
Dear friends,
I traveled to Taiwan last week, where I met many CEOs interested in AI transformation of traditional companies. I also visited Taiwan AI Labs which, similar to OpenAI, started as a nonprofit AI research institute.
Funded by government and private financing, Taiwan AI Labs works on smart city, healthcare, and other projects; for example, using computer vision to estimate traffic flow. Ethan Tu, the lab’s leader, tells me it focuses on practical and socially important projects, including ones that are hard to fund commercially, and openly publishes all its work. I also several professors on sabbatical there. They told me that the lab gives them more engineering resources for AI than they can generally find in a university.

I’m glad to see different nations experiment with new ways to organize AI research and development. I hope more countries will fund nonprofit AI research labs.
Shout out also to National Taiwan University, Taiwan Ministry of Science and Technology, and Taiwania Capital for helping organize my trip!
Keep learning,
Andrew
News
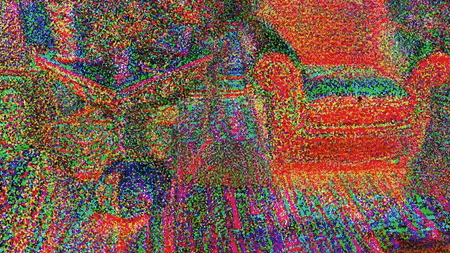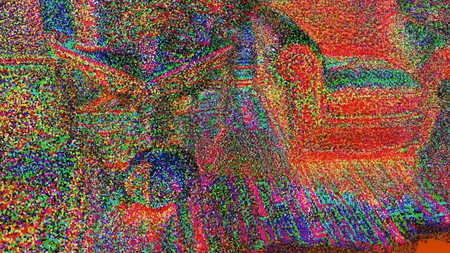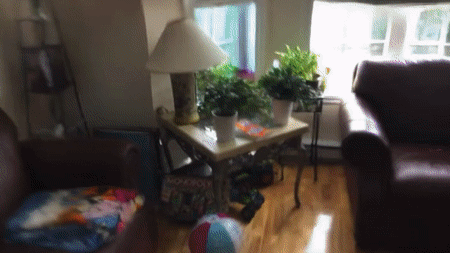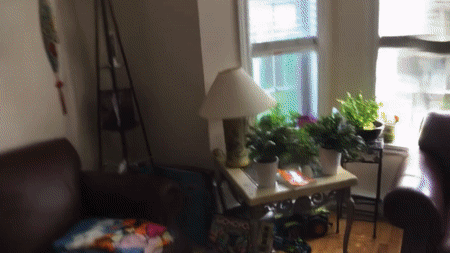
Points Paint the Picture
Creating a virtual representation of a scene using traditional polygons and texture maps involves several complex operations, and even neural-network approaches have required manual preprocessing. Researchers from the Samsung AI Center and Skolkovo Institute of Science and Technology propose a new deep-learning pipeline that visualizes scenes with far less fuss.
What’s new: Aliev et al.’s Neural Point Based Graphics technique rapidly produces realistic images in an end-to-end process. It does particularly well with thin objects that are hard to model using a polygonal mesh, such as shoe laces and bicycle tires. You can see it in action here.
Key insight: There’s no need to model surfaces to represent a scene. Point clouds and corresponding images together contain enough information for a neural network to generate realistic images. Moreover, neural networks can fill in missing information such as parts of objects hidden from view, which simplifies scene modeling.
How it works: The system starts with a point cloud representing a scene, an image of the scene, camera parameters including viewing angle, and a randomly initialized vector representation of each point that encodes shape and surface properties.
- Using traditional graphics libraries and algorithms, it pixelizes a scene’s point cloud and vectors into a multi-channel raw image.
- A rendering network based on the U-Net architecture takes the raw image as input. It learns simultaneously to improve the vectors and generate a final RGB image by minimizing the difference between generated and ground-truth images.
- Once trained, the system can accept a new camera position to generate corresponding viewpoints from a given pixel cloud and learned vectors.
