
Dear friends,
I’ve been thinking a lot about "small data." If you have an image classification problem and 1,000,000 images, then dozens of teams around the world can build a good classifier. But what if you have only 100 or 10 images? There would be a much greater variance between different teams’ performance faced with such a small data set.
At Landing AI, I’ve heard from several manufacturers wanting to use AI to find scratches and other defects on phones. Fortunately, no company has manufactured 1,000,000 scratched phones that subsequently needed to be thrown away; they may have only a limited number of images of defective phones.
The ability to build and deploy machine learning systems that learn from small data would unlock many applications. The research literature on one-shot learning, few-shot learning, domain adaptation, and transfer learning nibbles at the problem, but there’s still a long way to go.
Keep learning,
Andrew
News

Labeled Data On Tap
Data wranglers have tried bulking up training data sets with synthetically generated images, but such input often fails to capture real-world variety. Researchers propose a way to generate labeled data for visual tasks that aims to bring synthetic and real worlds into closer alignment.
What’s new: Where most approaches to synthesizing visual data concentrate on matching the appearance of real objects, Meta-Sim also aims to mimic their diversity and distribution as well. Its output proved quantitatively better than other methods in a number of tasks.
How it works: For a given task, Meta-Sim uses a probabilistic scene grammar, a set of compositional rules that attempt to represent objects and their distributions found in real-world scenes. To optimize the grammar attributes, Meta-Sim uses a neural network that continuously minimizes the divergence of object distributions between real-life images and synthetic images rendered from the grammar. The neural network can also be used to modify the grammar itself to boost performance on downstream tasks.
Results: Amlan Kar and his colleagues at MIT, Nvidia, University of Toronto, and Vector Institute show that tuning probabilistic scene grammars via Meta-Sim significantly improves generalization from synthetic to test data across a number of tasks. Trained on Meta-Sim data, networks built for digit recognition, car detection, and aerial road segmentation perform accurately on real-world data.
To be sure: Meta-Sim relies on probabilistic scene grammars for any particular task. Its output is only as good as the grammar itself, and it can model only scenes that are represented in PSG format.
Takeaway: There’s no such thing as too much labeled data. Meta-Sim offers an approach to generating endless quantities of diverse visual data that more closely mimics the real world, and points the way toward synthesizing more realistic data for other kinds of tasks. That could make for more accurate models going forward.
Weight Loss for AI
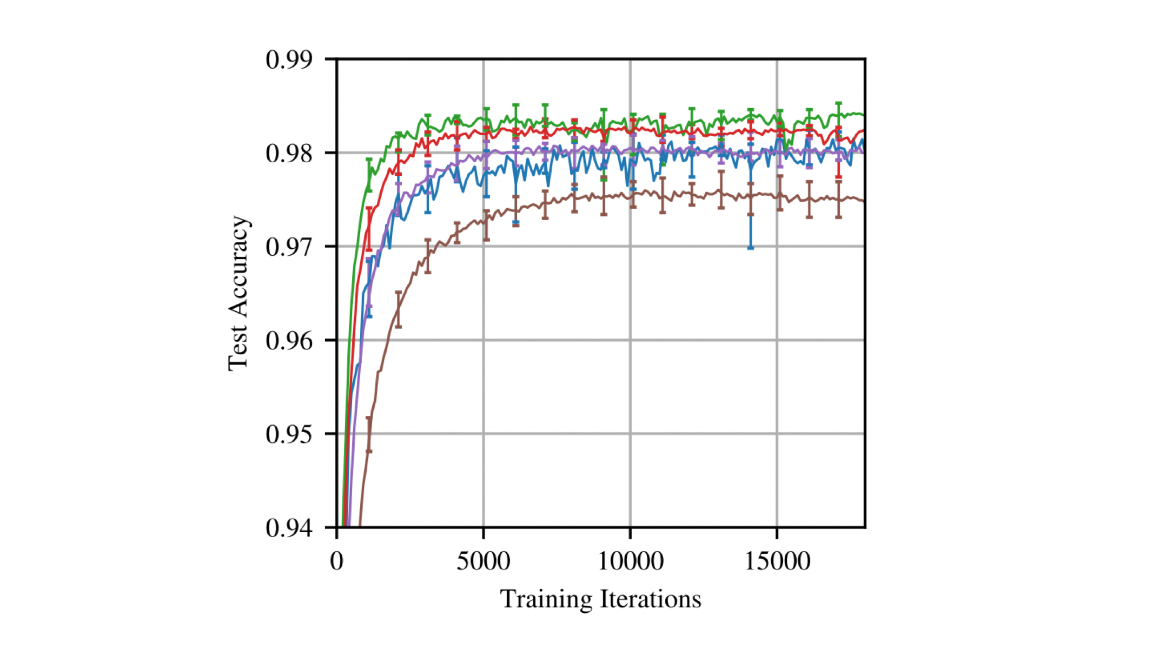
Larger neural networks can deliver better results, yet researchers found a way to make deep learning models perform just as well at one-tenth the size. Their work was awarded best paper at this year's International Conference on Learning Representations.
