
Dear friends,
In school, most questions have only one right answer. But elsewhere, decisions often come down to a difficult choice among imperfect options. I’d like to share with you some approaches that have helped me make such decisions.
When I was deciding where to set up a satellite office outside the U.S., there were many options. My team and I started by listing important criteria such as supply of talent, availability of local partners, safety and rule of law, availability of visas, and cost. Then we evaluated different options against these criteria and built a matrix with cities along one axis and our criteria along the other. That clarified which country would make a great choice.
When I feel stuck, I find it helpful to write out my thoughts:
- What options am I choosing among?
- What criteria are driving the choice?
- How does each option rate with respect to the criteria?
- if I need more information, how can I get it?

Documenting decisions in this way also builds a foundation for further choices. For example, over the years, I’ve collected training data for many different kinds of problems. When I need to select among tactics for acquiring data, having been through the process many times, I know that some of the most important criteria are (i) the time needed, (ii) the number of examples, (iii) accuracy of the labels, (iv) how representative the input distribution is, and (v) cost.
If I’m making a decision as part of a team, I check with teammates at each step to make sure we’re accurately capturing the top options, criteria, and so on. (The comments feature in Google Docs is a great way to facilitate open debate within a team.) This helps me avoid losing track of some criteria and acting based on an incomplete set; for example, picking the satellite office’s location based only on the availability of talent. It also helps align everyone on the final decision.
As you may know, I wound up setting up a satellite office in Colombia because of the availability of talent and a supportive ecosystem of partners. The team there has become a key part of many projects. Lately I’ve worried about their wellbeing amid Covid-19 and widespread unrest. But in hindsight, setting up in Colombia was one of my best decisions, and I remain as committed as ever to supporting my friends there.
Keep learning!
Andrew
News

Deadly Drones Act Alone
Autonomous weapons are often viewed as an alarming potential consequence of advances in AI — but they may already have been used in combat.
What’s new: Libyan forces unleashed armed drones capable of choosing their own targets against a breakaway rebel faction last year, said a recent United Nations (UN) report. The document, a letter from the organization’s Panel of Experts on Libya to the president of the Security Council, does not specify whether the drones targeted, attacked, or killed anyone. It was brought to light by New Scientist.
Killer robots: In March of 2020, amid Libya’s ongoing civil war, the UN-supported Government of National Accord allegedly attacked retreating rebel forces using Kargu-2 quadcopters manufactured by Turkish company STM.
- The fliers are equipped with object-detection and face-recognition algorithms to find and strike targets without explicit human direction.
- Upon acquiring a target, the drone flies directly at it and detonates a small warhead just before impact.
- STM claims that its systems can distinguish soldiers from civilians.
- The Turkish military bought at least 500 such units for use in its border conflict with Syria. STM is negotiating sales to three other nations, according to Forbes.
Behind the news: Many nations use machine learning in their armed forces, usually to bolster existing systems, typically with a human in the loop.
- In the most recent battle between Israel and Palestinians in Gaza, the Israeli Defense Force deployed machine learning systems that analyzed streams of incoming intelligence. The analysis helped its air force identify targets and warn ground troops about incoming attacks.
- The U.S. Army is testing a drone that uses computer vision to identify targets up to a kilometer away and determine whether they’re armed.
- The European Union has funded several AI-powered military projects including explosive device detection and small unmanned ground vehicles that follow foot soldiers through rough terrain.
Why it matters: Observers have long warned that deploying lethal autonomous weapons on the battlefield could ignite an arms race of deadly machines that decide for themselves who to kill. Assuming the UN report is accurate, the skirmish in Libya appears to have set a precedent.
We’re thinking: Considering the problems that have emerged in using today’s AI for critical processes like deploying police, sentencing convicts, and making loans, it’s clear that the technology simply should not be used to make life-and-death decisions. We urge all nations and the UN to develop rules to ensure that the world never sees a real AI war.
One Model for Vision-Language
Researchers have proposed task-agnostic architectures for image classification tasks and language tasks. New work proposes a single architecture for vision-language tasks.
What’s new: Led by Tanmay Gupta, researchers at the Allen Institute for AI and University of Illinois at Urbana-Champaign designed a general-purpose vision architecture and built a system, GPV-I, that can perform visual question answering, image captioning, object localization, and image classification.
