
Dear friends,
I just got back from AI Dev x NYC, the AI developer conference where our community gathers for a day of coding, learning, and connecting. The vibe in the room was buzzing! It was at the last AI Dev in San Francisco that I met up with Kirsty Tan and started collaborating with her on what became our AI advisory firm AI Aspire. In-person meetings can spark new opportunities, and I hope the months to come will bring more stories about things that started in AI Dev x NYC!
The event was full of conversations about coding with AI, agentic AI, context engineering, governance, and building and scaling AI applications in startups and in large corporations. But the overriding impression I took away was one of near-universal optimism about our field, despite the mix of pessimism and optimism about AI in the broader world.
For example, many businesses have not yet gotten AI agents to deliver a significant ROI, and some AI skeptics are quoting an MIT study that said 95% of AI pilots are failing. (This study, by the way, has methodological flaws that make the headline misleading.) But at AI Dev were many of the teams responsible for the successful and rapidly growing set of AI applications. Speaking with fellow developers, I realized that because of AI's low penetration in businesses, it is simultaneously true that (a) many businesses do not yet have AI delivering significant ROI, and (b) many skilled AI teams are starting to deliver significant ROI and see the number of successful AI projects climbing rapidly, albeit from a low base. This is why AI developers are bullish about the growth that is to come!
Multiple exhibitors told me this was the best conference they had attended in a long time, because they got to speak with real developers. One told me that many other conferences seemed like fluff, whereas participants at AI Dev had much deeper technical understanding and thus were interested in and able to understand the nuances of cutting-edge technology. Whether the discussion was on observability of agentic workflows, the nuances of context engineering for AI coding, or a debate on how long the proliferation of RL (reinforcement learning) gyms for training LLMs will continue, there was deep technical expertise in the room that lets us collectively see further into the future.

One special moment for me was when Nick Thompson, moderating a panel with Miriam Vogel and me, asked about governance. I replied that the United States’ recent hostile rhetoric toward immigrants is one of the worst moves it is making, and many in the audience clapped. Nick spoke about this moment in a video.
I enjoyed meeting many people at AI Dev, and am grateful to everyone who came and to all our speakers, exhibitors, sponsors, volunteers, and event staff. My only regret is that, even though we scaled up the event 3x compared to the previous San Francisco event, we had to limit the number of tickets because the space couldn’t admit more attendees.
Even though so much work is now online, in-person events are special and can be turning points for individuals and projects. We plan to make the next AI Dev in San Francisco on April 28-29, 2026, an even bigger event, and look forward to the conference helping to spark more sharing and connections in the future.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

In Semantic Caching for AI Agents, created with Redis, you’ll learn to make AI agents that become faster and more cost-effective over time by recognizing when different queries have the same meanings. Optimize accuracy and integrate caching into your agents. Enroll now!
News

Self-Driving Cars on U.S. Freeways
Waymo became the first company to offer fully autonomous, driverless taxi service on freeways in the United States.
What’s new: Waymo’s fleet is serving paying customers on high-speed roads in San Francisco and Los Angeles, California, and Phoenix, Arizona. The service is available to customers who have selected the Waymo app’s “freeway” preference, if the app determines that using freeways will result in a substantially faster trip.
How it works: Waymo, which operates thousands of vehicles in the San Francisco Bay Area, provided the most information about freeway service in that region. Its vehicles are plying the freeways that border roughly 260 square miles between San Francisco and San Jose, cutting ride times by as much as 50 percent.
- Autonomous vehicles have shuttled employees, members of the press, and other guests on freeways for more than a year.
- The vehicles were tested on millions of miles on public roads, closed courses, and simulated roads to gather sufficient examples of traffic maneuvers, system failures, crashes, and transitions between freeways and surface streets. The company generated redundant synthetic scenarios and produced varied training examples by tweaking variables related to the vehicle's behavior, the actions of others, and environmental conditions.
- In addition, the company is concerned with managing the psychological impact of autonomous freeway driving, Waymo co-CEO Tekedra Mawakana said. Riders in self-driving vehicles surrender control, and this may be more worrisome at 65 miles per hour than at lower speeds, she said.
