
Dear friends,
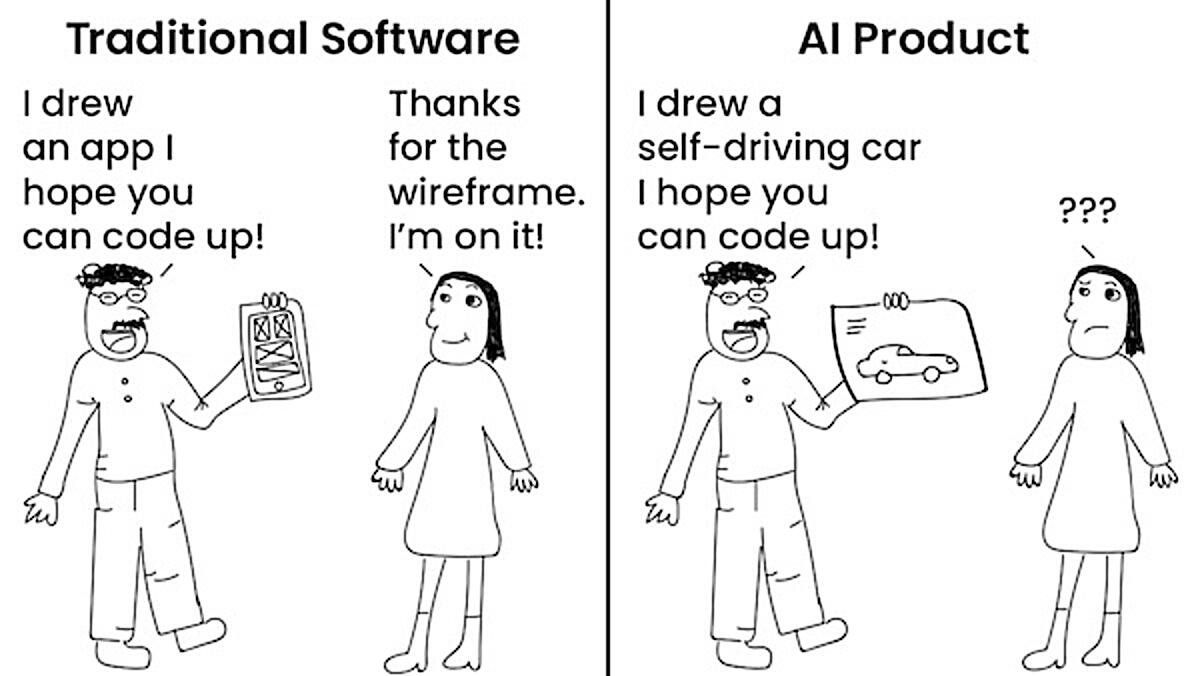
In a recent letter, I noted that one difference between building traditional software and AI products is the problem of complex product specification. With traditional software, product managers can specify a product in ways that communicate clearly to engineers what to build — for example, by providing a wireframe drawing. But these methods don’t work for AI products.
For an AI product, among the most important parts of the specification are:
- The space of acceptable operating conditions (also called the operational design domain)
- The level of performance required under various conditions, including machine learning metrics such as accuracy and software metrics such as latency and throughput
Consider the problem of how to build a self-driving car. We might decide the acceptable road conditions for autonomous operation and the acceptable rate of collisions with particular objects at various speeds (for example, gently bumping a traffic cone at five miles per hour every 1 million miles may be okay, but hitting a pedestrian at 20 miles per hour every 1,000 miles is not).
Or take reading electronic health records. What is an acceptable error rate when diagnosing a serious disease? How about the error rate when diagnosing a minor disease? What if human-level performance for a particular illness is low, so physicians tend to misdiagnose it, too?
