
Dear friends,
In an earlier letter, I wrote about the challenge of robustness: A learning algorithm that performs well on test data often doesn’t work well in a practical production environment because the real world turns out to be different than the test set.
Amid the Covid-19 pandemic, many machine learning teams have seen this firsthand:
- Financial anti-fraud systems broke because consumers changed their behavior. For example, credit card companies often flag a card as possibly stolen if the purchase pattern associated with it suddenly changes. But this rule of thumb doesn’t work well when huge swaths of society start working from home and stop going to restaurants and malls.
- Logistics models used to predict supply and demand broke when manufacturers, shippers, and consumers changed their behavior. Trained on last year’s data, a model that predicts 1,000 widgets arriving on time next month can’t be trusted anymore.
- Online services receiving a new surge or plunge in users are rethinking their demand estimation models, since earlier models no longer are accurate.

Although the tsunami of Covid-19 — with its devastating impact on lives and livelihoods — is a dramatic example of change in the world, small parts of the world experience waves of change all the time. A new online competitor may mean that a retail store’s demand estimation model no longer works. A new tariff by a small country subtly shifts supply chain behavior among larger ones.
Building practical machine learning systems almost always requires going beyond achieving high performance on a static test set (which, unfortunately, is what we are very good at). You may need to build an alert system to flag changes, use human-in-the-loop deployments to acquire new labels, assemble a robust MLOps team, and so on.
Technological improvements will make our algorithms more robust to the world’s ongoing changes. For the foreseeable future, though, I expect deploying ML systems — and bridging proof of concept and production deployments — to be rewarding but also hard.
I hope all of you continue to stay safe.
Keep learning!
Andrew
Covid-19 Watch
New Machine Learning Resources
The AI community is working to beat back coronavirus. Here are some recently released datasets and tools to fuel that effort.
- Mobility Trends Reports: Apple released Mobility Trends Reports, which presents anonymized, aggregated data that documents the use of various modes of transportation since the arrival of Covid-19. The company took advantage of customer requests for directions in Apple Maps to infer relative changes in walking, driving, and public transit ridership in cities around the world. The offering includes raw data and a handy visualization tool.
- C3.ai Data Lake: Enterprise software provider C3.ai opened a data lake that compiles many valuable coronavirus resources in one place. The service is free, and the data are updated continuously via unified, restful APIs. It offers everything from time series to case reports via single, simple API requests so you can spend more time generating insights.
- Folding@home: Looking to put your spare CPU cycles to good use? This distributed computing project, which simulates protein folding, is newly equipped to run experiments relevant to Covid-19. Your computing horsepower can help biologists unlock the virus’ secrets.
News

Tracking the Elusive Stop Sign
Recognizing stop signs, with their bold color scheme and distinctive shape, ought to be easy for computer vision — but it turns out to be a tricky problem. Tesla pulled back the curtain on what it takes to train its self-driving software to perform this task and others.
What’s new: Tesla AI chief Andrej Karpathy describes in a video presentation how the electric car maker is moving toward fully autonomous vehicles. Shot at February’s ScaledML Conference, the video was posted on YouTube last week.
Not just a big red hexagon: Stop signs take a surprising variety of forms and appearances, and that can make them hard to identify. Rather than an oversized icon on a pole, they’re often waved by construction workers, hanging off school buses, or paired with other signs. Karpathy describes how his team trained the company’s Autopilot system to detect a particularly vexing case: stop signs partially obscured by foliage.
- Engineers understood that AutoPilot was having trouble recognizing occluded stop signs because, among other things, the bounding boxes around them flickered.
- Using images from the existing dataset, they trained a model to detect occluded stop signs. They sent this model to the fleet with instructions to send back similar images. This gave them tens of thousands of new examples.
- They used the new examples to improve the model’s accuracy. Then they deployed it to HydraNet, the software that fuses outputs from AutoPilot’s 48 neural networks into a unified, labeled field of view.
Behind the news: Tesla is the only major autonomous driving company that doesn’t use lidar as its primary sensor. Instead, it relies on computer vision with help from radar and ultrasonic sensors. Cameras are relatively cheap, so Tesla can afford to install its self-driving sensor package into every car that comes off the line, even though self-driving software is still in the works. It’s also easier to label pictures than point clouds. The downside: Cameras need a lot of training to sense the world in three dimensions, which lidar units do right out of the box.