- The company worked with the California Highway Patrol to develop protocols for autonomous freeway driving.
- The California Public Utilities Commission had approved Waymo’s vehicles for freeway driving in March 2024 as part of a plan that includes adding more cars to the city’s streets and operating at any hour.
Behind the news: Waymo has its roots in vehicles built by the Stanford Racing Team to compete in the DARPA Grand Challenge and DARPA Urban Challenge autonomous vehicle contests in the mid-2000s. Google adopted the project in 2009 and spun out Waymo as an independent company in late 2016.
- It currently operates in Atlanta, Austin, Los Angeles, Phoenix, and San Francisco and has announced plans to expand into Dallas, Denver, Detroit, Las Vegas, Miami, Nashville, San Diego, and Seattle with several other cities on the drawing board including London and Tokyo.
- Although its safety record is not pristine — in September, a Waymo car killed a pet cat in San Francisco — the company claims that its cars have experienced 91 percent fewer injury-or-worse crashes and 92 percent fewer pedestrian crashes with injuries than human drivers who drive the same distances in the same area.
- In 2024 and 2025, the U.S. National Highway Transportation Safety Administration opened separate investigations into Waymo for alleged violations of traffic laws.
Why it matters: Operating on freeways is critical for self-driving cars to function fully as alternatives to human-driven vehicles. Fully autonomous freeway driving is a significant technical step forward for Waymo, since its cars must shift smoothly from city driving to freeway driving, where conditions are less tightly controlled, and systems must plan farther ahead and react more quickly to adjust to changes at higher speed. In addition, obtaining government approval to put Waymo cars on freeways is a huge accomplishment from regulatory and social perspectives. The company managed to persuade regulators that the benefits of putting self-driving cars on freeways outweigh the potential costs, including threats to safety and public trust. Waymo’s aggressive plans for expansion suggest that this is the first of more milestones to come.
We’re thinking: Andrew still has his t-shirt from the DARPA Urban Challenge. He remembers the optimism of those days, and how much longer than early forecasts it has taken to develop roadworthy self-driving vehicles. Between Waymo’s robotaxis and Tesla’s Full Self-Driving (Supervised) capability, the question is not whether this technology will become commonplace but when.
Top Agentic Results, Open Weights
The latest open-weights large language model from Moonshot AI challenges top proprietary LLMs at agentic tasks by executing hundreds of tool calls sequentially and pausing to think between each.
What’s new: Kimi K2 Thinking and the faster Kimi K2 Thinking Turbo are trillion-parameter reasoning versions of Moonshot’s earlier LLM Kimi K2. They were fine-tuned at 4-bit (INT4) precision, so they can run at lower cost and on lower-cost hardware than other LLMs of similar size.
- Input/output: Text in (up to 256,000 tokens), text out (size limit undisclosed, Kimi K2 Thinking 14 tokens per second, Kimi K2 Thinking Turbo 86 tokens per second)
- Architecture: Mixture-of-experts transformer, 1 trillion parameters total, 32 billion parameters active per token.
- Performance: Outperforms top closed LLMs in the τ²-Bench Telecom agentic benchmark, outperforms other open LLMs generally.
- Availability: Free web user interface with limited tool access, weights freely available for noncommercial and commercial uses up to 100 million monthly active users or monthly revenue of $20,000,000 under modified MIT license.
- API: Kimi K2 Thinking ($0.60/$0.15/$2.50 per million input/cached/output tokens), Kimi K2 Thinking Turbo ($1.15/$0.15/$8.00 per million input/cached/output tokens) via Moonshot AI and other vendors
- Features: Tool use including search, code interpreter, web browsing, “heavy” reasoning mode
- Undisclosed: Specific training methods and datasets, output size limit
How it works: Rather than completing all reasoning steps before acting, Kimi K2 Thinking executes cycles of reasoning and tool use. This enables it to adjust continually depending on interim reasoning steps or results of tool calls.
- Given a prompt, Kimi K2 Thinking interleaves reasoning, tool use (up to 300 calls), and planning. First it reasons about the task and then calls tools, interprets the results, plans the next step, and repeats the cycle. This investment at inference yields better results in tasks that require multiple steps. For example, the model correctly solved an advanced mathematical probability problem by alternating between 23 reasoning and tool-use steps.
