
Dear friends,
The Voice Stack is improving rapidly. Systems that interact with users via speaking and listening will drive many new applications. Over the past year, I’ve been working closely with DeepLearning.AI, AI Fund, and several collaborators on voice-based applications, and I will share best practices I’ve learned in this and future letters.
Foundation models that are trained to directly input, and often also directly generate, audio have contributed to this growth, but they are only part of the story. OpenAI’s RealTime API makes it easy for developers to write prompts to develop systems that deliver voice-in, voice-out experiences. This is great for building quick-and-dirty prototypes, and it also works well for low-stakes conversations where making an occasional mistake is okay. I encourage you to try it!
However, compared to text-based generation, it is still hard to control the output of voice-in voice-out models. In contrast to directly generating audio, when we use an LLM to generate text, we have many tools for building guardrails, and we can double-check the output before showing it to users. We can also use sophisticated agentic reasoning workflows to compute high-quality outputs. Before a customer-service agent shows a user the message, “Sure, I’m happy to issue a refund,” we can make sure that (i) issuing the refund is consistent with our business policy and (ii) we will call the API to issue the refund (and not just promise a refund without issuing it).
In contrast, the tools to prevent a voice-in, voice-out model from making such mistakes are much less mature.
In my experience, the reasoning capability of voice models also seems inferior to text-based models, and they give less sophisticated answers. (Perhaps this is because voice responses have to be more brief, leaving less room for chain-of-thought reasoning to get to a more thoughtful answer.)
When building applications where I need a high degree of control over the output, I use agentic workflows to reason at length about the user’s input. In voice applications, this means I end up using a pipeline that includes speech-to-text (STT, also known as ASR, or automatic speech recognition) to transcribe the user’s words, then processes the text using one or more LLM calls, and finally returns an audio response to the user via TTS (text-to-speech). This STT → LLM/Agentic workflow → TTS pipeline, where the reasoning is done in text, allows for more accurate responses.
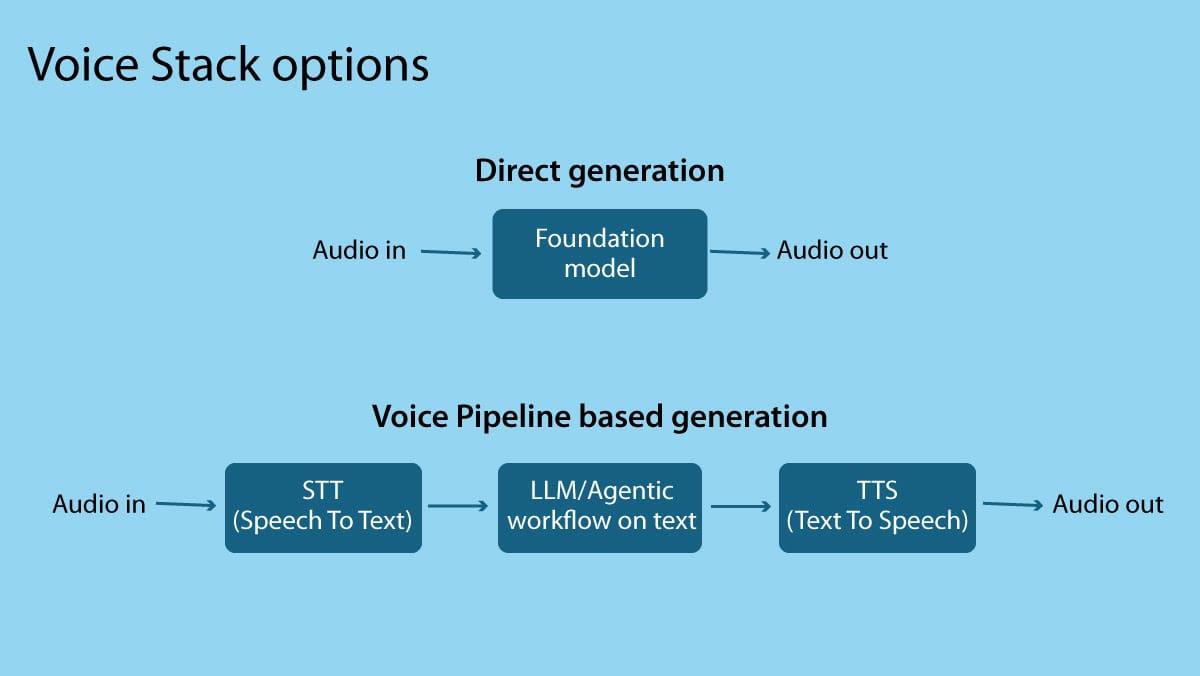
However, this process introduces latency, and users of voice applications are very sensitive to latency. When DeepLearning.AI worked with RealAvatar (an AI Fund portfolio company led by Jeff Daniel) to build an avatar of me, we found that getting TTS to generate a voice that sounded like me was not very hard, but getting it to respond to questions using words similar to those I would choose was. Even after a year of tuning our system — starting with iterating on multiple, long, mega-prompts and eventually developing complex agentic workflows — it remains a work in progress. You can play with it here.