Specifying the metrics, and the dataset or data distribution on which the metrics are to be assessed, gives machine learning teams a target to aim for. In this process, we might decide how to define a serious versus a minor disease and whether these are even appropriate concepts to define a product around. Engineers find it convenient to optimize a single metric (such as average test-set accuracy), but it’s not unusual for a practical specification to require optimizing multiple metrics.
Here are some ideas that I have found useful for specifying AI products.
- Clearly define slices (or subsets) of data that raise concerns about the system’s performance. One slice might be minor diseases and another major diseases. If the system is intended to make predictions tied to individuals, we might check for undesirable biases by specifying slices that correspond to users of different age groups, genders, ethnicities, and so on.
- For each slice, specify a level of performance that meets the user’s need, if it’s technically feasible. Also, examine performance across slices to ensure that the system meets reasonable standards of fairness.
- If the algorithm performs poorly on one slice, it may not be fruitful to tweak the code. Consider using a data-centric approach to improve the quality of data in that slice. Often this is the most efficient way to address the problem.
I’ve found it very helpful to have sufficient data and a clear target specification for each slice. This isn’t always easy or even possible, but it helps the team advance toward a reasonable target.
As a team performs experiments and develops a sense of what’s possible as well as where the system might falter, the appropriate slices can change. If you’re a machine learning engineer who is part-way through the project, and the product manager changes the product specification, don’t be frustrated! Ask them to buy you a coffee (or tea or other beverage of your choice) for your trouble, but recognize that this is part of developing a machine learning system. Hopefully such changes will happen less frequently as the team gains experience.
Keep learning!
Andrew
News
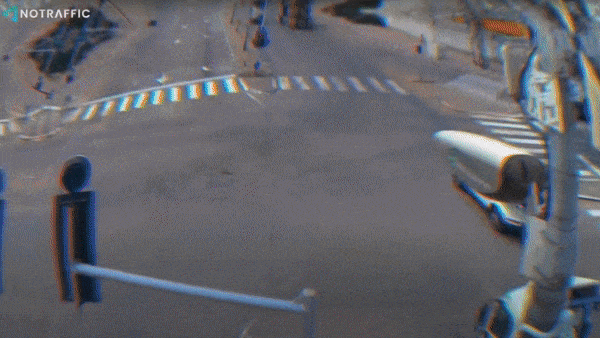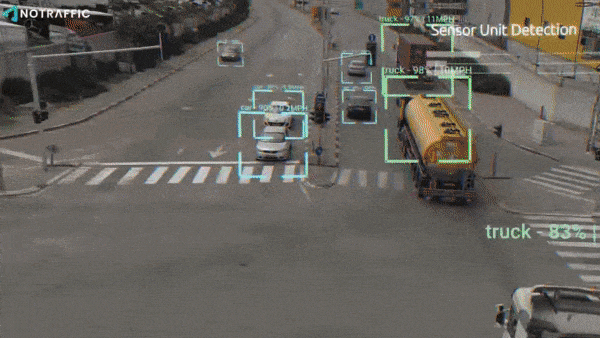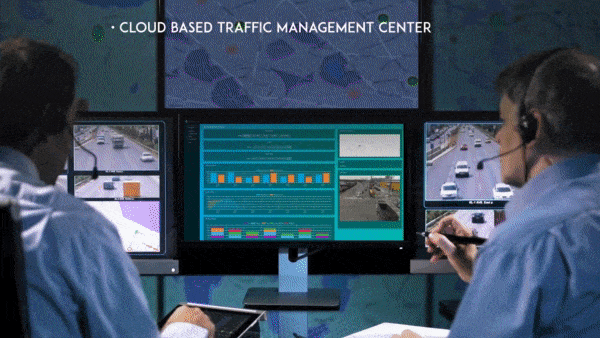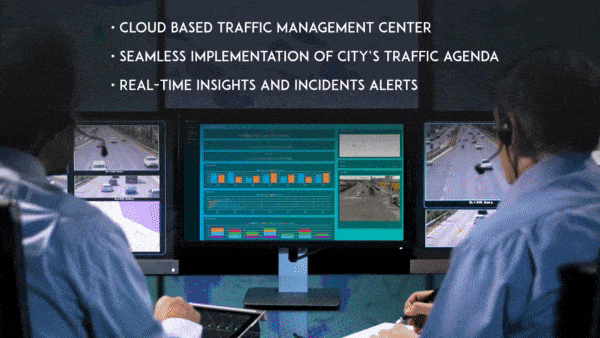
Lighter Traffic Ahead
Traffic signals controlled by AI are keeping vehicles rolling citywide.