Key insight: Model architectures usually are designed for specific tasks, which implies certain types of output. To classify ImageNet, for instance, you need 1,000 outputs, one for each class. But text can describe both tasks and outputs. Take classification: the task “Describe this image” leads to the output, “this image is a dog.” By generating a representation of text that describes a task, a model can learn to perform a variety of tasks and output text that completes it without task-specific alterations in its architecture.
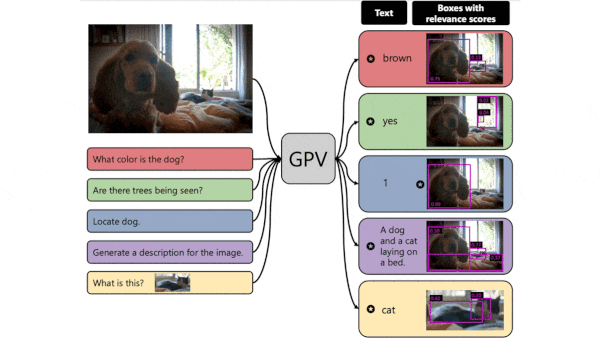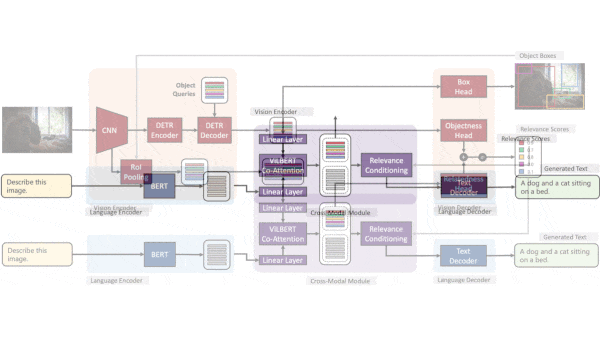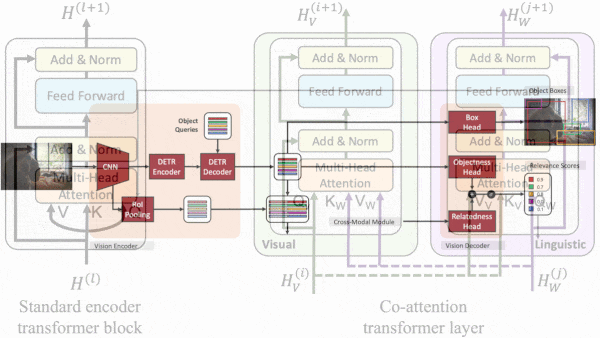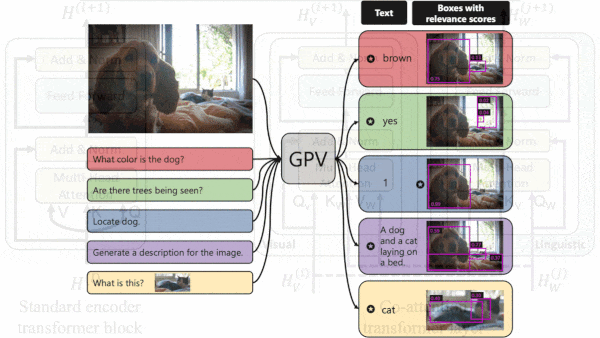
How it works: Given a text description of a task — say, “describe the image” — and an image, GPV-I generates separate representations of the text and image, determines their relative importance to one another, and outputs a relevant text response and a copy of the image with bounding boxes. The authors trained it on COCO image captioning, VQA question answering, and RefCOCO+ object localization datasets.
- The system uses BERT to produce a representation of the task. It extracts an initial image representation using a ResNet-50 and passes it to a transformer borrowed from DETR. The transformer splits the representation into a grid, each cell of which contains a representation for the corresponding location in the image.
- A so-called cross-modal module accepts the representations of the image (one for each grid cell) and text (that is, the task) and produces new ones that reflect their relationship. It uses co-attention between transformer layers to compare image and text representations and a sigmoid layer to compute the relevance of the image representations to the task. Then it weights each image representation by its relevance.
- An image decoder uses the DETR representations to generate a bounding box for each object detected and the relevance scores to select which boxes to draw over the image. The text decoder (a transformer) uses the BERT representations and weighted representations to generate text output.
