
Dear friends,
I spoke last week at the National Intergovernmental Audit Forum, a meeting attended by U.S. federal, state, and local government auditors. (Apparently some of the organizers had taken AI for Everyone.) Many attendees wanted to know how AI systems can be rolled out in a responsible and accountable way.
Consider the banking industry. Many regional banks are under tremendous competitive pressure. How well they assess risk directly affects their bottom line, so they turn to credit scoring systems from AI vendors. But if they don’t have the technical expertise to evaluate such models, a hasty rollout can lead to unintended consequences like unfairly charging higher interest rates on loans to minority groups.
For AI systems to enjoy smooth rollouts, we need to (a) make sure our systems perform well and pose minimal risk of unintended consequences and (b) build trust with customers, users, regulators, and the general public that these systems work as intended. These are hard problems. They require not just solving technical issues but also aligning technology with society’s values, and expectations.

An important part of the solution is transparency. The open source software movement has taught us that transparency makes software better. And if making source code publicly available means that someone finds an embarrassing security bug, so be it! At least it gets fixed.
With the rise of AI, we should similarly welcome third-party assistance, such as allowing independent parties to perform audits according to a well established procedure. That way, we can identify problems and fix them quickly and efficiently.
After my presentation, the moderator asked me how auditors can avoid getting into adversarial relationships with AI vendors. Instead, we need to build collaborative relationships. By collaborating, we can help make sure the criteria used to judge our systems is reasonable and well specified. For instance, what are the protected groups we need to make sure our systems aren’t biased against? We can also better avoid “gotcha” situations in which our systems are assessed according to arbitrary, after-the-fact criteria.
The AI community has a lot of work to do to ensure that our systems are fair, accountable, and reliable. For example, Credo AI (disclosure: a portfolio company of AI Fund, a sister organization to deeplearning.ai) is building tools that help audit and govern AI systems. Efforts like this can make a difference in designing and deploying AI systems that benefit all people.
Keep learning!
Andrew
News

AI Steps Up
A prosthetic leg that learns from the user’s motion could help amputees walk more naturally.
What’s new: Researchers from the University of Utah designed a robotic leg that uses machine learning to generate a human-like stride. It also helps wearers step over obstacles in a natural way.
How it works: Rather than trying to recognize obstacles in the user’s path, the prosthesis relies on cues from the user’s body to tell it when something is in the way. Sensors in the user’s hip feed data a thousand times per second into a processing unit located in the unit’s calf. For instance, the way a user rotates their hip might tell the leg to tuck its knee to avoid tripping over an obstacle.
- A finite state machine (a logic-based controller) determines when and how to flex the knee based on angles of the ankle and thigh and the weight on the prosthetic foot.
- A second model called the minimum-jerk planner kicks in when the angle and speed of the artificial limb reach a certain point. It works to minimize sharp, sudden actions.
- The prosthesis applies reinforcement learning to adjust its motion as the user walks, using smoothness as the cost function.
Behind the news: A new generation of AI-powered prosthetics could give amputees more control over robotic limbs.
- Researchers from the University of Michigan developed an open-source bionic leg that extrapolates knee and ankle movements by analyzing the wearer’s hip muscles, similar to the University of Utah’s method.
- A pair of Canadian students won Microsoft’s 2018 Imagine Cup with a camera-equipped prosthetic hand that uses computer vision to detect objects it is about to grasp and adjusts its grip accordingly.
- A mechanical arm from École polytechnique fédérale de Lausanne learns to associate common movements with cues from the user’s muscles.
Why it matters: Battery-powered prostheses allow amputees to walk more easily, but they tend to stumble on unfamiliar terrain. This smart leg could provide them with smooth, hazard-free perambulation.
We’re thinking: AI is helping people with the most basic human functions as well as the most abstract scientific problems.

Transforming Pixels
Language models like Bert, Ernie, and Elmo have achieved spectacular results based on clever pre-training approaches. New research applies some of those Sesame Street lessons into image processing.
What’s new: OpenAI researchers led by Mark Chen adapted to pixels techniques developed for processing words in Image Generative Pre-Training (iGPT).
Key insight: Language models based on the transformer architecture learn to predict the next word, or missing words, in text by unsupervised pre-training on an enormous corpus followed by supervised fine-tuning. The same approach can train models to predict the next pixel in an image.