- A “heavy” mode simultaneously runs 8 independent reasoning paths and combines their outputs to produce final output. This mode can improve accuracy on difficult problems at eight times the usual cost in computation.
- Moonshot fine-tuned Kimi K2 Thinking at INT4 precision (using integers encoded in 4 bits instead of 16 or 32 bits), roughly doubling output speed and reducing the model’s file size to 594 gigabytes (compared to Kimi K2 Instruct’s 1 terabyte). Kimi K2 Thinking used quantization aware training (or QAT), a technique that simulates low-precision arithmetic during fine-tuning. Training steps used low-precision math, but the weights were maintained in full precision, making later quantization more accurate.
- Kimi K2 Thinking cost $4.6 million to train, according to CNBC. That’s $1 million less than DeepSeek’s reported cost to train DeepSeek-V3.
Results: Kimi K2 Thinking leads open-weights LLMs in several benchmarks and achieves state-of-the-art results on some agentic tasks. However, it generates many more tokens than most competitors to achieve a comparable performance.
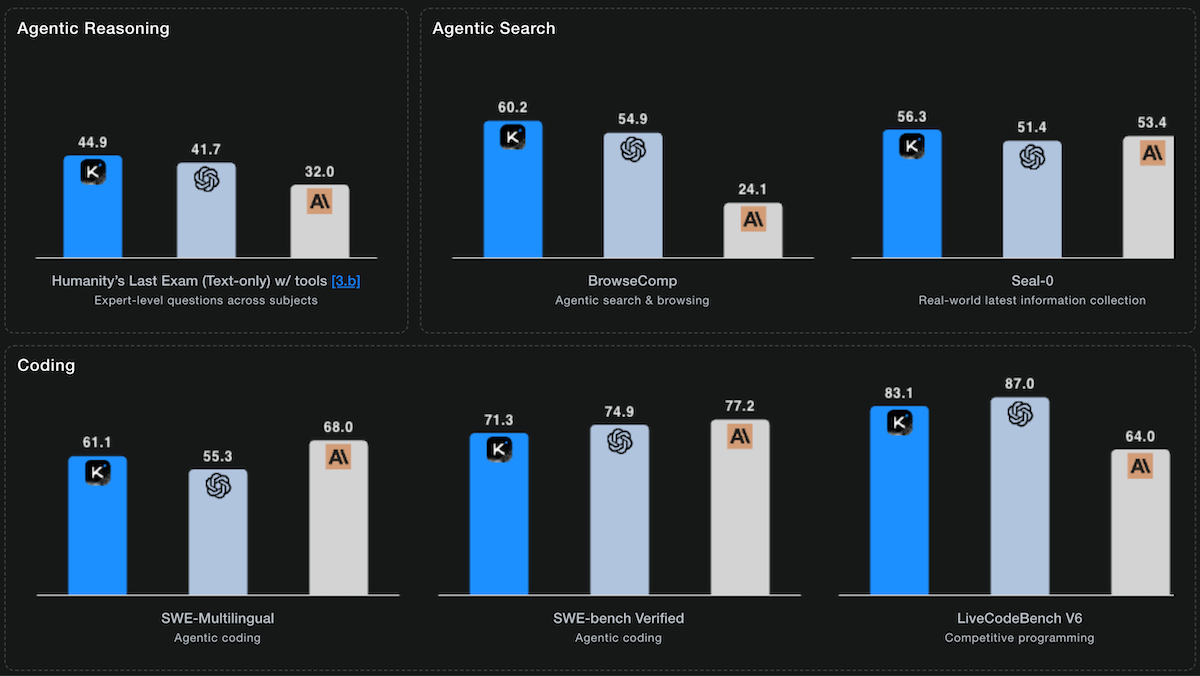
- On Artificial Analysis' Agentic Index, which measures multi-step problem-solving with tools, Kimi K2 Thinking ranked third (67 points) among LLMs tested, trailing only GPT-5 set to high reasoning and GPT-5 Codex set to high reasoning (68 points).
