
Dear friends,
Inexpensive token generation and agentic workflows for large language models (LLMs) open up intriguing new possibilities for training LLMs on synthetic data. Pretraining an LLM on its own directly generated responses to prompts doesn't help. But if an agentic workflow implemented with the LLM results in higher quality output than the LLM can generate directly, then training on that output becomes potentially useful.
Just as humans can learn from their own thinking, perhaps LLMs can, too. For example, imagine a math student who is learning to write mathematical proofs. By solving a few problems — even without external input — they can reflect on what does and doesn’t work and, through practice, learn how to more quickly generate good proofs.
Broadly, LLM training involves (i) pretraining (learning from unlabeled text data to predict the next word) followed by (ii) instruction fine-tuning (learning to follow instructions) and (iii) RLHF/DPO tuning to align the LLM’s output to human values. Step (i) requires many orders of magnitude more data than the other steps. For example, Llama 3 was pretrained on over 15 trillion tokens, and LLM developers are still hungry for more data. Where can we get more text to train on?
Many developers train smaller models directly on the output of larger models, so a smaller model learns to mimic a larger model’s behavior on a particular task. However, an LLM can’t learn much by training on data it generated directly, just like a supervised learning algorithm can’t learn from trying to predict labels it generated by itself. Indeed, training a model repeatedly on the output of an earlier version of itself can result in model collapse.

However, an LLM wrapped in an agentic workflow may produce higher-quality output than it can generate directly. In this case, the LLM’s higher-quality output might be useful as pretraining data for the LLM itself.
Efforts like these have precedents:
- When using reinforcement learning to play a game like chess, a model might learn a function that evaluates board positions. If we apply game tree search along with a low-accuracy evaluation function, the model can come up with more accurate evaluations. Then we can train that evaluation function to mimic these more accurate values.
- In the alignment step, Anthropic’s constitutional AI method uses RLAIF (RL from AI Feedback) to judge the quality of LLM outputs, substituting feedback generated by an AI model for human feedback.
A significant barrier to using LLMs prompted via agentic workflows to produce their own training data is the cost of generating tokens. Say we want to generate 1 trillion tokens to extend a pre-existing training dataset. Currently, at publicly announced prices, generating 1 trillion tokens using GPT-4-turbo ($30 per million output tokens), Claude 3 Opus ($75), Gemini 1.5 Pro ($21), and Llama-3-70B on Groq ($0.79) would cost, respectively, $30M, $75M, $21M and $790K. Of course, an agentic workflow that uses a design pattern like Reflection would require generating more than one token per token that we would use as training data. But budgets for training cutting-edge LLMs easily surpass $100M, so spending a few million dollars more for data to boost performance is quite feasible.
That’s why I believe agentic workflows will open up intriguing new opportunities for high-quality synthetic data generation.
Keep learning!
Andrew
P.S. In “Prompt Engineering for Vision Models,” taught by Abby Morgan, Jacques Verré, and Caleb Kaiser of Comet, you’ll learn how to prompt and fine-tune a variety of vision models for image generation, image editing, object detection, and segmentation. For example, you’ll use OWL-ViT to detect an object you describe in a text prompt, pass the bounding box to SAM to create a segmentation mask, and feed the mask into Stable Diffusion with a text prompt to replace the original object with a new one. Controlling vision models can be tricky, and this course will teach you the techniques to control their output. Get started here!
News
Think Different Small
Apple is thinking small — very small — with a new family of open large language models.