How it works: iGPT uses the GPT-2 architecture that made waves in natural language processing. However, it learns from sequences of pixels instead of sequences of words.
- The researchers preprocessed images by flattening them into one-dimensional vectors.
- The researchers trained iGPT to either predict the next pixel in a sequence (an autoregressive task) or predict a group of pixels missing from a sequence (which they call Bert).
- Pre-trained NLP models often are fine-tuned on a supervised task such as question answering. Similarly, the researchers fine-tuned iGPT on image classification. They found that hiding pixels from the model during fine-tuning improved performance.
- The researchers provided all intermediate-layer features and labels to a new output layer, but trained only that layer’s parameters.
Results: Using features extracted by the intermediate layers in the autoregressive task, iGPT achieved 72 percent accuracy on ImageNet, just behind the state-of-the-art 76.5 percent achieved by SimCLR, a popular unsupervised approach. iGPT outperformed SimCLR when fine-tuned and evaluated on the CIFAR datasets.
Yes, but: The researchers had to downsample ImageNet examples to about 7 percent of their original size to accommodate GPT-2. They suspect that iGPT would stack up better against SimCLR if it could accept larger images.
Why it matters: iGPT isn’t a convolutional neural network. It doesn’t even use the convolutional filter that’s fundamental to current image processing methods. This work shows the value of applying architectures proven in one domain to others.
We’re thinking: We’ve been encouraged by the progress in self-supervised learning using methods like Contrastive Predictive Coding and variations thereof, in which a neural network is trained on a supervised learning task that is created from unlabeled data. iGPT appears to be a new line of attack on this problem.
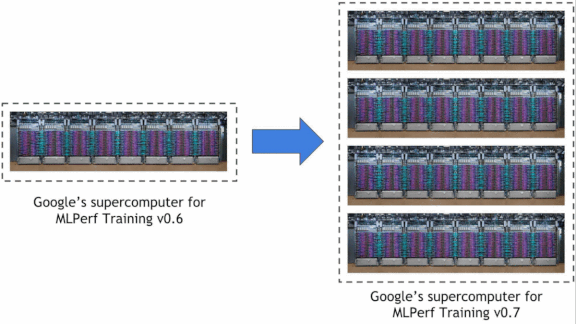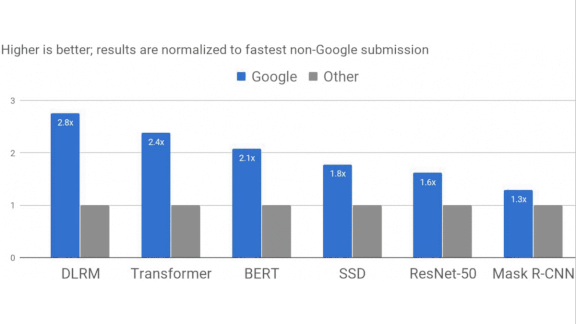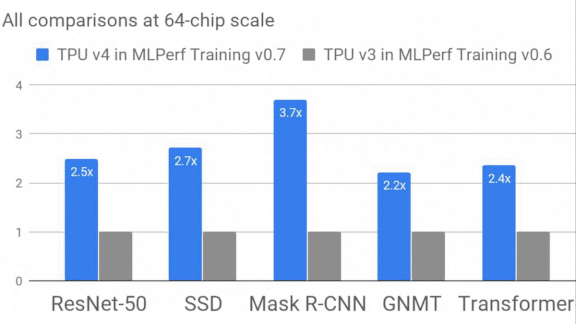
Built for Speed
Chips specially designed for AI are becoming much faster at training neural networks, judging from recent trials.
What’s new: MLPerf, an organization that’s developing standards for hardware performance in machine learning tasks, released results from its third benchmark competition. Nvidia’s latest products led the pack, but Google’s forthcoming hardware surpassed Nvidia’s scores.
Start your engines: MLPerf measures how long it takes various hardware configurations to train particular machine learning models. Tasks include object detection, image classification, language translation, recommendation, and reinforcement learning goals.
- Systems from nine organizations trained models 2.7 times faster, on average, than they did in tests conducted last November, demonstrating the rapid evolution of AI hardware (and enabling software such as compilers).