- On τ²-Bench Telecom, a test of agentic tool use, Kimi K2 Thinking achieved 93 percent accuracy, the highest score independently measured by Artificial Analysis and 6 percentage points ahead of the nearest contenders, GPT-5 Codex (87 percent accuracy) set to high reasoning and MiniMax-M2 (87 percent accuracy).
- On Humanity's Last Exam, a test of multi-domain, graduate-level reasoning, Artificial Analysis measured Kimi K2 Thinking (22.3 percent accuracy without tools) outperformed other open-weights LLMs but trailed GPT-5 set to high reasoning (26.5 percent) and Grok 4 (23.9 percent). With tools enabled, Moonshot reports the model achieved 44.9 percent, a state-of-the-art result higher than that of GPT-5 set to high reasoning (41.7 percent accuracy) and Anthropic Claude Sonnet 4.5 Thinking (32.0 percent accuracy).
- On coding benchmarks, Kimi K2 Thinking ranked first or tied for first among open-weights LLMs on Terminal-Bench Hard, SciCode, and LiveCodeBench, but trailed proprietary LLMs. On SWE-bench Verified, a test of software engineering, Moonshot reports Kimi K2 Thinking (71.3 percent accuracy) fell short of Claude Sonnet 4.5 Thinking (77.2 percent) and GPT-5 (high) (74.9 percent).
Yes, but: Kimi K2 Thinking used 140 million tokens to complete Artificial Analysis’ Intelligence Index evaluations, more than any other LLM tested, roughly 2.5 times the number used by DeepSeek-V3.2 Exp (62 million) and double that of GPT-5 Codex set to high reasoning (77 million). To run the Intelligence Index tests, Kimi K2 Thinking ($356) was around 2.5 times less expensive than GPT-5 set to high reasoning ($913), but roughly 9 times pricier than DeepSeek-V3.2 Exp ($41).
Behind the news: In July, Moonshot released the weights for Kimi K2, a non-reasoning version optimized for agentic tasks like tool use and solving problems that require multiple steps.
Why it matters: Agentic applications benefit from the ability to reason across many tool calls without human intervention. Kimi K2 Thinking is designed specifically for multi-step tasks like research, coding, and web navigation. INT4 precision enables the model to run on less expensive, more widely available chips — a boon especially in China, where access to the most advanced hardware is restricted — or at very high speeds.
We’re thinking: LLMs are getting smarter about when to think, when to grab a tool, and when to let either inform the other. According to early reports, Kimi K2 Thinking’s ability to plan and react helps in applications from science to web browsing and even creative writing — a task that reasoning models often don’t accomplish as well as their non-reasoning counterparts.
Anthropic Cyberattack Report Sparks Controversy
Independent cybersecurity researchers pushed back on a report by Anthropic that claimed hackers had used its Claude Code agentic coding system to perpetrate an unprecedented automated cyberattack.
What’s new: In a blog post, Anthropic described thwarting a September campaign by hackers sponsored by the government of China, calling it the “first documented case of a large-scale cyberattack without substantial human intervention.” However, some independent researchers said that current agents are not capable of performing such nefarious feats, Ars Technica reported. Moreover, the success rate — a few successful attacks among dozens — belie Anthropic’s claim that the agentic exploit revealed newly dangerous capabilities. The lack of detail in Anthropic’s publications makes it difficult to fully evaluate the company’s claims.
Claude exploited: The hackers circumvented Claude Code’s guardrails by role-playing as employees of a security company who were testing its networks, according to Anthropic’s report.
- They coaxed Claude Code to probe, breach, and extract data from networks in small steps that the underlying model didn’t recognize as malicious, Then it executed them at speeds beyond the reach of conventional hacks.
- Agentic AI performed 80 percent to 90 percent of the technical steps involved, and human intervention was required only to enter occasional commands like “yes, continue,” “don’t continue,” or “Oh, that doesn’t look right, Claude, are you sure?” The Wall Street Journal reported.
- The intruders targeted at least 30 organizations and succeeded in stealing sensitive information from several.
- The report didn’t identify the organizations attacked, explain how it detected the attacks, or explain how it associated the attackers with China. A spokesman for China’s Foreign Ministry said that China does not support hacking, The New York Times reported.