Initially, this agentic workflow incurred 5-9 seconds of latency, and having users wait that long for responses led to a bad experience. To address this, we came up with the following latency reduction technique. The system quickly generates a pre-response (short for preliminary response) that can be uttered quickly, which buys time for an agentic workflow to generate a more thoughtful, full response. (We’re grateful to LiveKit’s CEO Russ d’Sa and team for helping us get this working.) This is similar to how, if you were to ask me a complicated question, I might say “Hmm, let me think about that” or “Sure, I can help with that” — that’s the pre-response — while thinking about what my full response might be.
I think generating a pre-response followed by a full response, to quickly acknowledge the user’s query and also reduce the perceived latency, will be an important technique, and I hope many teams will find this useful. Our goal was to approach human face-to-face conversational latency, which is around 0.3-1 seconds. RealAvatar and DeepLearning.AI, through our efforts on the pre-response and other optimizations, have reduced the system’s latency to around 0.5-1 seconds.
Months ago, sitting in a coffee shop, I was able to buy a phone number on Twilio and hook it up to an STT → LLM → TTS pipeline in just hours. This enabled me to talk to my own LLM using custom prompts. Prototyping voice applications is much easier than most people realize!
Building reliable, scaled production applications takes longer, of course, but if you have a voice application in mind, I hope you’ll start building prototypes and see how far you can get! I’ll keep building voice applications and sharing best practices and voice-related technology trends in future letters.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

AI coding agents do more than autocomplete. They help you debug, refactor, and design applications. Learn how coding agents work under the hood, so you can streamline your projects and build applications such as a Wikipedia data-analysis app! Enroll Now.
News

Reading Minds, No Brain Implant Required
To date, efforts to decode what people are thinking from their brain waves often relied on electrodes implanted in the cortex. New work used devices outside the head to pick up brain signals that enabled an AI system, as a subject typed, to accurately guess what they were typing.
What’s new: Researchers presented Brain2Qwerty, a non-invasive method to translate brain waves into text. In addition, their work shed light on how the brain processes language. The team included people at Meta, Paris Sciences et Lettres University, Hospital Foundation Adolphe de Rothschild, Basque Center on Cognition, Brain and Language, Basque Foundation for Science, Aix-Marseille University, and Paris Cité University.
Gathering brainwave data: The authors recorded the brain activity of 35 healthy participants who typed Spanish-language sentences. The participants were connected to either an electroencephalogram (EEG), which records the brain’s electrical activity via electrodes on the scalp, or a magnetoencephalogram (MEG), which records magnetic activity through a device that surrounds the head but isn’t attached. 15 participants used each device and five used both.
- Participants were asked to read and memorize short sentences of 5 to 8 words. They were shown one word at a time.
- After a short waiting period, participants were asked to type the sentence. They could not see what they typed.
- The EEG dataset comprised around 4,000 sentences and 146,000 characters, while the MEG dataset comprised around 5,100 sentences and 193,000 characters.
Thoughts into text: Brain2Qwerty used a system made up of a convolutional neural network, transformer, and a 9-gram character-level language model pretrained on Spanish Wikipedia. The system classified the text a user typed from their brain activity. The authors trained separate systems on MEG and EEG data.
- The convolutional neural network segmented brain activity into windows of 500 milliseconds each. The transformer took these windows as input and generated possible text characters and their probabilities. The two models learned to predict characters jointly.
- The pretrained language model, given the most recently predicted nine characters, estimated the probability of the next character.
