
Dear friends,
Contrary to standard prompting advice that you should give LLMs the context they need to succeed, I find it’s sometimes faster to be lazy and dash off a quick, imprecise prompt and see what happens. The key to whether this is a good idea is whether you can quickly assess the output quality, so you can decide whether to provide more context. In this post, I’d like to share when and how I use “lazy prompting.”
When debugging code, many developers copy-paste error messages — sometimes pages of them — into an LLM without further instructions. Most LLMs are smart enough to figure out that you want them to help understand and propose fixes, so you don’t need to explicitly tell them. With brief instructions like “Edit this: …” or “sample dotenv code” (to remind you how to write code to use Python's dotenv package), an LLM will often generate a good response. Further, if the response is flawed, hopefully you can spot any problems and refine the prompt, for example to steer how the LLM edits your text.
At the other end of the spectrum, sometimes I spend 30 minutes carefully writing a 2-page prompt to get an AI system to help me solve a problem (for example to write many pages of code) that otherwise would have taken me much longer.
I don’t try a lazy prompt if (i) I feel confident there’s no chance the LLM will provide a good solution without additional context. For example, given a partial program spec, does even a skilled human developer have a chance of understanding what you want? If I absolutely want to use a particular piece of pdf-to-text conversion software (like my team LandingAI’s Agentic Doc Extraction!), I should say so in the prompt, since otherwise it’s very hard for the LLM to guess my preference. I also wouldn’t use a lazy prompt if (ii) a buggy implementation would take a long time to detect. For example, if the only way for me to figure out if the output is incorrect is to laboriously run the code to check its functionality, it would be better to spend the time up-front to give context that would increase the odds of the LLM generating what I want.

By the way, lazy prompting is an advanced technique. On average, I see more people giving too little context to LLMs than too much. Laziness is a good technique only when you’ve learned how to provide enough context, and then deliberately step back to see how little context you can get away with and still have it work. Also, lazy prompting applies only when you can iterate quickly using an LLM’s web or app interface It doesn’t apply to prompts written in code for the purpose of repeatedly calling an API, since presumably you won’t be examining every output to clarify and iterate if the output is poor.
Thank you to Rohit Prsad, who has been collaborating with me on the open-source package aisuite, for suggesting the term lazy prompting. There is an analogy to lazy evaluation in computer science, where you call a function at the latest possible moment and only when a specific result is needed. In lazy prompting, we add details to the prompt only when they are needed.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

In our latest course, “Getting Structured LLM Output,” you’ll learn to generate consistent, machine-readable outputs from LLMs using structured output APIs, re-prompting libraries, and token-level constraints. You’ll build a social media analysis agent that extracts sentiment and creates structured JSON ready for downstream use. Enroll for free
News
Interactive Voice-to-Voice With Vision
Researchers updated the highly responsive Moshi voice-to-voice model to discuss visual input.
What’s new: Amélie Royer, Moritz Böhle, and colleagues at Kyutai proposed MoshiVis. The weights are free to download under the CC-BY 4.0 license, which permits commercial and noncommercial uses. You can hear examples of its output and chat with a demo.
