
Dear friends,
Continuing our discussion on the Voice Stack, I’d like to explore an area that today’s voice-based systems mostly struggle with: Voice Activity Detection (VAD) and the turn-taking paradigm of communication.
When communicating with a text-based chatbot, the turns are clear: You write something, then the bot does, then you do, and so on. The success of text-based chatbots with clear turn-taking has influenced the design of voice-based bots, most of which also use the turn-taking paradigm.
A key part of building such a system is a VAD component to detect when the user is talking. This allows our software to take the parts of the audio stream in which the user is saying something and pass that to the model for the user’s turn. It also supports interruption in a limited way, whereby if a user insistently interrupts the AI system while it is talking, eventually the VAD system will realize the user is talking, shut off the AI’s output, and let the user take a turn. This works reasonably well in quiet environments.
However, VAD systems today struggle with noisy environments, particularly when the background noise is from other human speech. For example, if you are in a noisy cafe speaking with a voice chatbot, VAD — which is usually trained to detect human speech — tends to be inaccurate at figuring out when you, or someone else, is talking. (In comparison, it works much better if you are in a noisy vehicle, since the background noise is more clearly not human speech.) It might think you are interrupting when it was merely someone in the background speaking, or fail to recognize that you’ve stopped talking. This is why today’s speech applications often struggle in noisy environments.
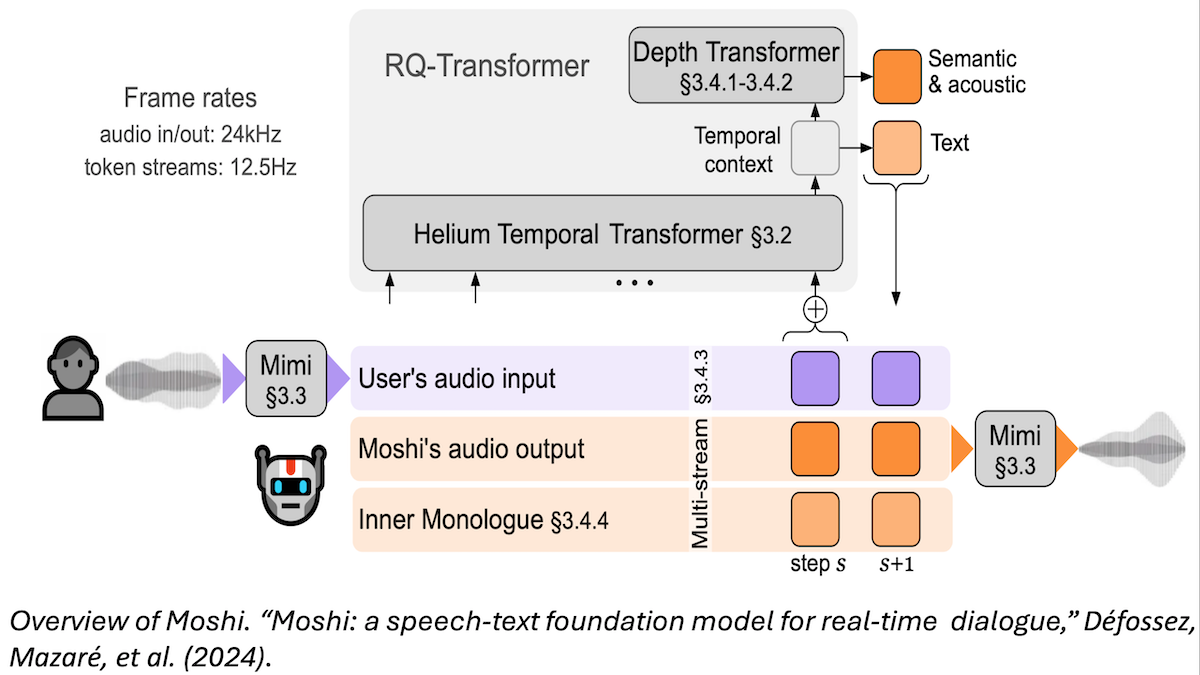
Intriguingly, last year, Kyutai Labs published Moshi, a model (GitHub) that had many technical innovations. An important one was enabling persistent bi-direction audio streams from the user to Moshi and from Moshi to the user.
If you and I were speaking in person or on the phone, we would constantly be streaming audio to each other (through the air or the phone system), and we’d use social cues to know when to listen and how to politely interrupt if one of us felt the need. Thus, the streams would not need to explicitly model turn-taking. Moshi works like this. It’s listening all the time, and it’s up to the model to decide when to stay silent and when to talk. This means an explicit VAD step is no longer necessary. (Moshi also included other innovations, such as an “inner monologue” that simultaneously generates text alongside the audio to improve the quality of responses as well as audio encoding.)
Just as the architecture of text-only transformers has gone through many evolutions (such as encoder-decoder models, decoder-only models, and reasoning models that generate a lot of “reasoning tokens” before the final output), voice models are going through a lot of architecture explorations. Given the importance of foundation models with voice-in and voice-out capabilities, many large companies right now are investing in developing better voice models. I’m confident we’ll see many more good voice models released this year.
It feels like the space of potential innovation for voice remains large. Hard technical problems, like the one of latency that I described last week and VAD errors, remain to be solved. As solutions get better, voice-to-voice will continue to be a promising category to build applications in.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Learn to build an event-driven AI agent that processes documents and fills out forms using RAG, workflows, and human-in-the-loop feedback. This course, built in partnership with LlamaIndex, walks you through designing, building, and refining automated document workflows. Enroll for free
News
Text Generation by Diffusion
Typical large language models are autoregressive, predicting the next token, one at a time, from left to right. A new model hones all text tokens at once.