Reasons for skepticism: Independent security researchers interviewed by Ars Technica , The Guardian, and others found a variety of reasons to question the report.
- While they agreed that AI can accelerate tasks such as log analysis and reverse engineering, they have found that AI agents are not yet capable of performing multi-step tasks without human input, and they don’t automate cyberattacks significantly more effectively than hacking tools that have been available for decades. “The threat actors aren't inventing something new here,” researcher Kevin Beaumont said in an online security forum.
- In addition to Claude Code, the hackers used common open-source tools, Anthropic said. Yet defenses against these familiar tools are also familiar to security experts, and it’s not clear how Claude Code would have changed this.
- Anthropic itself pointed out that Claude Code may well have hallucinated the information it purportedly hacked, since it “frequently overstated findings” and “occasionally fabricated data.” Such misbehavior is a significant barrier to using the system to execute cyberattacks, the company said.
Behind the news: Hackers routinely use AI to expedite or automate their work, for instance writing more effective phishing emails or generating malicious code. In August, Anthropic highlighted the rise of “vibe hacking,” in which bad actors who have limited technical skills use AI to pursue nefarious activities previously undertaken only by more highly skilled coders. In August, Anthropic reported that it had disrupted one such effort, which involved the theft of personal data and extortion. In October, White House AI Czar David Sacks accused Anthropic of running a “sophisticated regulatory capture strategy based on fear-mongering.”
Why it matters: It stands to reason that AI can make hacking faster and more effective, just as it does many everyday activities. But Anthropic’s description of the Claude-powered agentic cyberattack it discovered is at odds with the experience of security researchers outside the company. Independent researchers have found agents relatively ineffective for automating cyberattacks and conventional methods equally or more dangerous. Security researchers are right to explore agentic AI both to perpetrate and defend against security threats, but it has not yet been found to pose the dire threat that Anthropic warns of.
We’re thinking: AI companies want to promote the power of their products, and sometimes — paradoxically — that promotion emphasizes a product’s powerful contribution to a negative outcome. Positive or negative, hype is harmful. We hope that makers of state-of-the-art models and applications based on them will find ways to drum up interest in their accomplishments — many of which are genuinely impressive and exciting! — without misleading or confusing the public. With respect to cybersecurity, AI-driven detection of security flaws makes it easier to patch them. In this way, AI helps to shift the balance of power from attackers to defenders, making computers more secure, not less.
More-Efficient Agentic Search
Large language models may have learned knowledge that’s relevant to a given prompt, but they don’t always recall it consistently. Fine-tuning a model to search its parameters as though it were searching the web can help it find knowledge in its own weights.
What’s new: Yuchen Fan and colleagues at Tsinghua University, Shanghai Jiao Tong University, Shanghai AI Laboratory, University College London, China State Construction Engineering Corporation Third Bureau, and WeChat AI introduced Self-Search Reinforcement Learning (SSRL). SSRL trains a large language model (LLM) to answer questions by simulating the search process, from generating a query to providing the answer. In the authors’ tests, it improved the performance of models with and without access to web-search tools.