What’s new: Several U.S. cities are testing systems from Israel-based startup NoTraffic that promise to cut both commute times and carbon emissions, according to MotorTrend. The company plans to expand to 41 cities by the end of 2021.
How it works: NoTraffic uses a combination of neural networks and other techniques to optimize intersections and coordinate traffic signals throughout a city. The system is outfitted to integrate with pavement sensors and connected-vehicle protocols.
- Cameras installed at intersections run models that detect and classify oncoming vehicles, bikes, and pedestrians, and calculate their speed and location.
- They stream anonymized data to control modules housed in traffic signals, which aggregate the sensor outputs and optimize signal operation. For instance, the system can turn a green light red if there are no cars coming, or change a red light to green as an emergency vehicle approaches.
- The data is streamed to the cloud for optimization over larger areas and transmitted back to control modules to account for broader traffic patterns. For example, the system can coordinate multiple lights to reroute traffic around a road that has been closed due to an accident.
- In a two month trial, Redlands, CA, found that installing the systems in 2 percent of intersections spared commuters a total of 900 hours of gridlock, which translated to an extra $331,380 in economic productivity.
- The Redlands trial also staved off 11 tons of greenhouse gas emissions. The company estimates that installing its technology in every traffic signal in the U.S. would forestall the equivalent of 20 million vehicles’ worth of exhaust annually.
Behind the news: Machine learning is combating congestion outside the U.S. as well.
- Delhi deployed its own AI-powered traffic signal network at over 7,500 intersections.
- At least 23 cities in China and Malaysia use Alibaba’s CityBrain to control gridlock.
Why it matters: Worldwide, congestion costs hundreds of billions of dollars in annual productivity, pollutes cities, and burdens the planet with greenhouse gases. AI-driven traffic control doesn’t eliminate those impacts, but it can take the edge off.
We’re thinking: Many traffic lights already are geared to prioritize passage of emergency vehicles, for example by recognizing patterns of flashing lights — but networked sensors stand to improve traffic routing globally.
Behavioral Cloning Shootout
Neural networks have learned to play video games like Dota 2 via reinforcement learning by playing for the equivalent of thousands of years (compressed into far less time). In new work, an automated player learned not by playing for millennia but by watching a few days’ worth of recorded gameplay.
What’s new: Tim Pearce and Jun Zhu at Cambridge University trained an autonomous agent via supervised learning to play the first-person shooter Counter Strike: Global Offensive (CS:GO) by analyzing pixels. The model reached an intermediate level of skill. Check out a video presentation here.
Key insight: Reinforcement learning can be used to teach neural networks to play games that include a programming interface, which enables the model to explore all possible game states because gameplay proceeds much faster than real time. CS:GO lacks such an interface. An alternative is to learn from expert demonstrations, a technique known as behavioral cloning. Where such demonstrations are hard to collect, publicly broadcast matches can stand in.