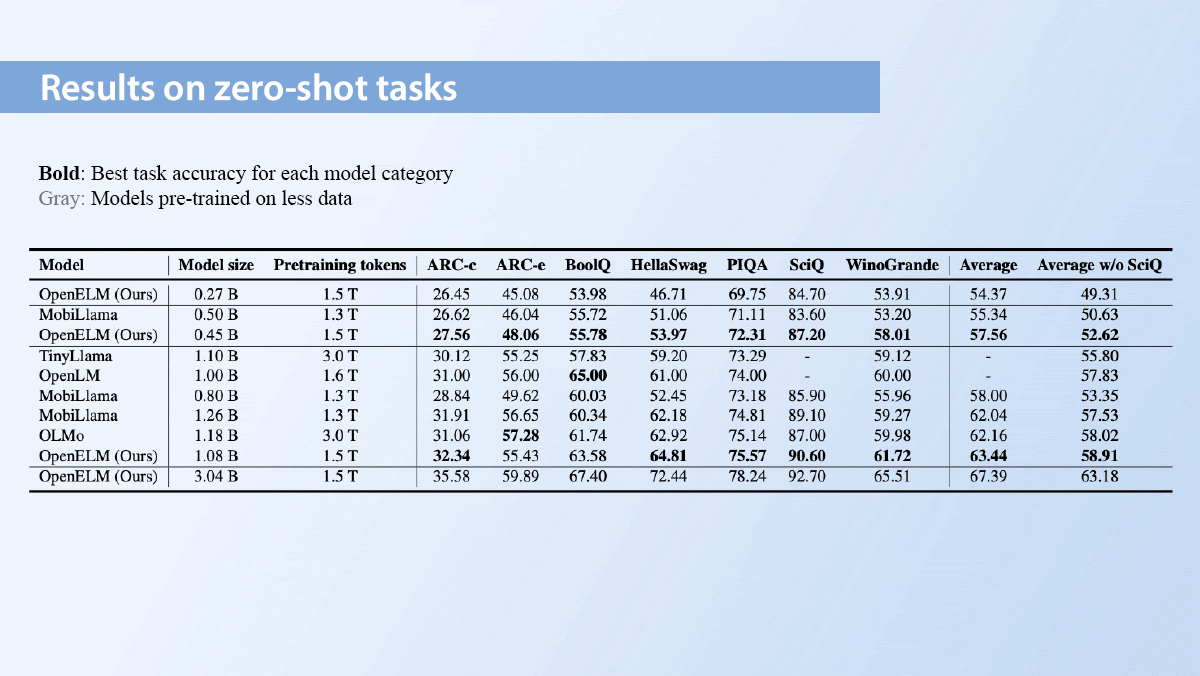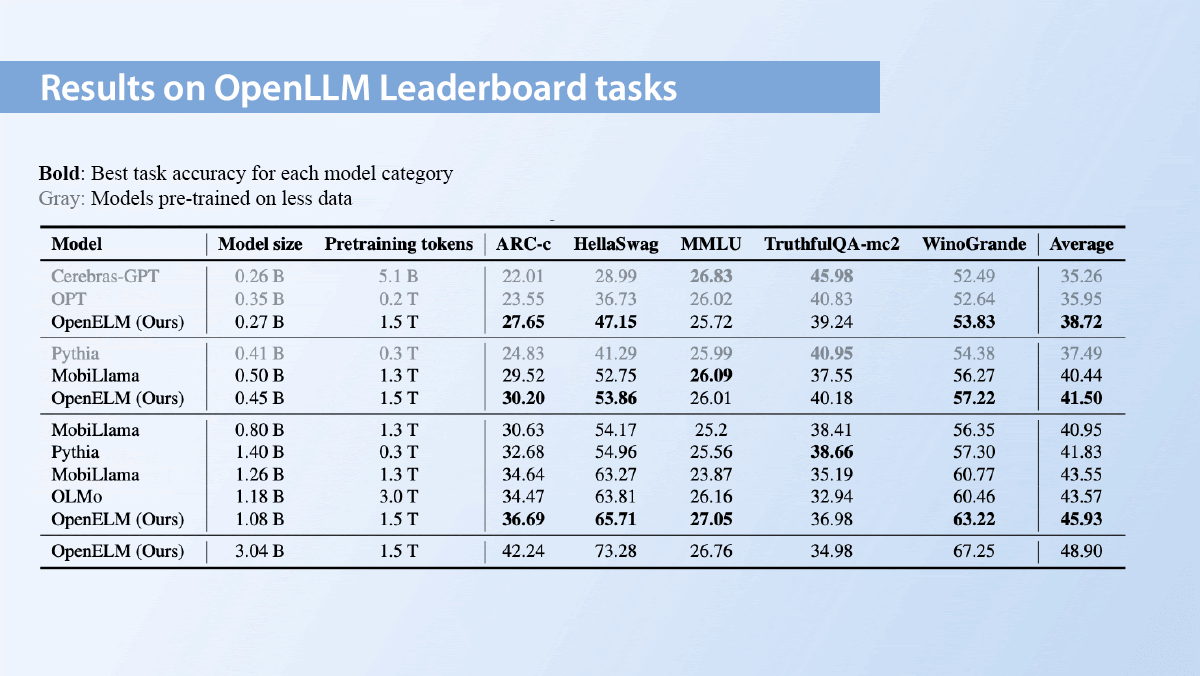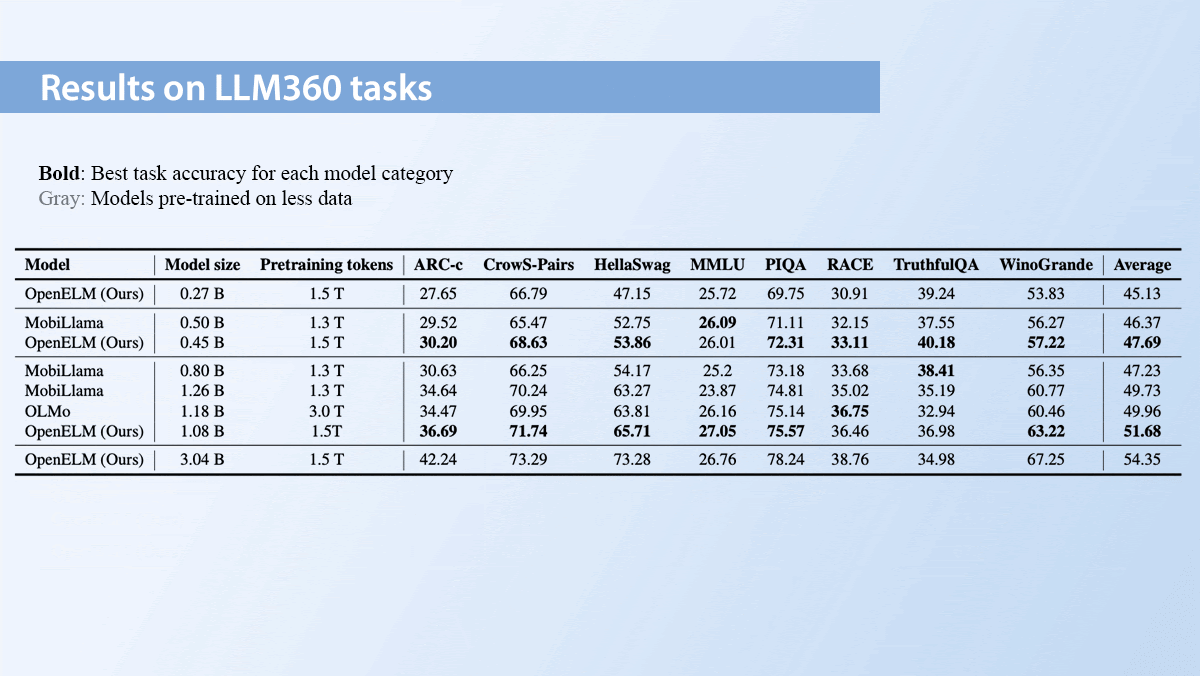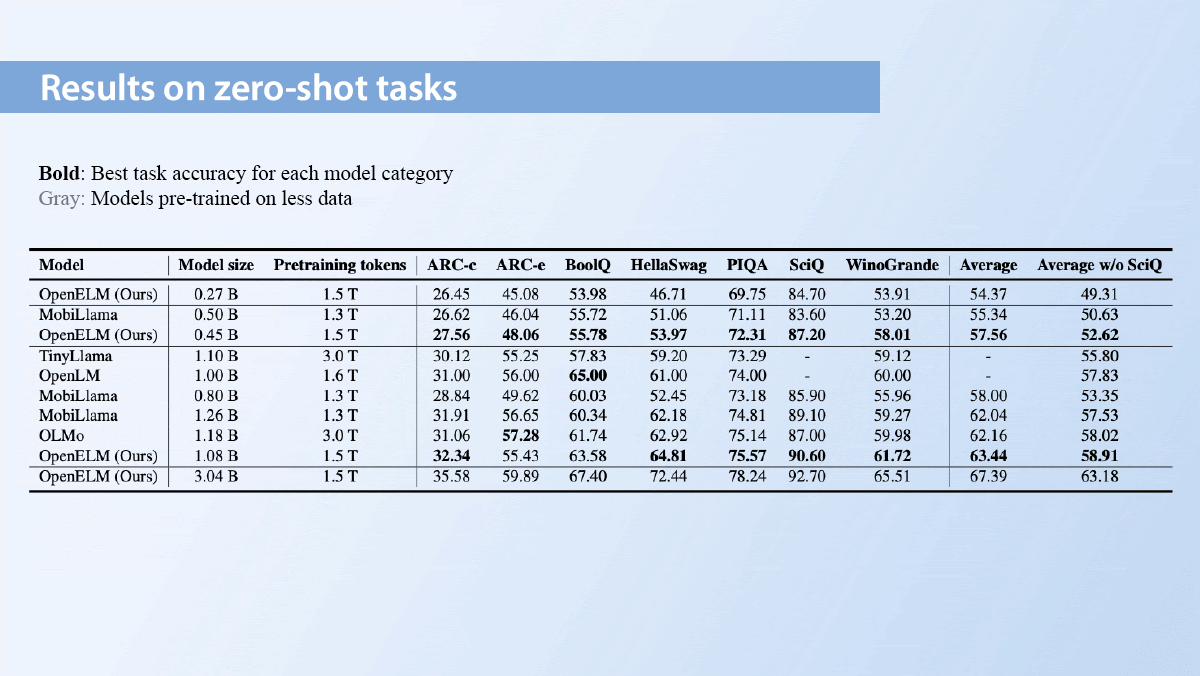
What's new: Sachin Mehta, Mohammad Hossein Sekhavat, Qingqing Cao, and colleagues at Apple released Open Source Efficient LLM (OpenELM), a family of smaller large language models. OpenELM ranges from 270 million parameters — plenty small enough to fit on a phone — to 3 billion parameters.