What’s new: Inception Labs, a Silicon Valley startup, emerged from stealth mode with Mercury Coder, a diffusion model that generates code, in small and mini versions. Registered users can try it out here, and an API (sign up for early access here) and on-premises deployments are in the works. The company has not yet announced availability and pricing.
How it works: Like image diffusion models, Mercury Coder improves its output over a number of steps by removing noise.
- Inception Labs shared little information about the model, leaving details including parameter count, input size and output size, training data, and training methods undisclosed.
- An October 2023 paper co-authored by an Inception Labs co-founder describes training a text diffusion model using score entropy. The model learned to estimate the transition ratio between two tokens; that is, the probability that token y is correct over the probability that the current token x is correct.
- In their most successful experiments, the authors added noise to tokens by progressively masking an ever-greater percentage of tokens at random over several steps.
- At inference, the model started with masked tokens and unmasked them over a number of steps. The estimated transition ratio determined how to change each token at each step.
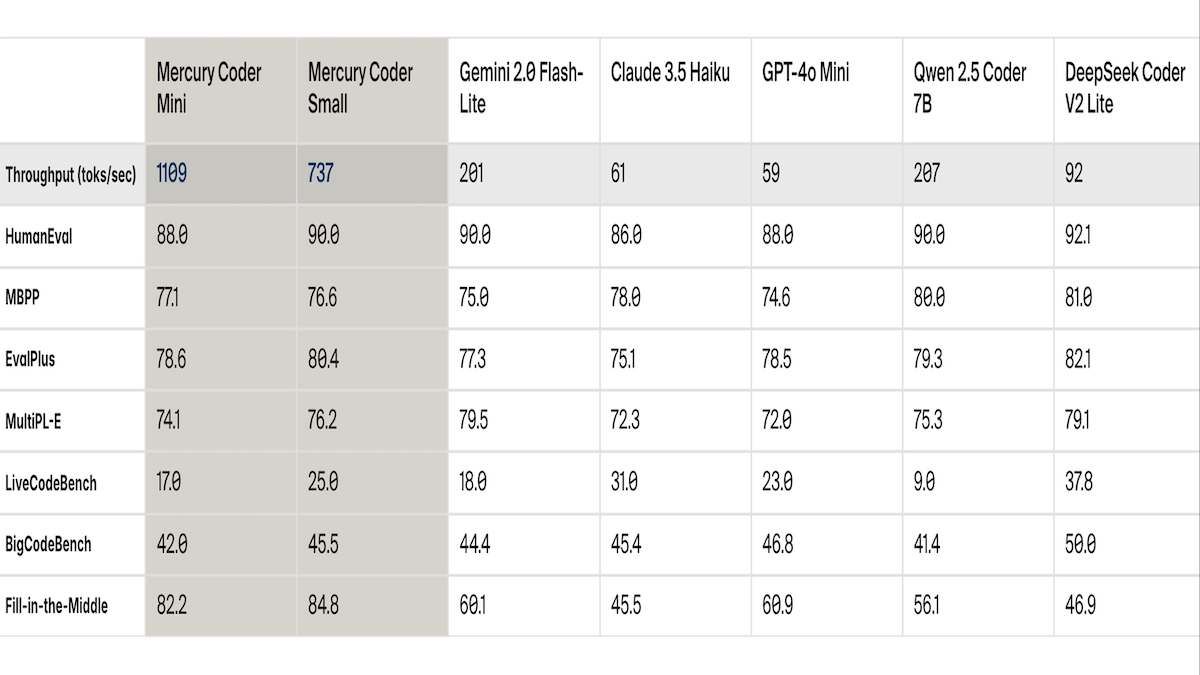
Results: Mercury Coder’s major advantage is speed, but it also performs well compared to several competitors.
- The Small and Mini versions are 3.5 to 18 times faster than comparable small coding models. Running on an Nvidia H100 graphics processing unit, Mercury Coder Small generates 737 tokens per second and Mercury Coder Mini generates 1,109 tokens per second. In comparison, Qwen 2.5 Coder 7B generates 207 tokens per second and GPT 4o-Mini generates 59 tokens per second.
- On coding tasks across six benchmarks, Mercury Coder Small outperforms Gemini 2.0 Flash-Lite, Claude 3.5 Haiku, GPT-4o Mini, and Qwen 2.5 Coder 7B on at least four. Mercury Coder Mini beats those models on at least two. Both versions of Mercury Coder lost to DeepSeek Coder V2 Lite on all six benchmarks.
Behind the news: Several teams have built diffusion models that generate text, but previous efforts have not been competitive with autoregressive large language models (LLMs). Recently, LLaDA showed comparable performance to Meta’s Llama 2 7B but fell short of Llama 3 8B and other similarly sized modern LLMs.
Why it matters: Text diffusion models are already faster than autoregressive models. They offer significant promise to accelerate text generation even further.
We’re thinking: Diffusion image generators have delivered good output with as little as four or even one step, generating output tokens significantly faster than autoregressive models. If text diffusion models can benefit from improvements in image generation, they could lead to rapid generation of lengthy texts and, in turn, faster agents and reasoning.