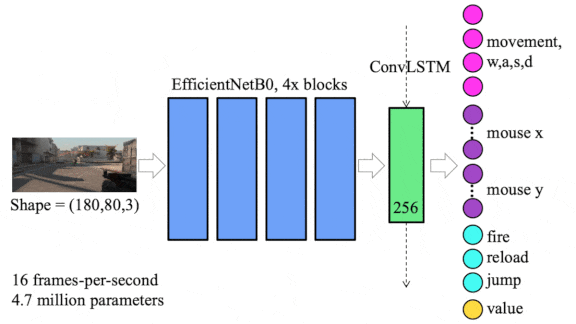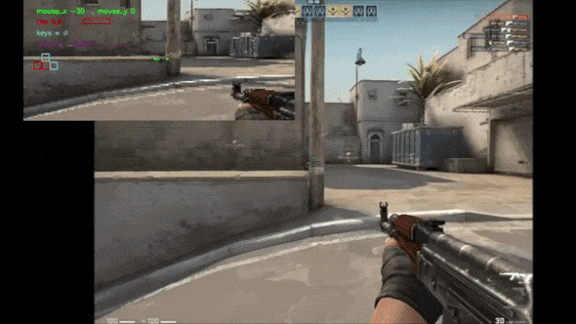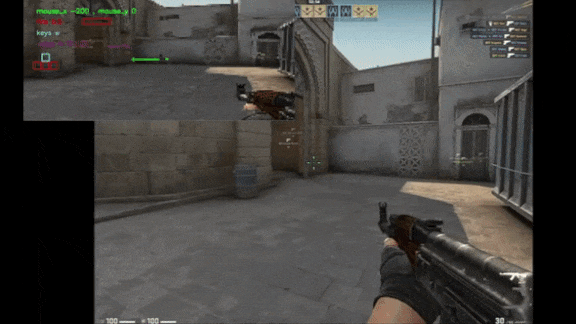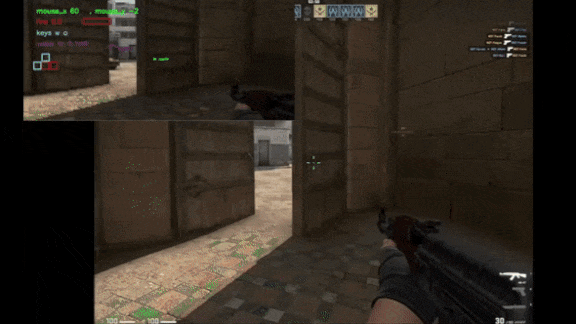
How it works: The system generated a representation of each video frame using a convolutional neural network and combined multiple representations using a convolutional LSTM. A linear layer decided what action to take per frame.
- The authors pretrained the system on 70 hours (4 million frames) of broadcast matches that pitted one team against another. They used handcrafted rules to label the frames with a player’s action: moving forward or backward, shooting, reloading, or changing the field of view.
- They fine-tuned the system on four hours (200,000 frames) of gameplay by a player who ranked in the Top 10 percent worldwide. They labeled this data using mouse and keyboard input to label the player’s action.
- During training, the system learned to minimize the difference between the predicted and recorded actions.
- At inference, the system chose how to move its onscreen character (for example, forward) and where to move the mouse cursor (which controls what the character can see) according to the model’s highest-probability prediction. It executed actions like shooting or reloading if the action’s probability was greater than a randomly generated number.
Results: Pitted against the game’s built-in medium-difficulty agent, which takes advantage of information that humans don’t have access to (such as the positions of all players), the author’s system came out on top. It achieved 2.67 kills per minute and 1.25 kills per death, compared to the built-in agent’s 1.97 kills per minute and 1.00 kills per death. Against human players in the top 10 percent, it didn’t fare so well. It achieved 0.5 kills per minute and 0.26 kills per death compared to the human average of 4.27 kills per minute and 2.34 kills per death
Why it matters: Behavioral cloning is a viable alternative to reinforcement learning — within the limits of available expert demonstrations. The authors’ system even learned the classic gamer swagger of jumping and spinning while it reloaded.
We’re thinking: We’re in the mood for a nonviolent round of Splatoon.