Unstoppable: Responding to Karpathy’s presentation on Twitter, Google Brain researcher David Ha (@hardmaru) created stop sign doodles using sketch-rnn, an image generator he and colleague David Eck trained on crude hand-drawn sketches. Generate your own doodled dataset here.
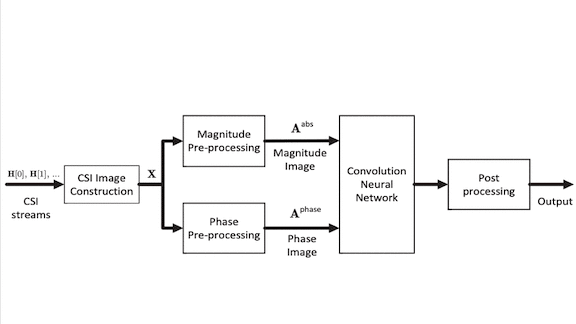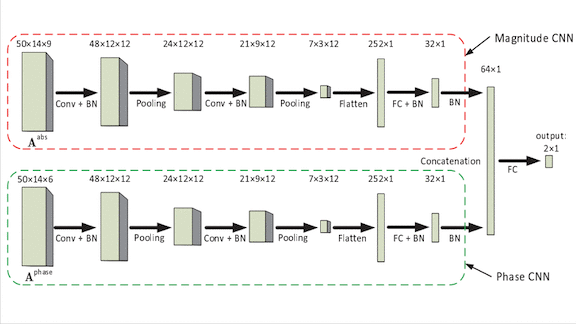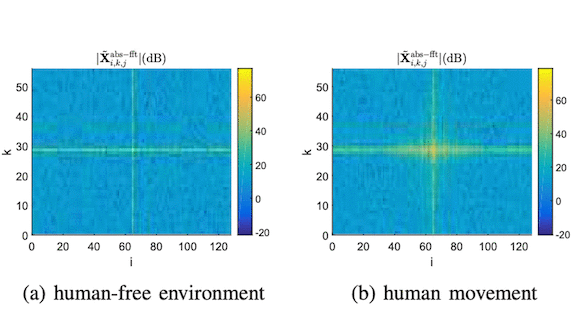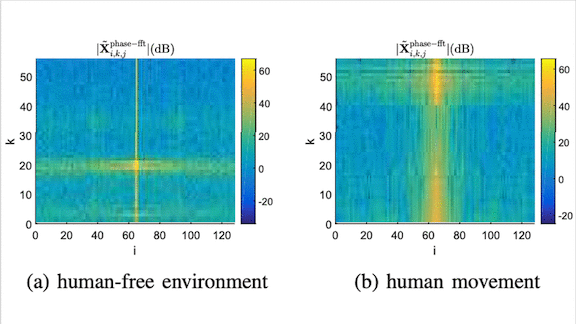
Room With a View
Your body disturbs Wi-Fi signals as you move through them. New research takes advantage of the effect to recognize the presence of people.
What’s new: Yang Liu and colleagues at Syracuse University detected people in a room with a Wi-Fi router by analyzing the signal.
Key insight: Radio waves interfere with one another, creating high-frequency noise that masks other kinds of perturbations. The researchers removed these components, making it easier to identify lower-frequency disturbances caused by human motion.
How it works: A Wi-Fi router comprises many antennas transmitting and receiving radio waves on different frequency bands called subcarriers. The researchers measured the signal strength and phase received by each antenna over a fixed time period to plot what is known as channel state information (CSI). The sequence of CSI images — cubes corresponding to measurements of the transmitting antenna, receiving antenna, and subcarrier — feeds a network that predicts whether someone is moving in the room
- The researchers extracted CSI components that represent signal strength and phase.
- The pre-processing algorithm transformed these components to the frequency domain to capture change from time step to time step.
- They fed the strength and phase information into a dual-input convolutional neural network, basically a pair of AlexNets operating in parallel. The model’s fully connected layers merged the features extracted by each CNN to render a prediction.
