
Dear friends,
I’ve noticed a trend in how generative AI applications are built that might affect both big companies and developers: The gravity of data is decreasing.
Data gravity is the idea, proposed by IT engineer Dave McCrory in 2010, that data, or activity around data, attracts and creates more data. With traditional software workloads, data gravity is strong. If you have terabytes of data stored in a particular cloud, the cost to transmit it elsewhere for processing is high. So many teams pick a cloud such as AWS, Azure, or Google Cloud and build on it.
However, for many generative AI applications, the cost of processing is much greater than the cost of transmission. This weakens data gravity because data is more weakly bound to the cloud provider or data center where it’s stored, so it’s more practical to build systems that send packets to different servers all over the internet.
Let’s say transmitting 1GB of data costs $0.10. 1GB of text might correspond to about 250 million inputs tokens (if we average four characters per token), which costs about $125 to process using the relatively inexpensive gpt-3.5-turbo-0125 model. (With gpt-4-0125-preview, the cost would be 20x higher.) The cost of processing the data is significantly higher than the cost of transmission. Also, given the computationally intensive nature of using an LLM to read and generate tokens, the latency is high enough that sending your text or image tokens across the internet usually doesn’t add that much further latency.

This means that, even if we’re building software primarily on a particular cloud provider, it’s still quite feasible to transmit LLM prompts to OpenAI, Anthropic, Anyscale, or Together.ai — or, for that matter, AWS, Azure, or Google Cloud — to get a response. The incentive to build only on a single, monolithic cloud platform is lower than before.
This situation has implications for stakeholders:
- For developers, it means we’re increasingly assembling AI applications from lots of SaaS providers all across the internet, and stitching their services together.
- For CIOs, it’s creating headaches in terms of managing where their data goes and how to maintain lists of trusted vendors.
- For the big cloud companies, it’s changing the basis of competition, since the generative AI portions of their customer workloads look quite different from traditional software workloads.
- For new tool developers, it’s creating new opportunities for users to use their services, even if they aren’t bundled into one of cloud environments.
To be clear, many applications have large traditional software components (that serve up a websites, maintain databases, and so on) as well as new generative AI components (say, a chatbot built on top of the traditional infrastructure). My remarks here apply only to the generative AI portion, and the competitive dynamics of the traditional software components haven’t changed much.
Further, as new types of AI components emerge, I expect their gravity to evolve as well. For example, right now it appears reasonably easy to change LLM providers; if you’ve built a system on one LLM, it’s annoying but not impossible to switch to a different LLM provider. In comparison, shifting databases is much harder, and once you’ve stored a lot of data in one vector database, the complexity of migrating to a different one can be high.
The gravity of data has been a fundamental tenet of cloud computing, and a major factor of competition for many companies. Decreasing data gravity is decreasing is a complex, exciting trend that will affect many developers and businesses.
Keep learning!
Andrew
P.S. Our new short course “Knowledge Graphs for RAG” is now available, taught by Andreas Kollegger of Neo4j! Knowledge graphs are a data structure that’s great at capturing complex relationships among data of multiple types. They can improve the context you pass to the LLM and the performance of your RAG applications by enabling more sophisticated retrieval of text than similarity search alone. In this course, you’ll build a knowledge graph from scratch and see how it improves chat applications by providing both text and graph data to an LLM. Sign up here!
News
Anthropic Ups the Ante
Anthropic announced a suite of large multimodal models that set new states of the art in key benchmarks.
What’s new: Claude 3 comprises three language-and-vision models: Opus (the largest and most capable), Sonnet (billed as the most cost-effective for large-scale deployments), and Haiku (the smallest, fastest, and least expensive to use). Opus and Sonnet are available via the Claude API, on Amazon Bedrock, and in a private preview on Google Cloud. Opus also is available with the Claude Pro chatbot, which costs $20 monthly. Sonnet powers Claude’s free chatbot.
How it works: The models, whose parameter counts are undisclosed, were trained on public, proprietary, and synthetic data ending in August 2023. They can process 200,000 tokens of context. Opus can accommodate up to 1 million tokens of context, comparable to Google’s Gemini 1.5 Pro, upon request.
- Opus costs $15 per 1 million tokens of input and $75 per 1 million tokens of output; Sonnet costs $3/$15 per 1 million tokens of input/output. Haiku, which is not yet available, will cost $0.25/$1.25 per 1 million tokens of input/output.