- At inference, the authors used a weighted average of probabilities from the transformer and language model. From that average, they computed the most likely sequence of characters as the final output.
Results. The authors’ MEG model achieved 32 percent character error rate (CER), much higher accuracy than the EEG competitors. Their EEG system outperformed EEGNet, a model designed to process EEG data that had been trained on the authors’ EEG data. It achieved 67 percent CER, while EEGNet achieved 78 percent CER.
Behind the news: For decades, researchers have used learning algorithms to interpret various aspects of brain activity with varying degrees of success. In recent years, they’ve used neural networks to generate text and speech from implanted electrodes, generate images of what people see while in an fMRI, and enable people to control robots using EEG signals.
Why it matters: In research into interpreting brain signals, subjects who are outfitted with surgical implants typically have supplied the highest-quality brain signals. fMRI scans, while similarly noninvasive, are less precise temporally, which makes them less useful for monitoring or predicting language production. Effective systems based on MEG, which can tap brain signals precisely without requiring participants to undergo surgery, open the door to collecting far more data, training far more robust models, and conducting a wider variety of experiments.
We’re thinking: The privacy implications of such research may be troubling, but keep in mind that Brain2Qwerty’s MEG system, which was the most effective approach tested, required patients to spend extended periods of time sitting still in a shielded room. We aren’t going to read minds in the wild anytime soon.
Big AI Spending Continues to Rise
Top AI companies announced plans to dramatically ramp up their spending on AI infrastructure.
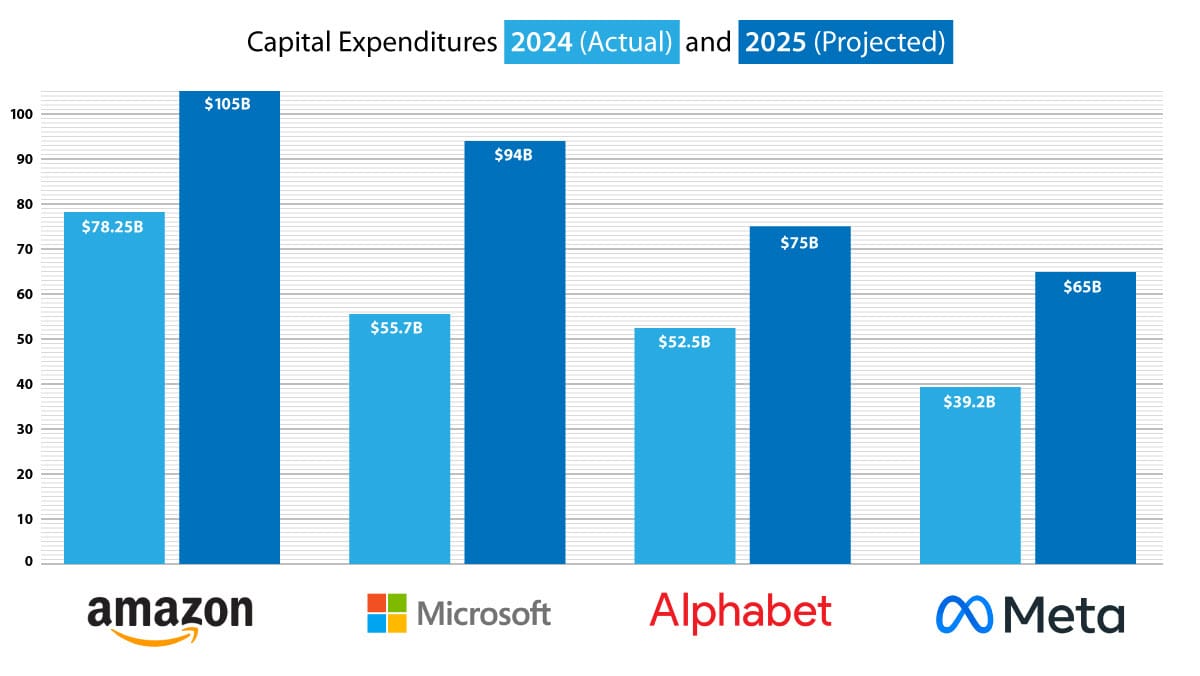
What’s new: Alphabet, Amazon, Meta, Microsoft, and others will boost their capital spending dramatically in 2025, pouring hundreds of billions of dollars into data centers where they process AI training, the companies said in their most recent quarterly reports. The surge suggests that more-efficient approaches to training models won’t dampen the need for greater and greater processing power.