Results: The authors’ method slightly outperformed conventional motion detectors based on infrared beams. The dual CNN detected a wider physical area. Although the training data included only people walking, it spotted minimal motion — say, typing on a keyboard while seated — almost twice as well as conventional detectors. (The success rate was only around 5 percent, but for much of the time, typing was the only motion to detect.) It may miss someone if they’re still, but combining multiple predictions over time improved accuracy unless someone was still for minutes on end.
Yes, but: The training and test data come from the same room, so the model’s practicality is limited for now. It would be onerous to retrain for each new room we might use it in.
Why it matters: It’s hard to imagine extracting this kind of information from radio waves without deep learning. Still, the preprocessing step was crucial. Neural networks can be distracted by input features that don’t correlate with the output. Radio interference doesn’t correlate with human motion, so the CNN would have required a huge amount of data to learn to detect people through the noise. Removing it at the outset made training far more efficient.
We’re thinking: It is well known that powerful actions can create a disturbance in the Force. But anyone can create a disturbance in the Wi-Fi.

Roads to Recovery
Deep learning promises to help emergency responders find their way through disaster zones.
What’s new: MIT researchers developed a tool that maps where hurricanes and other calamities have wiped out roads, helping to show aid workers the fastest ways to get to people in need.
How it works: Since 2017, following hurricanes in the Carolinas, Florida, Texas, and Puerto Rico, aircraft equipped with lidar collected three-dimensional images of the devastated landscapes. Previously, the researchers analyzed the data manually to evaluate damage to roads. Now they’re building neural networks that get the job done faster.
- The team trained a network to identify roads in the lidar imagery (the blue map in the animation above). The model identified roads scanned in a Boston suburb with 87 percent accuracy.
- The researchers trained an unsupervised model to spot sharp changes in the roads’ elevation (the graph above with black background and green points). A horizontal line of elevated lidar points that crosses a road, for instance, could be a downed tree. A sudden drop in elevation could be a washed-out bridge.
- They merged the road and obstruction output into OpenStreetMap and built an algorithm that finds the optimal route from place to place while avoiding impassable roads.
Results: In tests, the group was able to fly a lidar mission, process data, and generate route-finding analytics in under 36 hours.
Why it matters: After disaster strikes, damaged infrastructure often thwarts efforts by emergency responders and relief groups to deliver food and medical care to those in need. The new system could help save lives.
We’re thinking: Lidar is just one of many rich sources of post-disaster data. Machine learning engineers with humanitarian impulses can also dig into satellite imagery, GIS data, and social media posts.
A MESSAGE FROM DEEPLEARNING.AI
Interested in learning more about AI applications in medicine? Build your own diagnostic and prognostic models in our AI for Medicine Specialization. Enroll now
Bug Squasher
A new algorithm can triage programming bugs, highlighting dangerous flaws.
What’s new: Microsoft researchers developed a machine learning model that reads the titles of bug reports and recognizes those describing flaws that compromise security. Further, it sorts security bugs by severity.
How it works: Along with stellar software products, Microsoft developers produce 30,000 coding errors monthly. Users or other developers who encounter one can file a report. These reports are generated automatically, including a brief title that describes the bug plus detailed information that may include passwords or other sensitive details. To protect user privacy, Microsoft’s model reads only the title.
- 13 million bug reports collected between 2001 and 2018 served as data for training, validation, and testing. Security experts approved training data before training and evaluated the model’s performance in production.
- The data was annotated either by hand or automatically using software that recognizes similarities between previous bugs and new ones.
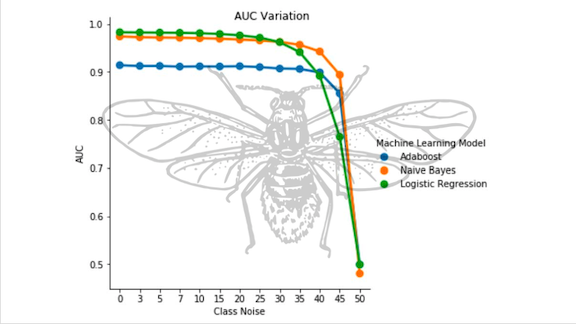
- The team extracted features using TF-IDF and trained separate models based on Naive Bayes, AdaBoost, and logistic regression, as described in a recent paper. Logistic regression achieved the best results.