What’s new: Researchers at MIT developed a procedure to identify, within a trained network, a much smaller subnetwork that performs the desired task as fast and accurately as its bulky counterpart.
How it works: The researchers started with a fully-connected convolutional feed-forward architecture. They initialized the network randomly and trained it over a number of iterations. Then they trimmed off the connections with the lowest weights in each layer. Finally, they reset the remaining connections to their initialization values and retrained. They repeated this process several times to achieve high performance in compact size.
Why it matters: Researchers Jonathan Frankle and Michael Carbin built on earlier work on pruning neural networks, but they achieved much more dramatic results. Apparently such high-performance subnetworks exist in any neural network, depending on weights assigned during initialization. The researchers call these high-performance subnetworks “winning tickets,” and they propose an algorithm to identify them. Winning tickets require a fraction of the usual memory resources, computational power, and energy. Spotting them early in the model-building process might yield immense savings.
To be sure: The researchers pruned only networks devoted to computer vision and trained on small data sets. It’s not clear whether the results would be equally impressive otherwise. Moreover, their method currently requires training a network more than a dozen times, so it requires a lot of computation.
What’s next: The researchers aim to identify winning tickets early, making it possible to build compact networks from the start. They’ll be studying winning tickets in hope of discovering more powerful architectures and initialization methods.
Toward Explainable AI
Machine learning systems are infamous for making predictions that can’t readily be explained. Now Microsoft offers an open source tool kit providing a variety of ways to interrogate models.
What's in the package: InterpretML implements Explainable Boosting Machine, a generative additive model that delivers both high accuracy and high explainability. The package also comes with several methods to generate explanations of model behavior for regression and binary classification models. Developers can compare explanations produced by different methods and check consistency among models.
Why it matters: Building models that can explain how they reach their conclusions is critical in life-and-death situations like transportation, healthcare, and law enforcement. And it’s a top priority in high-stakes industries such as finance where decisions may be called into question. Understanding the behavior of intelligent systems is important to:
- debug models
- detect bias
- meet regulatory requirements
- defend legal challenges
- establish trust in a system’s output
What’s next: Principal researcher Rich Caruana and his colleagues aim to improve InterpretML’s categorical encoding and add support for multi-class classification and missing values. They’re hopeful the open source community will build on their work to illuminate what goes on inside machine learning's proliferating black boxes.
A MESSAGE FROM DEEPLEARNING.AI

Still debating whether to get into deep learning? Check out the techniques you'll learn and projects you'll build in the Deep Learning Specialization. Learn more
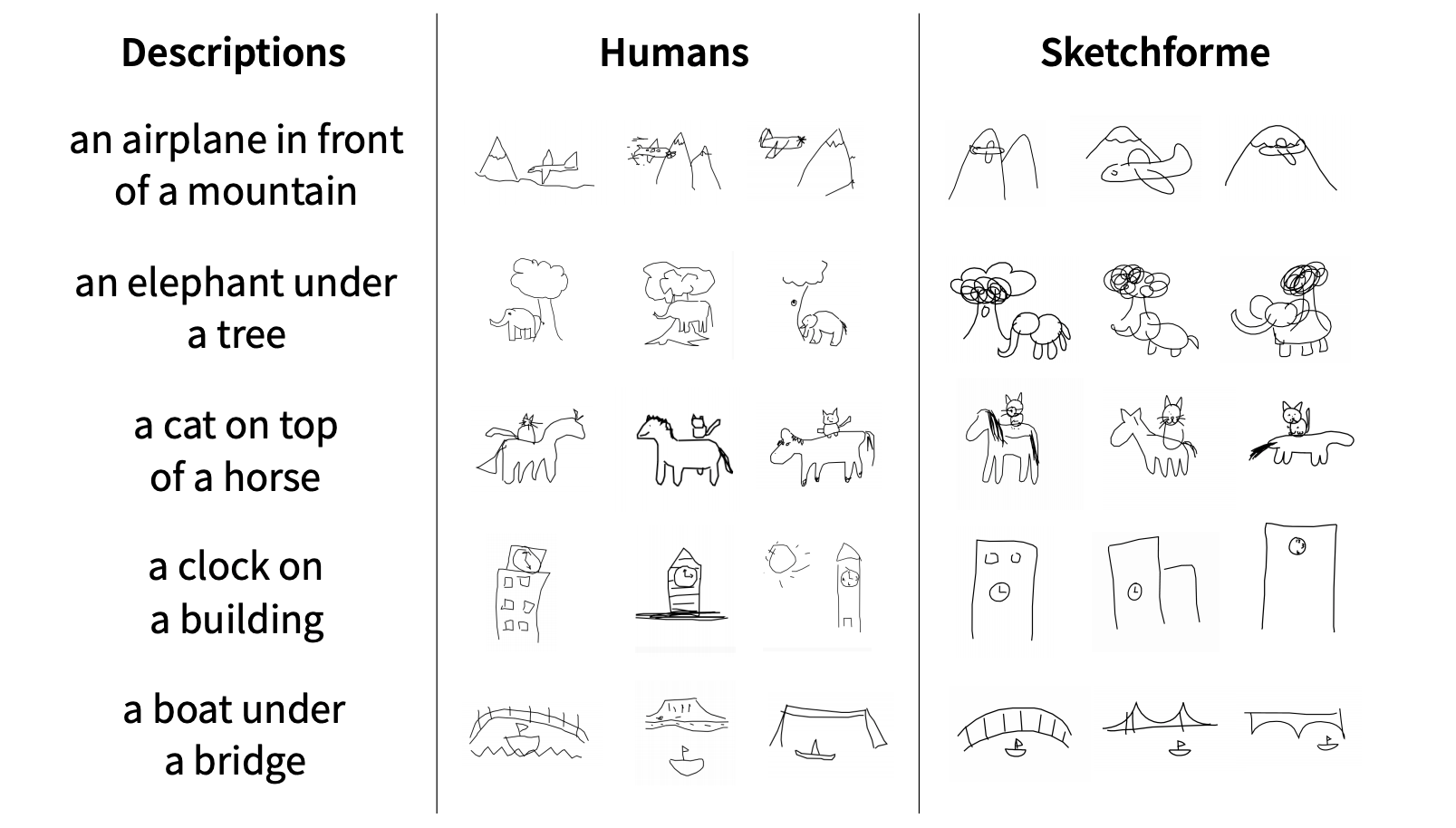
Digital Doodles
Wish you could draw, but your elephants look like crocodiles? Sketchforme doesn’t have that problem. This AI agent roughs out simple scenes based on text descriptions.
What’s new: Sketchforme generates crude drawings from natural-language descriptions such as “an apple on a tree” or “a dog next to a house.” People who viewed its output thought a human made the drawing a third of the time, a new paper says.
How it works: Sketchforme relies on two neural networks:
- The scene composer generates scene layouts. It was trained on the Visual Genome data set of photos annotated with captions, bounding boxes, and class information.
- The object sketcher draws the objects according to their real-world scale. It was trained on the Quick, Draw! data set of 50 million labeled sketches of individual objects.
Behind the news: Building a sketch generator was a thorny problem until the advent of neural networks. Sketch-RNN, an early sketcher based on neural nets in 2017, was trained on crowd-sourced drawings and draws requested objects using an initial stroke as a prompt. Sketchforme builds on that work.
Bottom line: Sketchforme’s output is remarkably true to human notions of what objects look like in the abstract. UC Berkeley researchers Forrest Huang and John F. Canny point out that sketching is a natural way to convey ideas quickly and a useful thinking tool in applications like learning languages. But the fact is, Sketchforme is just plain fun — and no slouch at drawing, too.
Hopes and Fears For AI in Business
Corporate executives worldwide are gearing up to take advantage of AI. But those in different countries aim to use the technology differently, and they bring different hopes and fears.