How it works: OpenELM comes in pretrained and instruction-tuned versions with parameter counts of 270 million, 450 million, 1.1 billion, and 3 billion. They can process 2,048 tokens of context. The release includes weights, code for training and inference, and code for running the models on Apple chips.
- The authors pretrained OpenELM on 1.8 trillion tokens drawn from subsets of publicly available text datasets.
- They fine-tuned the instruction-tuned models on the UltraFeedback dataset of 60 thousand prompts.
- OpenELM follows most of the architecture choices of current state-of-the-art transformer models with a major exception: The number of attention heads and size of fully connected layers increase the deeper in the network they are, following the idea that layers later in the network learn more complex representations of the input than early ones. This architecture contrasts to the current common practice, in which a transformer’s number of attention heads and size of fully connected layers remains consistent throughout the network.
Results: OpenELM beat a number of other open-source models trained solely on publicly available data.
- For example, on average across five tasks on the Open LLM Leaderboard, a 1.08 billion parameter OpenELM beat a 1.18 billion parameter OLMo 45.93 percent to 43.57 percent, although OLMo trained on twice as much data. The 270 million-parameter OpenELM achieved 38.72 percent.
- Comparing speed between OpenELM models that ran on consumer-grade computers, the 270 million-parameter model was over twice as fast as the 3 billion-parameter version. Apple did not present results obtained on phones.
- OpenELM fell short on MMLU (multiple choice questions from mathematics to microeconomics), achieving within 2.05 percent of random chance (25 percent) for all model sizes. To be fair, the other models chosen for comparison didn’t do much better. It’s possible that publicly available data isn’t sufficient for learning to solve MMLU. By comparison, Microsoft’s Phi-3-mini (3.8 billion parameters trained on web data filtered according to “educational level” plus generated data) achieved 68.8 percent accuracy.
Why it matters: After years of becoming only larger, neural networks lately have also been getting smaller. The smallest OpenELMs are tiny compared to, say, Microsoft’s Phi-3-mini. Apple has an extra incentive to make models capable of running on edge devices like phones. The company makes a major selling point of user privacy, and models run entirely on a smartphone (as opposed to in the cloud) keep the user’s activity under wraps.
We're thinking: DeLighT introduced this layer-scaling approach in 2020. Sometimes it takes a while for good ideas to catch on!
AI Trends in Depth
More expensive models, superhuman performance, growing impacts on society — an extensive report takes stock of developments in machine learning over the past year.
What's new: Stanford’s Institute for Human-Centric AI published the seventh “AI Index Report,” its annual overview of the state of AI. The report documents rising costs and capabilities, a shift from academic to corporate dominance, and the public’s anxiety as the technology becomes ever more embedded in daily life.
Themes and findings: The 500-page report collates a wide variety of papers, benchmarks, market research, and surveys published in 2023. It delves deeply into AI technology, economics, governance, and impact. Among its key conclusions:
- Foundation models, defined as versatile models trained on very large datasets, ballooned in number and cost. The Index counted 149 foundation models released in 2023 (including Google’s Gemini Ultra, which cost $191.4 million to train). That’s up from 32 foundation models in 2022, 9 in 2021, and 2 in 2020 (when OpenAI’s GPT-3 175B cost an estimated $4.3 million to train).
- Open foundation models, too, are on the rise: 66 percent of last year’s foundation models were open, up from 33 percent in 2021.
- State-of-the-art models approached or surpassed human performance on several popular benchmarks. These include MMLU (multitask language understanding), VisIT-Bench (vision-language instructions), and MATH (difficult math problems).