Results: The researchers evaluated GPV-I on COCO classification, COCO captioning, and VQA question answering. They compared its performance with models trained for those tasks. On classification, GPV-I achieved accuracy of 83.6 percent, while a ResNet-50 achieved 83.3 percent. On captioning, GPV-I achieved 1.023 CIDEr-D — a measure of the similarity of generated and ground-truth captions, higher is better — compared to a VLP’s 0.961 CIDEr-D. On question answering, GPV-I achieved 62.5 percent accuracy compared to ViLBERT’s score of 60.1 percent, based on the output’s similarity to a human answer.
Why it matters: A single architecture that can learn several tasks should be able to share concepts between tasks. For example, a model trained both to detect iguanas in images and to answer questions about other topics might be able to describe what these creatures look like even if they weren’t represented in the question-answering portion of the training data.
We’re thinking: Visual classification, image captioning, and visual questioning answering are a start. We look forward to seeing how this approach performs on more varied tasks.
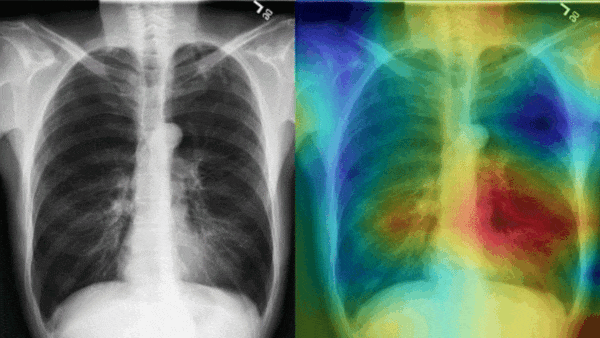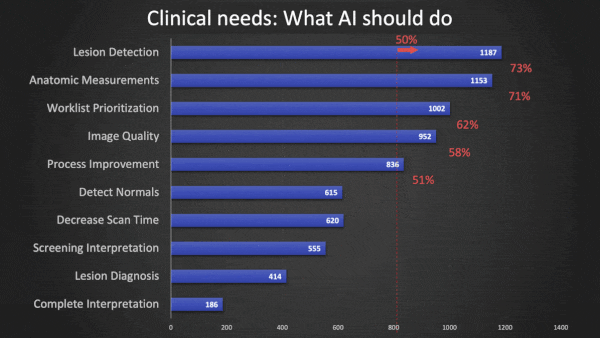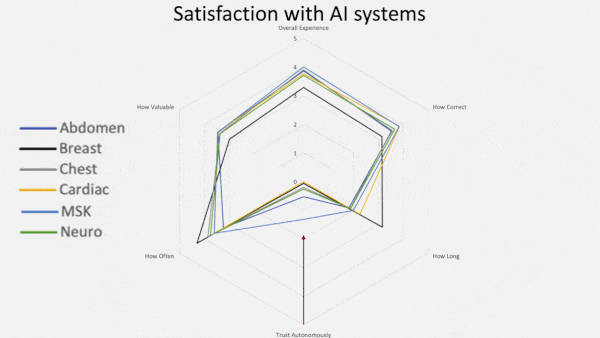
Radiologists Eye AI
AI lately has achieved dazzling success interpreting X-rays and other medical imagery in the lab. Now it’s catching on in the clinic.
What’s new: Roughly one-third of U.S. radiologists use AI in some form in their work, according to a survey by the American College of Radiology. One caveat: Many who responded positively may use older — and questionable — computer-aided detection, a technique for diagnosing breast cancer that dates to the 1980s, rather than newer methods.
What they found: The organization queried its membership via email and received 1,861 responses.
- Of respondents who said they use AI, just over half use it to interpret images, and another 11 percent for image enhancement. The most common applications were breast (45.7 percent), thoracic (36.2 percent), and neurological (30.1 percent) imaging.
- 12 percent of AI users said they use the technology to manage work lists, 11 percent to manage operations.
- Nearly 10 percent of AI users built their own algorithms rather than buying from outside vendors.
- 94 percent of AI users said their systems perform inconsistently. Around 6 percent said they always work, and 2 percent said they never work.