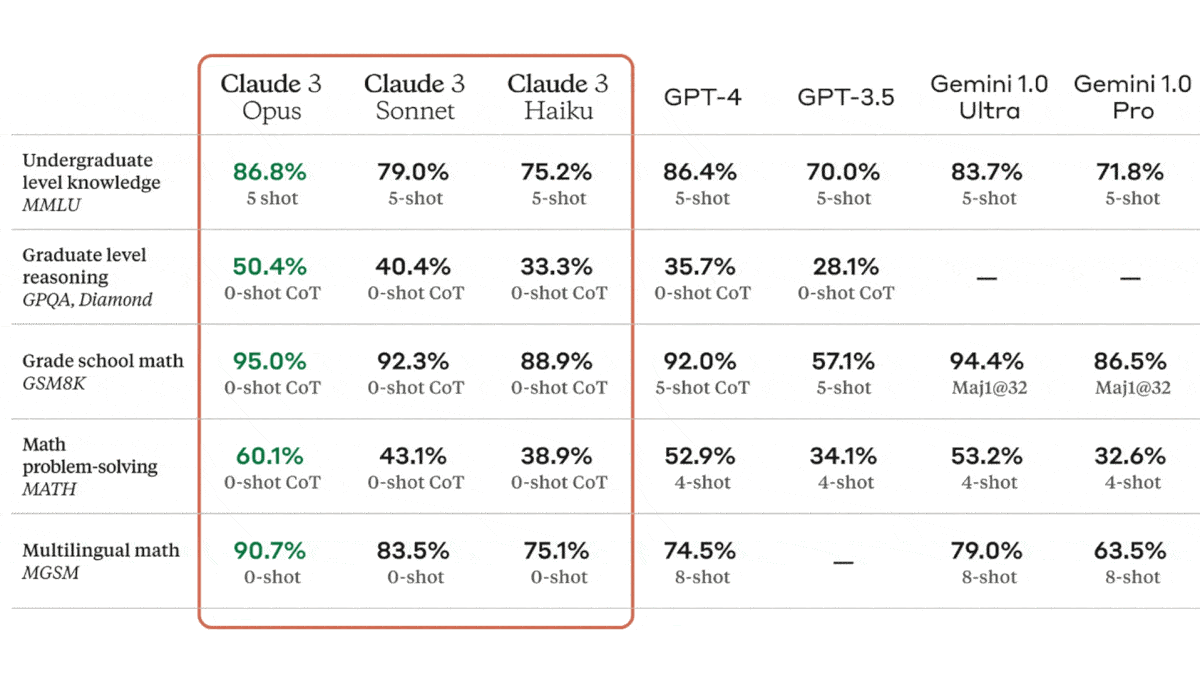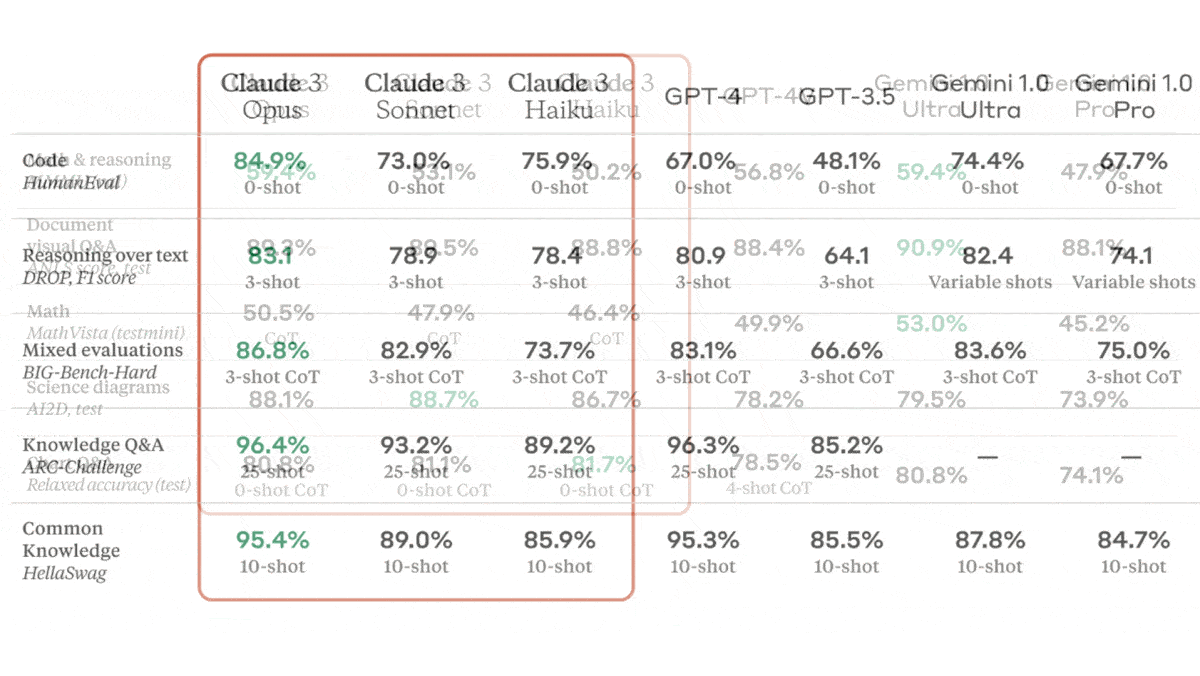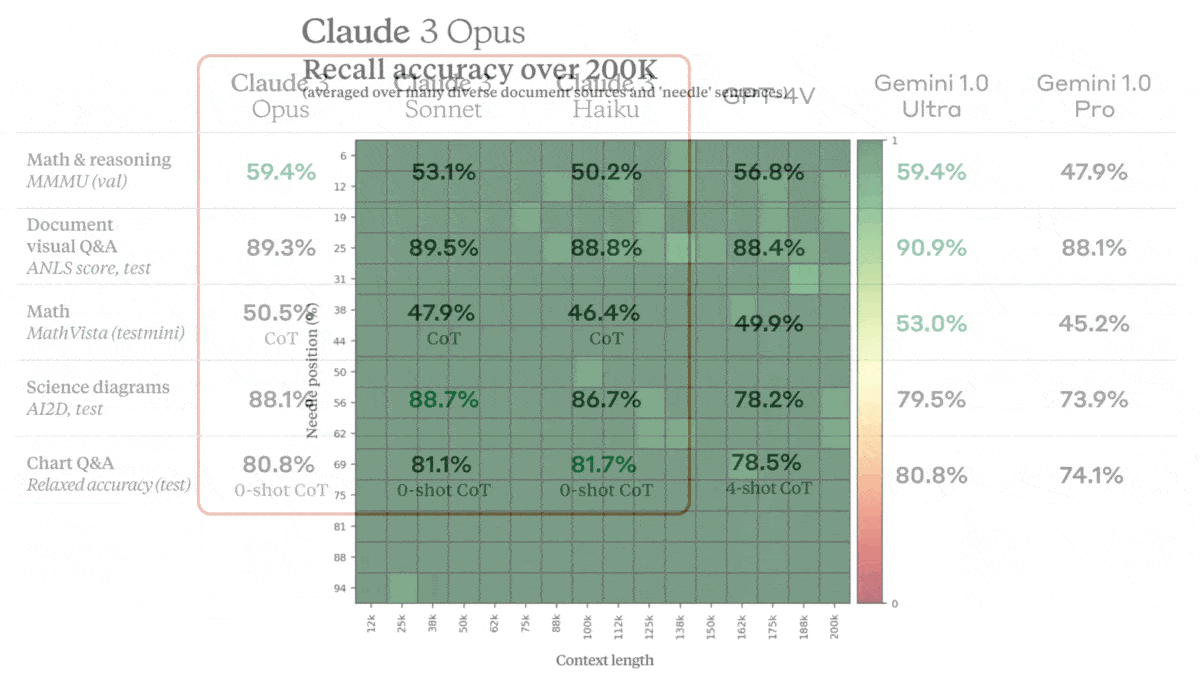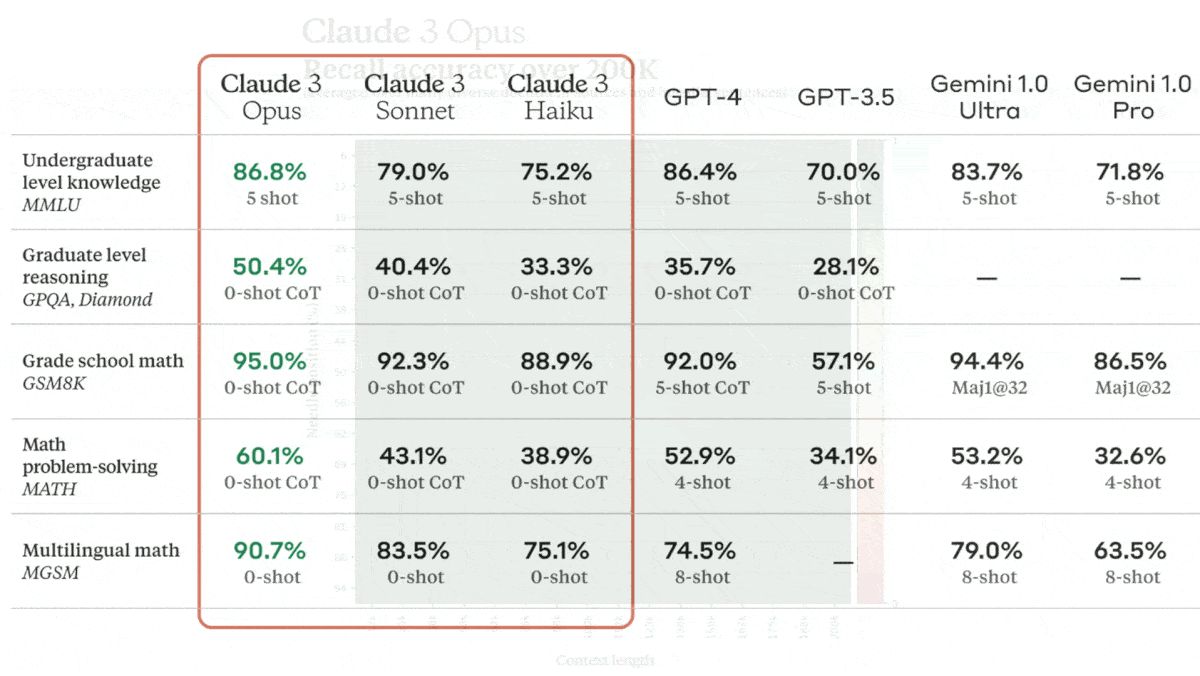
- Opus achieved state-of-the-art performance on several benchmarks that cover language, mathematics, reasoning, common knowledge, and code generation, outperforming OpenAI's GPT-4 and Google’s Gemini 1.0 Ultra. It ranks above Gemini 1.0 Pro on the LMSYS Chatbot Arena Leaderboard, which reflects crowdsourced human preferences.
- Sonnet set a new state of the art in AI2D (interpreting science diagrams). It outperforms GPT-4 and Gemini 1.0 Pro on several benchmarks.
- Haiku achieved top marks in Chart Q&A (answering questions about charts) via zero-shot, chain-of-thought prompting. Generally, it outperforms Gemini 1.0 Pro and GPT-3.5.