- The system first ranks bugs that have no security impact at a low priority, then grades security bugs as critical, important, or low-impact.
Results: The model recognized security bugs with 93 percent accuracy and achieved 98 percent area under the ROC curve. Based on an extensive review of earlier work on automated bug-hunting, the researchers believe their system is the first to classify software flaws based on report titles alone. They expect to deploy it in coming months.
Behind the news: Software bugs are responsible for some of history’s most infamous tech headaches.
- In 2014, the Heartbleed bug rendered huge swaths of the internet vulnerable to hackers.
- Issues in General Electric’s energy management software compounded a local power outage into a widespread blackout in 2003.
- Many software systems developed prior to the mid 1990s used two digits to represent the year. This design flaw led to global panic, and expensive efforts to make sure systems did not crash at the dawn of the year 2000.
Why it matters: In 2016, the U.S. government estimated that cyber security breaches — many of them made possible by software defects — cost the nation’s economy as much as $109 billion. Being able to spot and repair the most dangerous flaws quickly can save huge sums of money and keep people safer.
We’re thinking: As producers of our fair share of bugs, we’re glad to know AI has our back.
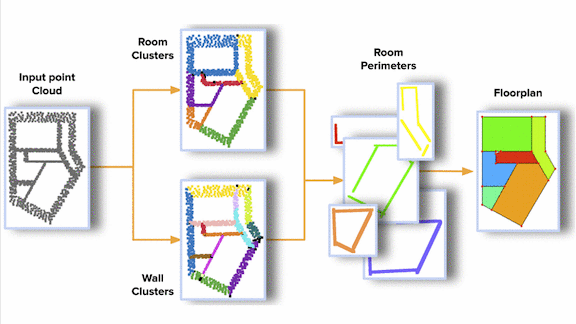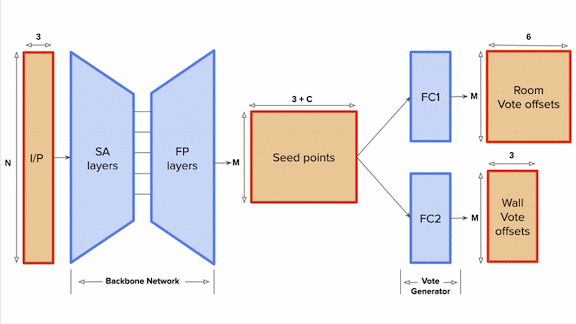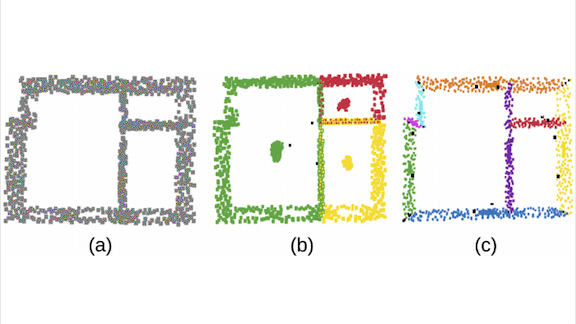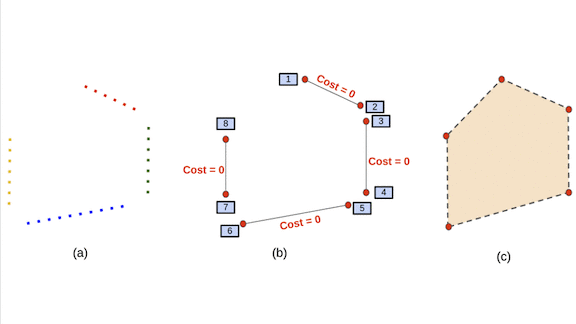
Finding a Floor Plan
Robot vacuum cleaners are pretty good at navigating rooms, but they still get stuck in tight spaces. New work takes a step toward giving them the smarts they’ll need to escape the bathroom.