OpenAI’s GPT-4.5 Goes Big
OpenAI launched GPT-4.5, which may be its last non-reasoning model.
What’s new: GPT-4.5 is available as a research preview. Unlike OpenAI’s recent models o1 and o3, GPT-4.5 is not fine-tuned to reason by generating a chain of thought, although the company hinted that it may serve as a basis of a reasoning model in the future. Instead, it’s a huge model that was trained using a huge amount of computation. As OpenAI’s biggest model to date, GPT-4.5 is very expensive to run, and the company is evaluating whether to offer it via API in the long term.
- Input/output: text and images in, text out. Voice and video interactions may be available in future updates.
- Availability/price: Via ChatGPT (currently ChatGPT Pro; soon ChatGPT Plus, Team, Enterprise, and Edu) and various APIs (Chat Completions, Assistants, and Batch). $75/$150 per million input/output tokens.
- Features: Web search, function calling, structured output, streaming, system messages, canvas collaborative user interface.
- Undisclosed: Parameter count, input and output size, architecture, training data, training methods.
How it works: OpenAI revealed few details about how GPT-4.5 was built. The model is bigger than GPT-4o, and it was pretrained and fine-tuned on more data using more computation — possibly 10x more, given OpenAI’s comment that “with every new order of magnitude of compute comes novel capabilities.”
- The model was trained on a combination of publicly available data and data from partnerships and in-house datasets, including data generated by smaller models. Its knowledge cutoff is October 2023.
- The data was filtered for quality, to eliminate personally identifying information, and to eliminate information that might contribute to proliferation of chemical, biological, radiological, and nuclear threats.
- OpenAI developed unspecified techniques to scale up unsupervised pretraining, supervised fine-tuning, and alignment.
Performance: “This isn’t a reasoning model and won’t crush benchmarks,” OpenAI CEO Sam Altman warned in a tweet. The company claims that GPT-4.5 offers improved general knowledge, adheres to prompts with more nuance, delivers greater creativity, and has higher emotional intelligence.
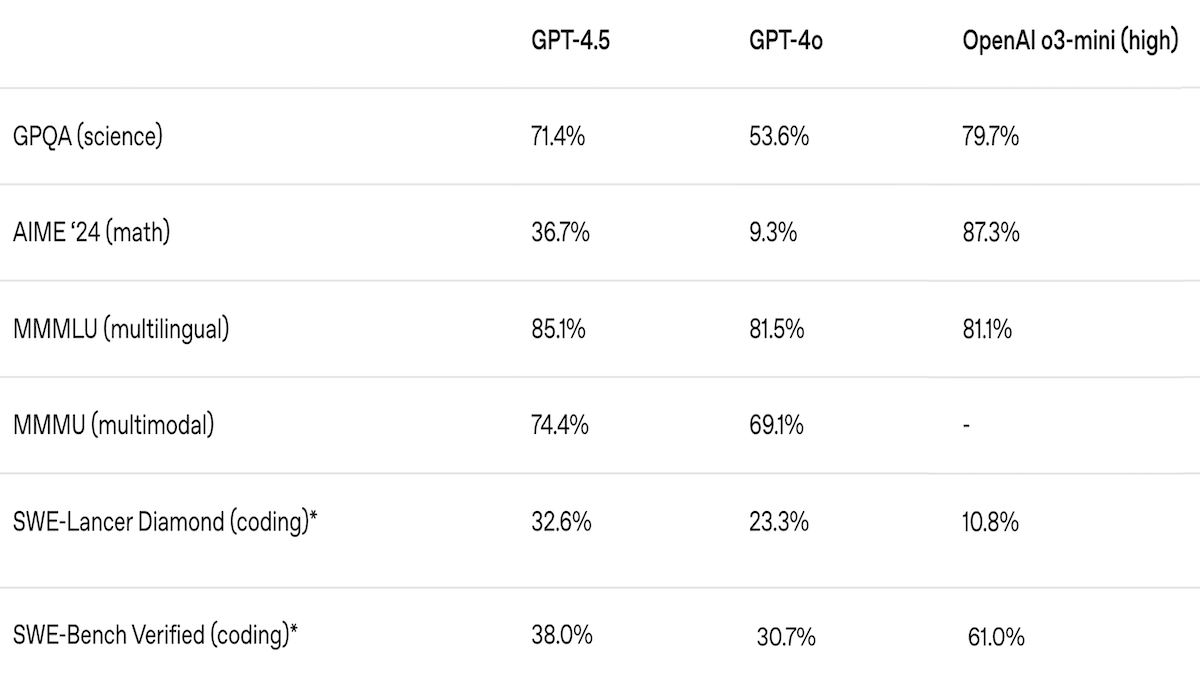
- GPT-4.5 shows less propensity to hallucinate, or confabulate information, than other OpenAI models. On PersonQA (questions that involve publicly available facts about people), GPT-4.5 achieved 78 percent accuracy compared to GPT-4o (28 percent accuracy) and o1 (55 percent accuracy). Moreover, GPT-4.5 achieved a hallucination rate (lower is better) of 0.19 compared to GPT-4o (0.52) and o1 (0.20).
- Its performance on coding benchmarks is mixed. On SWE-Bench Verified, GPT-4.5 achieved a 38 percent pass rate, higher than GPT-4o (30.7 percent) but well below deep research (61 percent), an agentic workflow that conducts multi-step research on the internet. On SWE-Lancer Diamond, which evaluates full-stack software engineering tasks, GPT-4.5 solved 32.6 percent of tasks, outperforming GPT-4o (23.3 percent) and o3-mini (10.8 percent) but again lagging deep research (around 48 percent).