- More than two thirds of respondents said they don’t use AI, and 80 percent of those said they see no benefit in it. Many believe that the technology is too expensive to implement, would hamper productivity, or wouldn’t be reimbursed.
Behind the news: AI’s role in medical imaging is still taking shape, as detailed by Stanford radiology professor Curtis Langlotz in the journal Radiology: Artificial Intelligence. In 2016, a prominent oncologist wrote in the New England Journal of Medicine, “machine learning will displace much of the work of radiologists.” Two years later, Harvard Business Review published a doctor-penned essay headlined, “AI Will Change Radiology, but It Won’t Replace Radiologists.” Radiology Business recently asked, “Will AI replace radiologists?” and concluded, “Yes. No. Maybe. It depends.”
Why it matters: AI’s recent progress in medical imaging is impressive. Although the reported 30 percent penetration rate probably includes approaches that have been uses for decades, radiologists are on their way to realizing the technology’s promise.
We’re thinking: One-third down, two-thirds to go! Machine learning engineers can use such findings to understand what radiologists need and develop better systems for them.
A MESSAGE FROM DEEPLEARNING.AI

We’re proud to launch Practical Data Science, in partnership with Amazon Web Services (AWS)! This new specialization will help you develop the practical skills to deploy data science projects effectively and overcome machine learning challenges using Amazon SageMaker. Enroll now

Tesla All-In For Computer Vision
Tesla is abandoning radar in favor of a self-driving system that relies entirely on cameras.
What’s new: The electric car maker announced it will no longer include radar sensors on Model 3 sedans and Model Y compact SUVs sold in North America. Tesla is the only major manufacturer of autonomous vehicles to bet solely on computer vision. Most others rely on a combination of lidar, radar, and cameras.
How it works: Tesla has dropped radar only in the U.S. and only in its two most popular models. It aims to gather data and refine the technology before making the change in Model S, Model X, and vehicles sold outside the U.S.
- The eight-camera system called Tesla Vision will provide sensory input for Autopilot driver-assistance features such as lane controls as well as the Full Self-Driving upgrade, which automatically parks and summons vehicles, slows for stop signals, and automates highway driving. Such features will be “limited or inactive” during the transition.
- The move comes on the heels of earlier statements that touted cameras. “When radar and vision disagree, which one do you believe?” Musk said in a tweet on April 10. “Vision has much more precision, so better to double down on vision than do sensor fusion.”
- CEO Elon Musk predicted that Tesla Vision would help the company’s vehicles achieve full autonomy by the end of 2021. (Musk has a history of declaring ambitious goals his company has failed to meet.)
Behind the news: Some people in the self-driving car industry favor using relatively expensive lidar and radar sensors in addition to low-cost cameras because they provide more information and thus greater safety. Camera-only advocates counter that humans can drive safely perceiving only images, so we should build AI that does the same. Most companies working on autonomous vehicles have chosen the more expensive route as the fastest way to reach full autonomy safely. Once they get there, the thinking goes, they can attend to bringing the cost down.
Why it matters: If Tesla’s bet on cameras pays off, it could have an outsize influence on future self-driving technology.
We’re thinking: While it’s great to see ambitious plans to commercialize computer vision, Tesla’s initiative will require tests on public streets. That means countless drivers will be the company’s unwitting test subjects — a situation that, as ever, demands strong oversight by road-safety authorities.