Results: The researchers compared photographic input and generated images from a variety of data sets, including consumer cameras, across several scene-capture techniques, including traditional and deep learning methods. Their system scored highest on a number of measures of image similarity. While its rendering of synthetic scenes isn’t as realistic as that achieved by state-of-the-art ray tracing methods, it produces good-looking images roughly 2,000 times faster.
Why it matters: Neural Point-Based Graphics is a distinct step forward for end-to-end scene capture. By demonstrating that point clouds and images — which can come from a smartphone — together can represent scenes in realistic detail, this research opens the door for refinements that could ultimately compete with the best current methods in a much simpler pipeline.
We’re thinking: Just as neural networks have replaced rule-based systems in computer vision and language applications, they’re on track to have a similar impact in graphics. Given its simplicity and speed, this approach could facilitate real-time applications such as video games, virtual reality, and augmented reality.

Smart Students, Dumb Algorithms
A growing number of companies that sell standardized tests are using natural language processing to assess writing skills. Critics contend that these language models don’t make the grade.
What happened: An investigation by Motherboard found that several programs designed to grade English-language essays show bias against minorities and some students who speak English as a second language. Some models gave high scores to computer-generated essays that contained big words but little meaning.
What they found: Models trained on human-graded papers learn to correlate patterns such as vocabulary, spelling, sentence length, and subject-verb agreement with higher or lower scores. Some experts say the models amplify the biases of human graders.
- In 2018, the publishers of the E-Rater — software used by the GRE, TOEFL, and many states — found that their model gave students from mainland China a 1.3 point lift (on a scale of 0 to 6). It seems that Chinese students, while scoring low on grammar and mechanics, tend to write long sentences and use sophisticated vocabulary.
- The same study found that E-Rater docked African-American students by .81 points, on average, due to biases in grammar, writing style, and organization.
- Motherboard used BABEL to generate two essays of magniloquent gibberish. Both received two 4-out-of-6 scores from the GRE’s online ScoreItNow! practice tool.
Behind the news: At least 21 U.S. states use NLP to grade essays on standardized tests for public schools. Of those, 18 also employ human graders to check a small percentage of papers randomly.
Why it matters: Standardized tests help determine access to education and jobs for millions of Americans every year. Inappropriate use of NLP could be robbing them of life-changing opportunities.
We’re thinking: The company behind E-Rater is the only one that publishes studies on its grading model’s shortcomings and what it’s doing to fix them. Colleges and school boards should lead the charge in demanding that other test providers do the same.

How to Share Dangerous AI
OpenAI raised eyebrows in February when it announced — and withheld — the full version of its groundbreaking language model, GPT-2. Six months later, the company has re-examined the decision.
What happened: The for-profit research organization issued a follow-up report that details the results of GPT-2’s “staged release.” Fearing that the full version would be used to generate convincing misinformation, OpenAI initially released a limited version (124 million parameters). That release was followed by larger versions culminating, so far, in a 774 million-parameter model made available along with the report.
What the report says: Releasing the model in stages while allowing certain partners full access helped advance an understanding of both benign and malignant uses, the organization says. OpenAI remains convinced that staged release is “likely to be a key foundation of responsible publication of AI.”
- Research by OpenAI’s partners confirms that GPT-2’s output can be as credible as New York Times articles and very difficult to detect.
- The report found no malicious uses of available GPT-2 versions.
- OpenAI is aware of five other groups that replicated the complete model. Some of them also opted for a staged release.
- It’s working with several universities to study the social and policy implications of larger GPT-2 models.
- OpenAI plans to release the complete version (1.5 billion parameters) in coming months, barring adverse consequences of smaller releases.
Behind the news: OpenAI’s decision to withhold the complete GPT-2 rankled many in the AI community; without the code and detailed training information, it’s impossible to replicate the results. However, the organization’s reticence didn’t stop a pair of Brown University graduate students, neither of whom had a background in language modeling, from replicating GPT-2 in August.