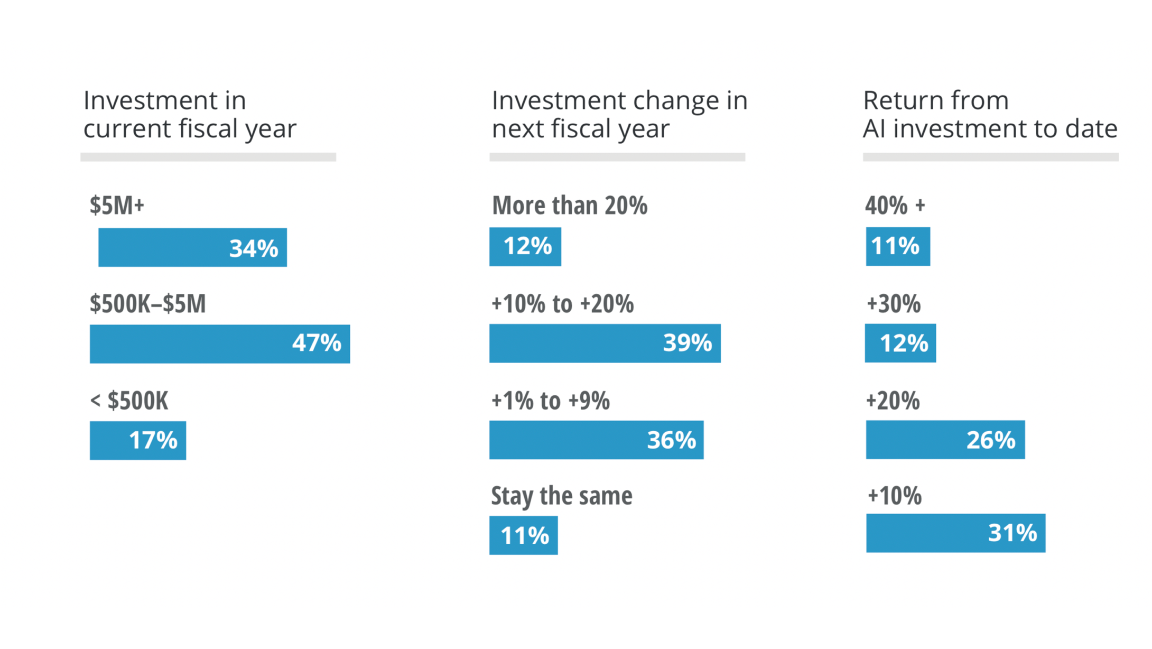
What’s new: In an international survey of executives who are using AI at scale, two-thirds believed AI already is “very” or “critically” important to success, according to Deloitte’s latest State of AI in the Enterprise report. Roughly 10 percent of respondents had achieved a return on their AI investment of 40 percent or more. Roughly 30 percent saw less than 10 percent return. The rest saw ROIs in between.
Experience versus strategy: Deloitte rated respondents in the U.S. the most seasoned. However, more of those in China and the UK reported having a company-wide AI strategy.
Different goals: While most executives in China said AI would help them widen their lead over competitors, majorities in Australia, Canada, and France were using AI to catch up or stay abreast of the competition. Those in the U.S. were nearly evenly divided between those aims.
Benefits: Early adopters deemed the primary benefits of AI to be:
- enhancing products and services
- optimizing internal operations
Challenges: They regarded the top challenges of AI as:
- data
- implementation
- cost
- measuring value
Risks: About half of French executives expressed “major” or “extreme” concern about AI’s potential risks. Among those in China, that number was only 16 percent. Generally, the greater the concern, the less the confidence expressed in preparations to meet it. The biggest concerns were:
- cybersecurity
- faulty predictions
- bias
Talent shortage: 68 percent of those surveyed judged the gap between skills needed and those available to be “moderate” to “extreme.” The top three roles needed were:
- researchers
- software developers
- data scientists
We're thinking: Globally, more than half of those surveyed said AI would substantially transform their company within three years, and roughly half said it would transform their industry within five. Deloitte consequently sees a two- to three-year window for companies to use AI to differentiate. It’s hard to believe, though, that the window is that brief. Even 30 years after the invention of the web, companies are still figuring out how to use it. The dust isn't likely to settle around AI in less than a decade.

When Good Models Do Bad Things
A lawsuit in London could set precedents for how to allocate responsibility when algorithms make poor predictions.
What’s happening: Samathur Li Kin-kan, a Hong Kong real-estate heir, sued high-profile hedge fund manager Raffaele Costa for $23 million for allegedly overstating the capabilities of an AI-driven trading platform. It’s the first known legal action over a financial loss caused by a predictive algorithm, according to Bloomberg.
Behind the news: Li in late 2017 invested $2.5 billion with Costa’s trading firm. Costa, who also goes by the name of Captain Magic, used a computer called K1 to recommend trades. Developed by Austrian software house 42.cx, the K1 system performed real-time sentiment analysis on news and social media to predict stock prices. Then it sent instructions to a broker to execute trades. Following a series of mishaps, the system lost $20.5 million in a single day in February 2018. Costa, in a countersuit for $3 million in unpaid fees, says he didn't guarantee a return on investment. Li's case is scheduled to go to trial in April 2020.
Why it matters: The question of who’s at fault when people act on erroneous predictions made by AI becomes more pressing as the technology finds its way into industries from healthcare to manufacturing. Reports of autonomous vehicle crashes and bias in law-enforcement software have made headlines, and such cases likely will become more common—and more contentious—in the future.
What they’re saying: “I think we did a pretty decent job. I know I can detect sentiment. I’m not a trader.” — 42.cx founder Daniel Mattes, quoted by Bloomberg.
Smart take: The outcome is bound to influence subsequent lawsuits involving AI — but it’s just the first step on a long, long road to establishing the legal status of AI.