Behind the news: GPT-4.5’s release comes as OpenAI nears an announced transition away from developing separate general-knowledge and reasoning models. The launch also comes as OpenAI faces an ongoing shortage of processing power. CEO Sam Altman said that the company is “out of GPUs” and struggling to meet demand — a constraint that may impact whether OpenAI continues to offer GPT-4.5 via API.
Why it matters: GPT-4.5 highlights a growing divide in AI research over whether to pursue performance gains by scaling up processing during pretraining or inference. Despite the success of approaches that consume extra processing power at inference, such as agentic techniques and reasoning models such as its own o family, OpenAI clearly still sees value in pretraining larger and larger models.
We’re thinking: There’s still more juice to be squeezed out of bigger models! We’re excited to see what the combination of additional compute applied to both pretraining and inference can achieve.
Budget for Reasoning to the Token
Anthropic’s Claude 3.7 Sonnet implements a hybrid reasoning approach that lets users decide how much thinking they want the model to do before it renders a response.
What’s new: Claude 3.7 Sonnet was trained for strong performance in coding and front-end web development, with less emphasis on math and computer-science competition problems. It implements tool use and computer use (but not web search) and lets users toggle between immediate responses and extended thinking mode, which can improve outputs by allocating a specific number of tokens to reasoning at inference. Like DeepSeek-R1 and Google Gemini Flash Thinking — and unlike OpenAI o1 — Claude 3.7 Sonnet fully displays reasoning tokens. Anthropic considers this functionality experimental, so it may change.
- Input/output: text and images in (up to 200,000 tokens), text out (up to 128,000 tokens).
- Availability/price: Via Anthropic tiers Free (extended thinking not available), Pro, Team, and Enterprise; Anthropic API; Amazon Bedrock; Google Cloud Vertex AI. $3/$15/$15 per million input/output/thinking tokens.
- Undisclosed: parameter count, architecture, training data, training method.
- Anthropic also introduced Claude Code, a command-line tool for AI-assisted coding, which is available as a limited research preview. Claude Code can edit files, write and run tests, commit and push code to GitHub, and use command-line tools.
How it works: Anthropic pretrained Claude 3.7 Sonnet on a mix of public and proprietary data (which explicitly did not include Claude users’ inputs and outputs). The team fine-tuned Claude 3.7 Sonnet using constitutional AI, which encourages a model to follow a set of human-crafted rules.
- When the model’s extended thinking mode is enabled, API users can control the thinking budget by specifying a number of tokens up to 128,000. (The specified budget is a rough target, so the number of tokens consumed may differ.)
- Anthropic says that extended thinking mode often is more effective given a general instruction to “think deeply” rather than step-by-step instructions.
- Visible thinking tokens are considered a research preview while Anthropic examines how they affect user interactions with the model. The company highlights three issues: Visible thinking tokens don’t reflect the model’s internal instructions that establish its character and therefore seem to be devoid of personality, they may not reflect the model’s actual reasoning process, and they can reveal flaws that malicious actors may exploit.
- Extended thinking mode processes tokens serially, but Anthropic is experimenting with parallel thinking that follows multiple independent thought processes and chooses the best one according to a majority vote.
Performance: Claude 3.7 Sonnet shows exceptional performance in general knowledge, software engineering, and agentic tasks.
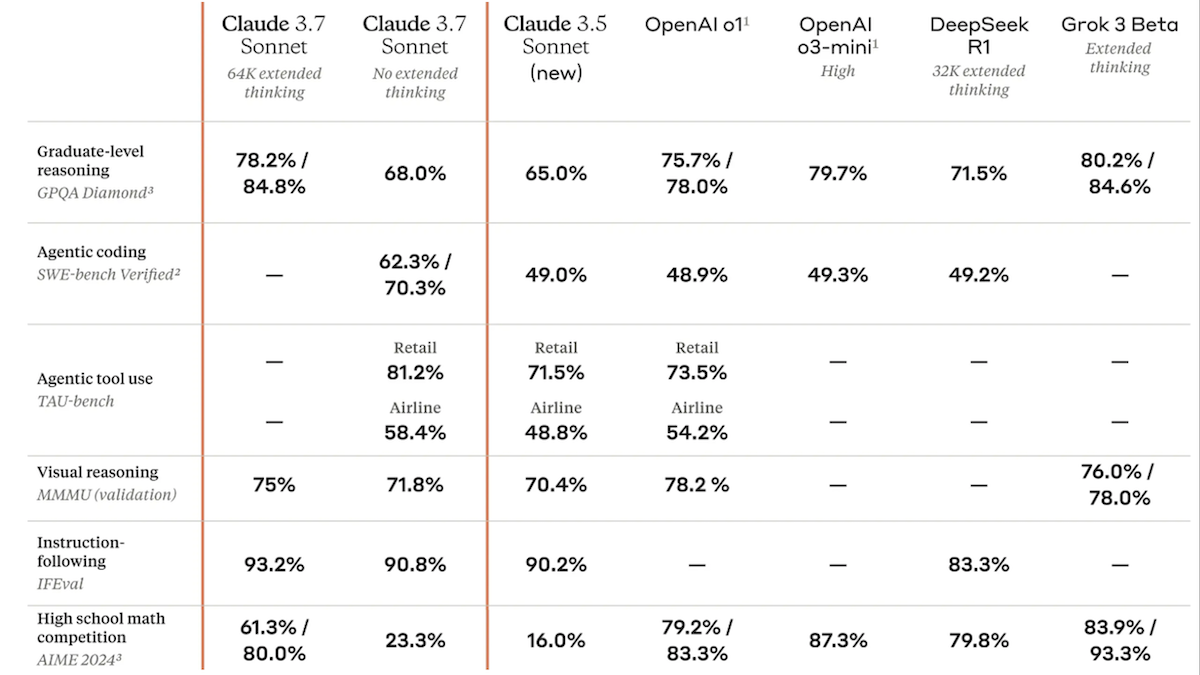
- On the GPQA Diamond (graduate-level science questions), Claude 3.7 Sonnet achieved 84.8 percent in parallel extended thinking mode with a 64,000-token budget. By comparison, X’s Grok 3 beta achieved 84.6 percent (majority voting with 64 tries), and OpenAI’s o3-mini achieved 79.7 percent with high effort.