What’s new: Led by Ameya Phalak, a team at Magic Leap created Scan2Plan, a model that segments 3D scans of empty indoor spaces into floor plans.
Key insight: Given a single scan covering an entire building, Scan2Plan learns to recognize scanned 3D points belonging to the same wall and those belonging to the same room. Once it knows the walls and rooms they form, generating a floor plan is easy.
How it works: 3D scanners project light and measure how long it takes to bounce back, producing a point cloud that represents the scene. In an empty room, these points are likely to belong to walls.
- The team started by creating a synthetic training dataset. They generated random 2D shapes divided into sub-shapes, all made of straight lines. Then they extended the shapes and sub-shapes into a third dimension and placed 3D points on the sub-shape boundaries to represent walls.
- The team adapted PointNet++, a neural net designed to process sets of points. For each point, the model predicted the 3D coordinates of the center of the wall it belonged to, the center of the room it belonged in, and the center of the adjoining room.
- The researchers used DBSCAN to cluster the predicted coordinates. Clustering allows for imprecision in the point locations, so the center of a room doesn’t appear to belong to different rooms in the floor plan.
- The company’s DeepPerimeter algorithm projects clusters that share rooms and walls onto a 2D plane to create a floor plan. Roughly speaking, DeepPerimeter draws lines between points in a wall cluster, merges those that overlap, and connects different walls.
Results: The team tested Scan2Plan on the Beijing Real Estate dataset. The network was over 100 times faster than the previous state of the art, Floor SP, while achieving better F1 scores for corners (0.915 versus 0.877) and walls (0.860 versus 0.788).
Yes, but: Much of Beijing Real Estate has been preprocessed to remove scanner noise. When noise was included, Floor SP achieved a better F1 score for corners, though similar results for walls and rooms.
Why it matters: Floor plans can help robots in tasks that require mapping their surroundings, such as localization. Although their performance is similar, Scan2Plan is much faster than Floor SP, producing floor plans in 4 seconds rather than 8 minutes.
We’re thinking: Standard supervised learning algorithms don’t have great ways to predict an arbitrary number of output classes, such as the number of rooms in a floor plan. Rather than try to predict a room’s identity directly (which is hard, because the world holds arbitrarily many rooms), this work predicted the location of the next room’s center. We continue to be impressed by the creativity of researchers working to fit supervised learning into larger systems.

Toward AI We Can Count On
A consortium of top AI experts proposed concrete steps to help machine learning engineers secure the public’s trust.
What’s new: Dozens of researchers and technologists recommended actions to counter public skepticism toward artificial intelligence, fueled by issues like data privacy and accidents caused by autonomous vehicles. The co-authors include scholars at universities like Cambridge and Stanford; researchers at companies including Intel, Google, and OpenAI; and representatives of nonprofits such as the Partnership on AI and Center for Security and Emerging Technology.
Recommendations: Lofty pronouncements about ethics aren’t enough, the authors declare. Like the airline industry, machine learning engineers must build an “infrastructure of technologies, norms, laws, and institutions” the public can depend on. The authors suggest 10 trust-building moves that fall into three categories.
- Institutional mechanisms such as third-party auditing to verify the accuracy of company claims and bounties to researchers who discover flaws in AI systems.
- Software mechanisms that make it easier to understand how a given algorithm works or capture information about a program’s development and deployment for subsequent auditing.
- Hardware mechanisms that protect data privacy, along with subsidies for computing power for academic researchers who may lack resources to evaluate what large-scale AI systems are doing.
Behind the news: The AI community is searching for ways to boost public trust amid rising worries about surveillance, the impact of automation on human labor, autonomous weapons, and computer-generated disinformation. Dozens of organizations have published their own principles, from Google and Microsoft to the European Commission and the Vatican. Even the U.S. Department of Defense published guidelines on using AI during warfare.
Why it matters: Widespread distrust in AI could undermine the great good this technology can do, frightening people away or prompting politicians to hamstring research and deployment.
We’re thinking: Setting clear standards and processes to verify claims about AI systems offers a path for regulators and users to demand evidence before they will trust an AI system. This document’s emphasis on auditing, explainability, and access to hardware makes a solid cornerstone for further efforts.