How it works: Capital expenditures include long-term purchases like land, buildings, and computing hardware rather than recurring costs like salaries or electricity. The AI leaders signaled that most of this spending will support their AI efforts.
- Amazon has budgeted $105 billion to capital expenditures in 2025, 35 percent more than last year. CFO Brian Olsavsky attributed the increase to the company’s need to satisfy demand for AI services and tech infrastructure. CEO Andy Jassy emphasized that it reflects strong demand for AI and dismissed concerns that cheaper alternatives like DeepSeek would reduce overall spending. (Disclosure: Andrew Ng is a member of Amazon’s board of directors.)
- Alphabet allocated $75 billion to capital expenditures, up from $52.5 billion last year, to support growth in Google Services, Google Cloud, and Google DeepMind. The company indicated that most of this money would go to technical infrastructure including data centers and networking.
- Meta’s annual capital expenditures will amount to $65 billion, a huge jump from $39.2 billion last year. CEO Mark Zuckerberg argued that such spending on AI infrastructure and chips is needed to assure the company’s lead in AI and integrate the technology into its social platforms.
- Microsoft said it would put around $80 billion — a figure that analysts expect to rise to $94 billion — into capital expenditures in 2025, another big jump following an 83 percent rise from 2023 to 2024. Most of this investment will support cloud infrastructure, servers, CPUs, and GPUs to meet demand for AI.
- OpenAI, Oracle, SoftBank, and others announced Stargate, a project that intends immediately to put $100 billion — $500 billion over time — into data centers that would support development of artificial general intelligence. Elon Musk claimed in a tweet that the investors “don’t actually have the money,” raising questions about the announcement’s veracity.
Behind the news: DeepSeek initially surprised many members of the AI community by claiming to have trained a high-performance large language model at a fraction of the usual cost.
- Specifically, DeepSeek-R1 reportedly cost less than $6 million and 2,048 GPUs to train. (For comparison, Anthropic’s Claude 3.5 Sonnet cost “a few $10Ms to train,” according to CEO Dario Amodei, and GPT-4 cost about $100 million to train, according to CEO Sam Altman.) Follow-up reports shed light on DeepSeek’s actual infrastructure and noted that the $6 million figure represented only DeepSeek-R1’s final training run, a small fraction of the total development cost.
- Furthermore, while initial reports said DeepSeek piggy-backed on a 10,000-GPU supercomputer owned by its parent company High-Flyer, a hedge fund, research firm SemiAnalysis questioned whether DeepSeek relied on High-Flyer’s hardware. DeepSeek has spent around $1.6 billion on a cluster of 50,000 Nvidia GPUs, Tom’s Hardware reported.
- Initial excitement over the company’s low training costs gave way to concerns about data sovereignty, security, and the cost of running DeepSeek-R1, which generates a larger number of reasoning tokens than similar models.
Why it matters: DeepSeek-R1’s purported training cost fueled fears that demand for AI infrastructure would cool, but the top AI companies’ plans show that it’s not happening yet. A possible explanation lies in the Jevons Paradox, a 19th-century economic theory named after the English economist William Stanley Jevons. As a valuable product becomes more affordable, demand doesn’t fall, it rises. According to this theory, even if training costs tumble, the world will demand ever greater processing power for inference.
We’re thinking: DeepSeek’s low-cost technology momentarily rattled investors who had expected the next big gains would come from the U.S. rather than China. But DeepSeek’s efficiency follows a broader pattern we’ve seen for years: The AI community steadily wrings better performance from less processing power.

Deepfake Developers Appropriate Celebrity Likenesses
A viral deepfake video showed media superstars who appeared to support a cause — but it was made without their participation or permission.
What’s new: The video shows AI-generated likenesses of 20 Jewish celebrities ranging from Scarlett Johansson to Simon & Garfunkel. They appear wearing T-shirts that feature a middle finger inscribed with the Star of David above the word “KANYE.” The clip, which ends with the words “Enough is enough” followed by “Join the fight against antisemitism,” responds to rapper Kanye West, who sold T-shirts emblazoned with swastikas on Shopify before the ecommerce platform shut down his store.