- On SWE-Bench Verified, which evaluates the ability to solve real-world software engineering problems, Claude 3.7 Sonnet achieved 70.3 percent without extended thinking, averaged over 16 trials. OpenAI’s o3-mini achieved 49.3 percent with high effort, and DeepSeek R1 achieved 49.2 percent with extended thinking, 32,000 tokens.
- τ-bench evaluates agentic reasoning. On the Retail subset, which assesses performance in product recommendations and customer service, Claude 3.7 Sonnet achieved 81.2 percent without extended thinking, outperforming OpenAI’s o1 (73.5 percent). In the Airline subset, which measures multi-step reasoning in tasks like flight bookings and customer support, Claude 3.7 Sonnet achieved 58.4 percent, likewise ahead of o1 (54.2 percent).
- On AIME 2024, competitive high-school math problems, Claude 3.7 Sonnet achieved 80.0 percent in parallel extended thinking mode with a 64,000-token budget. In this test, it underperformed o3-mini with high effort (87.3 percent) and o1 (83.3 percent).
Behind the news: Anthropic’s approach refines earlier efforts to enable users to control the incremental expense of computing extra tokens at inference. For instance, OpenAI o1 offers three levels of reasoning or “effort” — each of which allocates more tokens to reasoning — while X’s Grok 3 offers two.