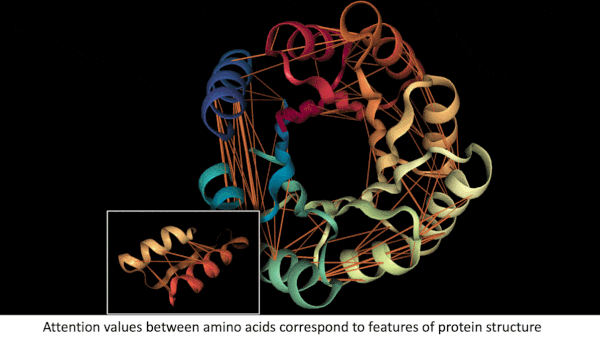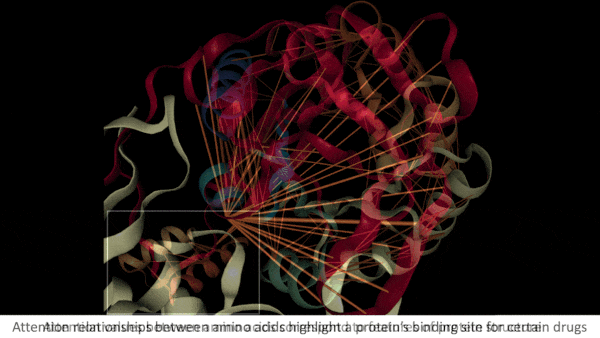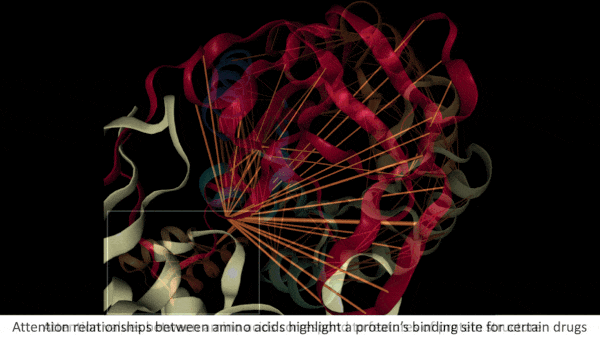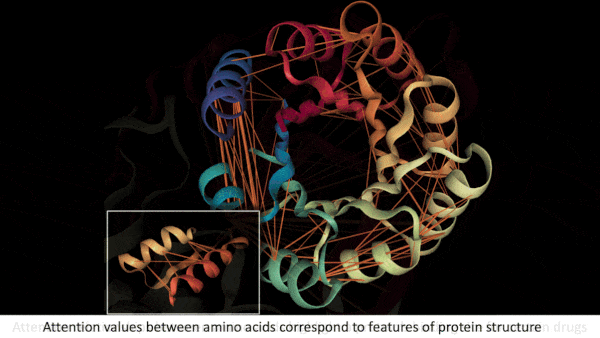
What AI Knows About Proteins
Transformer models trained on sequences of amino acids that form proteins have had success classifying and generating viable sequences. New research shows that they also capture information about protein structure.
What’s new: Transformers can encode the grammar of amino acids in a sequence the same way they do the grammar of words in a language. Jesse Vig and colleagues at Salesforce Research and University of Illinois at Urbana-Champaign developed methods to interpret such models that reveal biologically relevant properties.
Key insight: When amino acids bind to one another, the sequence folds into a shape that determines the resulting protein’s biological functions. In a transformer trained on such sequences, a high self-attention value between two amino acids can indicate that they play a significant role in the protein’s structure. For instance, the protein’s folds may bring them into contact.
How it works: The authors studied a BERT pretrained on a database of amino acid sequences to predict masked amino acids based on others in the sequence. Given a sequence, they studied the self-attention values in each layer of the model.
- For each sequence in the dataset, the authors filtered out self-attention values below a threshold to find amino acid pairs with strong relationships. Consulting information in the database, they tallied the number of relationships associated with a given property of the protein’s shape (for example, pairs of amino acids in contact).
- Some properties depended on only one amino acid in a pair. For example, an amino acid may be part of the protein site that binds to molecules such as drugs. (The authors counted such relationships if the second amino acid had the property in question.)
Results: The authors compared their model’s findings with those reported in other protein databases. The deeper layers of the model showed an increasing proportion of related pairs in which the amino acids actually were in contact, up to 44.7 percent, while the proportion of all amino acids in contact was 1.3 percent. The chance that the second amino acid in a related pair was part of a binding site didn’t rise steadily across layers, but it reached 48.2 percent, compared to a 4.8 percent chance that any amino acid was part of a binding site.
Why it matters: A transformer model trained only to predict missing amino acids in a sequence learned important things about how amino acids form a larger structure. Interpreting self-attention values reveals not only how a model works but also how nature works.
We’re thinking: Such tools might provide insight into the structure of viral proteins, helping biologists discover ways to fight viruses including SARS-CoV-2 more effectively.
A MESSAGE FROM DEEPLEARNING.AI

Join us for a live virtual event on June 9, 2021! Experts from Omdena will walk through two AI case studies: “Real Life: Understanding the Causes and Effects of Student Debt through Machine Learning” and “AI for Energy: Transitioning Toward a Sustainable Energy System.”