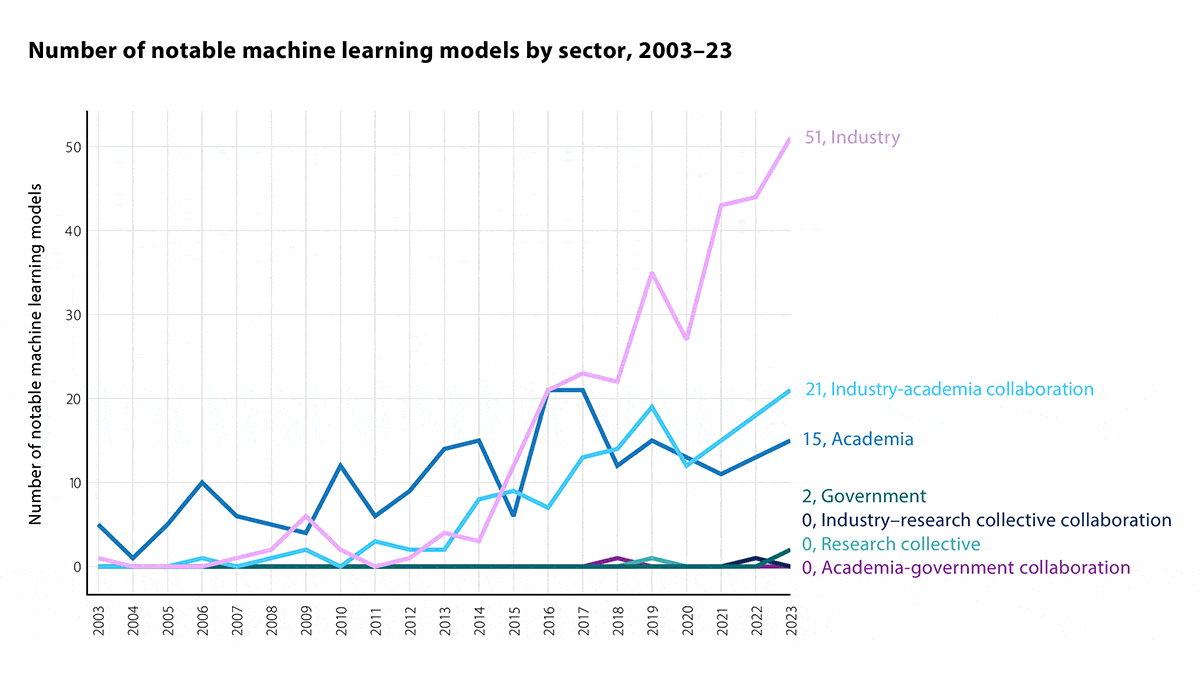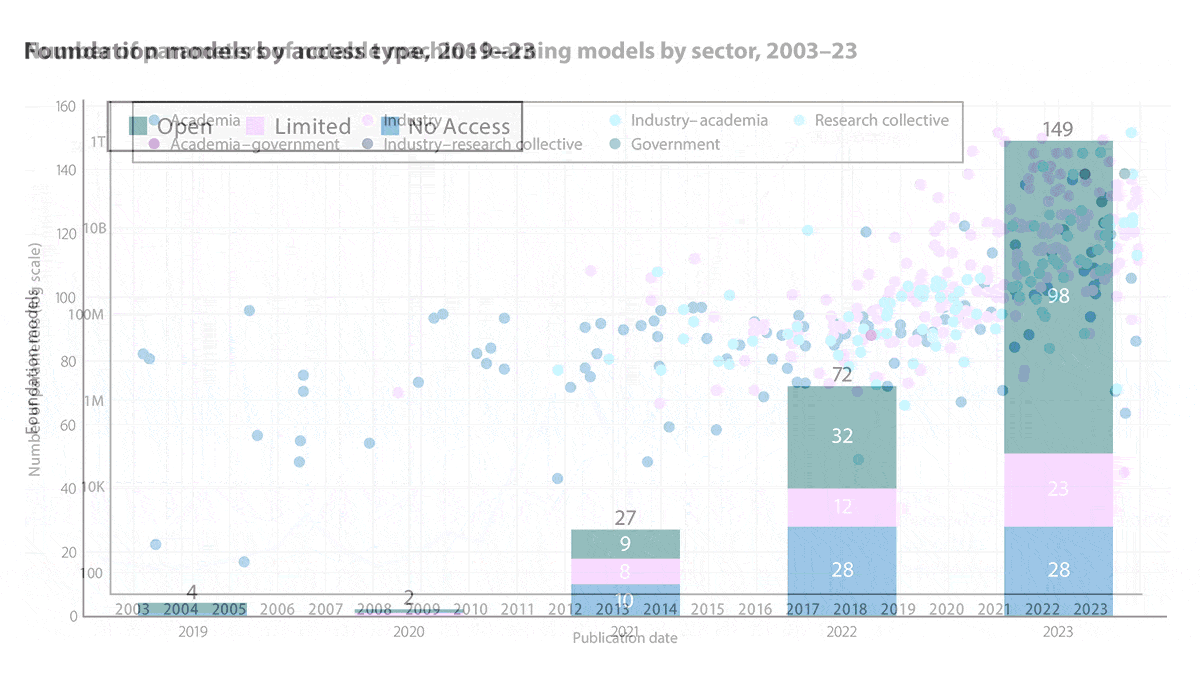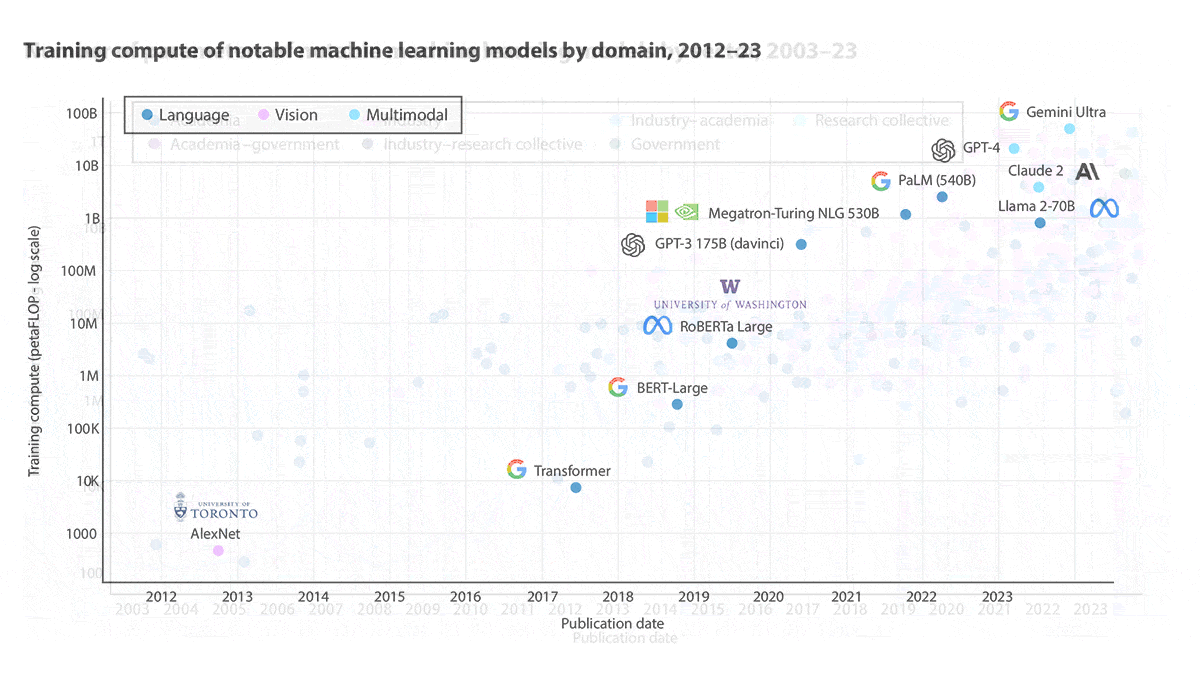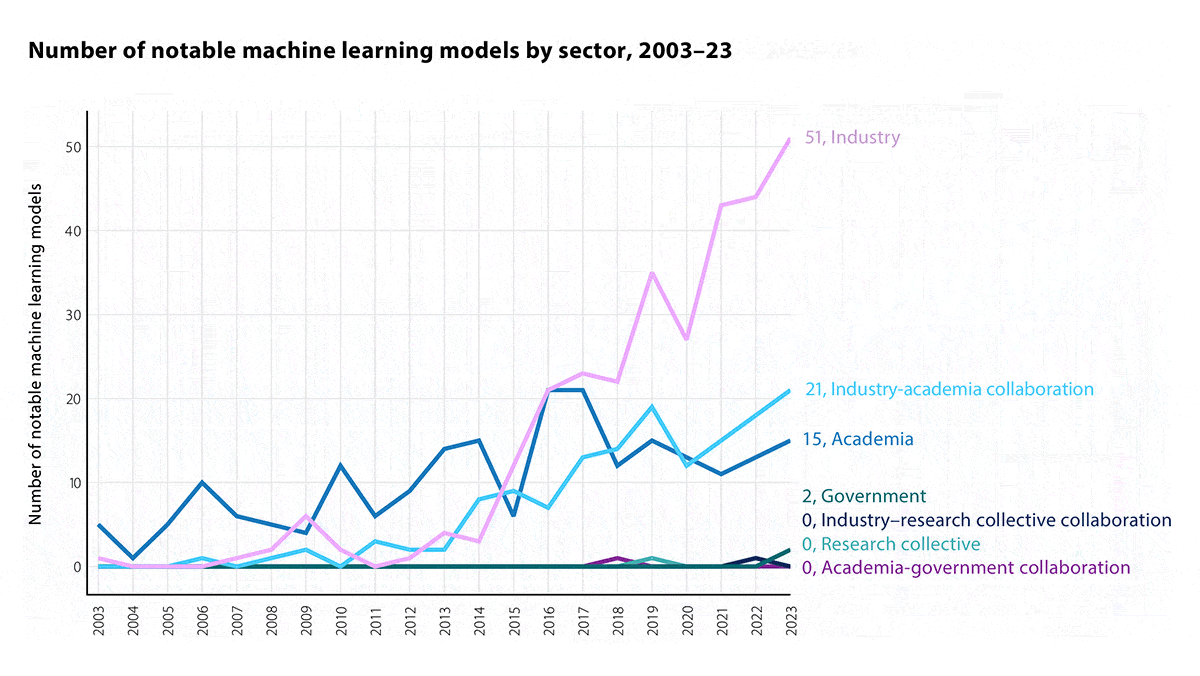
- Industry was the primary driver of innovation, contributing 57 percent of “notable” machine learning models. Partnerships between industry and academia accounted for 23 percent and academia alone for 17 percent. Corporate dominance in model building was a significant shift from previous years; in 2016, academia and industry contributed AI models equally.
- New models have achieved dramatic results in the sciences. For instance, AlphaDev found superior sorting algorithms. GraphCast generated mid-range weather forecasts more accurately than conventional methods. GNoME discovered new materials, and AlphaMissense pinpointed genetic mutations that cause human diseases.
Behind the news: The differences between the new one and the initial, 2018 edition highlight the field’s rapid pace of change. For instance, the 2018 report opened by trumpeting the nearly 9x growth of AI research papers published between 2000 and 2017. The new one opened not with the annual rate of research publications (though it has roughly doubled since 2017) but with a graph of industry’s growing dominance in innovation. The Batch has covered several editions.