- Nvidia submitted 40 different configurations. Those based on its A100 graphics processing unit (GPU) scored highest among commercially available systems.
- Showing off capabilities that aren’t yet on the market, Google dominated six of the eight tasks with its fourth-generation tensor processing unit (TPU). Earlier versions are available via the Google Cloud platform.
- Alibaba, Fujitsu, Intel, Inspur, Shenzhen Institute, and Tencent also joined the competition. Conspicuously absent: AI hardware upstarts Cerebras and Graphcore (see “New Horsepower for Neural Nets” below).
Behind the news: Nvidia’s GPUs have long been the premier machine learning chips, thanks to their ability to process large volumes of floating point integers per second. But startups including Cerebras, Graphcore, and Habana (acquired by Intel in December) are vying for that position, and Google Cloud is making a strong play for AI workloads.
Why it matters: It’s good to be past the era of Mythbusters videos as a way to compare AI hardware. Machine learning engineers benefit from faster, more energy-efficient hardware systems, but we need clear, consistent metrics like MLPerf to evaluate hardware performance with particular models.
We’re thinking: Since MLPerf’s first tests two years ago, the time required to train some models has plummeted from hours to seconds. Clearly semiconductor companies have been chipping away at the problem.
A MESSAGE FROM DEEPLEARNING.AI
Course 3 of our Natural Language Processing Specialization is now live on Coursera. Enroll today to gain in-demand technical skills! Course 4 is scheduled for release in September.
Cats Cured of Covid
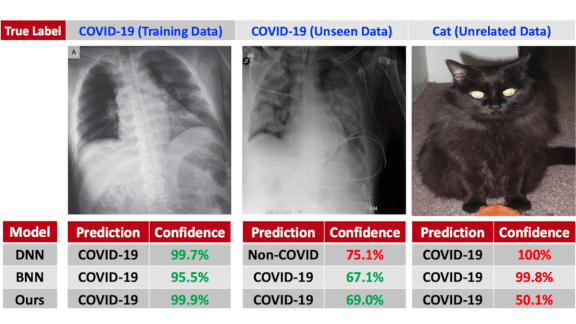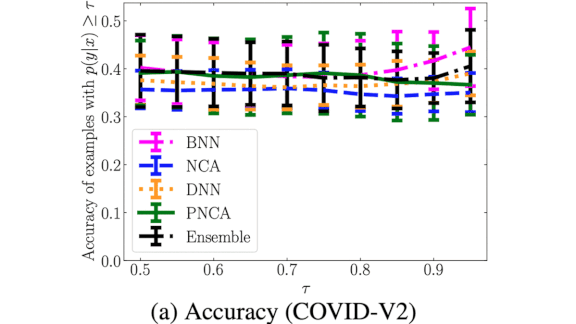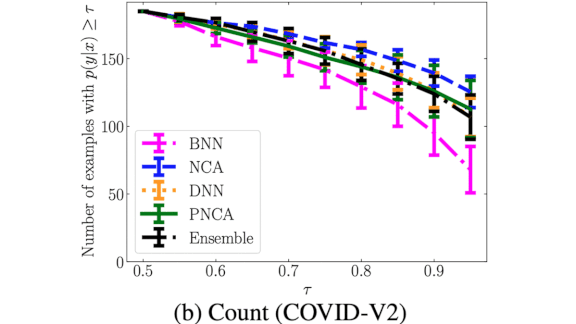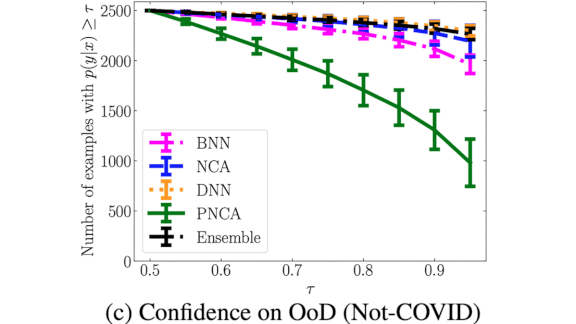
Neural networks are famously bad at interpreting input that falls outside the training set’s distribution, so it’s not surprising that some models are certain that cat pictures show symptoms of Covid-19. A new approach won’t mistakenly condemn your feline to a quarantine.