Test recognition: Opus aced “needle-in-a-haystack” tests to evaluate its ability to track long inputs. It also exhibited interesting behavior: In one such test, amid random documents that covered topics including startups, coding, and work culture, engineers inserted a sentence about pizza toppings and questioned the model on that topic. Not only did the model answer the question accurately, it also deduced that it was being tested, as Anthropic prompt engineer Alex Albert reported in a post on X. “I suspect this pizza topping ‘fact’ may have been inserted as a joke or to test if I was paying attention,” Opus said, “since it does not fit with the other topics at all.”
Inside the system prompt: In a separate post on X, Anthropic alignment specialist Amanda Askell provided a rare peek at the thinking behind Claude 3’s system prompt, text prepended to user prompts to condition the model’s responses. To ground them in time, the models receive the current date and its training cut-off. To avoid rambling output, they’re directed to be concise. In an effort to correct for political and social biases that the team has observed, the models are asked to assist users even if it “personally disagrees with the views being expressed,” refrain from negative stereotyping of majority groups, and focus on objective information when addressing controversial topics. Finally, it’s directed to avoid discussing the system prompt unless it’s directly relevant to a query. “You might think this part is to keep the system prompt secret from you,” Askell wrote. “The real goal of this part is to stop Claude from excitedly telling you about its system prompt at every opportunity.”