Why it matters: The “AI Index Report” offers a detailed snapshot of AI as it advances at an unprecedented rate and shows potential to revolutionize virtually every field of human endeavor. It dives deeply into areas of special concern to researchers (such as Gemini’s nearly $200 million training cost), practitioners (for instance, the slightly narrowing gender gap among computer science PhDs), businesses (the sharply rising number of regulations), and users (half of those who are aware of ChatGPT use it weekly). This year’s report includes new emphases on public opinion and geopolitics.
We're thinking: It’s heartening to see AI thriving. The field faces daunting challenges, yet the report highlights achievements in foundation models, science, medicine, and elsewhere that portend greater benefits directly ahead. What an exciting time for AI!
NEW FROM DEEPLEARNING.AI

Expand your prompting skills with our new short course, “Prompt Engineering for Vision Models.” Learn how to prompt and fine-tune vision models to accomplish tasks from image generation to object detection. Start learning today

Amazon Rethinks Cashier-Free Stores
Amazon is removing grab-and-go shopping from its cart.
What’s new: Amazon withdrew Just Walk Out, an AI-driven checkout service, from most of its Amazon Fresh grocery stores, The Information reported. Instead, the stores will provide smart shopping carts. (Disclosure: Andrew Ng is a member of Amazon’s Board of Directors.)
Checking out: Just Walk Out enables shoppers to scan a payment method upon entering a store, take items from shelves tracked by computer vision and weight-detection sensors, and simply exit with their purchases, bypassing the checkout counter. Amazon had installed the system in 47 Amazon Fresh stores in the U.S. and UK. In most of those locations. Amazon will replace Just Walk Out with Dash Cart, a shopping cart that enables customers to scan purchases as they shop. Amazon will retain Just Walk Out in its Amazon Go convenience stores and an unspecified number of smaller, UK-based Amazon Fresh stores. It has licensed the system to other retailers including Hudson Markets and plans to install in more third-party stores this year.
- Just Walk Out isn’t well suited to grocery shopping, in which customers may buy large numbers of items, since customers may not be aware of their total spending until they receive a receipt via email after leaving the store, Amazon executive Tony Hoggett said. Dash Cart enables users to see the bill in real time.