We’re thinking: The AI community thrives on shared information. Yet the potential for powerful AI models to wreak havoc on the general welfare suggests some sort of gatekeeping mechanism is in order. Staged release may be just the device that white hats need to stay one step ahead of malefactors.
A MESSAGE FROM DEEPLEARNING.AI

Learn tips for leading machine learning projects that you’d only get from years of industry experience. Take the Deep Learning Specialization
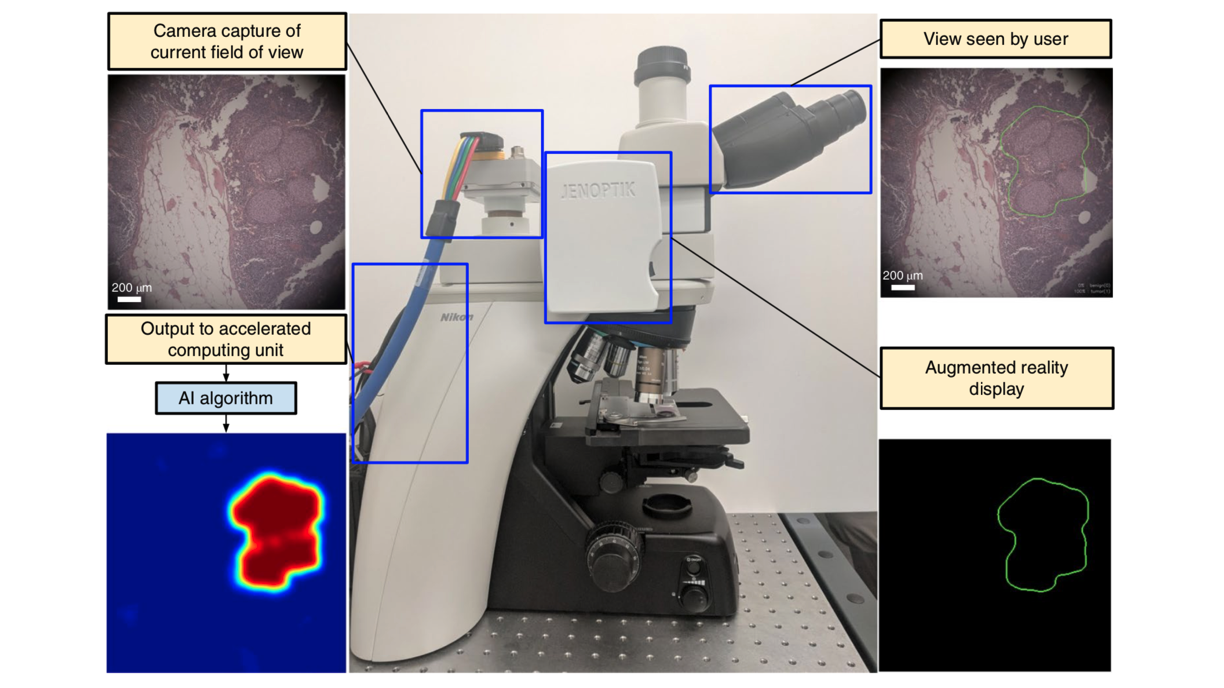
Seeing Cancer
Microscopes outfitted with AI-driven augmented reality could improve the accuracy of cancer diagnoses.
What’s happened: Google Health developed an attachment for analog microscopes that outlines signs of breast and prostate cancer in real time.
How it works: A computer-vision system spots cancer in a cell slide, while augmented-reality tech superimposes the AI’s prediction over the slide at around 27 frames per second.
- The developers combined the Inception V3 image classifier with a fully convolutional neural network, which allowed the system to recognize tumorous patterns much faster.
- A camera captures a head-on view of the slide and projects it, overlaid with the AI prediction, into the microscope eyepiece.
Behind the news: Pathologists use microscopes to measure tumor size relative to nearby lymph nodes and to count the number of cells nearing or undergoing mitosis. That information tells them how aggressively a patient’s cancer is spreading.