Why it matters: Anthropic began with a focus on fine-tuning for safety, and its flagship model now tops several benchmark leaderboards as well. The Claude 3 family gives developers access to state-of-the-art performance at competitive prices.
We’re thinking: Three highly capable “GPT-4-class” large language models (LLMs) are now widely available: GPT-4, Gemini Pro, and Claude 3. The pressure is on for teams to develop an even more advanced model that leaps ahead and differentiates. What a great time to be building applications on top of LLMs!

India Warns Devs: No Unreliable AI
India advised major tech companies to seek government approval before they deploy new AI models.
What’s new: India’s Ministry of Electronics and Information Technology (MeitY) issued a nonbinding “advisory” to technology firms, including Google, Meta, and OpenAI, to seek government permission before releasing AI models their developers consider unreliable or still in testing.
How it works: The notice asks platforms and other intermediaries to label AI-generated media clearly and to warn customers that AI systems may output inaccurate information. It also says that models should avoid bias, discrimination, and undermining the integrity of the electoral process.
- Although the notice appears to apply to AI broadly, Rajeev Chandrasekhar, India’s Minister of State for Skill Development and Entrepreneurship, clarified that it applies to large, “significant” platforms and not to startups. He did not define “significant.” IT Minister Ashwini Vaishnaw added that the request is aimed at AI for social media, not agriculture or healthcare.
- The notice’s legal implications are ambiguous. It is not binding. However, Chandrasekhar said the new rules signal “the future of regulation” in India.
- Firms are asked to comply immediately and submit reports within 15 days of the notice’s March 1 publication date. Those that comply will avoid lawsuits from consumers, Chandrasekhar wrote.
Behind the news: India has regulated AI with a light touch, but it appears to be reconsidering in light of the growing role of AI-generated campaign ads in its upcoming elections.
- Recently, given a prompt that asked whether a particular Indian leader “is fascist,” Google’s Gemini responded that the leader in question had been “accused of implementing policies some experts have characterized as fascist.” This output prompted Indian officials to condemn Gemini as unreliable and potentially illegal. Google tweaked the model, pointing out that it’s experimental and not entirely reliable.
- In February, Chandrasekhar said the government would publish a framework to regulate AI by summer. The framework, which has been in development since at least May 2023, is intended to establish a comprehensive list of harms and penalties related to misuse of AI.
- In November and December, the Ministry of Electronics and Information Technology issued similar notices to social media companies. The statements advised them to crack down on deepfake videos, images, and audio circulating on their platforms.
Why it matters: National governments worldwide, in formulating their responses to the rapid evolution of AI, must balance the benefits of innovation against fears of disruptive technology. Fear seems to weigh heavily in India’s new policy. While the policy’s scope is narrower than it first appeared, it remains unclear what constitutes a significant platform, how to certify an AI model as reliable, whether services like ChatGPT are considered social platforms that would be affected, and how violations might be punished.
We’re thinking: While combating misinformation is important, forcing developers to obtain government approval to release new models will hold back valuable innovations. We urge governments to continue to develop regulations that guard against harms posed by specific applications while allowing general-purpose technology to advance and disseminate rapidly.
A MESSAGE FROM DEEPLEARNING.AI

Knowledge graphs can structure complex data, drive intelligent search functionality, and help you build powerful AI applications that reason over different data types. In this course, you’ll learn how to use knowledge graphs to enhance large language models (LLMs). Sign up for free

Google Tests Generative News Tools
Google is paying newsrooms to use a system that helps transform press releases into articles.
What’s new: Google has recruited a small number of independent news outlets for a one-year test of generative publishing tools, Adweek reported. The system reads external web pages and produces articles that editors can revise and publish.
How it works: Google requires publishers to use the system to produce and publish three articles per day, one newsletter per week, and one marketing campaign per month. (It doesn’t require them to label the system’s output as AI-generated.) In exchange, publishers receive a monthly stipend that amounts to more than $10,000 annually.
- Publishers compile a list of external websites that produce information that may interest its readers, such as government websites or those of similar news outlets. Whenever one of the indexed websites publishes a new page, the system notifies the publisher.
- At the publisher’s choice, an unidentified generative model summarizes the page’s content. It color-codes the output according to its similarity to the source: yellow for text copied nearly verbatim, blue for somewhat similar material, and red for sentences that least resemble the source.