A MESSAGE FROM DEEPLEARNING.AI

Learn how to automate a natural language processing task in “Build, Train, and Deploy ML Pipelines Using BERT,” Course 2 in our new Practical Data Science Specialization. You'll build an end-to-end pipeline using Hugging Face’s optimized implementation of the state-of-the-art BERT algorithm using Amazon SageMaker Pipelines. Enroll now
Home Sweet AI-Appraised Home
Real estate websites helped turn automated real-estate assessment into a classic AI problem. The latest approach by a leader in the field gets a boost from deep learning.
What’s new: Zillow developed a neural network that predicts the value of homes across the United States. The system narrowed the error between earlier estimates and actual selling prices by 1 percent, achieving a median error rate of 6.9 percent. In addition to making it available online, Zillow plans to use it to improve its own real estate business.
How it works: Zillow’s Zestimate system previously employed roughly 1,000 separate non-machine-learning algorithms, each tailored to a different local market. The new network estimates the value of 104 million dwellings nationwide, updated as frequently as daily.
- A global model can outperform an ensemble of local models because home sales are sparse in any given area, a Zillow representative told The Batch.
- The architecture incorporates convolutional and fully connected layers that enable it to learn local patterns while scaling to a national level. Inputs include square footage, lot size, number of rooms, vintage, location, tax assessments, prior prices, days on the market, sizes of nearby homes, and proximity to a waterfront.
- Zestimate also incorporates earlier models, such as a vision system that analyzes photos for value-enhancing upgrades like marble countertops and stainless steel appliances.
- Since February, the company has used its estimates as the basis for cash offers on 900,000 homes. It believes the system’s improved accuracy will enable it to boost that number.
Behind the news: Zillow has been tweaking Zestimate since 2006. The new neural network grew from a hackathon in which 3,800 teams from 91 countries competed for a $1 million prize. The winning team used a combination of deep learning and other machine learning techniques. The company incorporates machine learning into other aspects of its business as well, Zillow vice president of AI Jasjeet Thind said in an interview for DeepLearning.AI’s Working AI series. For instance, the company is developing a natural language search system for parsing legal documents.
Why it matters: Between inspections, negotiating a price, and filling out reams of paperwork, buying a home is a complex ordeal. A tool that helps buyers and sellers alike get a fair price could be a big help.
We’re thinking: How much does a GPU rack add to the value of a home?
Bugbot
An insect-sorting robot could help scientists grapple with the global biodiversity crisis.