Why it matters: Test-time compute, or additional processing at inference, is powerful but expensive, and not all tasks benefit from it. So it’s helpful to let users choose how much to apply. Claude 3.7 Sonnet improves its predecessor’s general performance and provides an ample budget for additional reasoning.
We’re thinking: The cost of inference is rising as agentic workflows and other compute-intensive tasks become more widely used. Yet the cost of AI on a per-token basis is falling rapidly. Intelligence is becoming steadily cheaper and more plentiful.
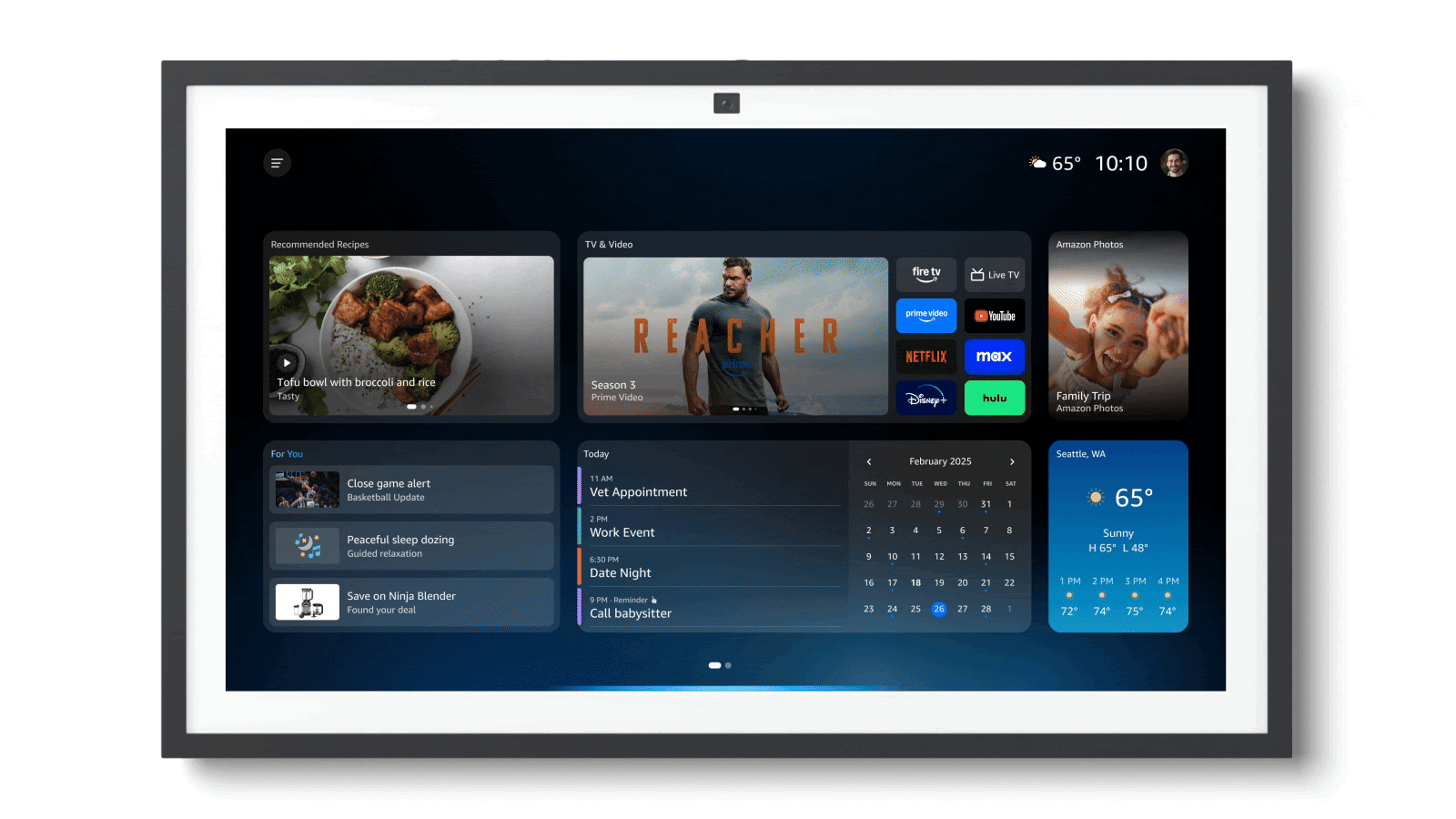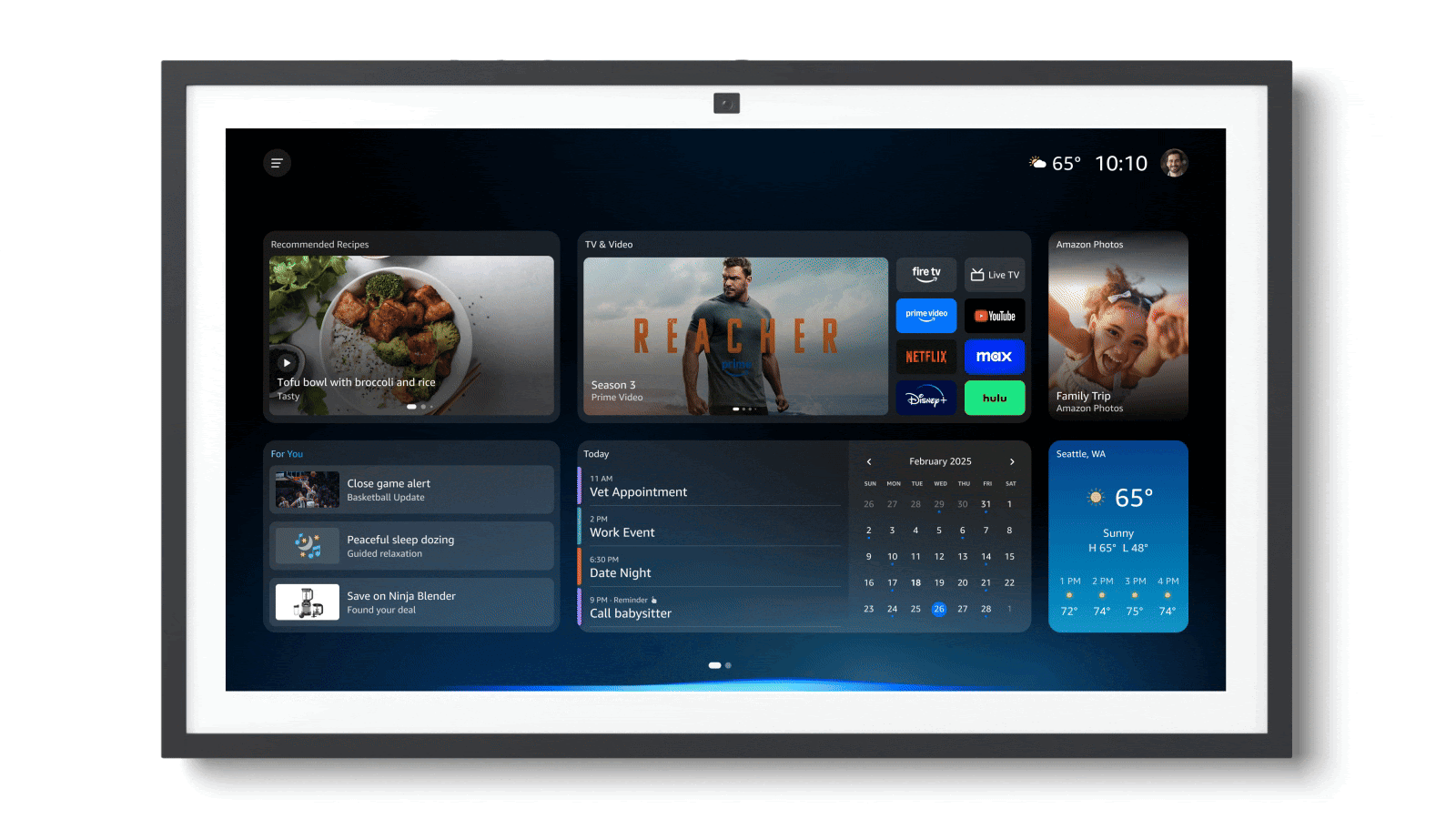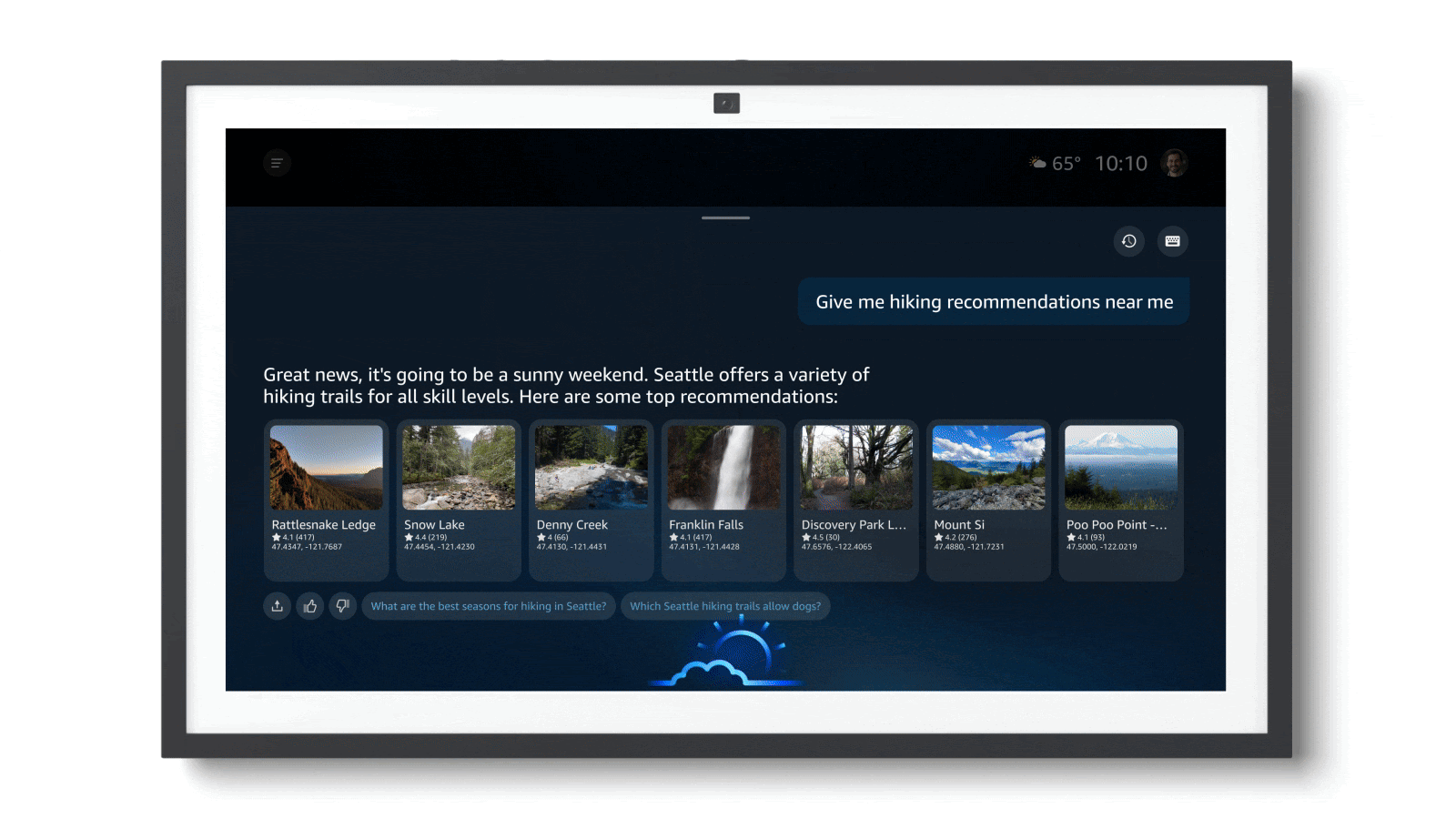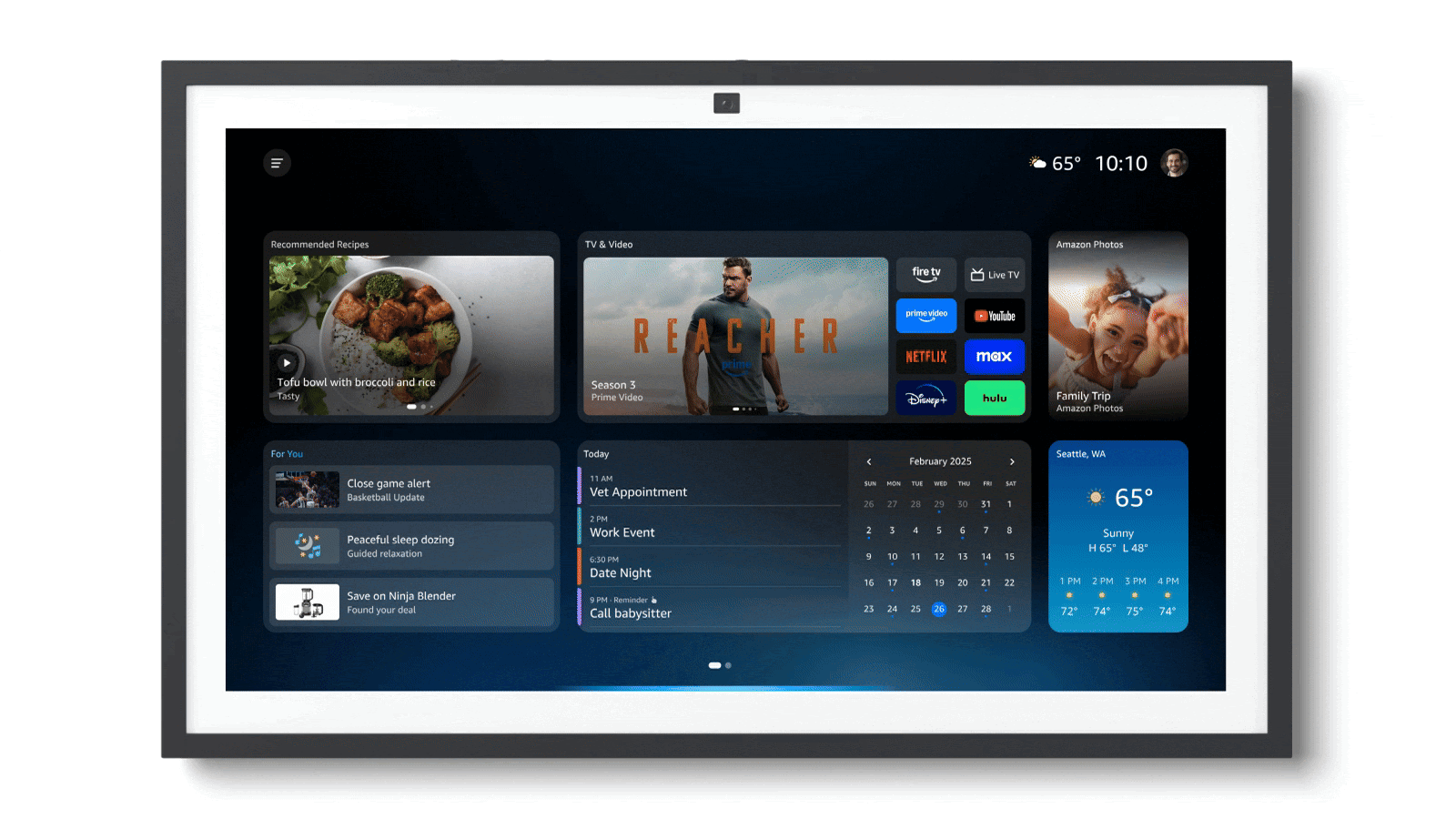
Amazon’s Next-Gen Voice Assistant
Amazon announced Alexa+, a major upgrade to its long-running voice assistant.
What’s new: Alexa+, which accepts spoken commands and responds conversationally, is designed to work with a variety of vendors as an autonomous agent to make purchases, book reservations, play media, and so on. It will roll out in the U.S. over coming weeks, initially on some Echo Show devices and eventually nearly every current Echo speaker.
How it works: Alexa+ updates the system to take advantage of generative AI including Anthropic Claude, Amazon Nova, and other large language models. Inputs are filtered through a routing system that determines the best model to respond to any given request. It’s trained to understand colloquial, conversational language. Its personality is designed to be “smart, considerate, empathetic, and inclusive” as well as humorous.