Who created it: Israeli developers Guy Bar and Ori Bejerano generated the video to spark a conversation about antisemitism, Bar told The Jerusalem Post. The team didn’t reveal the AI models, editing tools, or techniques used to produce the video.
Johansson reacts: Scarlett Johansson denounced the clip and urged the U.S. to regulate deepfakes. In 2024, she objected to one of the voices of OpenAI’s voice assistant, which she claimed resembled her own voice, leading the company to remove that voice from its service. The prior year, her attorneys ordered a company to stop using an unauthorized AI-generated version of her image in an advertisement.
Likenesses up for grabs: Existing U.S. laws protect some uses of a celebrity’s likeness in the form of a photo, drawing, or human lookalike, but they don’t explicitly protect against reproduction by AI systems. This leaves celebrities and public figures with limited recourse against unauthorized deepfakes.
- U.S. lawmakers have introduced legislation that targets deepfake pornography, but it covers only sexually explicit deepfakes.
- The right of publicity, which falls under trademark law, offers some protection against the unauthorized use of a person’s identity. However, it varies by state and provides broad exceptions for news, satire, and fine art.
- While some states outlaw misappropriation of names or likenesses, existing laws primarily target traditional forms of image misuse, such as false endorsements or unauthorized commercial exploitation. They do not explicitly cover AI-generated deepfakes used for noncommercial, political, or satirical purposes.
- A 2023 agreement between Hollywood actors and movie studios protects actors against such uses of AI-generated images of their likenesses in films. However, it doesn’t apply to deepfakes that are produced independently for distribution via social media networks.
Why it matters: Non-consensual deepfake pornography is widely condemned, but AI enables many other non-consensual uses of someone’s likeness, and their limits are not yet consistently coded into law. If the creators of the video that appropriated the images of celebrities had responded to Johansson’s criticism with an AI-generated satire, would that be a legitimate exercise of free speech or another misuse of AI? Previously, an ambiguous legal framework may have been acceptable because such images, and thus lawsuits arising from them, were uncommon. Now, as synthetic likenesses of specific people become easier to generate, clear legal boundaries are needed to keep misuses in check.