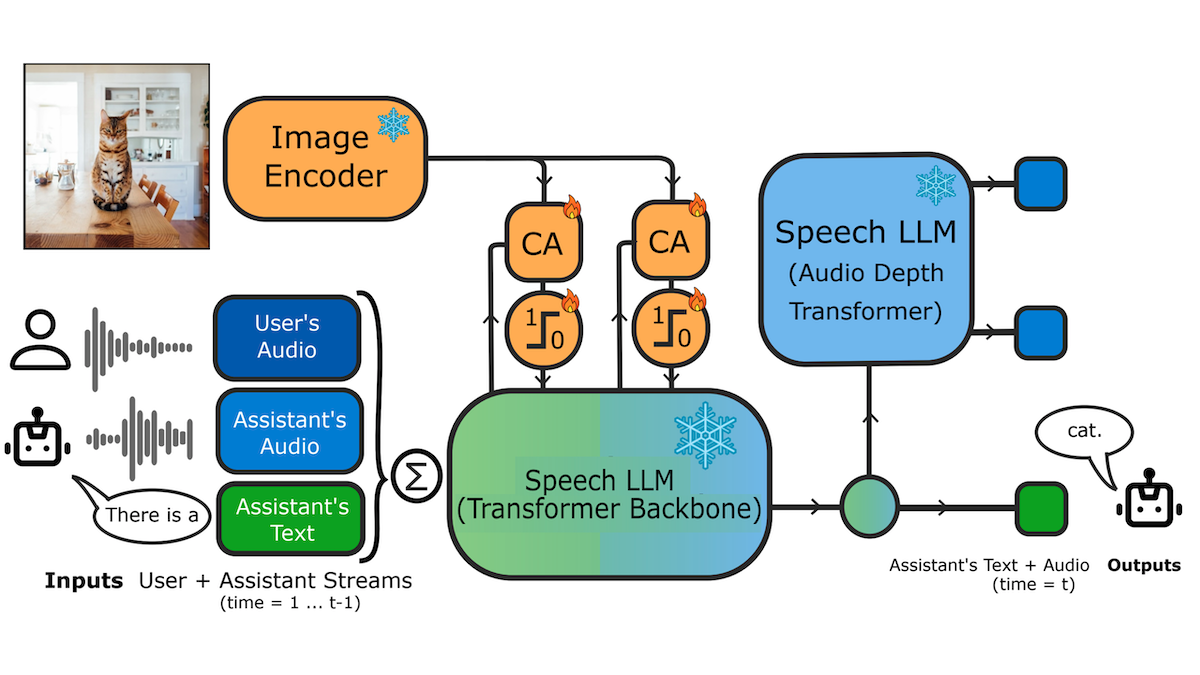
Key insight: The original Moshi, which manages overlapping voice-to-voice conversations, comprises two transformers. The first outputs a text transcription of its speech, and the second outputs speech. Since Moshi generates text as well as speech, the authors of that work fine-tuned it to predict the next token of text. In MoshiVis, the addition of a vision encoder enabled the authors to fine-tune on not only image-text datasets but also image-speech datasets, which are not so plentiful. Fine-tuning on this wider variety of images enabled the system to understand images better than fine-tuning it solely on image-speech datasets.
How it works: To Moshi, the authors added a model based on a pretrained SigLIP vision encoder to encode images, a cross-attention adapter to fuse image information with speech tokens, and vanilla neural networks trained to act as gates that determine how much image information to fuse. Specifically, the authors added the adapter and a gate between Moshi’s existing self-attention and fully connected layers.
- The authors fine-tuned MoshiVis on seven datasets. For instance, they produced a vision-speech-to-speech dataset by prompting two Mistral NeMo models to talk about an image from initial descriptions of images in the image-text datasets PixMo and DOCCI, then using a custom text-to-speech model to convert the text into speech. Another example: They used OCR-VQA, an image-text dataset for answering questions about images (no speech data involved).
- They fine-tuned MoshiVis to predict the next token of speech or text in their datasets, training only the newly added adapter and gates while keeping SigLIP and the two Moshi transformers frozen.
Results: MoshiVis is highly responsive in conversation with latency of roughly 50 milliseconds on a Mac Mini.
- Qualitatively, it handles transitions smoothly between talking about images and general conversation. However, it sounds more robotic than other recent voice generators.
- Quantitatively, the authors compared MoshiVis to the vision-language model PaliGemma fine-tuned to answer questions about images. Overall, MoshiVis prompted with audio (and images) performed less accurately than PaliGemma prompted with text (and images). For example, on OCR-VQA, MoshiVis achieved roughly 65 percent accuracy while PaliGemma achieved roughly 71 percent accuracy.
Behind the news: MoshiVis complements a small but growing roster of systems that combine vision with speech-to-speech. ChatGPT accepts and generates speech in response to camera views or a user’s phone screen. AnyGPT (open weights training and inference code) accepts or generates speech, text, images, and music. Similarly, Mini-Omni2 (open weights and inference code) accepts and generates text, speech, and images. The authors didn’t compare MoshiVis to these alternatives.
Why it matters: MoshiVis easily adapts a speech-to-speech model to work with a new type of media input. MoshiVis requires training only the adapters, while the earlier AnyGPT and Mini-Omni2, which can also discuss images via voice input and output, require training both adapters and the main model.
We’re thinking: Text-chat models respond appropriately when a user refers to a previous topic or something new, and MoshiVis does, too, in spoken interactions. Evaluations of this capability will become increasingly important as voice-to-voice becomes more widespread.
Scraping the Web? Beware the Maze
Bots that scrape websites for AI training data often ignore do-not-crawl requests. Now web publishers can enforce such appeals by luring scrapers to AI-generated decoy pages.
What’s new: Cloudflare launched AI Labyrinth, a bot-management tool that serves fake pages to unwanted bots, wasting their computational resources and making them easier to detect. It’s currently free to Cloudflare users.