- Just Walk Out relied on more than 1,000 remote employees to label video for training and review cases where it failed, and Amazon wasn’t able to improve the system as quickly as it expected, according to an earlier report by The Information. As of mid-2022, the system required about 700 human reviews per 1,000 sales, compared to a target between 20 and 50 per 1,000 sales. Amazon said the percentage of sales that require human review has declined since then.
- Training the models required 2,000 technologists and cost hundreds of millions of dollars in cloud computing resources to train and run.
- Just Walk Out’s cameras and sensors can be difficult to install in existing stores and sometimes requires extensive remodeling. The system also requires high ceilings, which existing stores may not have.
Behind the news: Amazon introduced Just Walk Out in 2016 at its first Amazon Go convenience store in Seattle. It extended the system to Amazon Fresh in 2020. Between September 2020 and September 2022, Amazon opened 44 Fresh stores in the U.S. and 19 in the UK, most of which included Just Walk Out. But Amazon’s brick-and-mortar locations suffered during the COVID-19 pandemic. From September 2022 to mid-2024, amid broader cost-cutting efforts, the company paused opening new grocery stores.
Why it matters: Grab-and-go shopping seems like a solid bet, given the increasing focus of retailing on immediate gratification. Yet Amazon’s retreat from Just Walk Out in larger stores suggests that the technology is less well suited to such environments. In addition, shoppers may not have adjusted easily to grab-and-go behavior, which removes social interactions with cashiers and encourages customers to spend without reviewing the bill.
We’re thinking: AI has the potential to revolutionize every field, including retailing, and it’s important to find productive uses for it. Not all experiments will succeed, but patient investment and experimentation can illuminate productive paths forward.

Predicting Scientific Discoveries
A new AI method directs scientists toward promising avenues of inquiry.
What's new: Jamshid Sourati and James A. Evans at University of Chicago proposed a method to predict new scientific discoveries by building a graph that connects researchers, their objects of study, and the scientific properties thereof. They evaluated their approach using data from materials science.
Key insight: Overlapping interests among researchers may indicate areas where further research would be fruitful. For example, if one group of researchers studies a material A and its property P, a second group studies materials A and B, and another group studies materials B and C, it may turn out that material C exhibits property P.
How it works: The authors tried to predict whether certain inorganic materials have certain electrical properties based on scientific literature through the year 2000. From 1.5 million articles that described 100,000 inorganic compounds, they extracted the author names, materials mentioned (for example, sodium nitrite), and their properties (for example, thermoelectricity, the ability to convert heat into electricity and vice versa). They used this data to construct a graph whose nodes were authors, materials, and properties. Edges connected the nodes that appeared in the same paper, for example a particular author whose paper covered specific material or property.
- The authors conducted random walks through the graph, stepping from node to node, to produce sequences of authors, materials, and properties. Then they removed the authors from the sequences, because they were interested mainly in establishing possible connections between materials and properties.
- They trained Word2Vec, which computes word embeddings, on their sequences, treating materials and properties as words and sequences as documents. This yielded an embedding for each material and property.
- To predict possible discoveries — that is, which material might exhibit a given property — the authors scored each material based on (i) the similarity between the material’s embedding and the given property’s embedding and (ii) the smallest number of edges in the path that connected each material and the property. Then they summed scores (i) and (ii). The 50 highest-scoring materials were predicted to have the property (that weren’t directly connected in the graph; that is, excluding materials that already were known to have the property).
Results: The authors predicted which materials possessed each of three properties. They compared their results with predictions obtained in a similar way using a Word2Vec model trained exclusively on text from scientific papers. They used papers from 2001 through 2018 to evaluate the predictions. For thermoelectricity, the cumulative precision (percentage of predicted discoveries proven correct) was 76 percent, while the cumulative precision of the alternative method was 48 percent. The cumulative precision of random guesses was about 3 percent. The authors obtained similar results for the other two properties.
Why it matters: Science is a social endeavor, where the connections between people and their work can be represented as a graph that reflects the collective attention of the scientific community. The collective attention acts as a signal that predicts promising avenues for further research — a signal that machine learning can help to tease out.
We're thinking: The authors also predicted drug discoveries with similarly good results. Their method may be useful for identifying fruitful directions in other scientific areas, and perhaps in other domains entirely.
Data Points
This week's Data Points features these highlights: Adobe's latest Firefly Image 3 model, enhanced smart glasses with Meta’s AI assistant, an AI-powered gene editor, and more.