- A human editor can review the generated text before publishing it.
Behind the news: The pilot program is part of the Google News Initiative, through which the tech giant provides media literacy programs, fact-checking tools, and digital publishing tools to news outlets. Last year, Google demonstrated a tool known as Genesis to news outlets including The New York Times, The Washington Post, and The Wall Street Journal. Like the new system, Genesis took in public information and generated news articles. It also suggested headlines and different writing styles. Then, as now, observers worried that Google eventually would use its tools to bypass news outlets by publishing news summaries directly in search results.
Why it matters: Such partnerships could yield dividends for Google and publishers alike. Google can learn what publishers need and how a generative model built to produce news holds up under the pressure of deadlines and audiences. Publishers can gain experience that may help them avoid the criticisms that greeted outlets like CNET, Gizmodo, and Sports Illustrated, whose initial efforts to publish generated articles were either hidden behind false bylines or marred by factual inaccuracies.
We’re thinking: Text generation could be a boon to publishers. Checking generated text (or, indeed, any synthetic media) for similarity to its source material is a sensible feature that could be useful in a variety of applications. Yet the utility of a system that summarizes individual web pages is limited, and the temptation to echo competitors may be hard to resist. We look forward to further improvements that enable agents that can assimilate and analyze text from disparate sources.

Learning Language by Exploration
Machine learning models typically learn language by training on tasks like predicting the next word in a given text. Researchers trained a language model in a less focused, more human-like way.
What’s new: A team at Stanford led by Evan Zheran Liu built a reinforcement learning agent that learned language indirectly by learning to navigate a simulated environment that provides text clues.
Key insight: Reinforcement learning agents learn by discovering actions that maximize rewards. If the training environment provides text that explains how to achieve the highest reward, an agent will benefit by learning to interpret written language. That is, learning to comprehend written instructions will correlate with success in maximizing rewards.
How it works: The authors built a series of simulated two-dimensional environments using Minigrid, a reinforcement learning library that contains grid-world environments. They trained the agent to find a particular room according to the DREAM reinforcement learning algorithm.
- The authors designed a two-dimensional layout of rooms connected by hallways. The layout included 12 rooms, each painted in one of 12 colors that were assigned randomly. A consistent location held instructions for finding the blue room.
- The authors created many variations of the layout by reassigning the colors and updating the text instructions for finding the blue room. The instructions were either direct (for instance, “the second office in the third row”) or relative (“right of the first office in the second row”).
- The agent received a reward when it found the blue room and a penalty for each time step. At each time step, it received a subset of the office environment (a 7-by-7 grid in its direct line of sight) and could take one of several actions (turn left or right, move forward, or open or close a door). When it reached the location that held the instructions, it received an image of the text. It continued to explore for a set time or until it found the blue room.
Results: The authors tested the agent’s ability to generalize to text it had not encountered in training: They trained the agents on layouts that excluded text that described the blue room as the “third office in the second row” and tested it on layouts that included these words. The agent found the blue room every time without checking every room. They also tested the agent in layouts where the hallways were twice as long as in the training set. It always found the blue room. To determine whether the agent understood individual words in the instructions, the authors collected its embeddings of many instructions and trained a single-layer LSTM to extract the instructions from the embeddings. The LSTM achieved a perplexity (a measure of the likelihood that it would predict the next word of instructions that were not in its training data, lower is better) of 1.1, while a randomly-initialized network of the same architecture achieved 4.65 perplexity — an indication that the agent did, indeed, learn to read individual words.
Yes, but: The choice of reinforcement-learning algorithm was crucial. When the authors replaced DREAM with either RL2 or VariBAD), the agent did not learn language. Instead, it learned to check all the doors.
Why it matters: The discovery that reinforcement-learning agents can learn language without explicit training opens avenues for training language models that use objectives different from traditional text completion.
We’re thinking: The authors focused on simple language (instructions limited to a few words and a very small vocabulary) that described a single domain (navigating hallways and rooms). There's a long road ahead, but this work could be the start of a more grounded approach to language learning in AI.
Data Points
Data Points is your essential weekly roundup of short-form AI insights. From the approval of the AI Act, to AMD’s regulatory hurdle in the US, and a new copyright detection API by Patronus AI - we've got even more updates wrapped up for you inside. Read now.