How it works: AI Labyrinth protects webpages by embedding them with hidden links to AI-generated alternatives that appear legitimate to bots but are irrelevant to the protected site.
- An unidentified open-source model that runs on Cloudflare’s Workers AI platform generates factual, science-related HTML pages on diverse topics. A pre-generation pipeline sanitizes the pages of XSS vulnerabilities before storing them in Cloudflare’s R2 storage platform.
- A custom process embeds links to decoy pages within a site’s HTML. Meta instructions hide these links from search engine indexers and other authorized crawlers, while other attributes and styling hide the decoy links from human visitors.
- When an unauthorized bot follows one of these links, it crawls through layers of irrelevant content.
- Cloudflare logs these interactions and uses the data to fingerprint culprit bots and improve its bot-detection models.
Behind the news: The robots.txt instructions that tell web crawlers which pages they can access aren’t legally binding, and web crawlers can disregard them. However, online publishers are moving to try to stop AI developers from training models on their content. Cloudflare, as the proxy server and content delivery network for nearly 20 percent of websites, plays a potentially large role in this movement. AI crawlers account for nearly 1 percent of web requests on Cloudflare’s network, the company says.
Why it matters: The latest AI models are trained on huge quantities of data gleaned from the web, which enables them to perform well enough to be widely useful. However, publishers increasingly aim to limit access to this data. AI Labyrinth gives them a new tool that raises the cost for bots that disregard instructions not to scrape web content.
We’re thinking: If AI Labyrinth gains traction, no doubt some teams that build crawlers will respond with their own AI models to sniff out its decoy pages. To the extent that the interest between crawlers and publishers is misaligned and clear, enforceable rules for crawling are lacking, this cat-and-mouse competition could go on for a long time.
Chatbot Use Creates Emotional Bonds
A pair of papers investigate how increasingly human-like chatbots affect users’ emotions.
What’s new: Jason Phang at OpenAI, Cathy Mengying Fang at MIT Media Lab, and colleagues at those organizations published complementary studies that examine ChatGPT’s influence on loneliness, social interactions, emotional dependence, and potentially problematic use.
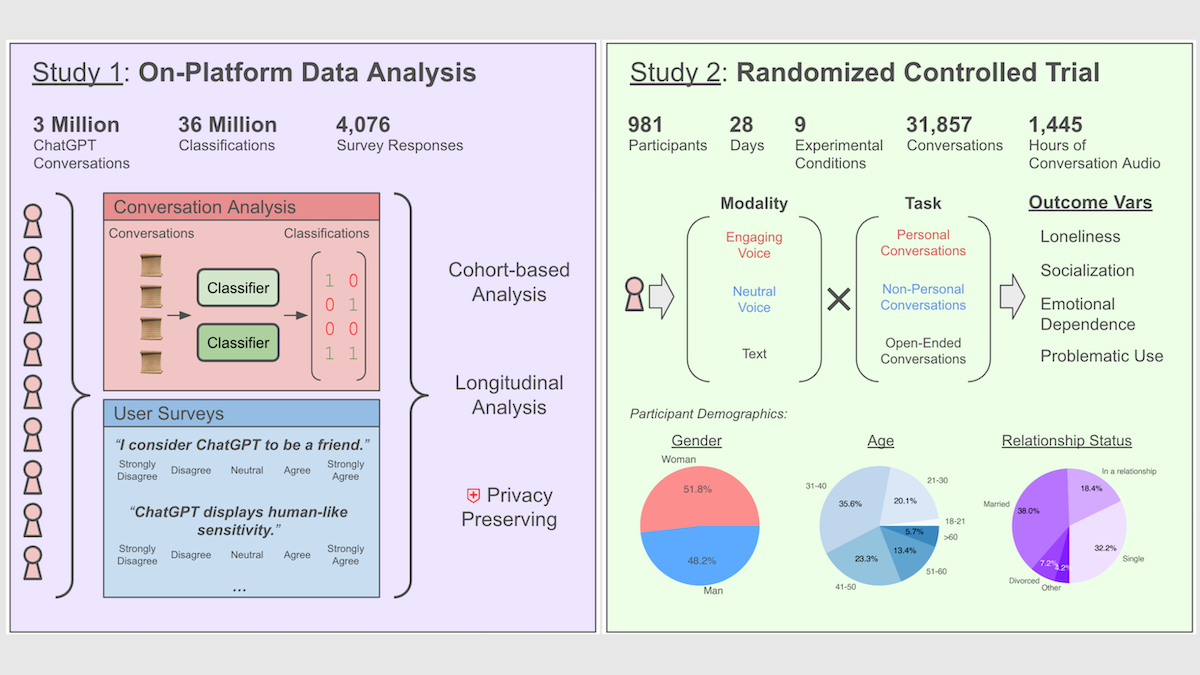
How it works: One study was a large-scale analysis of real-world conversations, and the other was a randomized control trial that tracked conversations of a selected cohort. Both evaluated conversations according to EmoClassifiersV1, a set of classifiers based on large language models that evaluate five top-level emotional classes (loneliness, dependence, and the like) and 20 sub-classes of emotional indicators (seeking support, use of pet names, and so on).