What’s new: Led by Ankur Mallick, researchers at Carnegie Mellon and Lawrence Livermore National Lab developed Probabilistic Neighborhood Components Analysis (PNCA) to help models estimate the confidence of their predictions.
Key insight: Neural networks often show high confidence in predictions that are clearly incorrect — a major issue in areas like healthcare and criminal justice. The problem can fade with enough training data, but it’s pervasive where training data is scarce. Overfitting limited data contributes to overconfidence, so combining deep learning with probabilistic methods, which are less prone to overfitting, might alleviate overconfidence.
How it works: PNCA is a probabilistic version of Neighborhood Component Analysis. NCA is a supervised learning method that trains neural nets to extract features that cluster examples of the same class. NCA determines the class of novel input by computing the distance between training data features and input features. It takes the softmax of the distances to obtain the probability that each training example belongs to the same class of the novel input. Practically speaking, NCA is a classification network with fixed output layer weights, but not size, given by the distance function.
- PNCA borrows ideas from deep Bayesian networks, which interpret inputs, weights, extracted features, neighborhoods, and class predictions as samples of probability distributions. The use of probability distributions allows PNCA to sharpen its confidence by computing the probability that a particular classification would occur with the provided input.
- The technique estimates the distribution of predicted classes by sampling weights from the weight distribution. Every pair of sampled weights and training examples determines a distinct extracted feature, so running the usual NCA on every pair yields a classification that depends on the weight distribution.
- PNCA determines the entire weight distribution by maintaining a sample of weights. Then it trains the sample of weights to generate a sample of predictions to match the training data, updating the weights to minimize the NCA loss.
Results: The researchers trained PNCA on a Kaggle dataset of chest x-rays showing Covid-19, and tested it on Covid-V2 and a Cats and Dogs dataset. PNCA performed with similar accuracy to other deep learning approaches on Covid-V2, while incorrectly classifying 1,000 cats and dogs out of 25,000 as Covid-19 with high confidence. This may seem like poor performance, but the same architecture with a standard supervised learning objective mistook around 2500 cats and dogs as Covid-19 chest x-rays.
Why it matters: Deep learning’s overconfidence and data hunger are limitations to their practical deployment. PNCA combines deep learning’s powerful feature extraction with a probabilistic ability to quantify uncertainty.
We’re thinking: We’re waiting for a model that can tell us the condition of Schroedinger’s cat.

New Horsepower for Neural Nets
A high-profile semiconductor startup made a bid for the future of AI computation.
What’s new: UK startup Graphcore released the Colossus Mk2, a processor intended to perform the matrix math calculations at the heart of deep learning more efficiently than other specialized processors or general-purpose chips from Intel and AMD. The company expects to be shipping at full volume in the fourth quarter.
How it works: The Mk2 comprises nearly 60 billion transistors. (Nvidia’s flagship A100 has 54 billion, while Cerebras’ gargantuan Wafer-Scale Engine boasts 1.2 trillion. Google doesn’t advertise its TPU transistor counts.) Girded by 900 megabytes of random access memory, the Mk2’s transistors are organized into 1,500 independent cores capable of running nearly 9,000 parallel threads.
- Graphcore is selling the new chips as part of a platform called IPU-Machine M200. Each M200 will hold four Mk2 chips to deliver a combined computational punch of 1 petaflop, or 1015 floating point operations per second.
- Each M200 can connect to up to 64,000 others for 16 exaflops of compute. (An exaflop is 1,000 petaflops.) That’s a hefty claim, given that competing systems have yet to reach 1 exaflop.
- The package includes software designed to manage a variety of machine learning frameworks. Developers can code directly using Python and C++.
- J.P. Morgan, Lawrence Berkeley National Laboratory, and the University of Oxford are among the first users of the new chip.
Why it matters: AI’s demand for computational resources is insatiable. A recent study from researchers at MIT, the University of Brasilia, and Yonsei University suggests that progress in deep learning could stall for lack of processing power. Innovations in chip technology may make a difference.
We’re thinking: The fact that software evolves faster than hardware is a major challenge to building chips. Graphcore’s design is geared to accelerate large, sparse recurrent neural networks at a moment when transformer networks are beginning to supplant RNNs in some applications. Will some bold chip maker tune its next generation for transformers?