- Alexa+ interacts with online vendors to manage smart-home devices (Philips Hue, Ring, Roborock), reserve restaurant seats (OpenTable, Vagaro), play music (Amazon Music, Spotify, Apple Music, iHeartRadio) and videos (Amazon Video, Hulu, Netflix, Disney+), book local service technicians (Thumbtack), and purchase items (Amazon Fresh, Whole Foods, Grubhub, Uber Eats, Ticketmaster). Amazon+ will cost $19.99 per month, free with an Amazon Prime membership ($139 per year). (Disclosure: Andrew Ng is a member of Amazon’s board of directors.)
- The system recognizes individual users and keeps track of personalized information such as dates; recipes, and preferences in sports, food, music, and movies. In addition, it can respond to queries based on purchase records, video and music playbacks, shipping addresses, documents, emails, photos, messages, and so on.
- It can behave proactively, for instance, advising users to start their commute early if traffic is heavy.
- The system calls what Amazon calls experts — groups of systems, APIs, and instructions — that orchestrate API calls to accomplish online tasks. For instance, it can navigate and use the web to perform tasks such as finding and booking, say, a local repair service to fix a broken household appliance.
- Alexa+ can deliver timely news and information based on partnerships with news sources including Associated Press, Business Insider, Politico, Reuters, USA Today, and The Washington Post.
Behind the news: Amazon launched Alexa in 2014, and the voice assistant now resides in over 600 million devices worldwide. However, users relied on it more to set timers, report sports scores, and play music than to purchase products, and Alexa revenue lagged. Following cutbacks in 2021, Amazon made multibillion-dollar investments in Anthropic and set about updating the technology for the generative AI era.
Why it matters: Alexa, along with Apple’s Siri and Google Assistant, pioneered the market for voice assistants. However, as large language models (LLMs) blossomed, all three systems fell behind the times. (Google allows Android users to substitute one of its Gemini LLMs for Google Assistant, but the system still calls Google Assistant for some tasks.) Alexa+ is the first major voice-assistant update that aims to take advantage of LLMs as well as emerging agentic technology and improved voice interactions, and the rollout is taking these capabilities to a large, existing user base.
We’re thinking: Rapid improvements in the voice stack are opening doors not only for voice assistants but for a galaxy of applications that rely on spoken input and output. Product designers will need to learn how to design smooth user voice experiences. Watching how Alexa+ manages them will provide useful guidelines.