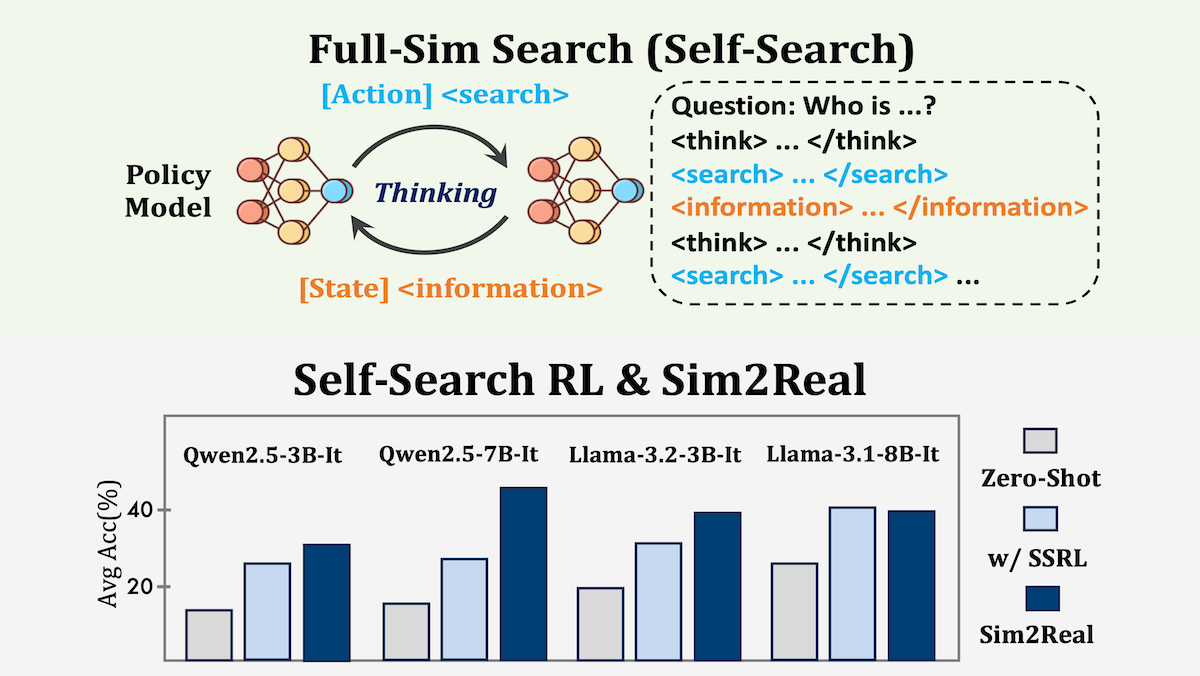
Key insight: The authors found that an LLM is more likely to return a correct answer among 1,000 responses than it does in smaller numbers of responses. This shows that LLMs don’t always respond with knowledge they have. Simulating search — by asking a model to generate a query followed by a response to the query, as though it were searching the web — during fine-tuning via reinforcement learning can refine the model’s ability to retrieve information from its weights.
How it works: The authors used the reinforcement learning algorithm Group Relative Policy Optimization (GRPO) to fine-tune Llama-3.1-8B, Qwen2.5-7B, and other pretrained models to answer questions in the Natural Questions and HotpotQA datasets by following a sequence of actions that included reasoning and simulated searches. The models learned to produce a sequence of thoughts, queries, and self-generated information, cycling through the sequence multiple times if necessary, before arriving at a final answer.
- The model generated text following a specific format, using
<think>, <search>, <information> (self-generated search responses), and <answer> tags to structure its reasoning process. - The authors rewarded the model for producing final answers correctly and for following the designated format.
- The system ignored the tokens between the <information> tags for the loss calculation. This encouraged the model to focus on the query and the reasoning process rather than memorize any erroneous information it generated.
Results: The team evaluated SSRL on 6 question-answering benchmarks (Natural Questions, HotpotQA, and four others) and compared it to methods that use external search engines. Models trained via SSRL tended to outperform baselines that rely on search. The skills learned via SSRL also improved the model’s performance when it was equipped to call an external search engine.
- Across the benchmarks, a Llama-3.1-8B model trained using SSRL exactly matched the correct answer 43.1 percent of the time on average. ZeroSearch, a model that uses a separate, fine-tuned Qwen-2.5-14B-Instruct to answer queries during training and Google to answer queries during testing, exactly matched the correct answer 41.5 percent of the time, and Search-R1, a model that’s trained to use Google search, exactly matched the right answer 40.4 percent of the time.
- Of four models trained with SSRL, three showed improved performance using Google Search instead of self-generating responses. For instance, a Qwen2.5-7B model’s performance improved from an average of 30.2 percent with SSRL to 46.8 percent with SSRL and Google search.
Why it matters: The gap between training in a simulation and performance in the real world can be a challenge for AI agents based on LLMs. In this case, LLMs that were trained to simulate web searches were able to perform actual web searches more effectively. This result demonstrates that, for knowledge-based tasks, an LLM’s own parameters can serve as a cost-effective, high-fidelity simulator.
We’re thinking: Agents can be more judicious with respect to when they need to search the web. This work suggests a hybrid approach, in which an agent first consults its internal knowledge and searches the web only when it detects a gap.