Why it matters: Interpreting cell slides is subjective, and one pathologist’s understanding can differ greatly from another’s. Patients in locations where trained pathologists are scarce tend to suffer most from this inconsistency. AI-enhanced tools could help make diagnoses more reliable.
We’re thinking: AI is a natural complement to digital microscopes, but analog microscopes are far more common. This technology promises to upgrade those tools at a fraction of the cost of replacing them.
Honey, I Shrunk the Network!
Deep learning models can be unwieldy and often impractical to run on smaller devices without major modification. Researchers at Facebook AI Research found a way to compress neural networks with minimal sacrifice in accuracy.
What’s new: Building on earlier work, the researchers coaxed networks to learn smaller layer representations. Rather than storing weights directly, the technique uses approximate values that can stand in for groups of weights.
Key insight: The researchers modified an existing data-compression method, product quantization, to learn viable weight approximations.
How it works: By representing groups of similar weights with a single value, the network can store only that value and pointers to it. This reduces the amount of storage needed for weights in a given layer. The network learns an optimal set of values for groups of weights, or subvectors, in a layer by minimizing the difference between layer outputs of the original and compressed networks.
- For fully connected layers, the authors group the weights into subvectors. (They propose a similar but more involved process for convolutional layers.)
- They pick a random subset of subvectors as starting values, then iteratively improve the values, layer by layer, to minimize the difference between the compressed and original neural network.
- Then they optimize the compressed network representation against multiple layers at a time, starting with the first two and ultimately encompassing the entire network.
Results: The researchers achieve best top-1 accuracy on ImageNet for model sizes of 5MB and 10MB. (They achieve competitive accuracy for 1MB models.) They also show that their quantization method is superior to previous methods for ResNet-18.
Why it matters: Typically, researchers establish the best model for a given task, and follow-up studies find new architectures that deliver similar performance using less memory. This work offers a way to compress an existing architecture, potentially taking any model from groundbreaking results in the lab to widespread distribution in the field with minimal degradation in performance.
Yes, but: The authors demonstrate their method on architectures with fully connected layers and CNNs only. Further research will be required to find its limits, and also to optimize the compressed results for compute speed.
We’re thinking: The ability to compress top-performing models could put state-of-the-art AI in the palm of your hand and eventually in your pacemaker.

AI in the Real World
Theoretical advances can be thrilling, but the excitement can drown out all the ways AI is actually being put to use. DeepIndex provides an up-to-date, well organized, cheeky guide to practical applications culled from news reports.
What it is: DeepIndex.org lists over 630 examples, organized into 19 categories and ranked according to how well they work.
- Categories include Gaming, Finance, Agriculture, Education, and Security, plus a catch-all for miscellaneous models like the one Apple used for its Animoji feature.
- DeepIndex creator Chris Yiu ranks the effectiveness of each application: Crushing It, Capable, or Getting There. The ranking reflects factors like product status, academic publications, and case studies.
Our favorites: DeepIndex is a treasure trove of bold efforts and unlikely concepts. Yiu’s personal favorite is a model that “fixes Warner Bros.’ terrible attempts to digitally remove Henry Cavill’s mustache in [the Hollywood blockbuster] Justice League.” That’s a fun use case, no doubt, but we found others more compelling:
- Fraugster, an AI-powered fraud prevention tool, calms some of our fears of getting swept up in the next data breach.
- A chatbot called DoNotPay has overturned hundreds of thousands of parking tickets in the UK.
- The Agriculture section includes a harvest of models capable of picking strawberries, sorting cucumbers, and spraying pesticides.
- Orbital Atlas is helping the U.S. Air Force (and presumably the incipient Space Force) navigate the increasingly cluttered space surrounding planet Earth.
- A machine learning algorithm called Warblr that matches tweets, chirps, and warbles to the bird species that sang them.
- And for metalheads, Dadabots generates an endless stream of death metal music. Now that’s crushing it.