6.1 percent accuracy and SpeechGPT (7 billion parameters) achieved 6.5 percent accuracy. The authors didn’t provide comparable results for GPT-4o or ChatGPT Voice.
Why it matters: While a turn-based approach may suffice for text input, voice-to-voice interactions benefit from a system that processes both input and output quickly and continuously. Previous systems process input and output separately, making users wait. Moshi delivers seamless interactivity.
We’re thinking: Generating silence is golden!