- The analysis of real-world conversations considered roughly 3 million English-language voice conversations by 6,000 heavy users of ChatGPT’s Advanced Voice Mode over three months and surveyed 4,076 of them about their perceptions. It analyzed conversations for emotional cues and tracked users’ percentages of emotional messages over time (decreasing, flat, or increasing). The team validated classification accuracy by comparing the classifier’s outputs with survey responses.
- The randomized controlled trial asked nearly 1,000 participants over 28 days to engage in particular conversation types (open-ended, personal, or non-personal) and modalities (text, interactions with ChatGPT’s neutral voice, or interactions with an engaging voice), controlling for variables like duration and age. Each participant spent at least five minutes per day interacting with ChatGPT, guided by prompts (such as “Help me reflect on a treasured memory”) and surveys (baseline, daily, weekly, and final). The study classified over 300,000 messages to identify qualities like loneliness and dependence and sorted them according to conversation type and modality.
Results: Both studies found that using ChatGPT was associated with reduced loneliness and increased emotional chat. However, it was also associated with decreased interpersonal social interaction and greater dependence on the chatbot, especially among users who spent more time chatting.
Yes, but: The authors of the randomized controlled trial acknowledged significant limitations. For instance, the study lacked a non-ChatGPT control group to differentiate AI-specific effects from influences such as seasonal emotional shifts, and the trial’s time frame and assignments may not mirror real-world behavior.
Why it matters: As AI chatbot behavior becomes more human-like, people may lean on large language models to satisfy emotional needs such as easing loneliness or grief. Yet we know little about their effects. These studies offer a starting point for AI developers who want to both foster emotional support and protect against over-reliance, and for social scientists who want to better understand the impact of chatbots.
We’re thinking: Social media turned out to cause emotional harm to some people in ways that were not obvious when the technology was new. As chatbots evolve, research like this can help us steer them toward protecting and enhancing mental health.
Human Action in 3D
AI systems designed to generate animated 3D scenes that include active human characters have been limited by a shortage of training data, such as matched 3D scenes and human motion-capture examples. Generated video clips can get the job done without motion capture.
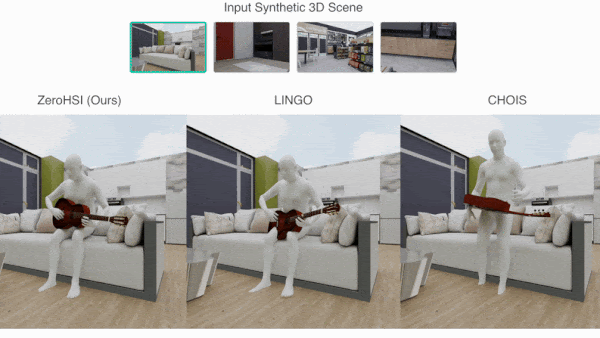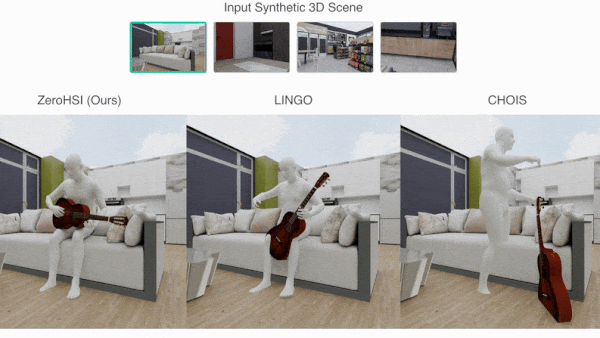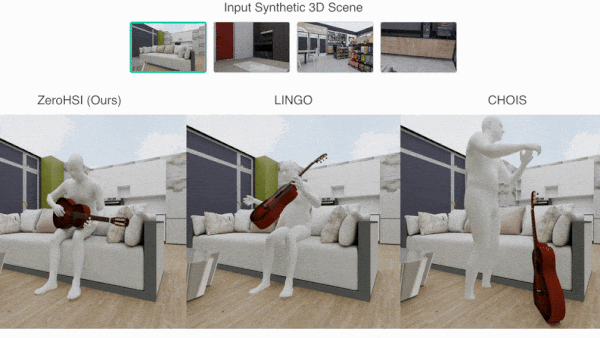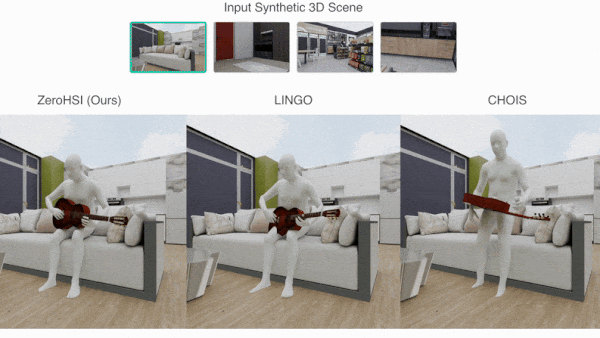
What’s new: A team led by Hongjie Li, Hong-Xing Yu, and Jiaman Li at Stanford University developed Zero-Shot 4D Human-Scene Interaction (ZeroHSI), a method that animates a 3D human figure interacting with a particular 3D object in a selected 3D scene. You can see its output here.
Key insight: Earlier approaches attempted to build a generalized approach: given a 3D scene, a text prompt, and motion-capture data, a diffusion model learned to alter the positions and rotations of human joints and objects over time. But if the system is designed to learn a 3D animation for a specific example motion, videos can stand in for motion capture. Current video generation models can take an image of a scene and generate a clip of realistic human motion and interactions with a wide variety of objects within it. From there, we can minimize the difference between the video frames and images of actions within the scene.