We’re thinking: Creating unauthorized lookalikes of existing people is not a good way to advance any cause, however worthy. Developers should work with businesses policymakers to establish standards that differentiate legitimate uses from unfair or misleading exploitation.
Reasoning in Vectors, Not Text
Although large language models can improve their performance by generating a chain of thought (CoT) — intermediate text tokens that break down the process of responding to a prompt into a series of steps — much of the CoT text is aimed at maintaining fluency (such as “a”, “of”, “we know that”) rather than reasoning (“a² + b² = c²”). Researchers addressed this inefficiency.
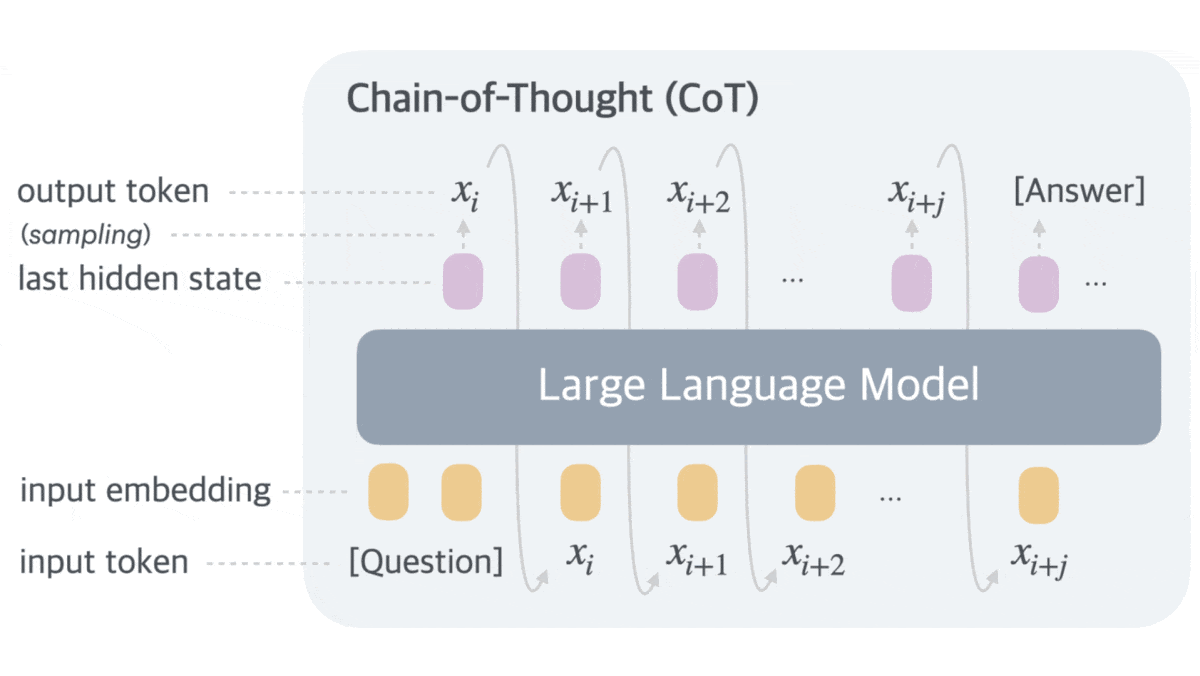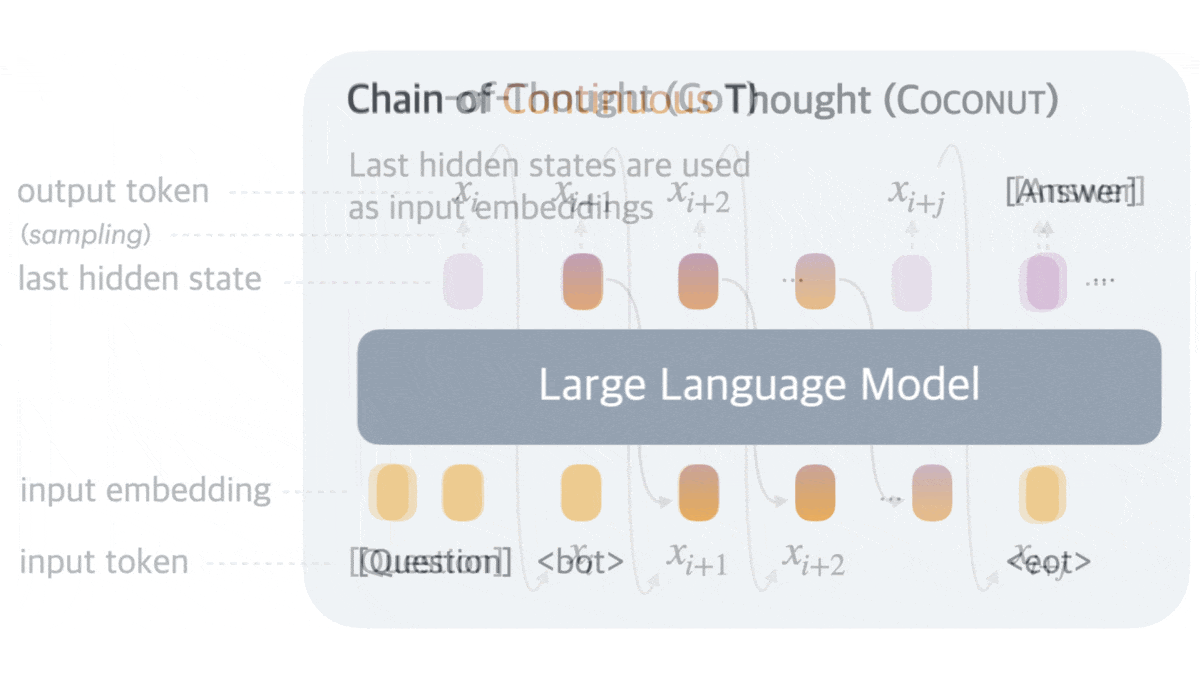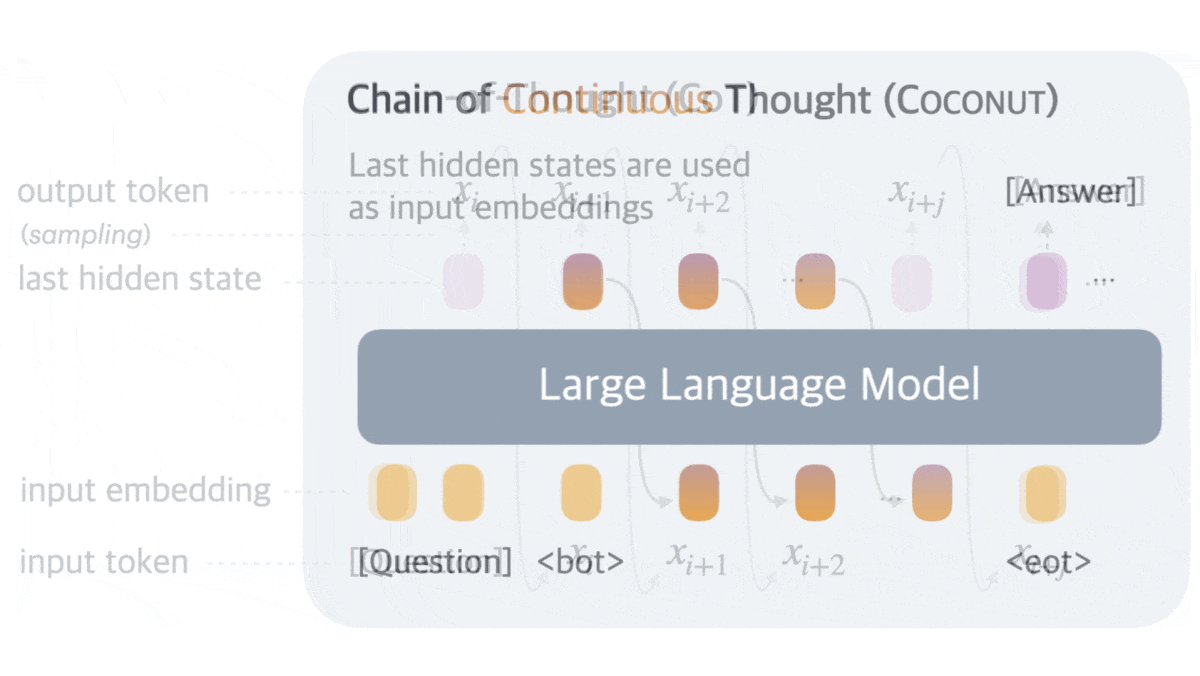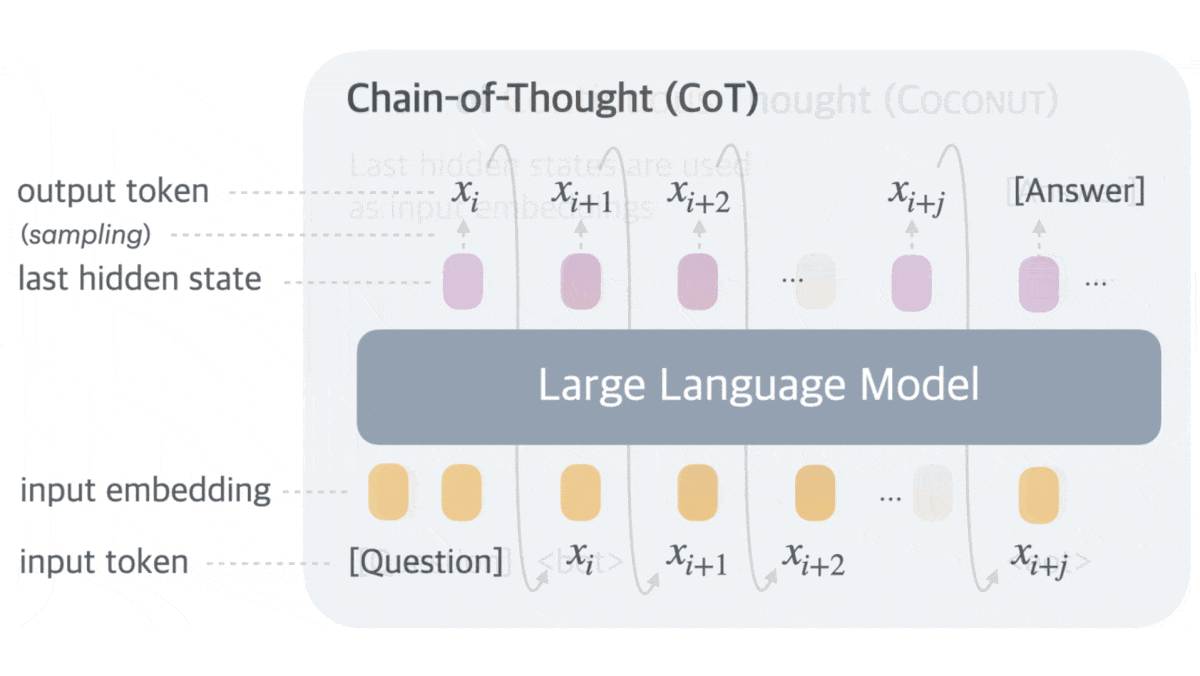
What’s new: Shibo Hao, Sainbayar Sukhbaatar, and colleagues at Meta and University of California San Diego introduced Coconut (Chain of Continuous Thought), a method that trains large language models (LLMs) to process chains of thought as vectors rather than words.