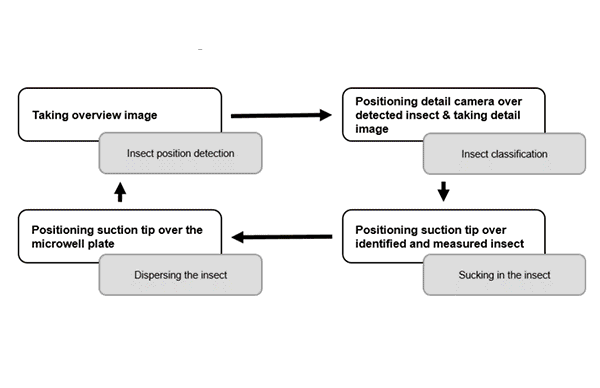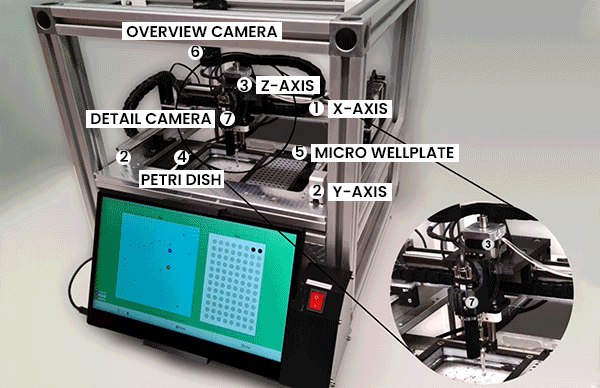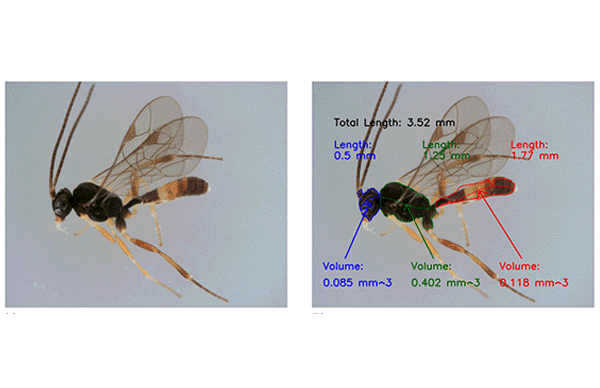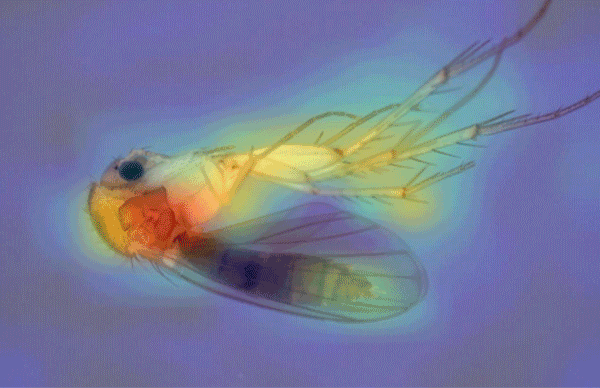
What’s new: An automated insect classifier sucks in tiny arthropods, classifies them, and maps their most important identifying features. It was developed by researchers at Karlsruhe Institute of Technology, Berlin Natural History Museum, Bavarian State Collection of Zoology, Sapienza University of Rome, and National University of Singapore.
How it works: The bot integrates systems that transport insects in and out, snap photos of them, and process the images. A touch screen serves as the user interface and displays model output. The authors pretrained a VGG19 convolutional neural network on ImageNet and fine-tuned it using 4,325 images of insects plus augmentations.
- Users place a petri dish full of unsorted, deceased insects in the machine’s receptacle. A downward-facing camera feeds a model that determines which shapes in the container are insects and helps a suction-tipped robot arm pick one up.
- A three-axis robot driven by a Raspberry Pi computer transfers the specimen to a plate, where a second camera takes a detailed photo. The VGG19 accepts the image and classifies the bug.
- The researchers used CAM to create a heat map of the parts of the image that were used to classify an image.
- The robot moves the specimen to a second tray for DNA sequencing. The system appends its DNA information to the file containing its picture, identification, and measurements.
Results: In testing, the system scored an average of 91.4 percent precision across all species — good but not up to the level of a human expert.
Behind the news: This is just the latest use of AI in the time-consuming task of insect identification.
- Researchers from Oregon State University developed a system that transports water-borne insects via a fluid-filled tube to a camera for identification.
- A team of Israeli inventors filed a patent for a system that differentiates male from female mosquitoes.
- A device designed by researchers in Denmark and Finland uses neural networks to identify insects, but it requires users to feed it individual specimens by hand.
- Why it matters: The World Economic Forum lists loss of biodiversity as one of the biggest threats to civilization worldwide. Insects are a key bellwether, but their tiny size and huge numbers make it difficult to track their wellbeing at a species level. Automated approaches to evaluating insect populations could help scientists assemble an accurate picture.
We’re thinking: If this system stopped working, someone would have to debug it.
A MESSAGE FROM DEEPLEARNING.AI

Learn how to counteract bias and unfair representations! Together with KPMG Ignition Tokyo and Machine Learning Tokyo, we invite you to “XAI: Learning Fairness with Interpretable Machine Learning” on July 8, 2021. Enroll now