How it works: ZeroHSI takes a pre-built 3D scene that includes a 3D human mesh and 3D object. It uses a rendered image of the scene to generate a video. Then it uses the video to help compute the motions of a human figure and object within the scene.
- The authors fed ZeroHSI a 3D scene complete with 3D human mesh and 3D object. ZeroHSI rendered an image of the scene, viewed from a default camera pose, using Gaussian splatting.
- ZeroHSI fed the rendered image, along with a prompt that described a human interacting with an object in the scene (“the person is playing guitar while sitting on the sofa”), to Kling, an image-to-video generator. Kling produced a video clip.
- For each generated video frame, ZeroHSI rendered a new image of the 3D scene and minimized a loss function with four terms. It used the loss function to calculate how to change the poses of the 3D human, 3D object, and camera in the 3D scene to match their poses in the video frame. For example, one loss term minimized pixel-level differences between the image and video frame. Another minimized the difference between the object’s center in the image and in a segmentation mask of the video frame produced by SAM 2.
- The system sometimes produced errors. For instance, one of the human figure’s hands might fail to touch the object, or the object penetrated the human figure’s body. To remedy this, for each video frame, the authors refined the poses in a separate phase that involved three loss terms. For instance, one term minimized the distance between surfaces of a hand and the object to prevent penetration or distance between them.
Results: The authors evaluated ZeroHSI using a proprietary dataset of 12 3D scenes that included a human figure and an object and between one and three text prompts that described interactions between the human and object and/or scene. In 100 evaluations, ZeroHSI outperformed LINGO, a diffusion model trained on matched 3D scene, 3D object, and human motion-capture data that had achieved the previous state of the art.
- ZeroHSI achieved 24.01 average CLIP Score, which measures how well text descriptions match images (higher is better), while LINGO achieved a 22.99 average CLIP Score. ZeroHSI achieved 0.033 average object penetration depth, a measure of plausibility in physical interactions (lower is better), while LINGO achieved 0.242 average object penetration depth.
- 400 participants judged whether they preferred ZeroHSI or LINGO with respect to realism and how well their output aligned with the prompt. 86.9 percent preferred ZeroHSI for realism, and 89.1 percent preferred ZeroHSI for how well its output matched the prompt.
Why it matters: Learning from motion-capture data is problematic in a couple of ways: (i) it’s expensive to produce, (ii) so little of it is available, which limits how much a learning algorithm can generalize from it. Video data, on the other hand, is available in endless variety, enabling video generation models to generalize across a wide variety of scenes, objects, and motions. ZeroHSI takes advantage of generated video to guide a 3D animation cheaply and effectively.
We’re thinking: There’s a lot of progress to be made in AI simply by finding clever ways to use synthetic data.