Key insight: A large language model (LLM) can be broken into an embedding layer, transformer, and classification layer. To generate the next text token from input text, the embedding layer embeds the text; given the text, the transformer outputs a hidden vector; and the classification layer maps the vector to text-token probabilities. Based on these probabilities, a decoding algorithm selects the next token to generate, which feeds back into the input text sequence to generate the next vector, and so on. When a model generates a CoT, committing to a specific word at each step limits the information available to the meanings of the words generated so far, while a vector could represent multiple possible words. Using vectors instead of text enables the CoT to encode richer information.
How it works: The authors built three LLMs by fine-tuning a pre-trained GPT-2 on three datasets of prompts, CoTs, and final outputs: GSM8k (grade-school math word problems); ProntoQA (questions and answers about fictional concepts expressed in made-up words, including synthetic CoTs in natural language); and (3) ProsQA, a more challenging question-answering dataset introduced by the authors, inspired by ProntoQA but with longer reasoning steps.
- Fine-tuning began with supervised training. The LLM learned to generate the text in the training set, including the CoT and final answers. As usual, the last-generated text token was fed back as input to produce the next token.
- Fine-tuning then progressed through k stages for each example. At each stage, the authors replaced a sentence in the CoT text with a thought vector (or two) to build a sequence of k replaced sentences. The start and end of the chain of thought vectors were marked by two special tokens. During vector steps, the LLM fed its output vectors back as input without decoding them into text. The LLM learned to generate only the remaining text tokens, not the thought vectors, which encouraged it to optimize its vector-based reasoning indirectly.
- During inference, the LLM generated a special token to mark the start of the chain of vectors. From this point, it fed back its output vectors, bypassing text decoding for six steps. Afterward, the LLM switched back to generating text for final output.
Results: The authors compared their method to a pretrained GPT-2 that was fine-tuned on the same datasets to predict the next word, including reasoning.
- On ProntoQA, Coconut outperformed the fine-tuned GPT-2 while producing far fewer interim vectors (Coconut) or tokens (baseline LLMs). It achieved 99.8 percent accuracy after generating nine vectors (or tokens) on average, while GPT-2 achieved 98.8 percent accuracy using 92.5 text tokens.
- Coconut excelled on ProsQA’s more complex questions. It achieved 97.0 percent accuracy after generating 14.2 vectors (or tokens) on average, while GPT-2 achieved 77.5 percent accuracy after generating 49.4 text tokens on average.
Yes, but: On GSM8k, Coconut achieved 34.1 percent accuracy, while the baseline LLM achieved 42.9 percent. However, it generated significantly fewer vectors and tokens than the CoT generated tokens. Coconut generated 8.2 vectors on average compared to the baseline LLM’s 25 text tokens.
Why it matters: A traditional CoT commits to a single word at each step and thus encodes one reasoning path in a single CoT. Vectors are less interpretable to humans than language, but the model’s output layer can still decode the thought vectors into probabilities over tokens. Further, inspecting the distribution of words stored along all continuous CoT vectors offers a way to understand multiple potential thought paths stored in one continuous CoT.
We’re thinking: LLMs typically learn to reason over text, mainly because text data is widely available to train on. In contrast, neuroscience shows that the part of the human brain responsible for language largely goes quiet during reasoning tasks, which suggests that explicit language is not a key mechanism for reasoning. Coconut takes an intriguing step to enable LLMs to explore representations that don’t encode the limitations of language.